

commit
0f008a29aa
29 changed files with 6435 additions and 0 deletions
+ 9
- 0
.gitignore
View File
| datasets | |||||
| results | |||||
| model-weights | |||||
| other | |||||
| saved_models | |||||
| __pycache__ | |||||
| .vscode | |||||
| venv |
+ 100
- 0
README.md
View File
| # Domain-Adaptation | |||||
| ## Prepare Environment | |||||
| Install the requirements using conda from `requirements-conda.txt` (or using pip from `requirements.txt`). | |||||
| *My setting:* conda 22.11.1 with Python 3.8 | |||||
| If you have trouble with installing torch check [this link](https://pytorch.org/get-started/previous-versions/) | |||||
| to find the currect version for your device. | |||||
| ## Run | |||||
| 1. Go to `src` directory. | |||||
| 2. Run `main.py` with appropriate arguments. | |||||
| Examples: | |||||
| - Perform MMD and CORAL adaptation on all 6 domain adaptations tasks from office31 dataset: | |||||
| ```bash | |||||
| python main.py --model_names MMD CORAL --batch_size 32 | |||||
| ``` | |||||
| - Tuning parameters of DANN model | |||||
| ```bash | |||||
| python main.py --max_epochs 10 --patience 3 --trials_count 1 --model_names DANN --num_workers 2 --batch_size 32 --source amazon --target webcam --hp_tune True | |||||
| ``` | |||||
| Check "Available arguments" in "Code Structure" section for all the available arguments. | |||||
| ## Code Structure | |||||
| The main code for project is located in the `src/` directory. | |||||
| - `main.py`: The entry to program | |||||
| - **Available arguments:** | |||||
| - `max_epochs`: Maximum number of epochs to run the training | |||||
| - `patience`: Maximum number of epochs to continue if no improvement is seen (Early stopping parameter) | |||||
| - `batch_size` | |||||
| - `num_workers` | |||||
| - `trials_count`: Number of trials to run each of the tasks | |||||
| - `initial_trial`: The number to start indexing the trials from | |||||
| - `download`: Whether to download the dataset or not | |||||
| - `root`: Path to the root of project | |||||
| - `data_root`: Path to the data root | |||||
| - `results_root`: Path to the directory to store the results | |||||
| - `model_names`: Names of models to run separated by space - available options: DANN, CDAN, MMD, MCD, CORAL, SOURCE | |||||
| - `lr`: learning rate** | |||||
| - `gamma`: Gamma value for ExponentialLR** | |||||
| - `hp_tune`: Set true of you want to run for different hyperparameters, used for hyperparameter tuning | |||||
| - `source`: The source domain to run the training for, training will run for all the available domains if not specified - available options: amazon, dslr, webcam | |||||
| - `target`: The target domain to run the training for, training will run for all the available domains if not specified - available options: amazon, dslr, webcam | |||||
| - `vishook_frequency`: Number of epochs to wait before save a visualization | |||||
| - `source_checkpoint_base_dir`: Path to source-only trained model directory to use as base, set `None` to not use source-trained model*** | |||||
| - `source_checkpoint_trial_number`: Trail number of source-only trained model to use | |||||
| - `models.py`: Contains models for adaptation | |||||
| - `train.py`: Contains base training iteration | |||||
| - `classifier_adapter.py`: Contains ClassifierAdapter class which is used for training a source-only model without adaptation | |||||
| - `load_source.py`: Load source-only trained model to use as base model for adaptation | |||||
| - `source.py`: Contains source model | |||||
| - `train_source.py`: Contains base source-only training iteration | |||||
| - `utils.py`: Contains utility classes | |||||
| - `vis_hook.py`: Contains VizHook class which is used for visualization | |||||
| ** Use can also set different lr and gammas for different models and tasks by changing `hp_map` in `main.py` directly. | |||||
| *** For perfoming domain adaptation on source-trained model, one must should train the model for source using option `--model_name SOURCE` first | |||||
| ## Acknowledgements | |||||
| [Pytorch Adapt](https://github.com/KevinMusgrave/pytorch-adapt/tree/0b0fb63b04c9bd7e2cc6cf45314c7ee9d6e391c0) |
+ 211
- 0
requirements-conda.txt
View File
| # This file may be used to create an environment using: | |||||
| # $ conda create --name <env> --file <this file> | |||||
| # platform: linux-64 | |||||
| _libgcc_mutex=0.1=main | |||||
| _openmp_mutex=5.1=1_gnu | |||||
| _pytorch_select=0.1=cpu_0 | |||||
| anyio=3.5.0=py38h06a4308_0 | |||||
| argon2-cffi=21.3.0=pyhd3eb1b0_0 | |||||
| argon2-cffi-bindings=21.2.0=py38h7f8727e_0 | |||||
| asttokens=2.0.5=pyhd3eb1b0_0 | |||||
| attrs=22.1.0=py38h06a4308_0 | |||||
| babel=2.11.0=py38h06a4308_0 | |||||
| backcall=0.2.0=pyhd3eb1b0_0 | |||||
| beautifulsoup4=4.11.1=py38h06a4308_0 | |||||
| blas=1.0=mkl | |||||
| bleach=4.1.0=pyhd3eb1b0_0 | |||||
| brotli=1.0.9=h5eee18b_7 | |||||
| brotli-bin=1.0.9=h5eee18b_7 | |||||
| brotlipy=0.7.0=py38h27cfd23_1003 | |||||
| ca-certificates=2022.10.11=h06a4308_0 | |||||
| certifi=2022.12.7=py38h06a4308_0 | |||||
| cffi=1.15.1=py38h5eee18b_3 | |||||
| charset-normalizer=2.0.4=pyhd3eb1b0_0 | |||||
| comm=0.1.2=py38h06a4308_0 | |||||
| contourpy=1.0.5=py38hdb19cb5_0 | |||||
| cryptography=38.0.1=py38h9ce1e76_0 | |||||
| cudatoolkit=10.1.243=h8cb64d8_10 | |||||
| cudnn=7.6.5.32=hc0a50b0_1 | |||||
| cycler=0.11.0=pyhd3eb1b0_0 | |||||
| dbus=1.13.18=hb2f20db_0 | |||||
| debugpy=1.5.1=py38h295c915_0 | |||||
| decorator=5.1.1=pyhd3eb1b0_0 | |||||
| defusedxml=0.7.1=pyhd3eb1b0_0 | |||||
| entrypoints=0.4=py38h06a4308_0 | |||||
| executing=0.8.3=pyhd3eb1b0_0 | |||||
| expat=2.4.9=h6a678d5_0 | |||||
| filelock=3.9.0=pypi_0 | |||||
| flit-core=3.6.0=pyhd3eb1b0_0 | |||||
| fontconfig=2.14.1=h52c9d5c_1 | |||||
| fonttools=4.25.0=pyhd3eb1b0_0 | |||||
| freetype=2.12.1=h4a9f257_0 | |||||
| gdown=4.6.0=pypi_0 | |||||
| giflib=5.2.1=h7b6447c_0 | |||||
| glib=2.69.1=he621ea3_2 | |||||
| gst-plugins-base=1.14.0=h8213a91_2 | |||||
| gstreamer=1.14.0=h28cd5cc_2 | |||||
| h5py=3.2.1=pypi_0 | |||||
| icu=58.2=he6710b0_3 | |||||
| idna=3.4=py38h06a4308_0 | |||||
| importlib-metadata=4.11.3=py38h06a4308_0 | |||||
| importlib_resources=5.2.0=pyhd3eb1b0_1 | |||||
| intel-openmp=2021.4.0=h06a4308_3561 | |||||
| ipykernel=6.19.2=py38hb070fc8_0 | |||||
| ipython=8.7.0=py38h06a4308_0 | |||||
| ipython_genutils=0.2.0=pyhd3eb1b0_1 | |||||
| ipywidgets=7.6.5=pyhd3eb1b0_1 | |||||
| jedi=0.18.1=py38h06a4308_1 | |||||
| jinja2=3.1.2=py38h06a4308_0 | |||||
| joblib=1.2.0=pypi_0 | |||||
| jpeg=9e=h7f8727e_0 | |||||
| json5=0.9.6=pyhd3eb1b0_0 | |||||
| jsonschema=4.16.0=py38h06a4308_0 | |||||
| jupyter=1.0.0=py38h06a4308_8 | |||||
| jupyter_client=7.4.8=py38h06a4308_0 | |||||
| jupyter_console=6.4.4=py38h06a4308_0 | |||||
| jupyter_core=5.1.1=py38h06a4308_0 | |||||
| jupyter_server=1.23.4=py38h06a4308_0 | |||||
| jupyterlab=3.5.2=py38h06a4308_0 | |||||
| jupyterlab_pygments=0.1.2=py_0 | |||||
| jupyterlab_server=2.16.5=py38h06a4308_0 | |||||
| jupyterlab_widgets=1.0.0=pyhd3eb1b0_1 | |||||
| kiwisolver=1.4.4=py38h6a678d5_0 | |||||
| krb5=1.19.2=hac12032_0 | |||||
| lcms2=2.12=h3be6417_0 | |||||
| ld_impl_linux-64=2.38=h1181459_1 | |||||
| lerc=3.0=h295c915_0 | |||||
| libbrotlicommon=1.0.9=h5eee18b_7 | |||||
| libbrotlidec=1.0.9=h5eee18b_7 | |||||
| libbrotlienc=1.0.9=h5eee18b_7 | |||||
| libclang=10.0.1=default_hb85057a_2 | |||||
| libdeflate=1.8=h7f8727e_5 | |||||
| libedit=3.1.20221030=h5eee18b_0 | |||||
| libevent=2.1.12=h8f2d780_0 | |||||
| libffi=3.4.2=h6a678d5_6 | |||||
| libgcc-ng=11.2.0=h1234567_1 | |||||
| libgomp=11.2.0=h1234567_1 | |||||
| libllvm10=10.0.1=hbcb73fb_5 | |||||
| libpng=1.6.37=hbc83047_0 | |||||
| libpq=12.9=h16c4e8d_3 | |||||
| libsodium=1.0.18=h7b6447c_0 | |||||
| libstdcxx-ng=11.2.0=h1234567_1 | |||||
| libtiff=4.4.0=hecacb30_2 | |||||
| libuuid=1.41.5=h5eee18b_0 | |||||
| libuv=1.40.0=h7b6447c_0 | |||||
| libwebp=1.2.4=h11a3e52_0 | |||||
| libwebp-base=1.2.4=h5eee18b_0 | |||||
| libxcb=1.15=h7f8727e_0 | |||||
| libxkbcommon=1.0.1=hfa300c1_0 | |||||
| libxml2=2.9.14=h74e7548_0 | |||||
| libxslt=1.1.35=h4e12654_0 | |||||
| llvmlite=0.39.1=pypi_0 | |||||
| lxml=4.9.1=py38h1edc446_0 | |||||
| lz4-c=1.9.4=h6a678d5_0 | |||||
| markupsafe=2.1.1=py38h7f8727e_0 | |||||
| matplotlib=3.4.2=pypi_0 | |||||
| matplotlib-inline=0.1.6=py38h06a4308_0 | |||||
| mistune=0.8.4=py38h7b6447c_1000 | |||||
| mkl=2021.4.0=h06a4308_640 | |||||
| mkl-service=2.4.0=py38h7f8727e_0 | |||||
| mkl_fft=1.3.1=py38hd3c417c_0 | |||||
| mkl_random=1.2.2=py38h51133e4_0 | |||||
| munkres=1.1.4=py_0 | |||||
| nbclassic=0.4.8=py38h06a4308_0 | |||||
| nbclient=0.5.13=py38h06a4308_0 | |||||
| nbconvert=6.5.4=py38h06a4308_0 | |||||
| nbformat=5.7.0=py38h06a4308_0 | |||||
| ncurses=6.3=h5eee18b_3 | |||||
| nest-asyncio=1.5.6=py38h06a4308_0 | |||||
| ninja=1.10.2=h06a4308_5 | |||||
| ninja-base=1.10.2=hd09550d_5 | |||||
| notebook=6.5.2=py38h06a4308_0 | |||||
| notebook-shim=0.2.2=py38h06a4308_0 | |||||
| nspr=4.33=h295c915_0 | |||||
| nss=3.74=h0370c37_0 | |||||
| numba=0.56.4=pypi_0 | |||||
| numpy=1.22.4=pypi_0 | |||||
| opencv-python=4.5.2.54=pypi_0 | |||||
| openssl=1.1.1s=h7f8727e_0 | |||||
| packaging=22.0=py38h06a4308_0 | |||||
| pandas=1.5.2=pypi_0 | |||||
| pandocfilters=1.5.0=pyhd3eb1b0_0 | |||||
| parso=0.8.3=pyhd3eb1b0_0 | |||||
| pcre=8.45=h295c915_0 | |||||
| pexpect=4.8.0=pyhd3eb1b0_3 | |||||
| pickleshare=0.7.5=pyhd3eb1b0_1003 | |||||
| pillow=8.4.0=pypi_0 | |||||
| pip=22.3.1=py38h06a4308_0 | |||||
| pkgutil-resolve-name=1.3.10=py38h06a4308_0 | |||||
| platformdirs=2.5.2=py38h06a4308_0 | |||||
| ply=3.11=py38_0 | |||||
| prometheus_client=0.14.1=py38h06a4308_0 | |||||
| prompt-toolkit=3.0.36=py38h06a4308_0 | |||||
| prompt_toolkit=3.0.36=hd3eb1b0_0 | |||||
| psutil=5.9.0=py38h5eee18b_0 | |||||
| ptyprocess=0.7.0=pyhd3eb1b0_2 | |||||
| pure_eval=0.2.2=pyhd3eb1b0_0 | |||||
| pycparser=2.21=pyhd3eb1b0_0 | |||||
| pygments=2.11.2=pyhd3eb1b0_0 | |||||
| pynndescent=0.5.8=pypi_0 | |||||
| pyopenssl=22.0.0=pyhd3eb1b0_0 | |||||
| pyparsing=3.0.9=py38h06a4308_0 | |||||
| pyqt=5.15.7=py38h6a678d5_1 | |||||
| pyqt5-sip=12.11.0=py38h6a678d5_1 | |||||
| pyrsistent=0.18.0=py38heee7806_0 | |||||
| pysocks=1.7.1=py38h06a4308_0 | |||||
| python=3.8.15=h7a1cb2a_2 | |||||
| python-dateutil=2.8.2=pyhd3eb1b0_0 | |||||
| python-fastjsonschema=2.16.2=py38h06a4308_0 | |||||
| pytorch-adapt=0.0.82=pypi_0 | |||||
| pytorch-ignite=0.4.9=pypi_0 | |||||
| pytorch-metric-learning=1.6.3=pypi_0 | |||||
| pytz=2022.7=py38h06a4308_0 | |||||
| pyyaml=6.0=pypi_0 | |||||
| pyzmq=23.2.0=py38h6a678d5_0 | |||||
| qt-main=5.15.2=h327a75a_7 | |||||
| qt-webengine=5.15.9=hd2b0992_4 | |||||
| qtconsole=5.3.2=py38h06a4308_0 | |||||
| qtpy=2.2.0=py38h06a4308_0 | |||||
| qtwebkit=5.212=h4eab89a_4 | |||||
| readline=8.2=h5eee18b_0 | |||||
| requests=2.28.1=py38h06a4308_0 | |||||
| scikit-learn=1.0=pypi_0 | |||||
| scipy=1.6.3=pypi_0 | |||||
| seaborn=0.12.2=pypi_0 | |||||
| send2trash=1.8.0=pyhd3eb1b0_1 | |||||
| setuptools=65.5.0=py38h06a4308_0 | |||||
| sip=6.6.2=py38h6a678d5_0 | |||||
| six=1.16.0=pyhd3eb1b0_1 | |||||
| sniffio=1.2.0=py38h06a4308_1 | |||||
| soupsieve=2.3.2.post1=py38h06a4308_0 | |||||
| sqlite=3.40.0=h5082296_0 | |||||
| stack_data=0.2.0=pyhd3eb1b0_0 | |||||
| terminado=0.17.1=py38h06a4308_0 | |||||
| threadpoolctl=3.1.0=pypi_0 | |||||
| timm=0.4.9=pypi_0 | |||||
| tinycss2=1.2.1=py38h06a4308_0 | |||||
| tk=8.6.12=h1ccaba5_0 | |||||
| toml=0.10.2=pyhd3eb1b0_0 | |||||
| tomli=2.0.1=py38h06a4308_0 | |||||
| torch=1.8.1+cu101=pypi_0 | |||||
| torchaudio=0.8.1=pypi_0 | |||||
| torchmetrics=0.9.3=pypi_0 | |||||
| torchvision=0.9.1+cu101=pypi_0 | |||||
| tornado=6.2=py38h5eee18b_0 | |||||
| tqdm=4.61.2=pypi_0 | |||||
| traitlets=5.7.1=py38h06a4308_0 | |||||
| typing-extensions=4.4.0=py38h06a4308_0 | |||||
| typing_extensions=4.4.0=py38h06a4308_0 | |||||
| umap-learn=0.5.3=pypi_0 | |||||
| urllib3=1.26.13=py38h06a4308_0 | |||||
| wcwidth=0.2.5=pyhd3eb1b0_0 | |||||
| webencodings=0.5.1=py38_1 | |||||
| websocket-client=0.58.0=py38h06a4308_4 | |||||
| wheel=0.37.1=pyhd3eb1b0_0 | |||||
| widgetsnbextension=3.5.2=py38h06a4308_0 | |||||
| xz=5.2.8=h5eee18b_0 | |||||
| yacs=0.1.8=pypi_0 | |||||
| zeromq=4.3.4=h2531618_0 | |||||
| zipp=3.11.0=py38h06a4308_0 | |||||
| zlib=1.2.13=h5eee18b_0 | |||||
| zstd=1.5.2=ha4553b6_0 |
+ 134
- 0
requirements.txt
View File
| anyio @ file:///tmp/build/80754af9/anyio_1644481698350/work/dist | |||||
| argon2-cffi @ file:///opt/conda/conda-bld/argon2-cffi_1645000214183/work | |||||
| argon2-cffi-bindings @ file:///tmp/build/80754af9/argon2-cffi-bindings_1644569684262/work | |||||
| asttokens @ file:///opt/conda/conda-bld/asttokens_1646925590279/work | |||||
| attrs @ file:///croot/attrs_1668696182826/work | |||||
| Babel @ file:///croot/babel_1671781930836/work | |||||
| backcall @ file:///home/ktietz/src/ci/backcall_1611930011877/work | |||||
| beautifulsoup4 @ file:///opt/conda/conda-bld/beautifulsoup4_1650462163268/work | |||||
| bleach @ file:///opt/conda/conda-bld/bleach_1641577558959/work | |||||
| brotlipy==0.7.0 | |||||
| certifi @ file:///croot/certifi_1671487769961/work/certifi | |||||
| cffi @ file:///croot/cffi_1670423208954/work | |||||
| charset-normalizer @ file:///tmp/build/80754af9/charset-normalizer_1630003229654/work | |||||
| comm @ file:///croot/comm_1671231121260/work | |||||
| contourpy @ file:///opt/conda/conda-bld/contourpy_1663827406301/work | |||||
| cryptography @ file:///croot/cryptography_1665612644927/work | |||||
| cycler @ file:///tmp/build/80754af9/cycler_1637851556182/work | |||||
| debugpy @ file:///tmp/build/80754af9/debugpy_1637091796427/work | |||||
| decorator @ file:///opt/conda/conda-bld/decorator_1643638310831/work | |||||
| defusedxml @ file:///tmp/build/80754af9/defusedxml_1615228127516/work | |||||
| entrypoints @ file:///tmp/build/80754af9/entrypoints_1649926445639/work | |||||
| executing @ file:///opt/conda/conda-bld/executing_1646925071911/work | |||||
| fastjsonschema @ file:///opt/conda/conda-bld/python-fastjsonschema_1661371079312/work | |||||
| filelock==3.9.0 | |||||
| flit_core @ file:///opt/conda/conda-bld/flit-core_1644941570762/work/source/flit_core | |||||
| fonttools==4.25.0 | |||||
| gdown==4.6.0 | |||||
| h5py==3.2.1 | |||||
| idna @ file:///croot/idna_1666125576474/work | |||||
| importlib-metadata @ file:///tmp/build/80754af9/importlib-metadata_1648562408398/work | |||||
| importlib-resources @ file:///tmp/build/80754af9/importlib_resources_1625135880749/work | |||||
| ipykernel @ file:///croot/ipykernel_1671488378391/work | |||||
| ipython @ file:///croot/ipython_1670919316550/work | |||||
| ipython-genutils @ file:///tmp/build/80754af9/ipython_genutils_1606773439826/work | |||||
| ipywidgets @ file:///tmp/build/80754af9/ipywidgets_1634143127070/work | |||||
| jedi @ file:///tmp/build/80754af9/jedi_1644315233700/work | |||||
| Jinja2 @ file:///croot/jinja2_1666908132255/work | |||||
| joblib==1.2.0 | |||||
| json5 @ file:///tmp/build/80754af9/json5_1624432770122/work | |||||
| jsonschema @ file:///opt/conda/conda-bld/jsonschema_1663375472438/work | |||||
| jupyter @ file:///tmp/abs_33h4eoipez/croots/recipe/jupyter_1659349046347/work | |||||
| jupyter-console @ file:///croot/jupyter_console_1671541909316/work | |||||
| jupyter-server @ file:///croot/jupyter_server_1671707632269/work | |||||
| jupyter_client @ file:///croot/jupyter_client_1671703053786/work | |||||
| jupyter_core @ file:///croot/jupyter_core_1672332224593/work | |||||
| jupyterlab @ file:///croot/jupyterlab_1672132689850/work | |||||
| jupyterlab-pygments @ file:///tmp/build/80754af9/jupyterlab_pygments_1601490720602/work | |||||
| jupyterlab-widgets @ file:///tmp/build/80754af9/jupyterlab_widgets_1609884341231/work | |||||
| jupyterlab_server @ file:///croot/jupyterlab_server_1672127357747/work | |||||
| kiwisolver @ file:///croot/kiwisolver_1672387140495/work | |||||
| llvmlite==0.39.1 | |||||
| lxml @ file:///opt/conda/conda-bld/lxml_1657545139709/work | |||||
| MarkupSafe @ file:///opt/conda/conda-bld/markupsafe_1654597864307/work | |||||
| matplotlib==3.4.2 | |||||
| matplotlib-inline @ file:///opt/conda/conda-bld/matplotlib-inline_1662014470464/work | |||||
| mistune==0.8.4 | |||||
| mkl-fft==1.3.1 | |||||
| mkl-random @ file:///tmp/build/80754af9/mkl_random_1626186064646/work | |||||
| mkl-service==2.4.0 | |||||
| munkres==1.1.4 | |||||
| nbclassic @ file:///croot/nbclassic_1668174957779/work | |||||
| nbclient @ file:///tmp/build/80754af9/nbclient_1650308366712/work | |||||
| nbconvert @ file:///croot/nbconvert_1668450669124/work | |||||
| nbformat @ file:///croot/nbformat_1670352325207/work | |||||
| nest-asyncio @ file:///croot/nest-asyncio_1672387112409/work | |||||
| notebook @ file:///croot/notebook_1668179881751/work | |||||
| notebook_shim @ file:///croot/notebook-shim_1668160579331/work | |||||
| numba==0.56.4 | |||||
| numpy==1.22.4 | |||||
| opencv-python==4.5.2.54 | |||||
| packaging @ file:///croot/packaging_1671697413597/work | |||||
| pandas==1.5.2 | |||||
| pandocfilters @ file:///opt/conda/conda-bld/pandocfilters_1643405455980/work | |||||
| parso @ file:///opt/conda/conda-bld/parso_1641458642106/work | |||||
| pexpect @ file:///tmp/build/80754af9/pexpect_1605563209008/work | |||||
| pickleshare @ file:///tmp/build/80754af9/pickleshare_1606932040724/work | |||||
| Pillow==8.4.0 | |||||
| pkgutil_resolve_name @ file:///opt/conda/conda-bld/pkgutil-resolve-name_1661463321198/work | |||||
| platformdirs @ file:///opt/conda/conda-bld/platformdirs_1662711380096/work | |||||
| ply==3.11 | |||||
| prometheus-client @ file:///tmp/abs_d3zeliano1/croots/recipe/prometheus_client_1659455100375/work | |||||
| prompt-toolkit @ file:///croot/prompt-toolkit_1672387306916/work | |||||
| psutil @ file:///opt/conda/conda-bld/psutil_1656431268089/work | |||||
| ptyprocess @ file:///tmp/build/80754af9/ptyprocess_1609355006118/work/dist/ptyprocess-0.7.0-py2.py3-none-any.whl | |||||
| pure-eval @ file:///opt/conda/conda-bld/pure_eval_1646925070566/work | |||||
| pycparser @ file:///tmp/build/80754af9/pycparser_1636541352034/work | |||||
| Pygments @ file:///opt/conda/conda-bld/pygments_1644249106324/work | |||||
| pynndescent==0.5.8 | |||||
| pyOpenSSL @ file:///opt/conda/conda-bld/pyopenssl_1643788558760/work | |||||
| pyparsing @ file:///opt/conda/conda-bld/pyparsing_1661452539315/work | |||||
| PyQt5-sip==12.11.0 | |||||
| pyrsistent @ file:///tmp/build/80754af9/pyrsistent_1636110947380/work | |||||
| PySocks @ file:///tmp/build/80754af9/pysocks_1605305779399/work | |||||
| python-dateutil @ file:///tmp/build/80754af9/python-dateutil_1626374649649/work | |||||
| pytorch-adapt==0.0.82 | |||||
| pytorch-ignite==0.4.9 | |||||
| pytorch-metric-learning==1.6.3 | |||||
| pytz @ file:///croot/pytz_1671697431263/work | |||||
| PyYAML==6.0 | |||||
| pyzmq @ file:///opt/conda/conda-bld/pyzmq_1657724186960/work | |||||
| qtconsole @ file:///opt/conda/conda-bld/qtconsole_1662018252641/work | |||||
| QtPy @ file:///opt/conda/conda-bld/qtpy_1662014892439/work | |||||
| requests @ file:///opt/conda/conda-bld/requests_1657734628632/work | |||||
| scikit-learn==1.0 | |||||
| scipy==1.6.3 | |||||
| seaborn==0.12.2 | |||||
| Send2Trash @ file:///tmp/build/80754af9/send2trash_1632406701022/work | |||||
| sip @ file:///tmp/abs_44cd77b_pu/croots/recipe/sip_1659012365470/work | |||||
| six @ file:///tmp/build/80754af9/six_1644875935023/work | |||||
| sniffio @ file:///tmp/build/80754af9/sniffio_1614030475067/work | |||||
| soupsieve @ file:///croot/soupsieve_1666296392845/work | |||||
| stack-data @ file:///opt/conda/conda-bld/stack_data_1646927590127/work | |||||
| terminado @ file:///croot/terminado_1671751832461/work | |||||
| threadpoolctl==3.1.0 | |||||
| timm==0.4.9 | |||||
| tinycss2 @ file:///croot/tinycss2_1668168815555/work | |||||
| toml @ file:///tmp/build/80754af9/toml_1616166611790/work | |||||
| tomli @ file:///opt/conda/conda-bld/tomli_1657175507142/work | |||||
| torch==1.8.1+cu101 | |||||
| torchaudio==0.8.1 | |||||
| torchmetrics==0.9.3 | |||||
| torchvision==0.9.1+cu101 | |||||
| tornado @ file:///opt/conda/conda-bld/tornado_1662061693373/work | |||||
| tqdm==4.61.2 | |||||
| traitlets @ file:///croot/traitlets_1671143879854/work | |||||
| typing_extensions @ file:///croot/typing_extensions_1669924550328/work | |||||
| umap-learn==0.5.3 | |||||
| urllib3 @ file:///croot/urllib3_1670526988650/work | |||||
| wcwidth @ file:///Users/ktietz/demo/mc3/conda-bld/wcwidth_1629357192024/work | |||||
| webencodings==0.5.1 | |||||
| websocket-client @ file:///tmp/build/80754af9/websocket-client_1614804261064/work | |||||
| widgetsnbextension @ file:///tmp/build/80754af9/widgetsnbextension_1645009353553/work | |||||
| yacs==0.1.8 | |||||
| zipp @ file:///croot/zipp_1672387121353/work |
+ 21
- 0
src/classifier_adapter.py
View File
| from pytorch_adapt.adapters.base_adapter import BaseGCAdapter | |||||
| from pytorch_adapt.adapters.utils import with_opt | |||||
| from pytorch_adapt.hooks import ClassifierHook | |||||
| class ClassifierAdapter(BaseGCAdapter): | |||||
| """ | |||||
| Wraps [AlignerPlusCHook][pytorch_adapt.hooks.AlignerPlusCHook]. | |||||
| |Container|Required keys| | |||||
| |---|---| | |||||
| |models|```["G", "C"]```| | |||||
| |optimizers|```["G", "C"]```| | |||||
| """ | |||||
| def init_hook(self, hook_kwargs): | |||||
| opts = with_opt(list(self.optimizers.keys())) | |||||
| self.hook = self.hook_cls(opts, **hook_kwargs) | |||||
| @property | |||||
| def hook_cls(self): | |||||
| return ClassifierHook |
+ 67
- 0
src/load_source.py
View File
| import torch | |||||
| import os | |||||
| from pytorch_adapt.adapters import DANN, MCD, VADA, CDAN, RTN, ADDA, Aligner, SymNets | |||||
| from pytorch_adapt.containers import Models, Optimizers, LRSchedulers | |||||
| from pytorch_adapt.models import Discriminator, office31C, office31G | |||||
| from pytorch_adapt.containers import Misc | |||||
| from pytorch_adapt.containers import LRSchedulers | |||||
| from classifier_adapter import ClassifierAdapter | |||||
| from utils import HP, DAModels | |||||
| import copy | |||||
| import matplotlib.pyplot as plt | |||||
| import torch | |||||
| import os | |||||
| import gc | |||||
| from datetime import datetime | |||||
| from pytorch_adapt.datasets import DataloaderCreator, get_office31 | |||||
| from pytorch_adapt.frameworks.ignite import CheckpointFnCreator, Ignite | |||||
| from pytorch_adapt.validators import AccuracyValidator, IMValidator, ScoreHistory | |||||
| from pytorch_adapt.frameworks.ignite import ( | |||||
| CheckpointFnCreator, | |||||
| IgniteValHookWrapper, | |||||
| checkpoint_utils, | |||||
| ) | |||||
| device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") | |||||
| def get_source_trainer(checkpoint_dir): | |||||
| G = office31G(pretrained=False).to(device) | |||||
| C = office31C(pretrained=False).to(device) | |||||
| optimizers = Optimizers((torch.optim.Adam, {"lr": 1e-4})) | |||||
| lr_schedulers = LRSchedulers((torch.optim.lr_scheduler.ExponentialLR, {"gamma": 0.99})) | |||||
| models = Models({"G": G, "C": C}) | |||||
| adapter= ClassifierAdapter(models=models, optimizers=optimizers, lr_schedulers=lr_schedulers) | |||||
| checkpoint_fn = CheckpointFnCreator(dirname=checkpoint_dir, require_empty=False) | |||||
| sourceAccuracyValidator = AccuracyValidator() | |||||
| val_hooks = [ScoreHistory(sourceAccuracyValidator)] | |||||
| new_trainer = Ignite( | |||||
| adapter, val_hooks=val_hooks, checkpoint_fn=checkpoint_fn, device=device | |||||
| ) | |||||
| objs = [ | |||||
| { | |||||
| "engine": new_trainer.trainer, | |||||
| **checkpoint_utils.adapter_to_dict(new_trainer.adapter), | |||||
| } | |||||
| ] | |||||
| for to_load in objs: | |||||
| checkpoint_fn.load_best_checkpoint(to_load) | |||||
| return new_trainer |
+ 172
- 0
src/main.py
View File
| import argparse | |||||
| import logging | |||||
| import os | |||||
| from datetime import datetime | |||||
| from train import train | |||||
| from train_source import train_source | |||||
| from utils import HP, DAModels | |||||
| import tracemalloc | |||||
| logging.basicConfig() | |||||
| logging.getLogger("pytorch-adapt").setLevel(logging.WARNING) | |||||
| DATASET_PAIRS = [("amazon", "webcam"), ("amazon", "dslr"), | |||||
| ("webcam", "amazon"), ("webcam", "dslr"), | |||||
| ("dslr", "amazon"), ("dslr", "webcam")] | |||||
| def run_experiment_on_model(args, model_name, trial_number): | |||||
| train_fn = train | |||||
| if model_name == DAModels.SOURCE: | |||||
| train_fn = train_source | |||||
| base_output_dir = f"{args.results_root}/{model_name}/{trial_number}" | |||||
| os.makedirs(base_output_dir, exist_ok=True) | |||||
| hp_map = { | |||||
| 'DANN': { | |||||
| 'a2d': (5e-05, 0.99), | |||||
| 'a2w': (5e-05, 0.99), | |||||
| 'd2a': (0.0001, 0.9), | |||||
| 'd2w': (5e-05, 0.99), | |||||
| 'w2a': (0.0001, 0.99), | |||||
| 'w2d': (0.0001, 0.99), | |||||
| }, | |||||
| 'CDAN': { | |||||
| 'a2d': (1e-05, 1), | |||||
| 'a2w': (1e-05, 1), | |||||
| 'd2a': (1e-05, 0.99), | |||||
| 'd2w': (1e-05, 0.99), | |||||
| 'w2a': (0.0001, 0.99), | |||||
| 'w2d': (5e-05, 0.99), | |||||
| }, | |||||
| 'MMD': { | |||||
| 'a2d': (5e-05, 1), | |||||
| 'a2w': (5e-05, 0.99), | |||||
| 'd2a': (0.0001, 0.99), | |||||
| 'd2w': (5e-05, 0.9), | |||||
| 'w2a': (0.0001, 0.99), | |||||
| 'w2d': (1e-05, 0.99), | |||||
| }, | |||||
| 'MCD': { | |||||
| 'a2d': (1e-05, 0.9), | |||||
| 'a2w': (0.0001, 1), | |||||
| 'd2a': (1e-05, 0.9), | |||||
| 'd2w': (1e-05, 0.99), | |||||
| 'w2a': (1e-05, 0.9), | |||||
| 'w2d': (5*1e-6, 0.99), | |||||
| }, | |||||
| 'CORAL': { | |||||
| 'a2d': (1e-05, 0.99), | |||||
| 'a2w': (1e-05, 1), | |||||
| 'd2a': (5*1e-6, 0.99), | |||||
| 'd2w': (0.0001, 0.99), | |||||
| 'w2a': (1e-5, 0.99), | |||||
| 'w2d': (0.0001, 0.99), | |||||
| }, | |||||
| } | |||||
| if not args.hp_tune: | |||||
| d = datetime.now() | |||||
| results_file = f"{base_output_dir}/e{args.max_epochs}_p{args.patience}_{d.strftime('%Y%m%d-%H:%M:%S')}.txt" | |||||
| with open(results_file, "w") as myfile: | |||||
| myfile.write("pair, source_acc, target_acc, best_epoch, best_score, time, cur, peak, lr, gamma\n") | |||||
| for source_domain, target_domain in DATASET_PAIRS: | |||||
| pair_name = f"{source_domain[0]}2{target_domain[0]}" | |||||
| hp_parmas = hp_map[DAModels.CDAN.name][pair_name] | |||||
| lr = args.lr if args.lr else hp_parmas[0] | |||||
| gamma = args.gamma if args.gamma else hp_parmas[1] | |||||
| hp = HP(lr=lr, gamma=gamma) | |||||
| tracemalloc.start() | |||||
| train_fn(args, model_name, hp, base_output_dir, results_file, source_domain, target_domain) | |||||
| cur, peak = tracemalloc.get_traced_memory() | |||||
| tracemalloc.stop() | |||||
| with open(results_file, "a") as myfile: | |||||
| myfile.write(f"{cur}, {peak}\n") | |||||
| else: | |||||
| # gamma_list = [1, 0.99, 0.9, 0.8] | |||||
| # lr_list = [1e-5, 3*1e-5, 1e-4, 3*1e-4] | |||||
| hp_values = { | |||||
| 1e-4: [0.99, 0.9], | |||||
| 1e-5: [0.99, 0.9], | |||||
| 5*1e-5: [0.99, 0.9], | |||||
| 5*1e-6: [0.99] | |||||
| # 5*1e-4: [1, 0.99], | |||||
| # 1e-3: [0.99, 0.9, 0.8], | |||||
| } | |||||
| d = datetime.now() | |||||
| hp_file = f"{base_output_dir}/hp_e{args.max_epochs}_p{args.patience}_{d.strftime('%Y%m%d-%H:%M:%S')}.txt" | |||||
| with open(hp_file, "w") as myfile: | |||||
| myfile.write("lr, gamma, pair, source_acc, target_acc, best_epoch, best_score\n") | |||||
| hp_best = None | |||||
| hp_best_score = None | |||||
| for lr, gamma_list in hp_values.items(): | |||||
| # for lr in lr_list: | |||||
| for gamma in gamma_list: | |||||
| hp = HP(lr=lr, gamma=gamma) | |||||
| print("HP:", hp) | |||||
| for source_domain, target_domain in DATASET_PAIRS: | |||||
| _, _, best_score = \ | |||||
| train_fn(args, model_name, hp, base_output_dir, hp_file, source_domain, target_domain) | |||||
| if best_score is not None and (hp_best_score is None or hp_best_score < best_score): | |||||
| hp_best = hp | |||||
| hp_best_score = best_score | |||||
| with open(hp_file, "a") as myfile: | |||||
| myfile.write(f"\nbest: {hp_best.lr}, {hp_best.gamma}\n") | |||||
| if __name__ == "__main__": | |||||
| parser = argparse.ArgumentParser() | |||||
| parser.add_argument('--max_epochs', default=60, type=int) | |||||
| parser.add_argument('--patience', default=10, type=int) | |||||
| parser.add_argument('--batch_size', default=32, type=int) | |||||
| parser.add_argument('--num_workers', default=2, type=int) | |||||
| parser.add_argument('--trials_count', default=3, type=int) | |||||
| parser.add_argument('--initial_trial', default=0, type=int) | |||||
| parser.add_argument('--download', default=False, type=bool) | |||||
| parser.add_argument('--root', default="../") | |||||
| parser.add_argument('--data_root', default="../datasets/pytorch-adapt/") | |||||
| parser.add_argument('--results_root', default="../results/") | |||||
| parser.add_argument('--model_names', default=["DANN"], nargs='+') | |||||
| parser.add_argument('--lr', default=None, type=float) | |||||
| parser.add_argument('--gamma', default=None, type=float) | |||||
| parser.add_argument('--hp_tune', default=False, type=bool) | |||||
| parser.add_argument('--source', default=None) | |||||
| parser.add_argument('--target', default=None) | |||||
| parser.add_argument('--vishook_frequency', default=5, type=int) | |||||
| parser.add_argument('--source_checkpoint_base_dir', default=None) # default='../results/DAModels.SOURCE/' | |||||
| parser.add_argument('--source_checkpoint_trial_number', default=-1, type=int) | |||||
| args = parser.parse_args() | |||||
| print(args) | |||||
| for trial_number in range(args.initial_trial, args.initial_trial + args.trials_count): | |||||
| if args.source_checkpoint_trial_number == -1: | |||||
| args.source_checkpoint_trial_number = trial_number | |||||
| for model_name in args.model_names: | |||||
| try: | |||||
| model_enum = DAModels(model_name) | |||||
| except ValueError: | |||||
| logging.warning(f"Model {model_name} not found. skipping...") | |||||
| continue | |||||
| run_experiment_on_model(args, model_enum, trial_number) |
+ 85
- 0
src/models.py
View File
| import torch | |||||
| import os | |||||
| from pytorch_adapt.adapters import DANN, MCD, VADA, CDAN, RTN, ADDA, Aligner, SymNets | |||||
| from pytorch_adapt.containers import Models, Optimizers, LRSchedulers | |||||
| from pytorch_adapt.models import Discriminator, office31C, office31G | |||||
| from pytorch_adapt.containers import Misc | |||||
| from pytorch_adapt.layers import RandomizedDotProduct | |||||
| from pytorch_adapt.layers import MultipleModels, CORALLoss, MMDLoss | |||||
| from pytorch_adapt.utils import common_functions | |||||
| from pytorch_adapt.containers import LRSchedulers | |||||
| from classifier_adapter import ClassifierAdapter | |||||
| from load_source import get_source_trainer | |||||
| from utils import HP, DAModels | |||||
| import copy | |||||
| device = torch.device("cuda" if torch.cuda.is_available() else "cpu") | |||||
| def get_model(model_name, hp: HP, source_checkpoint_dir, data_root, source_domain): | |||||
| if source_checkpoint_dir: | |||||
| source_trainer = get_source_trainer(source_checkpoint_dir) | |||||
| G = copy.deepcopy(source_trainer.adapter.models["G"]) | |||||
| C = copy.deepcopy(source_trainer.adapter.models["C"]) | |||||
| D = Discriminator(in_size=2048, h=1024).to(device) | |||||
| else: | |||||
| weights_root = os.path.join(data_root, "weights") | |||||
| G = office31G(pretrained=True, model_dir=weights_root).to(device) | |||||
| C = office31C(domain=source_domain, pretrained=True, | |||||
| model_dir=weights_root).to(device) | |||||
| D = Discriminator(in_size=2048, h=1024).to(device) | |||||
| optimizers = Optimizers((torch.optim.Adam, {"lr": hp.lr})) | |||||
| lr_schedulers = LRSchedulers((torch.optim.lr_scheduler.ExponentialLR, {"gamma": hp.gamma})) | |||||
| if model_name == DAModels.DANN: | |||||
| models = Models({"G": G, "C": C, "D": D}) | |||||
| adapter = DANN(models=models, optimizers=optimizers, lr_schedulers=lr_schedulers) | |||||
| elif model_name == DAModels.CDAN: | |||||
| models = Models({"G": G, "C": C, "D": D}) | |||||
| misc = Misc({"feature_combiner": RandomizedDotProduct([2048, 31], 2048)}) | |||||
| adapter = CDAN(models=models, misc=misc, optimizers=optimizers, lr_schedulers=lr_schedulers) | |||||
| elif model_name == DAModels.MCD: | |||||
| C1 = common_functions.reinit(copy.deepcopy(C)) | |||||
| C_combined = MultipleModels(C, C1) | |||||
| models = Models({"G": G, "C": C_combined}) | |||||
| adapter= MCD(models=models, optimizers=optimizers, lr_schedulers=lr_schedulers) | |||||
| elif model_name == DAModels.SYMNET: | |||||
| C1 = common_functions.reinit(copy.deepcopy(C)) | |||||
| C_combined = MultipleModels(C, C1) | |||||
| models = Models({"G": G, "C": C_combined}) | |||||
| adapter= SymNets(models=models, optimizers=optimizers, lr_schedulers=lr_schedulers) | |||||
| elif model_name == DAModels.MMD: | |||||
| models = Models({"G": G, "C": C}) | |||||
| hook_kwargs = {"loss_fn": MMDLoss()} | |||||
| adapter= Aligner(models=models, optimizers=optimizers, lr_schedulers=lr_schedulers, hook_kwargs=hook_kwargs) | |||||
| elif model_name == DAModels.CORAL: | |||||
| models = Models({"G": G, "C": C}) | |||||
| hook_kwargs = {"loss_fn": CORALLoss()} | |||||
| adapter= Aligner(models=models, optimizers=optimizers, lr_schedulers=lr_schedulers, hook_kwargs=hook_kwargs) | |||||
| elif model_name == DAModels.SOURCE: | |||||
| models = Models({"G": G, "C": C}) | |||||
| adapter= ClassifierAdapter(models=models, optimizers=optimizers, lr_schedulers=lr_schedulers) | |||||
| return adapter | |||||
+ 167
- 0
src/source.py
View File
| import logging | |||||
| import matplotlib.pyplot as plt | |||||
| import pandas as pd | |||||
| import seaborn as sns | |||||
| import torch | |||||
| import umap | |||||
| from tqdm import tqdm | |||||
| import os | |||||
| import gc | |||||
| from datetime import datetime | |||||
| from pytorch_adapt.adapters import DANN, MCD, VADA, CDAN, RTN, ADDA, Aligner | |||||
| from pytorch_adapt.adapters.base_adapter import BaseGCAdapter | |||||
| from pytorch_adapt.adapters.utils import with_opt | |||||
| from pytorch_adapt.hooks import ClassifierHook | |||||
| from pytorch_adapt.containers import Models, Optimizers, LRSchedulers | |||||
| from pytorch_adapt.datasets import DataloaderCreator, get_mnist_mnistm, get_office31 | |||||
| from pytorch_adapt.frameworks.ignite import CheckpointFnCreator, Ignite | |||||
| from pytorch_adapt.models import Discriminator, mnistC, mnistG, office31C, office31G | |||||
| from pytorch_adapt.validators import AccuracyValidator, IMValidator, ScoreHistory | |||||
| from pytorch_adapt.containers import Misc | |||||
| from pytorch_adapt.layers import RandomizedDotProduct | |||||
| from pytorch_adapt.layers import MultipleModels | |||||
| from pytorch_adapt.utils import common_functions | |||||
| from pytorch_adapt.containers import LRSchedulers | |||||
| import copy | |||||
| from pprint import pprint | |||||
| PATIENCE = 5 | |||||
| EPOCHS = 50 | |||||
| BATCH_SIZE = 32 | |||||
| NUM_WORKERS = 2 | |||||
| TRIAL_COUNT = 5 | |||||
| logging.basicConfig() | |||||
| logging.getLogger("pytorch-adapt").setLevel(logging.WARNING) | |||||
| class ClassifierAdapter(BaseGCAdapter): | |||||
| """ | |||||
| Wraps [AlignerPlusCHook][pytorch_adapt.hooks.AlignerPlusCHook]. | |||||
| |Container|Required keys| | |||||
| |---|---| | |||||
| |models|```["G", "C"]```| | |||||
| |optimizers|```["G", "C"]```| | |||||
| """ | |||||
| def init_hook(self, hook_kwargs): | |||||
| opts = with_opt(list(self.optimizers.keys())) | |||||
| self.hook = self.hook_cls(opts, **hook_kwargs) | |||||
| @property | |||||
| def hook_cls(self): | |||||
| return ClassifierHook | |||||
| root='/content/drive/MyDrive/Shared with Sabas/Bsc/' | |||||
| # root="datasets/pytorch-adapt/" | |||||
| data_root = os.path.join(root,'data') | |||||
| batch_size=BATCH_SIZE | |||||
| num_workers=NUM_WORKERS | |||||
| device = torch.device("cuda") | |||||
| model_dir = os.path.join(data_root, "weights") | |||||
| DATASET_PAIRS = [("amazon", ["webcam", "dslr"]), | |||||
| ("webcam", ["dslr", "amazon"]), | |||||
| ("dslr", ["amazon", "webcam"]) | |||||
| ] | |||||
| MODEL_NAME = "base" | |||||
| model_name = MODEL_NAME | |||||
| pass_next= 0 | |||||
| pass_trial = 0 | |||||
| for trial_number in range(10, 10 + TRIAL_COUNT): | |||||
| if pass_trial: | |||||
| pass_trial -= 1 | |||||
| continue | |||||
| base_output_dir = f"{root}/results/vishook/{MODEL_NAME}/{trial_number}" | |||||
| os.makedirs(base_output_dir, exist_ok=True) | |||||
| d = datetime.now() | |||||
| results_file = f"{base_output_dir}/{d.strftime('%Y%m%d-%H:%M:%S')}.txt" | |||||
| with open(results_file, "w") as myfile: | |||||
| myfile.write("pair, source_acc, target_acc, best_epoch, time\n") | |||||
| for source_domain, target_domains in DATASET_PAIRS: | |||||
| datasets = get_office31([source_domain], [], folder=data_root) | |||||
| dc = DataloaderCreator(batch_size=batch_size, | |||||
| num_workers=num_workers, | |||||
| ) | |||||
| dataloaders = dc(**datasets) | |||||
| G = office31G(pretrained=True, model_dir=model_dir) | |||||
| C = office31C(domain=source_domain, pretrained=True, model_dir=model_dir) | |||||
| optimizers = Optimizers((torch.optim.Adam, {"lr": 0.0005})) | |||||
| lr_schedulers = LRSchedulers((torch.optim.lr_scheduler.ExponentialLR, {"gamma": 0.99})) | |||||
| if model_name == "base": | |||||
| models = Models({"G": G, "C": C}) | |||||
| adapter= ClassifierAdapter(models=models, optimizers=optimizers, lr_schedulers=lr_schedulers) | |||||
| checkpoint_fn = CheckpointFnCreator(dirname="saved_models", require_empty=False) | |||||
| val_hooks = [ScoreHistory(AccuracyValidator())] | |||||
| trainer = Ignite( | |||||
| adapter, val_hooks=val_hooks, checkpoint_fn=checkpoint_fn, | |||||
| ) | |||||
| early_stopper_kwargs = {"patience": PATIENCE} | |||||
| start_time = datetime.now() | |||||
| best_score, best_epoch = trainer.run( | |||||
| datasets, dataloader_creator=dc, max_epochs=EPOCHS, early_stopper_kwargs=early_stopper_kwargs | |||||
| ) | |||||
| end_time = datetime.now() | |||||
| training_time = end_time - start_time | |||||
| for target_domain in target_domains: | |||||
| if pass_next: | |||||
| pass_next -= 1 | |||||
| continue | |||||
| pair_name = f"{source_domain[0]}2{target_domain[0]}" | |||||
| output_dir = os.path.join(base_output_dir, pair_name) | |||||
| os.makedirs(output_dir, exist_ok=True) | |||||
| print("output dir:", output_dir) | |||||
| # print(f"best_score={best_score}, best_epoch={best_epoch}, training_time={training_time.seconds}") | |||||
| plt.plot(val_hooks[0].score_history, label='source') | |||||
| plt.title("val accuracy") | |||||
| plt.legend() | |||||
| plt.savefig(f"{output_dir}/val_accuracy.png") | |||||
| plt.close('all') | |||||
| datasets = get_office31([source_domain], [target_domain], folder=data_root, return_target_with_labels=True) | |||||
| dc = DataloaderCreator(batch_size=64, num_workers=2, all_val=True) | |||||
| validator = AccuracyValidator(key_map={"src_val": "src_val"}) | |||||
| src_score = trainer.evaluate_best_model(datasets, validator, dc) | |||||
| print("Source acc:", src_score) | |||||
| validator = AccuracyValidator(key_map={"target_val_with_labels": "src_val"}) | |||||
| target_score = trainer.evaluate_best_model(datasets, validator, dc) | |||||
| print("Target acc:", target_score) | |||||
| with open(results_file, "a") as myfile: | |||||
| myfile.write(f"{pair_name}, {src_score}, {target_score}, {best_epoch}, {training_time.seconds}\n") | |||||
| del trainer | |||||
| del G | |||||
| del C | |||||
| gc.collect() | |||||
| torch.cuda.empty_cache() |
+ 112
- 0
src/train.py
View File
| import matplotlib.pyplot as plt | |||||
| import torch | |||||
| import os | |||||
| import gc | |||||
| from datetime import datetime | |||||
| from pytorch_adapt.datasets import DataloaderCreator, get_office31 | |||||
| from pytorch_adapt.frameworks.ignite import CheckpointFnCreator, Ignite | |||||
| from pytorch_adapt.validators import AccuracyValidator, IMValidator, ScoreHistory, DiversityValidator, EntropyValidator, MultipleValidators | |||||
| from models import get_model | |||||
| from utils import DAModels | |||||
| from vis_hook import VizHook | |||||
| def train(args, model_name, hp, base_output_dir, results_file, source_domain, target_domain): | |||||
| if args.source != None and args.source != source_domain: | |||||
| return None, None, None | |||||
| if args.target != None and args.target != target_domain: | |||||
| return None, None, None | |||||
| pair_name = f"{source_domain[0]}2{target_domain[0]}" | |||||
| output_dir = os.path.join(base_output_dir, pair_name) | |||||
| os.makedirs(output_dir, exist_ok=True) | |||||
| print("output dir:", output_dir) | |||||
| datasets = get_office31([source_domain], [target_domain], | |||||
| folder=args.data_root, | |||||
| return_target_with_labels=True, | |||||
| download=args.download) | |||||
| dc = DataloaderCreator(batch_size=args.batch_size, | |||||
| num_workers=args.num_workers, | |||||
| train_names=["train"], | |||||
| val_names=["src_train", "target_train", "src_val", "target_val", | |||||
| "target_train_with_labels", "target_val_with_labels"]) | |||||
| source_checkpoint_dir = None if not args.source_checkpoint_base_dir else \ | |||||
| f"{args.source_checkpoint_base_dir}/{args.source_checkpoint_trial_number}/{pair_name}/saved_models" | |||||
| print("source_checkpoint_dir", source_checkpoint_dir) | |||||
| adapter = get_model(model_name, hp, source_checkpoint_dir, args.data_root, source_domain) | |||||
| checkpoint_fn = CheckpointFnCreator(dirname=f"{output_dir}/saved_models", require_empty=False) | |||||
| sourceAccuracyValidator = AccuracyValidator() | |||||
| validators = { | |||||
| "entropy": EntropyValidator(), | |||||
| "diversity": DiversityValidator(), | |||||
| } | |||||
| validator = ScoreHistory(MultipleValidators(validators)) | |||||
| targetAccuracyValidator = AccuracyValidator(key_map={"target_val_with_labels": "src_val"}) | |||||
| val_hooks = [ScoreHistory(sourceAccuracyValidator), | |||||
| ScoreHistory(targetAccuracyValidator), | |||||
| VizHook(output_dir=output_dir, frequency=args.vishook_frequency)] | |||||
| trainer = Ignite( | |||||
| adapter, validator=validator, val_hooks=val_hooks, checkpoint_fn=checkpoint_fn | |||||
| ) | |||||
| early_stopper_kwargs = {"patience": args.patience} | |||||
| start_time = datetime.now() | |||||
| best_score, best_epoch = trainer.run( | |||||
| datasets, dataloader_creator=dc, max_epochs=args.max_epochs, early_stopper_kwargs=early_stopper_kwargs | |||||
| ) | |||||
| end_time = datetime.now() | |||||
| training_time = end_time - start_time | |||||
| print(f"best_score={best_score}, best_epoch={best_epoch}") | |||||
| plt.plot(val_hooks[0].score_history, label='source') | |||||
| plt.plot(val_hooks[1].score_history, label='target') | |||||
| plt.title("val accuracy") | |||||
| plt.legend() | |||||
| plt.savefig(f"{output_dir}/val_accuracy.png") | |||||
| plt.close('all') | |||||
| plt.plot(validator.score_history) | |||||
| plt.title("score_history") | |||||
| plt.savefig(f"{output_dir}/score_history.png") | |||||
| plt.close('all') | |||||
| src_score = trainer.evaluate_best_model(datasets, sourceAccuracyValidator, dc) | |||||
| print("Source acc:", src_score) | |||||
| target_score = trainer.evaluate_best_model(datasets, targetAccuracyValidator, dc) | |||||
| print("Target acc:", target_score) | |||||
| print("---------") | |||||
| if args.hp_tune: | |||||
| with open(results_file, "a") as myfile: | |||||
| myfile.write(f"{hp.lr}, {hp.gamma}, {pair_name}, {src_score}, {target_score}, {best_epoch}, {best_score}\n") | |||||
| else: | |||||
| with open(results_file, "a") as myfile: | |||||
| myfile.write( | |||||
| f"{pair_name}, {src_score}, {target_score}, {best_epoch}, {best_score}, {training_time.seconds}, {hp.lr}, {hp.gamma},") | |||||
| del adapter | |||||
| gc.collect() | |||||
| torch.cuda.empty_cache() | |||||
| return src_score, target_score, best_score |
+ 121
- 0
src/train_source.py
View File
| import torch | |||||
| import os | |||||
| from pytorch_adapt.adapters import DANN, MCD, VADA, CDAN, RTN, ADDA, Aligner, SymNets | |||||
| from pytorch_adapt.containers import Models, Optimizers, LRSchedulers | |||||
| from pytorch_adapt.models import Discriminator, office31C, office31G | |||||
| from pytorch_adapt.containers import Misc | |||||
| from pytorch_adapt.layers import RandomizedDotProduct | |||||
| from pytorch_adapt.layers import MultipleModels, CORALLoss, MMDLoss | |||||
| from pytorch_adapt.utils import common_functions | |||||
| from pytorch_adapt.containers import LRSchedulers | |||||
| from classifier_adapter import ClassifierAdapter | |||||
| from utils import HP, DAModels | |||||
| import copy | |||||
| import matplotlib.pyplot as plt | |||||
| import torch | |||||
| import os | |||||
| import gc | |||||
| from datetime import datetime | |||||
| from pytorch_adapt.datasets import DataloaderCreator, get_office31 | |||||
| from pytorch_adapt.frameworks.ignite import CheckpointFnCreator, Ignite | |||||
| from pytorch_adapt.validators import AccuracyValidator, IMValidator, ScoreHistory, DiversityValidator, EntropyValidator, MultipleValidators | |||||
| device = torch.device("cuda" if torch.cuda.is_available() else "cpu") | |||||
| def train_source(args, model_name, hp, base_output_dir, results_file, source_domain, target_domain): | |||||
| if args.source != None and args.source != source_domain: | |||||
| return None, None, None | |||||
| if args.target != None and args.target != target_domain: | |||||
| return None, None, None | |||||
| pair_name = f"{source_domain[0]}2{target_domain[0]}" | |||||
| output_dir = os.path.join(base_output_dir, pair_name) | |||||
| os.makedirs(output_dir, exist_ok=True) | |||||
| print("output dir:", output_dir) | |||||
| datasets = get_office31([source_domain], [], | |||||
| folder=args.data_root, | |||||
| return_target_with_labels=True, | |||||
| download=args.download) | |||||
| dc = DataloaderCreator(batch_size=args.batch_size, | |||||
| num_workers=args.num_workers, | |||||
| ) | |||||
| weights_root = os.path.join(args.data_root, "weights") | |||||
| G = office31G(pretrained=True, model_dir=weights_root).to(device) | |||||
| C = office31C(domain=source_domain, pretrained=True, | |||||
| model_dir=weights_root).to(device) | |||||
| optimizers = Optimizers((torch.optim.Adam, {"lr": hp.lr})) | |||||
| lr_schedulers = LRSchedulers((torch.optim.lr_scheduler.ExponentialLR, {"gamma": hp.gamma})) | |||||
| models = Models({"G": G, "C": C}) | |||||
| adapter= ClassifierAdapter(models=models, optimizers=optimizers, lr_schedulers=lr_schedulers) | |||||
| # adapter = get_model(model_name, hp, args.data_root, source_domain) | |||||
| print("checkpoint dir:", output_dir) | |||||
| checkpoint_fn = CheckpointFnCreator(dirname=f"{output_dir}/saved_models", require_empty=False) | |||||
| sourceAccuracyValidator = AccuracyValidator() | |||||
| val_hooks = [ScoreHistory(sourceAccuracyValidator)] | |||||
| trainer = Ignite( | |||||
| adapter, val_hooks=val_hooks, checkpoint_fn=checkpoint_fn | |||||
| ) | |||||
| early_stopper_kwargs = {"patience": args.patience} | |||||
| start_time = datetime.now() | |||||
| best_score, best_epoch = trainer.run( | |||||
| datasets, dataloader_creator=dc, max_epochs=args.max_epochs, early_stopper_kwargs=early_stopper_kwargs | |||||
| ) | |||||
| end_time = datetime.now() | |||||
| training_time = end_time - start_time | |||||
| print(f"best_score={best_score}, best_epoch={best_epoch}") | |||||
| plt.plot(val_hooks[0].score_history, label='source') | |||||
| plt.title("val accuracy") | |||||
| plt.legend() | |||||
| plt.savefig(f"{output_dir}/val_accuracy.png") | |||||
| plt.close('all') | |||||
| datasets = get_office31([source_domain], [target_domain], folder=args.data_root, return_target_with_labels=True) | |||||
| dc = DataloaderCreator(batch_size=args.batch_size, num_workers=args.num_workers, all_val=True) | |||||
| validator = AccuracyValidator(key_map={"src_val": "src_val"}) | |||||
| src_score = trainer.evaluate_best_model(datasets, validator, dc) | |||||
| print("Source acc:", src_score) | |||||
| validator = AccuracyValidator(key_map={"target_val_with_labels": "src_val"}) | |||||
| target_score = trainer.evaluate_best_model(datasets, validator, dc) | |||||
| print("Target acc:", target_score) | |||||
| print("---------") | |||||
| if args.hp_tune: | |||||
| with open(results_file, "a") as myfile: | |||||
| myfile.write(f"{hp.lr}, {hp.gamma}, {pair_name}, {src_score}, {target_score}, {best_epoch}, {best_score}\n") | |||||
| else: | |||||
| with open(results_file, "a") as myfile: | |||||
| myfile.write( | |||||
| f"{pair_name}, {src_score}, {target_score}, {best_epoch}, {best_score}, {training_time.seconds}, ") | |||||
| del adapter | |||||
| gc.collect() | |||||
| torch.cuda.empty_cache() | |||||
| return src_score, target_score, best_score |
+ 17
- 0
src/utils.py
View File
| from dataclasses import dataclass | |||||
| from enum import Enum | |||||
| @dataclass | |||||
| class HP: | |||||
| lr:float = 0.0005 | |||||
| gamma:float = 0.99 | |||||
| class DAModels(Enum): | |||||
| DANN = "DANN" | |||||
| MCD = "MCD" | |||||
| CDAN = "CDAN" | |||||
| SOURCE = "SOURCE" | |||||
| MMD = "MMD" | |||||
| CORAL = "CORAL" | |||||
| SYMNET = "SYMNET" |
+ 47
- 0
src/vis_hook.py
View File
| import matplotlib.pyplot as plt | |||||
| import pandas as pd | |||||
| import seaborn as sns | |||||
| import torch | |||||
| import umap | |||||
| from datetime import datetime | |||||
| from pytorch_adapt.adapters import DANN | |||||
| from pytorch_adapt.containers import Models, Optimizers, LRSchedulers | |||||
| from pytorch_adapt.datasets import DataloaderCreator, get_office31 | |||||
| from pytorch_adapt.frameworks.ignite import CheckpointFnCreator, Ignite | |||||
| from pytorch_adapt.models import Discriminator, office31C, office31G | |||||
| from pytorch_adapt.validators import AccuracyValidator, IMValidator, ScoreHistory | |||||
| class VizHook: | |||||
| def __init__(self, **kwargs): | |||||
| self.required_data = ["src_val", | |||||
| "target_val", "target_val_with_labels"] | |||||
| self.kwargs = kwargs | |||||
| def __call__(self, epoch, src_val, target_val, target_val_with_labels, **kwargs): | |||||
| accuracy_validator = AccuracyValidator() | |||||
| accuracy = accuracy_validator.compute_score(src_val=src_val) | |||||
| print("src_val accuracy:", accuracy) | |||||
| accuracy_validator = AccuracyValidator() | |||||
| accuracy = accuracy_validator.compute_score(src_val=target_val_with_labels) | |||||
| print("target_val accuracy:", accuracy) | |||||
| if epoch >= 2 and epoch % kwargs.get("frequency", 5) != 0: | |||||
| return | |||||
| features = [src_val["features"], target_val["features"]] | |||||
| domain = [src_val["domain"], target_val["domain"]] | |||||
| features = torch.cat(features, dim=0).cpu().numpy() | |||||
| domain = torch.cat(domain, dim=0).cpu().numpy() | |||||
| emb = umap.UMAP().fit_transform(features) | |||||
| df = pd.DataFrame(emb).assign(domain=domain) | |||||
| df["domain"] = df["domain"].replace({0: "Source", 1: "Target"}) | |||||
| sns.set_theme(style="white", rc={"figure.figsize": (8, 6)}) | |||||
| sns.scatterplot(data=df, x=0, y=1, hue="domain", s=10) | |||||
| plt.savefig(f"{self.kwargs['output_dir']}/val_{epoch}.png") | |||||
| plt.close('all') |
+ 42
- 0
utils/dataset_vis.py
View File
| import matplotlib.pyplot as plt | |||||
| import numpy as np | |||||
| import torchvision | |||||
| from pytorch_adapt.datasets import get_office31 | |||||
| # root="datasets/pytorch-adapt/" | |||||
| mean = [0.485, 0.456, 0.406] | |||||
| std = [0.229, 0.224, 0.225] | |||||
| inv_normalize = torchvision.transforms.Normalize( | |||||
| mean=[-m / s for m, s in zip(mean, std)], std=[1 / s for s in std] | |||||
| ) | |||||
| idx = 0 | |||||
| def imshow(img, domain, figsize=(10, 6)): | |||||
| img = inv_normalize(img) | |||||
| npimg = img.numpy() | |||||
| plt.figure(figsize=figsize) | |||||
| plt.imshow(np.transpose(npimg, (1, 2, 0))) | |||||
| plt.axis('off') | |||||
| plt.savefig(f"office31-{idx}") | |||||
| plt.show() | |||||
| plt.close("all") | |||||
| idx += 1 | |||||
| def imshow_many(datasets, src, target): | |||||
| d = datasets["train"] | |||||
| for name in ["src_imgs", "target_imgs"]: | |||||
| domains = src if name == "src_imgs" else target | |||||
| if len(domains) == 0: | |||||
| continue | |||||
| print(domains) | |||||
| imgs = [d[i][name] for i in np.random.choice(len(d), size=16, replace=False)] | |||||
| imshow(torchvision.utils.make_grid(imgs)) | |||||
| for src, target in [(["amazon"], ["dslr"]), (["webcam"], [])]: | |||||
| datasets = get_office31(src, target,folder=root) | |||||
| imshow_many(datasets, src, target) |
+ 1416
- 0
utils/experiment-saba-pytorch.ipynb
File diff suppressed because it is too large
View File
+ 2322
- 0
utils/experiment-saba.ipynb
File diff suppressed because it is too large
View File
+ 165
- 0
utils/get_average.py
View File
| import itertools | |||||
| import numpy as np | |||||
| from pprint import pprint | |||||
| domains = ["w", "d", "a"] | |||||
| pairs = [[f"{d1}2{d2}" for d1 in domains] for d2 in domains] | |||||
| pairs = list(itertools.chain.from_iterable(pairs)) | |||||
| pairs.sort() | |||||
| # print(pairs) | |||||
| ROUND_FACTOR = 3 | |||||
| all_accs_list = {} | |||||
| files = [ | |||||
| "all.txt", | |||||
| "all2.txt", | |||||
| "all3.txt", | |||||
| # "all_step_scheduler.txt", | |||||
| # "all_source_trained_1.txt", | |||||
| # "all_source_trained_2_specific_hp.txt", | |||||
| ] | |||||
| for file in files: | |||||
| with open(file) as f: | |||||
| name = None | |||||
| for line in f: | |||||
| splitted = line.split(" ") | |||||
| if splitted[0] == "##": # e.g. ## DANN | |||||
| name = splitted[1].strip() | |||||
| splitted = line.split(",") # a2w, acc1, acc2, | |||||
| if splitted[0] in pairs: | |||||
| pair = splitted[0] | |||||
| name = name.lower() | |||||
| acc = float(splitted[2].strip()) | |||||
| if name not in all_accs_list: | |||||
| all_accs_list[name] = {p:[] for p in pairs} | |||||
| all_accs_list[name][pair].append(acc) | |||||
| # all_accs_list format: {'dann': {'a2w': [acc1, acc2, acc3]}} | |||||
| acc_means_by_model_name = {} | |||||
| vars_by_model_name = {} | |||||
| for name, pair_list in all_accs_list.items(): | |||||
| accs = {p:[] for p in pairs} | |||||
| vars = {p:[] for p in pairs} | |||||
| for pair, acc_list in pair_list.items(): | |||||
| if len(acc_list) > 0: | |||||
| ## Calculate average and round | |||||
| accs[pair] = round(100 * sum(acc_list) / len(acc_list), ROUND_FACTOR) | |||||
| vars[pair] = round(np.var(acc_list) * 100, ROUND_FACTOR) | |||||
| print(vars[pair], "|||", acc_list) | |||||
| acc_means_by_model_name[name] = accs | |||||
| vars_by_model_name[name] = vars | |||||
| # for name, acc_list in acc_means_by_model_name.items(): | |||||
| # pprint(name) | |||||
| # pprint(all_accs_list) | |||||
| # pprint(acc_means_by_model_name) | |||||
| # pprint(vars_by_model_name) | |||||
| print() | |||||
| latex_table = "" | |||||
| header = [pair for pair in pairs if pair[0] != pair[-1]] | |||||
| table = [] | |||||
| var_table = [] | |||||
| for name, acc_list in acc_means_by_model_name.items(): | |||||
| if "target" in name: | |||||
| continue | |||||
| var_list = vars_by_model_name[name] | |||||
| valid_accs = [] | |||||
| table_row = [] | |||||
| var_table_row = [] | |||||
| for pair in pairs: | |||||
| acc = acc_list[pair] | |||||
| var = var_list[pair] | |||||
| if pair[0] != pair[-1]: # exclude w2w, ... | |||||
| table_row.append(acc) | |||||
| var_table_row.append(var) | |||||
| if acc != None: | |||||
| valid_accs.append(acc) | |||||
| acc_average = round(sum(valid_accs) / len(header), ROUND_FACTOR) | |||||
| table_row.append(acc_average) | |||||
| table.append(table_row) | |||||
| var =round(np.var(valid_accs), ROUND_FACTOR) | |||||
| print(var, "~~~~~~", valid_accs) | |||||
| var_table_row.append(var) | |||||
| var_table.append(var_table_row) | |||||
| t = np.array(table) | |||||
| t[t==None] = np.nan | |||||
| # pprint(t) | |||||
| col_max = t.max(axis=0) | |||||
| pprint(table) | |||||
| latex_table = "" | |||||
| header = [pair for pair in pairs if pair[0] != pair[-1]] | |||||
| name_map = {"base_source": "Source-Only"} | |||||
| j = 0 | |||||
| for name, acc_list in acc_means_by_model_name.items(): | |||||
| if "target" in name: | |||||
| continue | |||||
| latex_name = name | |||||
| if name in name_map: | |||||
| latex_name= name_map[name] | |||||
| latex_row = f"{latex_name.replace('_','-').upper()} &" | |||||
| acc_sum = 0 | |||||
| for i, acc in enumerate(table[j]): | |||||
| if i == len(table[j]) - 1: | |||||
| acc_str = f"${acc}$" | |||||
| else: | |||||
| acc_str = f"${acc} \pm {var_table[j][i]}$" | |||||
| if acc == col_max[i]: | |||||
| latex_row += f" \\underline{{{acc_str}}} &" | |||||
| else: | |||||
| latex_row += f" {acc_str} &" | |||||
| latex_row = f"{latex_row[:-1]} \\\\ \hline" | |||||
| latex_table += f"{latex_row}\n" | |||||
| j += 1 | |||||
| print(*header, sep=" & ") | |||||
| print(latex_table) | |||||
| data = np.array(table) | |||||
| legend = [key for key in acc_means_by_model_name.keys()] | |||||
| labels = [*header, "avg"] | |||||
| data = np.array([[71.75, 75.94 ,67.38, 90.99, 68.91, 96.67, 78.61], [64.0, 66.67, 37.32, 94.97, 45.74, 98.5, 67.87]]) | |||||
| legend = ["CDAN", "Source-only"] | |||||
| labels = [*header, "avg"] | |||||
| import matplotlib.pyplot as plt | |||||
| # Assume your matrix is called 'data' | |||||
| n, m = data.shape | |||||
| # Create an array of x-coordinates for the bars | |||||
| x = np.arange(m) | |||||
| # Plot the bars for each row side by side | |||||
| for i in range(n): | |||||
| row = data[i, :] | |||||
| plt.bar(x + (i-n/2)*0.3, row, width=0.25, align='center') | |||||
| # Set x-axis tick labels and labels | |||||
| plt.xticks(x, labels=labels) | |||||
| # plt.xlabel("Task") | |||||
| plt.ylabel("Accuracy") | |||||
| # Add a legend | |||||
| plt.legend(legend) | |||||
| plt.show() |
+ 167
- 0
utils/get_time.py
View File
| import itertools | |||||
| import numpy as np | |||||
| from pprint import pprint | |||||
| domains = ["w", "d", "a"] | |||||
| pairs = [[f"{d1}2{d2}" for d1 in domains] for d2 in domains] | |||||
| pairs = list(itertools.chain.from_iterable(pairs)) | |||||
| pairs.sort() | |||||
| # print(pairs) | |||||
| ROUND_FACTOR = 2 | |||||
| all_accs_list = {} | |||||
| files = [ | |||||
| # "all.txt", | |||||
| # "all2.txt", | |||||
| # "all3.txt", | |||||
| # "all_step_scheduler.txt", | |||||
| # "all_source_trained_1.txt", | |||||
| "all_source_trained_2_specific_hp.txt", | |||||
| ] | |||||
| for file in files: | |||||
| with open(file) as f: | |||||
| name = None | |||||
| for line in f: | |||||
| splitted = line.split(" ") | |||||
| if splitted[0] == "##": # e.g. ## DANN | |||||
| name = splitted[1].strip() | |||||
| splitted = line.split(",") # a2w, acc1, acc2, | |||||
| if splitted[0] in pairs: | |||||
| pair = splitted[0] | |||||
| name = name.lower() | |||||
| acc = float(splitted[5].strip()) #/ 60 / 60 | |||||
| if name not in all_accs_list: | |||||
| all_accs_list[name] = {p:[] for p in pairs} | |||||
| all_accs_list[name][pair].append(acc) | |||||
| # all_accs_list format: {'dann': {'a2w': [acc1, acc2, acc3]}} | |||||
| acc_means_by_model_name = {} | |||||
| vars_by_model_name = {} | |||||
| for name, pair_list in all_accs_list.items(): | |||||
| accs = {p:[] for p in pairs} | |||||
| vars = {p:[] for p in pairs} | |||||
| for pair, acc_list in pair_list.items(): | |||||
| if len(acc_list) > 0: | |||||
| ## Calculate average and round | |||||
| accs[pair] = round(sum(acc_list) / len(acc_list), ROUND_FACTOR) | |||||
| vars[pair] = round(np.var(acc_list) * 100, ROUND_FACTOR) | |||||
| print(vars[pair], "|||", acc_list) | |||||
| acc_means_by_model_name[name] = accs | |||||
| vars_by_model_name[name] = vars | |||||
| # for name, acc_list in acc_means_by_model_name.items(): | |||||
| # pprint(name) | |||||
| # pprint(all_accs_list) | |||||
| # pprint(acc_means_by_model_name) | |||||
| # pprint(vars_by_model_name) | |||||
| print() | |||||
| latex_table = "" | |||||
| header = [pair for pair in pairs if pair[0] != pair[-1]] | |||||
| table = [] | |||||
| var_table = [] | |||||
| for name, acc_list in acc_means_by_model_name.items(): | |||||
| if "target" in name or "source" in name: | |||||
| continue | |||||
| print("~~~~%%%%~~~", name) | |||||
| var_list = vars_by_model_name[name] | |||||
| valid_accs = [] | |||||
| table_row = [] | |||||
| var_table_row = [] | |||||
| for pair in pairs: | |||||
| acc = acc_list[pair] | |||||
| var = var_list[pair] | |||||
| if pair[0] != pair[-1]: # exclude w2w, ... | |||||
| table_row.append(acc) | |||||
| var_table_row.append(var) | |||||
| if acc != None: | |||||
| valid_accs.append(acc) | |||||
| acc_average = round(sum(valid_accs) / len(header), ROUND_FACTOR) | |||||
| table_row.append(acc_average) | |||||
| table.append(table_row) | |||||
| var =round(np.var(valid_accs), ROUND_FACTOR) | |||||
| print(var, ">>>", valid_accs) | |||||
| var_table_row.append(var) | |||||
| var_table.append(var_table_row) | |||||
| t = np.array(table) | |||||
| t[t==None] = np.nan | |||||
| # pprint(t) | |||||
| col_max = t.min(axis=0) | |||||
| pprint(table) | |||||
| latex_table = "" | |||||
| header = [pair for pair in pairs if pair[0] != pair[-1]] | |||||
| name_map = {"base_source": "Source-Only"} | |||||
| j = 0 | |||||
| for name, acc_list in acc_means_by_model_name.items(): | |||||
| if "target" in name or "source" in name: | |||||
| continue | |||||
| latex_name = name | |||||
| if name in name_map: | |||||
| latex_name= name_map[name] | |||||
| latex_row = f"{latex_name.replace('_','-').upper()} &" | |||||
| acc_sum = 0 | |||||
| for i, acc in enumerate(table[j]): | |||||
| if i == len(table[j]) - 1: | |||||
| acc_str = f"${acc}$" | |||||
| else: | |||||
| acc_str = f"${acc}$" | |||||
| if acc == col_max[i]: | |||||
| latex_row += f" \\underline{{{acc_str}}} &" | |||||
| else: | |||||
| latex_row += f" {acc_str} &" | |||||
| latex_row = f"{latex_row[:-1]} \\\\ \hline" | |||||
| latex_table += f"{latex_row}\n" | |||||
| j += 1 | |||||
| print(*header, sep=" & ") | |||||
| print(latex_table) | |||||
| data = np.array(table) | |||||
| legend = [key for key in acc_means_by_model_name.keys() if "source" not in key] | |||||
| labels = [*header, "avg"] | |||||
| # data = np.array([[71.75, 75.94 ,67.38, 90.99, 68.91, 96.67, 78.61], [64.0, 66.67, 37.32, 94.97, 45.74, 98.5, 67.87]]) | |||||
| # legend = ["CDAN", "Source-only"] | |||||
| # labels = [*header, "avg"] | |||||
| import matplotlib.pyplot as plt | |||||
| # Assume your matrix is called 'data' | |||||
| n, m = data.shape | |||||
| # Create an array of x-coordinates for the bars | |||||
| x = np.arange(m) | |||||
| # Plot the bars for each row side by side | |||||
| for i in range(n): | |||||
| row = data[i, :] | |||||
| plt.bar(x + (i-n/2)*0.1, row, width=0.08, align='center') | |||||
| # Set x-axis tick labels and labels | |||||
| plt.xticks(x, labels=labels) | |||||
| # plt.xlabel("Task") | |||||
| plt.ylabel("Time (s)") | |||||
| # Add a legend | |||||
| plt.legend(legend) | |||||
| plt.show() |
+ 30
- 0
utils/num_workers.py
View File
| from pytorch_adapt.datasets import DataloaderCreator, get_office31 | |||||
| from pytorch_adapt.frameworks.ignite import CheckpointFnCreator, Ignite | |||||
| from pytorch_adapt.validators import AccuracyValidator, IMValidator, ScoreHistory, DiversityValidator, EntropyValidator, MultipleValidators | |||||
| from time import time | |||||
| import multiprocessing as mp | |||||
| data_root = "../datasets/pytorch-adapt/" | |||||
| batch_size = 32 | |||||
| for num_workers in range(2, mp.cpu_count(), 2): | |||||
| datasets = get_office31(["amazon"], ["webcam"], | |||||
| folder=data_root, | |||||
| return_target_with_labels=True, | |||||
| download=False) | |||||
| dc = DataloaderCreator(batch_size=batch_size, | |||||
| num_workers=num_workers, | |||||
| train_names=["train"], | |||||
| val_names=["src_train", "target_train", "src_val", "target_val", | |||||
| "target_train_with_labels", "target_val_with_labels"]) | |||||
| dataloaders = dc(**datasets) | |||||
| train_loader = dataloaders["train"] | |||||
| start = time() | |||||
| for epoch in range(1, 3): | |||||
| for i, data in enumerate(train_loader, 0): | |||||
| pass | |||||
| end = time() | |||||
| print("Finish with:{} second, num_workers={}".format(end - start, num_workers)) |
+ 924
- 0
utils/test-save-load.ipynb
View File
| { | |||||
| "cells": [ | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 1, | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "data": { | |||||
| "text/plain": [ | |||||
| "device(type='cuda', index=0)" | |||||
| ] | |||||
| }, | |||||
| "execution_count": 1, | |||||
| "metadata": {}, | |||||
| "output_type": "execute_result" | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "\n", | |||||
| "import torch\n", | |||||
| "import os\n", | |||||
| "\n", | |||||
| "from pytorch_adapt.adapters import DANN, MCD, VADA, CDAN, RTN, ADDA, Aligner, SymNets\n", | |||||
| "from pytorch_adapt.containers import Models, Optimizers, LRSchedulers\n", | |||||
| "from pytorch_adapt.models import Discriminator, office31C, office31G\n", | |||||
| "from pytorch_adapt.containers import Misc\n", | |||||
| "from pytorch_adapt.layers import RandomizedDotProduct\n", | |||||
| "from pytorch_adapt.layers import MultipleModels, CORALLoss, MMDLoss\n", | |||||
| "from pytorch_adapt.utils import common_functions\n", | |||||
| "from pytorch_adapt.containers import LRSchedulers\n", | |||||
| "\n", | |||||
| "from classifier_adapter import ClassifierAdapter\n", | |||||
| "\n", | |||||
| "from utils import HP, DAModels\n", | |||||
| "\n", | |||||
| "import copy\n", | |||||
| "\n", | |||||
| "import matplotlib.pyplot as plt\n", | |||||
| "import torch\n", | |||||
| "import os\n", | |||||
| "import gc\n", | |||||
| "from datetime import datetime\n", | |||||
| "\n", | |||||
| "from pytorch_adapt.datasets import DataloaderCreator, get_office31\n", | |||||
| "from pytorch_adapt.frameworks.ignite import CheckpointFnCreator, Ignite\n", | |||||
| "from pytorch_adapt.validators import AccuracyValidator, IMValidator, ScoreHistory, DiversityValidator, EntropyValidator, MultipleValidators\n", | |||||
| "\n", | |||||
| "from models import get_model\n", | |||||
| "from utils import DAModels\n", | |||||
| "\n", | |||||
| "from vis_hook import VizHook\n", | |||||
| "device = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\n", | |||||
| "device" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 2, | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "Namespace(batch_size=64, data_root='./datasets/pytorch-adapt/', download=False, gamma=0.99, hp_tune=False, initial_trial=0, lr=0.0001, max_epochs=1, model_names=['DANN'], num_workers=1, patience=2, results_root='./results/', root='./', source=None, target=None, trials_count=1, vishook_frequency=5)\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "import argparse\n", | |||||
| "parser = argparse.ArgumentParser()\n", | |||||
| "parser.add_argument('--max_epochs', default=1, type=int)\n", | |||||
| "parser.add_argument('--patience', default=2, type=int)\n", | |||||
| "parser.add_argument('--batch_size', default=64, type=int)\n", | |||||
| "parser.add_argument('--num_workers', default=1, type=int)\n", | |||||
| "parser.add_argument('--trials_count', default=1, type=int)\n", | |||||
| "parser.add_argument('--initial_trial', default=0, type=int)\n", | |||||
| "parser.add_argument('--download', default=False, type=bool)\n", | |||||
| "parser.add_argument('--root', default=\"./\")\n", | |||||
| "parser.add_argument('--data_root', default=\"./datasets/pytorch-adapt/\")\n", | |||||
| "parser.add_argument('--results_root', default=\"./results/\")\n", | |||||
| "parser.add_argument('--model_names', default=[\"DANN\"], nargs='+')\n", | |||||
| "parser.add_argument('--lr', default=0.0001, type=float)\n", | |||||
| "parser.add_argument('--gamma', default=0.99, type=float)\n", | |||||
| "parser.add_argument('--hp_tune', default=False, type=bool)\n", | |||||
| "parser.add_argument('--source', default=None)\n", | |||||
| "parser.add_argument('--target', default=None) \n", | |||||
| "parser.add_argument('--vishook_frequency', default=5, type=int)\n", | |||||
| " \n", | |||||
| "\n", | |||||
| "args = parser.parse_args(\"\")\n", | |||||
| "print(args)\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 45, | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "source_domain = 'amazon'\n", | |||||
| "target_domain = 'webcam'\n", | |||||
| "datasets = get_office31([source_domain], [],\n", | |||||
| " folder=args.data_root,\n", | |||||
| " return_target_with_labels=True,\n", | |||||
| " download=args.download)\n", | |||||
| "\n", | |||||
| "dc = DataloaderCreator(batch_size=args.batch_size,\n", | |||||
| " num_workers=args.num_workers,\n", | |||||
| " )\n", | |||||
| "\n", | |||||
| "weights_root = os.path.join(args.data_root, \"weights\")\n", | |||||
| "\n", | |||||
| "G = office31G(pretrained=True, model_dir=weights_root).to(device)\n", | |||||
| "C = office31C(domain=source_domain, pretrained=True,\n", | |||||
| " model_dir=weights_root).to(device)\n", | |||||
| "\n", | |||||
| "\n", | |||||
| "optimizers = Optimizers((torch.optim.Adam, {\"lr\": 1e-4}))\n", | |||||
| "lr_schedulers = LRSchedulers((torch.optim.lr_scheduler.ExponentialLR, {\"gamma\": 0.99})) \n", | |||||
| "\n", | |||||
| "models = Models({\"G\": G, \"C\": C})\n", | |||||
| "adapter= ClassifierAdapter(models=models, optimizers=optimizers, lr_schedulers=lr_schedulers)" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": null, | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "cuda:0\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "data": { | |||||
| "application/vnd.jupyter.widget-view+json": { | |||||
| "model_id": "f28aaf5a334d4f91a9beb21e714c43a5", | |||||
| "version_major": 2, | |||||
| "version_minor": 0 | |||||
| }, | |||||
| "text/plain": [ | |||||
| "[1/35] 3%|2 |it [00:00<?]" | |||||
| ] | |||||
| }, | |||||
| "metadata": {}, | |||||
| "output_type": "display_data" | |||||
| }, | |||||
| { | |||||
| "data": { | |||||
| "application/vnd.jupyter.widget-view+json": { | |||||
| "model_id": "7131d8b9099c4d0a95155595919c55f5", | |||||
| "version_major": 2, | |||||
| "version_minor": 0 | |||||
| }, | |||||
| "text/plain": [ | |||||
| "[1/9] 11%|#1 |it [00:00<?]" | |||||
| ] | |||||
| }, | |||||
| "metadata": {}, | |||||
| "output_type": "display_data" | |||||
| }, | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "best_score=None, best_epoch=None\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "ename": "AttributeError", | |||||
| "evalue": "'Namespace' object has no attribute 'dataroot'", | |||||
| "output_type": "error", | |||||
| "traceback": [ | |||||
| "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m", | |||||
| "\u001b[0;31mAttributeError\u001b[0m Traceback (most recent call last)", | |||||
| "Cell \u001b[0;32mIn[39], line 31\u001b[0m\n\u001b[1;32m 28\u001b[0m plt\u001b[39m.\u001b[39msavefig(\u001b[39mf\u001b[39m\u001b[39m\"\u001b[39m\u001b[39m{\u001b[39;00moutput_dir\u001b[39m}\u001b[39;00m\u001b[39m/val_accuracy.png\u001b[39m\u001b[39m\"\u001b[39m)\n\u001b[1;32m 29\u001b[0m plt\u001b[39m.\u001b[39mclose(\u001b[39m'\u001b[39m\u001b[39mall\u001b[39m\u001b[39m'\u001b[39m)\n\u001b[0;32m---> 31\u001b[0m datasets \u001b[39m=\u001b[39m get_office31([source_domain], [target_domain], folder\u001b[39m=\u001b[39margs\u001b[39m.\u001b[39;49mdataroot, return_target_with_labels\u001b[39m=\u001b[39m\u001b[39mTrue\u001b[39;00m)\n\u001b[1;32m 32\u001b[0m dc \u001b[39m=\u001b[39m DataloaderCreator(batch_size\u001b[39m=\u001b[39margs\u001b[39m.\u001b[39mbatch_size, num_workers\u001b[39m=\u001b[39margs\u001b[39m.\u001b[39mnum_workers, all_val\u001b[39m=\u001b[39m\u001b[39mTrue\u001b[39;00m)\n\u001b[1;32m 34\u001b[0m validator \u001b[39m=\u001b[39m AccuracyValidator(key_map\u001b[39m=\u001b[39m{\u001b[39m\"\u001b[39m\u001b[39msrc_val\u001b[39m\u001b[39m\"\u001b[39m: \u001b[39m\"\u001b[39m\u001b[39msrc_val\u001b[39m\u001b[39m\"\u001b[39m})\n", | |||||
| "\u001b[0;31mAttributeError\u001b[0m: 'Namespace' object has no attribute 'dataroot'" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "\n", | |||||
| "output_dir = \"tmp\"\n", | |||||
| "checkpoint_fn = CheckpointFnCreator(dirname=f\"{output_dir}/saved_models\", require_empty=False)\n", | |||||
| "\n", | |||||
| "sourceAccuracyValidator = AccuracyValidator()\n", | |||||
| "val_hooks = [ScoreHistory(sourceAccuracyValidator)]\n", | |||||
| "\n", | |||||
| "trainer = Ignite(\n", | |||||
| " adapter, val_hooks=val_hooks, checkpoint_fn=checkpoint_fn, device=device\n", | |||||
| ")\n", | |||||
| "print(trainer.device)\n", | |||||
| "\n", | |||||
| "early_stopper_kwargs = {\"patience\": args.patience}\n", | |||||
| "\n", | |||||
| "start_time = datetime.now()\n", | |||||
| "\n", | |||||
| "best_score, best_epoch = trainer.run(\n", | |||||
| " datasets, dataloader_creator=dc, max_epochs=args.max_epochs, early_stopper_kwargs=early_stopper_kwargs\n", | |||||
| ")\n", | |||||
| "\n", | |||||
| "end_time = datetime.now()\n", | |||||
| "training_time = end_time - start_time\n", | |||||
| "\n", | |||||
| "print(f\"best_score={best_score}, best_epoch={best_epoch}\")\n", | |||||
| "\n", | |||||
| "plt.plot(val_hooks[0].score_history, label='source')\n", | |||||
| "plt.title(\"val accuracy\")\n", | |||||
| "plt.legend()\n", | |||||
| "plt.savefig(f\"{output_dir}/val_accuracy.png\")\n", | |||||
| "plt.close('all')\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": null, | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "data": { | |||||
| "application/vnd.jupyter.widget-view+json": { | |||||
| "model_id": "173d54ab994d4abda6e4f0897ad96c49", | |||||
| "version_major": 2, | |||||
| "version_minor": 0 | |||||
| }, | |||||
| "text/plain": [ | |||||
| "[1/9] 11%|#1 |it [00:00<?]" | |||||
| ] | |||||
| }, | |||||
| "metadata": {}, | |||||
| "output_type": "display_data" | |||||
| }, | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "Source acc: 0.868794322013855\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "data": { | |||||
| "application/vnd.jupyter.widget-view+json": { | |||||
| "model_id": "13b4a1ccc3b34456b68c73357d14bc21", | |||||
| "version_major": 2, | |||||
| "version_minor": 0 | |||||
| }, | |||||
| "text/plain": [ | |||||
| "[1/3] 33%|###3 |it [00:00<?]" | |||||
| ] | |||||
| }, | |||||
| "metadata": {}, | |||||
| "output_type": "display_data" | |||||
| }, | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "Target acc: 0.74842768907547\n", | |||||
| "---------\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "\n", | |||||
| "datasets = get_office31([source_domain], [target_domain], folder=args.data_root, return_target_with_labels=True)\n", | |||||
| "dc = DataloaderCreator(batch_size=args.batch_size, num_workers=args.num_workers, all_val=True)\n", | |||||
| "\n", | |||||
| "validator = AccuracyValidator(key_map={\"src_val\": \"src_val\"})\n", | |||||
| "src_score = trainer.evaluate_best_model(datasets, validator, dc)\n", | |||||
| "print(\"Source acc:\", src_score)\n", | |||||
| "\n", | |||||
| "validator = AccuracyValidator(key_map={\"target_val_with_labels\": \"src_val\"})\n", | |||||
| "target_score = trainer.evaluate_best_model(datasets, validator, dc)\n", | |||||
| "print(\"Target acc:\", target_score)\n", | |||||
| "print(\"---------\")" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": null, | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "C2 = copy.deepcopy(C) " | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 93, | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "cuda:0\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "source_domain = 'amazon'\n", | |||||
| "target_domain = 'webcam'\n", | |||||
| "G = office31G(pretrained=False).to(device)\n", | |||||
| "C = office31C(pretrained=False).to(device)\n", | |||||
| "\n", | |||||
| "\n", | |||||
| "optimizers = Optimizers((torch.optim.Adam, {\"lr\": 1e-4}))\n", | |||||
| "lr_schedulers = LRSchedulers((torch.optim.lr_scheduler.ExponentialLR, {\"gamma\": 0.99})) \n", | |||||
| "\n", | |||||
| "models = Models({\"G\": G, \"C\": C})\n", | |||||
| "adapter= ClassifierAdapter(models=models, optimizers=optimizers, lr_schedulers=lr_schedulers)\n", | |||||
| "\n", | |||||
| "\n", | |||||
| "output_dir = \"tmp\"\n", | |||||
| "checkpoint_fn = CheckpointFnCreator(dirname=f\"{output_dir}/saved_models\", require_empty=False)\n", | |||||
| "\n", | |||||
| "sourceAccuracyValidator = AccuracyValidator()\n", | |||||
| "val_hooks = [ScoreHistory(sourceAccuracyValidator)]\n", | |||||
| "\n", | |||||
| "new_trainer = Ignite(\n", | |||||
| " adapter, val_hooks=val_hooks, checkpoint_fn=checkpoint_fn, device=device\n", | |||||
| ")\n", | |||||
| "print(trainer.device)\n", | |||||
| "\n", | |||||
| "from pytorch_adapt.frameworks.ignite import (\n", | |||||
| " CheckpointFnCreator,\n", | |||||
| " IgniteValHookWrapper,\n", | |||||
| " checkpoint_utils,\n", | |||||
| ")\n", | |||||
| "\n", | |||||
| "objs = [\n", | |||||
| " {\n", | |||||
| " \"engine\": new_trainer.trainer,\n", | |||||
| " \"validator\": new_trainer.validator,\n", | |||||
| " \"val_hook0\": val_hooks[0],\n", | |||||
| " **checkpoint_utils.adapter_to_dict(new_trainer.adapter),\n", | |||||
| " }\n", | |||||
| " ]\n", | |||||
| " \n", | |||||
| "# best_score, best_epoch = trainer.run(\n", | |||||
| "# datasets, dataloader_creator=dc, max_epochs=args.max_epochs, early_stopper_kwargs=early_stopper_kwargs\n", | |||||
| "# )\n", | |||||
| "\n", | |||||
| "for to_load in objs:\n", | |||||
| " checkpoint_fn.load_best_checkpoint(to_load)\n", | |||||
| "\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 94, | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "data": { | |||||
| "application/vnd.jupyter.widget-view+json": { | |||||
| "model_id": "32f01ff7ea254739909e4567a133b00a", | |||||
| "version_major": 2, | |||||
| "version_minor": 0 | |||||
| }, | |||||
| "text/plain": [ | |||||
| "[1/9] 11%|#1 |it [00:00<?]" | |||||
| ] | |||||
| }, | |||||
| "metadata": {}, | |||||
| "output_type": "display_data" | |||||
| }, | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "Source acc: 0.868794322013855\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "data": { | |||||
| "application/vnd.jupyter.widget-view+json": { | |||||
| "model_id": "cef345c05e5e46eb9fc0e1cc40b02435", | |||||
| "version_major": 2, | |||||
| "version_minor": 0 | |||||
| }, | |||||
| "text/plain": [ | |||||
| "[1/3] 33%|###3 |it [00:00<?]" | |||||
| ] | |||||
| }, | |||||
| "metadata": {}, | |||||
| "output_type": "display_data" | |||||
| }, | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "Target acc: 0.74842768907547\n", | |||||
| "---------\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "\n", | |||||
| "datasets = get_office31([source_domain], [target_domain], folder=args.data_root, return_target_with_labels=True)\n", | |||||
| "dc = DataloaderCreator(batch_size=args.batch_size, num_workers=args.num_workers, all_val=True)\n", | |||||
| "\n", | |||||
| "validator = AccuracyValidator(key_map={\"src_val\": \"src_val\"})\n", | |||||
| "src_score = new_trainer.evaluate_best_model(datasets, validator, dc)\n", | |||||
| "print(\"Source acc:\", src_score)\n", | |||||
| "\n", | |||||
| "validator = AccuracyValidator(key_map={\"target_val_with_labels\": \"src_val\"})\n", | |||||
| "target_score = new_trainer.evaluate_best_model(datasets, validator, dc)\n", | |||||
| "print(\"Target acc:\", target_score)\n", | |||||
| "print(\"---------\")" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 89, | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "\n", | |||||
| "datasets = get_office31([source_domain], [target_domain],\n", | |||||
| " folder=args.data_root,\n", | |||||
| " return_target_with_labels=True,\n", | |||||
| " download=args.download)\n", | |||||
| " \n", | |||||
| "dc = DataloaderCreator(batch_size=args.batch_size,\n", | |||||
| " num_workers=args.num_workers,\n", | |||||
| " train_names=[\"train\"],\n", | |||||
| " val_names=[\"src_train\", \"target_train\", \"src_val\", \"target_val\",\n", | |||||
| " \"target_train_with_labels\", \"target_val_with_labels\"])\n", | |||||
| "\n", | |||||
| "G = new_trainer.adapter.models[\"G\"]\n", | |||||
| "C = new_trainer.adapter.models[\"C\"]\n", | |||||
| "D = Discriminator(in_size=2048, h=1024).to(device)\n", | |||||
| "\n", | |||||
| "optimizers = Optimizers((torch.optim.Adam, {\"lr\": 0.001}))\n", | |||||
| "lr_schedulers = LRSchedulers((torch.optim.lr_scheduler.ExponentialLR, {\"gamma\": 0.99}))\n", | |||||
| "# lr_schedulers = LRSchedulers((torch.optim.lr_scheduler.MultiStepLR, {\"milestones\": [2, 5, 10, 20, 40], \"gamma\": hp.gamma}))\n", | |||||
| "\n", | |||||
| "models = Models({\"G\": G, \"C\": C, \"D\": D})\n", | |||||
| "adapter = DANN(models=models, optimizers=optimizers, lr_schedulers=lr_schedulers)\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 90, | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "cuda:0\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "data": { | |||||
| "application/vnd.jupyter.widget-view+json": { | |||||
| "model_id": "bf490d18567444149070191e100f8c45", | |||||
| "version_major": 2, | |||||
| "version_minor": 0 | |||||
| }, | |||||
| "text/plain": [ | |||||
| "[1/3] 33%|###3 |it [00:00<?]" | |||||
| ] | |||||
| }, | |||||
| "metadata": {}, | |||||
| "output_type": "display_data" | |||||
| }, | |||||
| { | |||||
| "data": { | |||||
| "application/vnd.jupyter.widget-view+json": { | |||||
| "model_id": "525920fcd19d4178a4bada48932c8fb1", | |||||
| "version_major": 2, | |||||
| "version_minor": 0 | |||||
| }, | |||||
| "text/plain": [ | |||||
| "[1/9] 11%|#1 |it [00:00<?]" | |||||
| ] | |||||
| }, | |||||
| "metadata": {}, | |||||
| "output_type": "display_data" | |||||
| }, | |||||
| { | |||||
| "data": { | |||||
| "application/vnd.jupyter.widget-view+json": { | |||||
| "model_id": "bd1158f548e746cdab88d608b22ab65c", | |||||
| "version_major": 2, | |||||
| "version_minor": 0 | |||||
| }, | |||||
| "text/plain": [ | |||||
| "[1/9] 11%|#1 |it [00:00<?]" | |||||
| ] | |||||
| }, | |||||
| "metadata": {}, | |||||
| "output_type": "display_data" | |||||
| }, | |||||
| { | |||||
| "data": { | |||||
| "application/vnd.jupyter.widget-view+json": { | |||||
| "model_id": "196fa120037b48fdb4e9a879e7e7c79b", | |||||
| "version_major": 2, | |||||
| "version_minor": 0 | |||||
| }, | |||||
| "text/plain": [ | |||||
| "[1/3] 33%|###3 |it [00:00<?]" | |||||
| ] | |||||
| }, | |||||
| "metadata": {}, | |||||
| "output_type": "display_data" | |||||
| }, | |||||
| { | |||||
| "data": { | |||||
| "application/vnd.jupyter.widget-view+json": { | |||||
| "model_id": "6795edb658a84309b1a03bcea6a24643", | |||||
| "version_major": 2, | |||||
| "version_minor": 0 | |||||
| }, | |||||
| "text/plain": [ | |||||
| "[1/9] 11%|#1 |it [00:00<?]" | |||||
| ] | |||||
| }, | |||||
| "metadata": {}, | |||||
| "output_type": "display_data" | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "\n", | |||||
| "output_dir = \"tmp\"\n", | |||||
| "checkpoint_fn = CheckpointFnCreator(dirname=f\"{output_dir}/saved_models\", require_empty=False)\n", | |||||
| "\n", | |||||
| "sourceAccuracyValidator = AccuracyValidator()\n", | |||||
| "targetAccuracyValidator = AccuracyValidator(key_map={\"target_val_with_labels\": \"src_val\"})\n", | |||||
| "val_hooks = [ScoreHistory(sourceAccuracyValidator), ScoreHistory(targetAccuracyValidator)]\n", | |||||
| "\n", | |||||
| "trainer = Ignite(\n", | |||||
| " adapter, val_hooks=val_hooks, device=device\n", | |||||
| ")\n", | |||||
| "print(trainer.device)\n", | |||||
| "\n", | |||||
| "best_score, best_epoch = trainer.run(\n", | |||||
| " datasets, dataloader_creator=dc, max_epochs=args.max_epochs, early_stopper_kwargs=early_stopper_kwargs, check_initial_score=True\n", | |||||
| ")\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 91, | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "data": { | |||||
| "text/plain": [ | |||||
| "ScoreHistory(\n", | |||||
| " validator=AccuracyValidator(required_data=['src_val'])\n", | |||||
| " latest_score=0.30319148302078247\n", | |||||
| " best_score=0.868794322013855\n", | |||||
| " best_epoch=0\n", | |||||
| ")" | |||||
| ] | |||||
| }, | |||||
| "execution_count": 91, | |||||
| "metadata": {}, | |||||
| "output_type": "execute_result" | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "val_hooks[0]" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 92, | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "data": { | |||||
| "text/plain": [ | |||||
| "ScoreHistory(\n", | |||||
| " validator=AccuracyValidator(required_data=['target_val_with_labels'])\n", | |||||
| " latest_score=0.2515723407268524\n", | |||||
| " best_score=0.74842768907547\n", | |||||
| " best_epoch=0\n", | |||||
| ")" | |||||
| ] | |||||
| }, | |||||
| "execution_count": 92, | |||||
| "metadata": {}, | |||||
| "output_type": "execute_result" | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "val_hooks[1]" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 86, | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "del trainer" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 87, | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "data": { | |||||
| "text/plain": [ | |||||
| "21169" | |||||
| ] | |||||
| }, | |||||
| "execution_count": 87, | |||||
| "metadata": {}, | |||||
| "output_type": "execute_result" | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "import gc\n", | |||||
| "gc.collect()" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 88, | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "torch.cuda.empty_cache()" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 95, | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "args.vishook_frequency = 133" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 96, | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "data": { | |||||
| "text/plain": [ | |||||
| "Namespace(batch_size=64, data_root='./datasets/pytorch-adapt/', download=False, gamma=0.99, hp_tune=False, initial_trial=0, lr=0.0001, max_epochs=1, model_names=['DANN'], num_workers=1, patience=2, results_root='./results/', root='./', source=None, target=None, trials_count=1, vishook_frequency=133)" | |||||
| ] | |||||
| }, | |||||
| "execution_count": 96, | |||||
| "metadata": {}, | |||||
| "output_type": "execute_result" | |||||
| }, | |||||
| { | |||||
| "ename": "", | |||||
| "evalue": "", | |||||
| "output_type": "error", | |||||
| "traceback": [ | |||||
| "\u001b[1;31mThe Kernel crashed while executing code in the the current cell or a previous cell. Please review the code in the cell(s) to identify a possible cause of the failure. Click <a href='https://aka.ms/vscodeJupyterKernelCrash'>here</a> for more info. View Jupyter <a href='command:jupyter.viewOutput'>log</a> for further details." | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "args" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": null, | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [] | |||||
| }, | |||||
| { | |||||
| "attachments": {}, | |||||
| "cell_type": "markdown", | |||||
| "metadata": {}, | |||||
| "source": [ | |||||
| "-----" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 3, | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "path = \"/media/10TB71/shashemi/Domain-Adaptation/results/DAModels.CDAN/2000/a2d/saved_models\"" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 5, | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "source_domain = 'amazon'\n", | |||||
| "target_domain = 'dslr'\n", | |||||
| "G = office31G(pretrained=False).to(device)\n", | |||||
| "C = office31C(pretrained=False).to(device)\n", | |||||
| "\n", | |||||
| "\n", | |||||
| "optimizers = Optimizers((torch.optim.Adam, {\"lr\": 1e-4}))\n", | |||||
| "lr_schedulers = LRSchedulers((torch.optim.lr_scheduler.ExponentialLR, {\"gamma\": 0.99})) \n", | |||||
| "\n", | |||||
| "models = Models({\"G\": G, \"C\": C})\n", | |||||
| "adapter= ClassifierAdapter(models=models, optimizers=optimizers, lr_schedulers=lr_schedulers)\n", | |||||
| "\n", | |||||
| "\n", | |||||
| "output_dir = \"tmp\"\n", | |||||
| "checkpoint_fn = CheckpointFnCreator(dirname=f\"{output_dir}/saved_models\", require_empty=False)\n", | |||||
| "\n", | |||||
| "sourceAccuracyValidator = AccuracyValidator()\n", | |||||
| "val_hooks = [ScoreHistory(sourceAccuracyValidator)]\n", | |||||
| "\n", | |||||
| "new_trainer = Ignite(\n", | |||||
| " adapter, val_hooks=val_hooks, checkpoint_fn=checkpoint_fn, device=device\n", | |||||
| ")\n", | |||||
| "\n", | |||||
| "from pytorch_adapt.frameworks.ignite import (\n", | |||||
| " CheckpointFnCreator,\n", | |||||
| " IgniteValHookWrapper,\n", | |||||
| " checkpoint_utils,\n", | |||||
| ")\n", | |||||
| "\n", | |||||
| "objs = [\n", | |||||
| " {\n", | |||||
| " \"engine\": new_trainer.trainer,\n", | |||||
| " \"validator\": new_trainer.validator,\n", | |||||
| " \"val_hook0\": val_hooks[0],\n", | |||||
| " **checkpoint_utils.adapter_to_dict(new_trainer.adapter),\n", | |||||
| " }\n", | |||||
| " ]\n", | |||||
| " \n", | |||||
| "# best_score, best_epoch = trainer.run(\n", | |||||
| "# datasets, dataloader_creator=dc, max_epochs=args.max_epochs, early_stopper_kwargs=early_stopper_kwargs\n", | |||||
| "# )\n", | |||||
| "\n", | |||||
| "for to_load in objs:\n", | |||||
| " checkpoint_fn.load_best_checkpoint(to_load)\n", | |||||
| "\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 6, | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "data": { | |||||
| "application/vnd.jupyter.widget-view+json": { | |||||
| "model_id": "926966dd640e4979ade6a45cf0fcdd49", | |||||
| "version_major": 2, | |||||
| "version_minor": 0 | |||||
| }, | |||||
| "text/plain": [ | |||||
| "[1/9] 11%|#1 |it [00:00<?]" | |||||
| ] | |||||
| }, | |||||
| "metadata": {}, | |||||
| "output_type": "display_data" | |||||
| }, | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "Source acc: 0.868794322013855\n" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "data": { | |||||
| "application/vnd.jupyter.widget-view+json": { | |||||
| "model_id": "64cd5cfb052c4f52af9af1a63a4c0087", | |||||
| "version_major": 2, | |||||
| "version_minor": 0 | |||||
| }, | |||||
| "text/plain": [ | |||||
| "[1/2] 50%|##### |it [00:00<?]" | |||||
| ] | |||||
| }, | |||||
| "metadata": {}, | |||||
| "output_type": "display_data" | |||||
| }, | |||||
| { | |||||
| "name": "stdout", | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "Target acc: 0.7200000286102295\n", | |||||
| "---------\n" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "\n", | |||||
| "datasets = get_office31([source_domain], [target_domain], folder=args.data_root, return_target_with_labels=True)\n", | |||||
| "dc = DataloaderCreator(batch_size=args.batch_size, num_workers=args.num_workers, all_val=True)\n", | |||||
| "\n", | |||||
| "validator = AccuracyValidator(key_map={\"src_val\": \"src_val\"})\n", | |||||
| "src_score = new_trainer.evaluate_best_model(datasets, validator, dc)\n", | |||||
| "print(\"Source acc:\", src_score)\n", | |||||
| "\n", | |||||
| "validator = AccuracyValidator(key_map={\"target_val_with_labels\": \"src_val\"})\n", | |||||
| "target_score = new_trainer.evaluate_best_model(datasets, validator, dc)\n", | |||||
| "print(\"Target acc:\", target_score)\n", | |||||
| "print(\"---------\")" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 10, | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "source_domain = 'amazon'\n", | |||||
| "target_domain = 'dslr'\n", | |||||
| "G = new_trainer.adapter.models[\"G\"]\n", | |||||
| "C = new_trainer.adapter.models[\"C\"]\n", | |||||
| "\n", | |||||
| "G.fc = C.net[:6]\n", | |||||
| "C.net = C.net[6:]\n", | |||||
| "\n", | |||||
| "\n", | |||||
| "optimizers = Optimizers((torch.optim.Adam, {\"lr\": 1e-4}))\n", | |||||
| "lr_schedulers = LRSchedulers((torch.optim.lr_scheduler.ExponentialLR, {\"gamma\": 0.99})) \n", | |||||
| "\n", | |||||
| "models = Models({\"G\": G, \"C\": C})\n", | |||||
| "adapter= ClassifierAdapter(models=models, optimizers=optimizers, lr_schedulers=lr_schedulers)\n", | |||||
| "\n", | |||||
| "\n", | |||||
| "output_dir = \"tmp\"\n", | |||||
| "checkpoint_fn = CheckpointFnCreator(dirname=f\"{output_dir}/saved_models\", require_empty=False)\n", | |||||
| "\n", | |||||
| "sourceAccuracyValidator = AccuracyValidator()\n", | |||||
| "val_hooks = [ScoreHistory(sourceAccuracyValidator)]\n", | |||||
| "\n", | |||||
| "more_new_trainer = Ignite(\n", | |||||
| " adapter, val_hooks=val_hooks, checkpoint_fn=checkpoint_fn, device=device\n", | |||||
| ")" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 13, | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [ | |||||
| "from pytorch_adapt.hooks import FeaturesAndLogitsHook\n", | |||||
| "\n", | |||||
| "h1 = FeaturesAndLogitsHook()" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": 19, | |||||
| "metadata": {}, | |||||
| "outputs": [ | |||||
| { | |||||
| "ename": "KeyError", | |||||
| "evalue": "in FeaturesAndLogitsHook: __call__\nin FeaturesHook: __call__\nFeaturesHook: Getting src\nFeaturesHook: Getting output: ['src_imgs_features']\nFeaturesHook: Using model G with inputs: src_imgs\nG", | |||||
| "output_type": "error", | |||||
| "traceback": [ | |||||
| "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m", | |||||
| "\u001b[0;31mKeyError\u001b[0m Traceback (most recent call last)", | |||||
| "Cell \u001b[0;32mIn[19], line 1\u001b[0m\n\u001b[0;32m----> 1\u001b[0m h1(datasets)\n", | |||||
| "File \u001b[0;32m/media/10TB71/shashemi/miniconda3/envs/cdtrans/lib/python3.8/site-packages/pytorch_adapt/hooks/base.py:52\u001b[0m, in \u001b[0;36mBaseHook.__call__\u001b[0;34m(self, inputs, losses)\u001b[0m\n\u001b[1;32m 50\u001b[0m \u001b[39mtry\u001b[39;00m:\n\u001b[1;32m 51\u001b[0m inputs \u001b[39m=\u001b[39m c_f\u001b[39m.\u001b[39mmap_keys(inputs, \u001b[39mself\u001b[39m\u001b[39m.\u001b[39mkey_map)\n\u001b[0;32m---> 52\u001b[0m x \u001b[39m=\u001b[39m \u001b[39mself\u001b[39;49m\u001b[39m.\u001b[39;49mcall(inputs, losses)\n\u001b[1;32m 53\u001b[0m \u001b[39mif\u001b[39;00m \u001b[39misinstance\u001b[39m(x, (\u001b[39mbool\u001b[39m, np\u001b[39m.\u001b[39mbool_)):\n\u001b[1;32m 54\u001b[0m \u001b[39mself\u001b[39m\u001b[39m.\u001b[39mlogger\u001b[39m.\u001b[39mreset()\n", | |||||
| "File \u001b[0;32m/media/10TB71/shashemi/miniconda3/envs/cdtrans/lib/python3.8/site-packages/pytorch_adapt/hooks/utils.py:109\u001b[0m, in \u001b[0;36mChainHook.call\u001b[0;34m(self, inputs, losses)\u001b[0m\n\u001b[1;32m 107\u001b[0m all_losses \u001b[39m=\u001b[39m {\u001b[39m*\u001b[39m\u001b[39m*\u001b[39mall_losses, \u001b[39m*\u001b[39m\u001b[39m*\u001b[39mprev_losses}\n\u001b[1;32m 108\u001b[0m \u001b[39mif\u001b[39;00m \u001b[39mself\u001b[39m\u001b[39m.\u001b[39mconditions[i](all_inputs, all_losses):\n\u001b[0;32m--> 109\u001b[0m x \u001b[39m=\u001b[39m h(all_inputs, all_losses)\n\u001b[1;32m 110\u001b[0m \u001b[39melse\u001b[39;00m:\n\u001b[1;32m 111\u001b[0m x \u001b[39m=\u001b[39m \u001b[39mself\u001b[39m\u001b[39m.\u001b[39malts[i](all_inputs, all_losses)\n", | |||||
| "File \u001b[0;32m/media/10TB71/shashemi/miniconda3/envs/cdtrans/lib/python3.8/site-packages/pytorch_adapt/hooks/base.py:52\u001b[0m, in \u001b[0;36mBaseHook.__call__\u001b[0;34m(self, inputs, losses)\u001b[0m\n\u001b[1;32m 50\u001b[0m \u001b[39mtry\u001b[39;00m:\n\u001b[1;32m 51\u001b[0m inputs \u001b[39m=\u001b[39m c_f\u001b[39m.\u001b[39mmap_keys(inputs, \u001b[39mself\u001b[39m\u001b[39m.\u001b[39mkey_map)\n\u001b[0;32m---> 52\u001b[0m x \u001b[39m=\u001b[39m \u001b[39mself\u001b[39;49m\u001b[39m.\u001b[39;49mcall(inputs, losses)\n\u001b[1;32m 53\u001b[0m \u001b[39mif\u001b[39;00m \u001b[39misinstance\u001b[39m(x, (\u001b[39mbool\u001b[39m, np\u001b[39m.\u001b[39mbool_)):\n\u001b[1;32m 54\u001b[0m \u001b[39mself\u001b[39m\u001b[39m.\u001b[39mlogger\u001b[39m.\u001b[39mreset()\n", | |||||
| "File \u001b[0;32m/media/10TB71/shashemi/miniconda3/envs/cdtrans/lib/python3.8/site-packages/pytorch_adapt/hooks/features.py:80\u001b[0m, in \u001b[0;36mBaseFeaturesHook.call\u001b[0;34m(self, inputs, losses)\u001b[0m\n\u001b[1;32m 78\u001b[0m func \u001b[39m=\u001b[39m \u001b[39mself\u001b[39m\u001b[39m.\u001b[39mmode_detached \u001b[39mif\u001b[39;00m detach \u001b[39melse\u001b[39;00m \u001b[39mself\u001b[39m\u001b[39m.\u001b[39mmode_with_grad\n\u001b[1;32m 79\u001b[0m in_keys \u001b[39m=\u001b[39m c_f\u001b[39m.\u001b[39mfilter(\u001b[39mself\u001b[39m\u001b[39m.\u001b[39min_keys, \u001b[39mf\u001b[39m\u001b[39m\"\u001b[39m\u001b[39m^\u001b[39m\u001b[39m{\u001b[39;00mdomain\u001b[39m}\u001b[39;00m\u001b[39m\"\u001b[39m)\n\u001b[0;32m---> 80\u001b[0m func(inputs, outputs, domain, in_keys)\n\u001b[1;32m 82\u001b[0m \u001b[39mself\u001b[39m\u001b[39m.\u001b[39mcheck_outputs_requires_grad(outputs)\n\u001b[1;32m 83\u001b[0m \u001b[39mreturn\u001b[39;00m outputs, {}\n", | |||||
| "File \u001b[0;32m/media/10TB71/shashemi/miniconda3/envs/cdtrans/lib/python3.8/site-packages/pytorch_adapt/hooks/features.py:106\u001b[0m, in \u001b[0;36mBaseFeaturesHook.mode_with_grad\u001b[0;34m(self, inputs, outputs, domain, in_keys)\u001b[0m\n\u001b[1;32m 104\u001b[0m output_keys \u001b[39m=\u001b[39m c_f\u001b[39m.\u001b[39mfilter(\u001b[39mself\u001b[39m\u001b[39m.\u001b[39m_out_keys(), \u001b[39mf\u001b[39m\u001b[39m\"\u001b[39m\u001b[39m^\u001b[39m\u001b[39m{\u001b[39;00mdomain\u001b[39m}\u001b[39;00m\u001b[39m\"\u001b[39m)\n\u001b[1;32m 105\u001b[0m output_vals \u001b[39m=\u001b[39m \u001b[39mself\u001b[39m\u001b[39m.\u001b[39mget_kwargs(inputs, output_keys)\n\u001b[0;32m--> 106\u001b[0m \u001b[39mself\u001b[39;49m\u001b[39m.\u001b[39;49madd_if_new(\n\u001b[1;32m 107\u001b[0m outputs, output_keys, output_vals, inputs, \u001b[39mself\u001b[39;49m\u001b[39m.\u001b[39;49mmodel_name, in_keys, domain\n\u001b[1;32m 108\u001b[0m )\n\u001b[1;32m 109\u001b[0m \u001b[39mreturn\u001b[39;00m output_keys, output_vals\n", | |||||
| "File \u001b[0;32m/media/10TB71/shashemi/miniconda3/envs/cdtrans/lib/python3.8/site-packages/pytorch_adapt/hooks/features.py:133\u001b[0m, in \u001b[0;36mBaseFeaturesHook.add_if_new\u001b[0;34m(self, outputs, full_key, output_vals, inputs, model_name, in_keys, domain)\u001b[0m\n\u001b[1;32m 130\u001b[0m \u001b[39mdef\u001b[39;00m \u001b[39madd_if_new\u001b[39m(\n\u001b[1;32m 131\u001b[0m \u001b[39mself\u001b[39m, outputs, full_key, output_vals, inputs, model_name, in_keys, domain\n\u001b[1;32m 132\u001b[0m ):\n\u001b[0;32m--> 133\u001b[0m c_f\u001b[39m.\u001b[39;49madd_if_new(\n\u001b[1;32m 134\u001b[0m outputs,\n\u001b[1;32m 135\u001b[0m full_key,\n\u001b[1;32m 136\u001b[0m output_vals,\n\u001b[1;32m 137\u001b[0m inputs,\n\u001b[1;32m 138\u001b[0m model_name,\n\u001b[1;32m 139\u001b[0m in_keys,\n\u001b[1;32m 140\u001b[0m logger\u001b[39m=\u001b[39;49m\u001b[39mself\u001b[39;49m\u001b[39m.\u001b[39;49mlogger,\n\u001b[1;32m 141\u001b[0m )\n", | |||||
| "File \u001b[0;32m/media/10TB71/shashemi/miniconda3/envs/cdtrans/lib/python3.8/site-packages/pytorch_adapt/utils/common_functions.py:96\u001b[0m, in \u001b[0;36madd_if_new\u001b[0;34m(d, key, x, kwargs, model_name, in_keys, other_args, logger)\u001b[0m\n\u001b[1;32m 94\u001b[0m condition \u001b[39m=\u001b[39m is_none\n\u001b[1;32m 95\u001b[0m \u001b[39mif\u001b[39;00m \u001b[39many\u001b[39m(condition(y) \u001b[39mfor\u001b[39;00m y \u001b[39min\u001b[39;00m x):\n\u001b[0;32m---> 96\u001b[0m model \u001b[39m=\u001b[39m kwargs[model_name]\n\u001b[1;32m 97\u001b[0m input_vals \u001b[39m=\u001b[39m [kwargs[k] \u001b[39mfor\u001b[39;00m k \u001b[39min\u001b[39;00m in_keys] \u001b[39m+\u001b[39m \u001b[39mlist\u001b[39m(other_args\u001b[39m.\u001b[39mvalues())\n\u001b[1;32m 98\u001b[0m new_x \u001b[39m=\u001b[39m try_use_model(model, model_name, input_vals)\n", | |||||
| "\u001b[0;31mKeyError\u001b[0m: in FeaturesAndLogitsHook: __call__\nin FeaturesHook: __call__\nFeaturesHook: Getting src\nFeaturesHook: Getting output: ['src_imgs_features']\nFeaturesHook: Using model G with inputs: src_imgs\nG" | |||||
| ] | |||||
| } | |||||
| ], | |||||
| "source": [ | |||||
| "h1(datasets)" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "execution_count": null, | |||||
| "metadata": {}, | |||||
| "outputs": [], | |||||
| "source": [] | |||||
| } | |||||
| ], | |||||
| "metadata": { | |||||
| "kernelspec": { | |||||
| "display_name": "cdtrans", | |||||
| "language": "python", | |||||
| "name": "python3" | |||||
| }, | |||||
| "language_info": { | |||||
| "codemirror_mode": { | |||||
| "name": "ipython", | |||||
| "version": 3 | |||||
| }, | |||||
| "file_extension": ".py", | |||||
| "mimetype": "text/x-python", | |||||
| "name": "python", | |||||
| "nbconvert_exporter": "python", | |||||
| "pygments_lexer": "ipython3", | |||||
| "version": "3.8.15 (default, Nov 24 2022, 15:19:38) \n[GCC 11.2.0]" | |||||
| }, | |||||
| "orig_nbformat": 4, | |||||
| "vscode": { | |||||
| "interpreter": { | |||||
| "hash": "959b82c3a41427bdf7d14d4ba7335271e0c50cfcddd70501934b27dcc36968ad" | |||||
| } | |||||
| } | |||||
| }, | |||||
| "nbformat": 4, | |||||
| "nbformat_minor": 2 | |||||
| } |
BIN
visualizations/domain-images-count.jpg
View File
{kind=link}
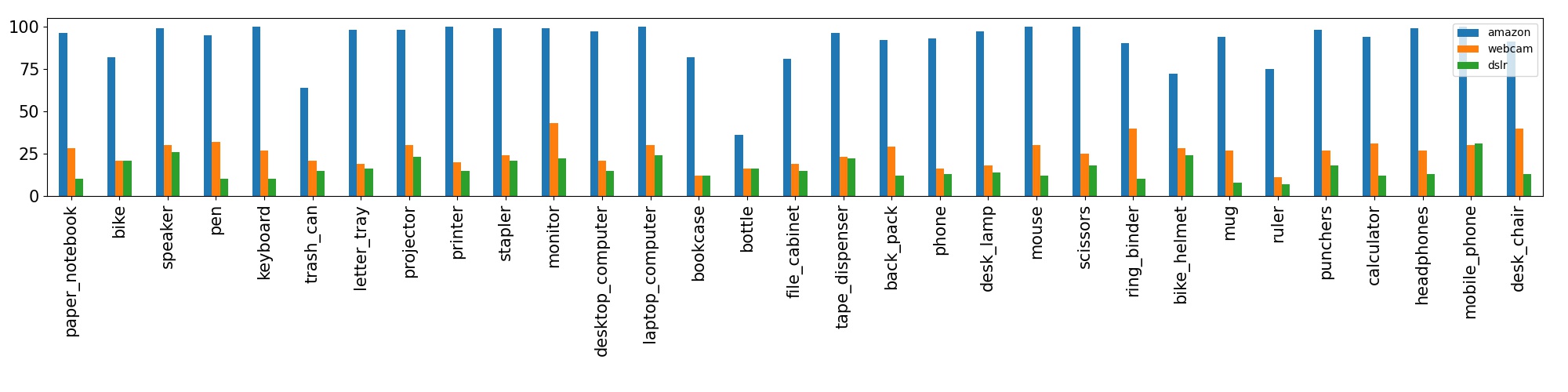
+ 101
- 0
visualizations/domain-images-count.txt
View File
| { | |||||
| "amazon": { | |||||
| "back_pack": 92, | |||||
| "bike": 82, | |||||
| "bike_helmet": 72, | |||||
| "bookcase": 82, | |||||
| "bottle": 36, | |||||
| "calculator": 94, | |||||
| "desk_chair": 91, | |||||
| "desk_lamp": 97, | |||||
| "desktop_computer": 97, | |||||
| "file_cabinet": 81, | |||||
| "headphones": 99, | |||||
| "keyboard": 100, | |||||
| "laptop_computer": 100, | |||||
| "letter_tray": 98, | |||||
| "mobile_phone": 100, | |||||
| "monitor": 99, | |||||
| "mouse": 100, | |||||
| "mug": 94, | |||||
| "paper_notebook": 96, | |||||
| "pen": 95, | |||||
| "phone": 93, | |||||
| "printer": 100, | |||||
| "projector": 98, | |||||
| "punchers": 98, | |||||
| "ring_binder": 90, | |||||
| "ruler": 75, | |||||
| "scissors": 100, | |||||
| "speaker": 99, | |||||
| "stapler": 99, | |||||
| "tape_dispenser": 96, | |||||
| "trash_can": 64 | |||||
| }, | |||||
| "dslr": { | |||||
| "back_pack": 12, | |||||
| "bike": 21, | |||||
| "bike_helmet": 24, | |||||
| "bookcase": 12, | |||||
| "bottle": 16, | |||||
| "calculator": 12, | |||||
| "desk_chair": 13, | |||||
| "desk_lamp": 14, | |||||
| "desktop_computer": 15, | |||||
| "file_cabinet": 15, | |||||
| "headphones": 13, | |||||
| "keyboard": 10, | |||||
| "laptop_computer": 24, | |||||
| "letter_tray": 16, | |||||
| "mobile_phone": 31, | |||||
| "monitor": 22, | |||||
| "mouse": 12, | |||||
| "mug": 8, | |||||
| "paper_notebook": 10, | |||||
| "pen": 10, | |||||
| "phone": 13, | |||||
| "printer": 15, | |||||
| "projector": 23, | |||||
| "punchers": 18, | |||||
| "ring_binder": 10, | |||||
| "ruler": 7, | |||||
| "scissors": 18, | |||||
| "speaker": 26, | |||||
| "stapler": 21, | |||||
| "tape_dispenser": 22, | |||||
| "trash_can": 15 | |||||
| }, | |||||
| "webcam": { | |||||
| "back_pack": 29, | |||||
| "bike": 21, | |||||
| "bike_helmet": 28, | |||||
| "bookcase": 12, | |||||
| "bottle": 16, | |||||
| "calculator": 31, | |||||
| "desk_chair": 40, | |||||
| "desk_lamp": 18, | |||||
| "desktop_computer": 21, | |||||
| "file_cabinet": 19, | |||||
| "headphones": 27, | |||||
| "keyboard": 27, | |||||
| "laptop_computer": 30, | |||||
| "letter_tray": 19, | |||||
| "mobile_phone": 30, | |||||
| "monitor": 43, | |||||
| "mouse": 30, | |||||
| "mug": 27, | |||||
| "paper_notebook": 28, | |||||
| "pen": 32, | |||||
| "phone": 16, | |||||
| "printer": 20, | |||||
| "projector": 30, | |||||
| "punchers": 27, | |||||
| "ring_binder": 40, | |||||
| "ruler": 11, | |||||
| "scissors": 25, | |||||
| "speaker": 30, | |||||
| "stapler": 24, | |||||
| "tape_dispenser": 23, | |||||
| "trash_can": 21 | |||||
| } | |||||
| } |
BIN
visualizations/domain-total-count.jpg
View File
{kind=link}
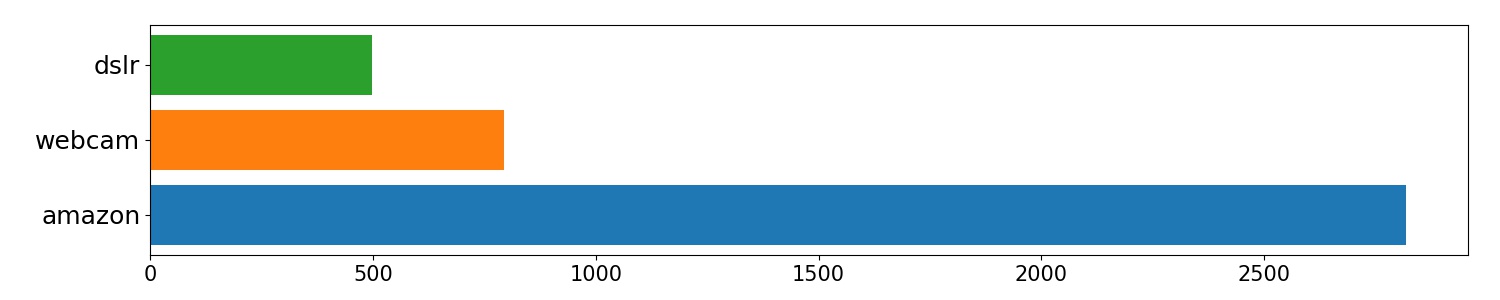
+ 5
- 0
visualizations/domain-total-count.txt
View File
| { | |||||
| "amazon": 2817, | |||||
| "dslr": 498, | |||||
| "webcam": 795 | |||||
| } |
BIN
visualizations/office-31-10_classes_complete_dataset.png
View File
{kind=link}
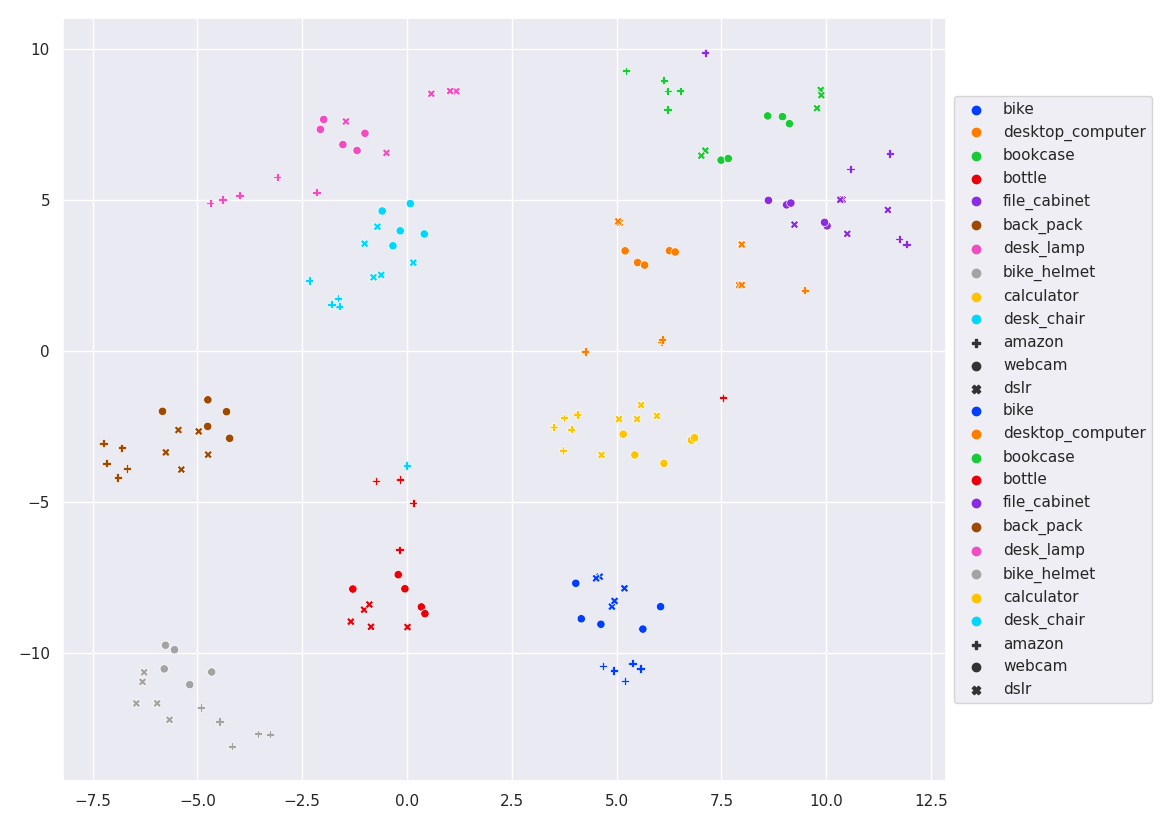
BIN
visualizations/office-31-3_classes_complete_dataset.png
View File
{kind=link}
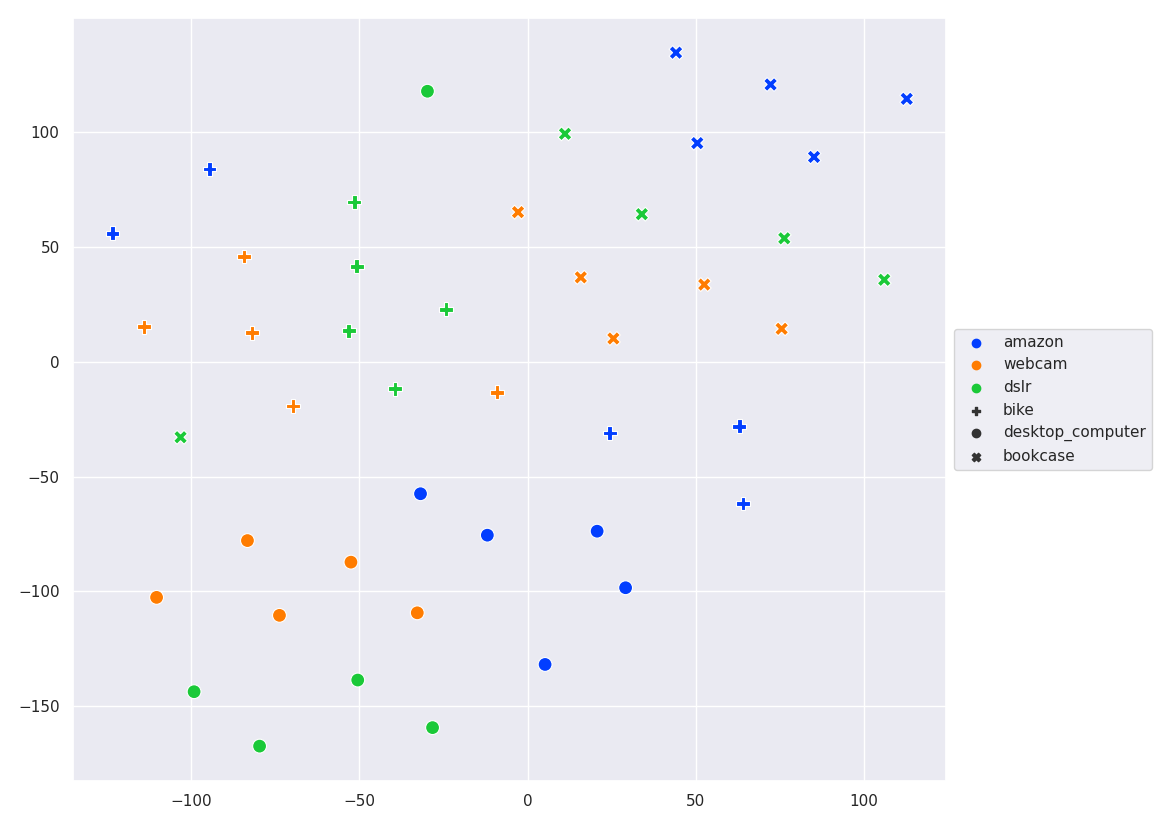
BIN
visualizations/office-31-3_classes_complete_dataset_resnet.png
View File
{kind=link}
BIN
visualizations/office-31-3_classes_complete_dataset_resnet_untrained.png
View File
{kind=link}
BIN
visualizations/office-31-3_classes_complete_dataset_resnet_untrained_100.png
View File
{kind=link}
Loading…