
commit
441a4583c3
100 changed files with 257537 additions and 0 deletions
BIN
Presentation/My Seminar - Version 3.pdf
View File
BIN
Presentation/My Seminar - Version 3.pptx
View File
BIN
Presentation/Thesis final presentation (Finalest Final).pdf
View File
BIN
Presentation/Thesis final presentation (Finalest Final).pptx
View File
+ 0
- 0
Readme.md
View File
BIN
Refrences/1- Online Display Advertising Markets - A Literature Review and Future Directions.pdf
View File
BIN
Refrences/10- Gradient-Based Learning Applied to Document Recognition.pdf
View File
BIN
Refrences/11- A limited memory BFGS-type method for large-scale unconstrained optimization.pdf
View File
BIN
Refrences/12- Web-Scale Bayesian CTR Prediction for Sponsored Search Advertising in Microsoft's Bing Search Engine.pdf
View File
BIN
Refrences/13- Factorization Machines.pdf
View File
BIN
Refrences/14- Field-aware Factorization Machines for CTR Prediction.pdf
View File
BIN
Refrences/15- Field Aware Factorization Machines in a Real-world Online Advertising System.pdf
View File
BIN
Refrences/16- Field-weighted Factorization Machines for Click-Through Rate Prediction in Display Advertising.pdf
View File
BIN
Refrences/17- Bayesian Factorization Machines.pdf
View File
BIN
Refrences/18- Sparse Factorization Machines for Click-through Rate Prediction.pdf
View File
BIN
Refrences/19- Attentional Factorization Machines; Learning the Weight of Feature Interactions via Attention Networks.pdf
View File
BIN
Refrences/2- A Survey on Real Time Bidding Advertising .pdf
View File
BIN
Refrences/20- Dropout; A Simple Way to Prevent Neural Networks from Overfitting.pdf
View File
BIN
Refrences/22- Deep Learning based Recommender System A Survey and new prespectives.pdf
View File
BIN
Refrences/23- Deep CTR Prediction in Display Advertising.pdf
View File
BIN
Refrences/24- Deep Residual Learning for Image Recognition.pdf
View File
BIN
Refrences/25- Rectifed linear units improve restricted Boltzmann Machines.pdf
View File
BIN
Refrences/26- Entity Embeddings of Categorical Variables.pdf
View File
BIN
Refrences/27- Batch Normalization; Accelerating Deep Network Training by Reducing Internal Covariate Shift.pdf
View File
BIN
Refrences/28- DeepFM; A Factorization-Machine based Neural Network for CTR Prediction.pdf
View File
BIN
Refrences/29- DeepFM; An End-to-End Wide & Deep Learning Framework for CTR Prediction.pdf
View File
BIN
Refrences/3- Revenue Models for Demand Side Platforms in Real Time Bidding Advertising.pdf
View File
BIN
Refrences/30- Wide & Deep Learning for Recommender Systems.pdf
View File
BIN
Refrences/31- A New Approach for Advertising CTR Prediction Based on Deep Neural Network via Attention Mechanism.pdf
View File
BIN
Refrences/32- Modular Learning in Neural Networks.pdf
View File
BIN
Refrences/33- The Mathematical Theory of Communication.pdf
View File
BIN
Refrences/34- On the Dimensionality of Embeddings for Sparse Features and Data.pdf
View File
BIN
Refrences/35- Mixed Dimension Embeddings with Application to Memory-Efficient Recommendation Systems.pdf
View File
BIN
Refrences/36- Neural Collaborative Filtering.pdf
View File
BIN
Refrences/37- Rectifier Nonlinearities Improve Neural Network Acoustic Models.pdf
View File
BIN
Refrences/38- Visualizing Data using t-SNE.pdf
View File
BIN
Refrences/4- Class Imbalance Problem.pdf
View File
+ 215396
- 0
Refrences/4- Encyclopedia of Machine Learning adn Data Mining.pdf
File diff suppressed because it is too large
View File
BIN
Refrences/5- High dimensionality; The latest challenge to data analysis.pdf
View File
BIN
Refrences/6- Facing the cold start problem in recommender systems.pdf
View File
BIN
Refrences/7- Solving the Cold-Start Problem in Recommender Systems with Social Tags.pdf
View File
BIN
Refrences/8- A Training Algorithm for Optimal Margin Classifiers.pdf
View File
BIN
Refrences/9- Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction.pdf
View File
+ 447
- 0
Thesis/IEEEabrv.bib
View File
| IEEEabrv.bib | |||||
| V1.12 (2007/01/11) | |||||
| Copyright (c) 2002-2007 by Michael Shell | |||||
| See: http://www.michaelshell.org/ | |||||
| for current contact information. | |||||
| BibTeX bibliography string definitions of the ABBREVIATED titles of | |||||
| IEEE journals and magazines and online publications. | |||||
| This file is designed for bibliography styles that require | |||||
| abbreviated titles and is not for use in bibliographies that | |||||
| require full-length titles. | |||||
| Support sites: | |||||
| http://www.michaelshell.org/tex/ieeetran/ | |||||
| http://www.ctan.org/tex-archive/macros/latex/contrib/IEEEtran/ | |||||
| and/or | |||||
| http://www.ieee.org/ | |||||
| Special thanks to Laura Hyslop and ken Rawson of IEEE for their help | |||||
| in obtaining the information needed to compile this file. Also, | |||||
| Volker Kuhlmann and Moritz Borgmann kindly provided some corrections | |||||
| and additions. | |||||
| ************************************************************************* | |||||
| Legal Notice: | |||||
| This code is offered as-is without any warranty either expressed or | |||||
| implied; without even the implied warranty of MERCHANTABILITY or | |||||
| FITNESS FOR A PARTICULAR PURPOSE! | |||||
| User assumes all risk. | |||||
| In no event shall IEEE or any contributor to this code be liable for | |||||
| any damages or losses, including, but not limited to, incidental, | |||||
| consequential, or any other damages, resulting from the use or misuse | |||||
| of any information contained here. | |||||
| All comments are the opinions of their respective authors and are not | |||||
| necessarily endorsed by the IEEE. | |||||
| This work is distributed under the LaTeX Project Public License (LPPL) | |||||
| ( http://www.latex-project.org/ ) version 1.3, and may be freely used, | |||||
| distributed and modified. A copy of the LPPL, version 1.3, is included | |||||
| in the base LaTeX documentation of all distributions of LaTeX released | |||||
| 2003/12/01 or later. | |||||
| Retain all contribution notices and credits. | |||||
| ** Modified files should be clearly indicated as such, including ** | |||||
| ** renaming them and changing author support contact information. ** | |||||
| File list of work: IEEEabrv.bib, IEEEfull.bib, IEEEexample.bib, | |||||
| IEEEtran.bst, IEEEtranS.bst, IEEEtranSA.bst, | |||||
| IEEEtranN.bst, IEEEtranSN.bst, IEEEtran_bst_HOWTO.pdf | |||||
| ************************************************************************* | |||||
| USAGE: | |||||
| \bibliographystyle{mybstfile} | |||||
| \bibliography{IEEEabrv,mybibfile} | |||||
| where the IEEE titles in the .bib database entries use the strings | |||||
| defined here. e.g., | |||||
| journal = IEEE_J_AC, | |||||
| to yield "{IEEE} Trans. Automat. Contr." | |||||
| IEEE uses abbreviated journal titles in their bibliographies - | |||||
| this file is suitable for work that is to be submitted to the IEEE. | |||||
| For work that requires full-length titles, you should use the full | |||||
| titles provided in the companion file, IEEEfull.bib. | |||||
| ** NOTES ** | |||||
| 1. Journals have been grouped according to subject in order to make it | |||||
| easier to locate and extract the definitions for related journals - | |||||
| as most works use references that are confined to a single topic. | |||||
| Magazines are listed in straight alphabetical order. | |||||
| 2. String names are closely based on IEEE's own internal acronyms. | |||||
| 3. Abbreviations follow IEEE's style. | |||||
| 4. Older, out-of-print IEEE titles are included (but not including titles | |||||
| dating prior to IEEE's formation from the IRE and AIEE in 1963). | |||||
| 5. The following NEW/current journal definitions have been disabled because | |||||
| their abbreviations have not yet been verified: | |||||
| STRING{IEEE_J_CBB = "{IEEE/ACM} Trans. Comput. Biology Bioinformatics"} | |||||
| STRING{IEEE_J_CJECE = "Canadian J. Elect. Comput. Eng."} | |||||
| STRING{IEEE_J_DSC = "{IEEE} Trans. Dependable Secure Comput."} | |||||
| STRING{IEEE_O_DSO = "{IEEE} Distrib. Syst. Online"} | |||||
| 6. The following OLD journal definitions have been disabled because | |||||
| their abbreviations have not yet been found/verified: | |||||
| STRING{IEEE_J_BCTV = "{IEEE} Trans. Broadcast Television Receivers"} | |||||
| STRING{IEEE_J_EWS = "{IEEE} Trans. Eng. Writing Speech"} | |||||
| If you know what the proper abbreviation is for a string in #5 or #6 above, | |||||
| email me and I will correct them in the next release. | |||||
| IEEE Journals | |||||
| aerospace and military | |||||
| @STRING{IEEE_J_AES = "{IEEE} Trans. Aerosp. Electron. Syst."} | |||||
| @STRING{IEEE_J_ANE = "{IEEE} Trans. Aerosp. Navig. Electron."} | |||||
| @STRING{IEEE_J_ANNE = "{IEEE} Trans. Aeronaut. Navig. Electron."} | |||||
| @STRING{IEEE_J_AS = "{IEEE} Trans. Aerosp."} | |||||
| @STRING{IEEE_J_AIRE = "{IEEE} Trans. Airborne Electron."} | |||||
| @STRING{IEEE_J_MIL = "{IEEE} Trans. Mil. Electron."} | |||||
| autos, transportation and vehicles (non-aerospace) | |||||
| @STRING{IEEE_J_ITS = "{IEEE} Trans. Intell. Transp. Syst."} | |||||
| @STRING{IEEE_J_VT = "{IEEE} Trans. Veh. Technol."} | |||||
| @STRING{IEEE_J_VC = "{IEEE} Trans. Veh. Commun."} | |||||
| circuits, signals, systems, audio and controls | |||||
| @STRING{IEEE_J_SPL = "{IEEE} Signal Process. Lett."} | |||||
| @STRING{IEEE_J_ASSP = "{IEEE} Trans. Acoust., Speech, Signal Process."} | |||||
| @STRING{IEEE_J_AU = "{IEEE} Trans. Audio"} | |||||
| @STRING{IEEE_J_AUEA = "{IEEE} Trans. Audio Electroacoust."} | |||||
| @STRING{IEEE_J_AC = "{IEEE} Trans. Autom. Control"} | |||||
| @STRING{IEEE_J_CAS = "{IEEE} Trans. Circuits Syst."} | |||||
| @STRING{IEEE_J_CASVT = "{IEEE} Trans. Circuits Syst. Video Technol."} | |||||
| @STRING{IEEE_J_CASI = "{IEEE} Trans. Circuits Syst. {I}"} | |||||
| @STRING{IEEE_J_CASII = "{IEEE} Trans. Circuits Syst. {II}"} | |||||
| in 2004 CASI and CASII renamed part title to CASI_RP and CASII_EB, respectively. | |||||
| @STRING{IEEE_J_CASI_RP = "{IEEE} Trans. Circuits Syst. {I}"} | |||||
| @STRING{IEEE_J_CASII_EB = "{IEEE} Trans. Circuits Syst. {II}"} | |||||
| @STRING{IEEE_J_CT = "{IEEE} Trans. Circuit Theory"} | |||||
| @STRING{IEEE_J_CST = "{IEEE} Trans. Control Syst. Technol."} | |||||
| @STRING{IEEE_J_SP = "{IEEE} Trans. Signal Process."} | |||||
| @STRING{IEEE_J_SU = "{IEEE} Trans. Sonics Ultrason."} | |||||
| @STRING{IEEE_J_SAP = "{IEEE} Trans. Speech Audio Process."} | |||||
| @STRING{IEEE_J_UE = "{IEEE} Trans. Ultrason. Eng."} | |||||
| @STRING{IEEE_J_UFFC = "{IEEE} Trans. Ultrason., Ferroelectr., Freq. Control"} | |||||
| communications | |||||
| @STRING{IEEE_J_COML = "{IEEE} Commun. Lett."} | |||||
| @STRING{IEEE_J_JSAC = "{IEEE} J. Sel. Areas Commun."} | |||||
| @STRING{IEEE_J_COM = "{IEEE} Trans. Commun."} | |||||
| @STRING{IEEE_J_COMT = "{IEEE} Trans. Commun. Technol."} | |||||
| @STRING{IEEE_J_WCOM = "{IEEE} Trans. Wireless Commun."} | |||||
| components, packaging and manufacturing | |||||
| @STRING{IEEE_J_ADVP = "{IEEE} Trans. Adv. Packag."} | |||||
| @STRING{IEEE_J_CHMT = "{IEEE} Trans. Compon., Hybrids, Manuf. Technol."} | |||||
| @STRING{IEEE_J_CPMTA = "{IEEE} Trans. Compon., Packag., Manuf. Technol. {A}"} | |||||
| @STRING{IEEE_J_CPMTB = "{IEEE} Trans. Compon., Packag., Manuf. Technol. {B}"} | |||||
| @STRING{IEEE_J_CPMTC = "{IEEE} Trans. Compon., Packag., Manuf. Technol. {C}"} | |||||
| @STRING{IEEE_J_CAPT = "{IEEE} Trans. Compon. Packag. Technol."} | |||||
| @STRING{IEEE_J_CAPTS = "{IEEE} Trans. Compon. Packag. Technol."} | |||||
| @STRING{IEEE_J_CPART = "{IEEE} Trans. Compon. Parts"} | |||||
| @STRING{IEEE_J_EPM = "{IEEE} Trans. Electron. Packag. Manuf."} | |||||
| @STRING{IEEE_J_MFT = "{IEEE} Trans. Manuf. Technol."} | |||||
| @STRING{IEEE_J_PHP = "{IEEE} Trans. Parts, Hybrids, Packag."} | |||||
| @STRING{IEEE_J_PMP = "{IEEE} Trans. Parts, Mater., Packag."} | |||||
| CAD | |||||
| @STRING{IEEE_J_TCAD = "{IEEE} J. Technol. Comput. Aided Design"} | |||||
| @STRING{IEEE_J_CAD = "{IEEE} Trans. Comput.-Aided Design Integr. Circuits Syst."} | |||||
| coding, data, information, knowledge | |||||
| @STRING{IEEE_J_IT = "{IEEE} Trans. Inf. Theory"} | |||||
| @STRING{IEEE_J_KDE = "{IEEE} Trans. Knowl. Data Eng."} | |||||
| computers, computation, networking and software | |||||
| @STRING{IEEE_J_C = "{IEEE} Trans. Comput."} | |||||
| @STRING{IEEE_J_CAL = "{IEEE} Comput. Archit. Lett."} | |||||
| disabled till definition is verified | |||||
| STRING{IEEE_J_DSC = "{IEEE} Trans. Dependable Secure Comput."} | |||||
| @STRING{IEEE_J_ECOMP = "{IEEE} Trans. Electron. Comput."} | |||||
| @STRING{IEEE_J_EVC = "{IEEE} Trans. Evol. Comput."} | |||||
| @STRING{IEEE_J_FUZZ = "{IEEE} Trans. Fuzzy Syst."} | |||||
| @STRING{IEEE_J_IFS = "{IEEE} Trans. Inf. Forensics Security"} | |||||
| @STRING{IEEE_J_MC = "{IEEE} Trans. Mobile Comput."} | |||||
| @STRING{IEEE_J_NET = "{IEEE/ACM} Trans. Netw."} | |||||
| @STRING{IEEE_J_NN = "{IEEE} Trans. Neural Netw."} | |||||
| @STRING{IEEE_J_PDS = "{IEEE} Trans. Parallel Distrib. Syst."} | |||||
| @STRING{IEEE_J_SE = "{IEEE} Trans. Softw. Eng."} | |||||
| computer graphics, imaging, and multimedia | |||||
| @STRING{IEEE_J_JDT = "{IEEE/OSA} J. Display Technol."} | |||||
| @STRING{IEEE_J_IP = "{IEEE} Trans. Image Process."} | |||||
| @STRING{IEEE_J_MM = "{IEEE} Trans. Multimedia"} | |||||
| @STRING{IEEE_J_VCG = "{IEEE} Trans. Vis. Comput. Graphics"} | |||||
| cybernetics, ergonomics, robots, man-machine, and automation | |||||
| @STRING{IEEE_J_ASE = "{IEEE} Trans. Autom. Sci. Eng."} | |||||
| @STRING{IEEE_J_JRA = "{IEEE} J. Robot. Autom."} | |||||
| @STRING{IEEE_J_HFE = "{IEEE} Trans. Hum. Factors Electron."} | |||||
| @STRING{IEEE_J_MMS = "{IEEE} Trans. Man-Mach. Syst."} | |||||
| @STRING{IEEE_J_PAMI = "{IEEE} Trans. Pattern Anal. Mach. Intell."} | |||||
| in 1989 JRA became RA | |||||
| in August 2004, RA split into ASE and RO | |||||
| @STRING{IEEE_J_RA = "{IEEE} Trans. Robot. Autom."} | |||||
| @STRING{IEEE_J_RO = "{IEEE} Trans. Robot."} | |||||
| @STRING{IEEE_J_SMC = "{IEEE} Trans. Syst., Man, Cybern."} | |||||
| @STRING{IEEE_J_SMCA = "{IEEE} Trans. Syst., Man, Cybern. {A}"} | |||||
| @STRING{IEEE_J_SMCB = "{IEEE} Trans. Syst., Man, Cybern. {B}"} | |||||
| @STRING{IEEE_J_SMCC = "{IEEE} Trans. Syst., Man, Cybern. {C}"} | |||||
| @STRING{IEEE_J_SSC = "{IEEE} Trans. Syst. Sci. Cybern."} | |||||
| earth, wind, fire and water | |||||
| @STRING{IEEE_J_GE = "{IEEE} Trans. Geosci. Electron."} | |||||
| @STRING{IEEE_J_GRS = "{IEEE} Trans. Geosci. Remote Sens."} | |||||
| @STRING{IEEE_J_GRSL = "{IEEE} Geosci. Remote Sens. Lett."} | |||||
| @STRING{IEEE_J_OE = "{IEEE} J. Ocean. Eng."} | |||||
| education, engineering, history, IEEE, professional | |||||
| disabled till definition is verified | |||||
| STRING{IEEE_J_CJECE = "Canadian J. Elect. Comput. Eng."} | |||||
| @STRING{IEEE_J_PROC = "Proc. {IEEE}"} | |||||
| @STRING{IEEE_J_EDU = "{IEEE} Trans. Educ."} | |||||
| @STRING{IEEE_J_EM = "{IEEE} Trans. Eng. Manag."} | |||||
| disabled till definition is verified | |||||
| STRING{IEEE_J_EWS = "{IEEE} Trans. Eng. Writing Speech"} | |||||
| @STRING{IEEE_J_PC = "{IEEE} Trans. Prof. Commun."} | |||||
| electromagnetics, antennas, EMI, magnetics and microwave | |||||
| @STRING{IEEE_J_AWPL = "{IEEE} Antennas Wireless Propag. Lett."} | |||||
| @STRING{IEEE_J_MGWL = "{IEEE} Microw. Guided Wave Lett."} | |||||
| IEEE seems to want "Compon." here, not "Comp." | |||||
| @STRING{IEEE_J_MWCL = "{IEEE} Microw. Wireless Compon. Lett."} | |||||
| @STRING{IEEE_J_AP = "{IEEE} Trans. Antennas Propag."} | |||||
| @STRING{IEEE_J_EMC = "{IEEE} Trans. Electromagn. Compat."} | |||||
| @STRING{IEEE_J_MAG = "{IEEE} Trans. Magn."} | |||||
| @STRING{IEEE_J_MTT = "{IEEE} Trans. Microw. Theory Tech."} | |||||
| @STRING{IEEE_J_RFI = "{IEEE} Trans. Radio Freq. Interference"} | |||||
| @STRING{IEEE_J_TJMJ = "{IEEE} Transl. J. Magn. Jpn."} | |||||
| energy and power | |||||
| @STRING{IEEE_J_EC = "{IEEE} Trans. Energy Convers."} | |||||
| @STRING{IEEE_J_PEL = "{IEEE} Power Electron. Lett."} | |||||
| @STRING{IEEE_J_PWRAS = "{IEEE} Trans. Power App. Syst."} | |||||
| @STRING{IEEE_J_PWRD = "{IEEE} Trans. Power Del."} | |||||
| @STRING{IEEE_J_PWRE = "{IEEE} Trans. Power Electron."} | |||||
| @STRING{IEEE_J_PWRS = "{IEEE} Trans. Power Syst."} | |||||
| industrial, commercial and consumer | |||||
| @STRING{IEEE_J_APPIND = "{IEEE} Trans. Appl. Ind."} | |||||
| @STRING{IEEE_J_BC = "{IEEE} Trans. Broadcast."} | |||||
| disabled till definition is verified | |||||
| STRING{IEEE_J_BCTV = "{IEEE} Trans. Broadcast Television Receivers"} | |||||
| @STRING{IEEE_J_CE = "{IEEE} Trans. Consum. Electron."} | |||||
| @STRING{IEEE_J_IE = "{IEEE} Trans. Ind. Electron."} | |||||
| @STRING{IEEE_J_IECI = "{IEEE} Trans. Ind. Electron. Contr. Instrum."} | |||||
| @STRING{IEEE_J_IA = "{IEEE} Trans. Ind. Appl."} | |||||
| @STRING{IEEE_J_IGA = "{IEEE} Trans. Ind. Gen. Appl."} | |||||
| @STRING{IEEE_J_IINF = "{IEEE} Trans. Ind. Informat."} | |||||
| @STRING{IEEE_J_PSE = "{IEEE} J. Product Safety Eng."} | |||||
| instrumentation and measurement | |||||
| @STRING{IEEE_J_IM = "{IEEE} Trans. Instrum. Meas."} | |||||
| insulation and materials | |||||
| @STRING{IEEE_J_JEM = "{IEEE/TMS} J. Electron. Mater."} | |||||
| @STRING{IEEE_J_DEI = "{IEEE} Trans. Dielectr. Electr. Insul."} | |||||
| @STRING{IEEE_J_EI = "{IEEE} Trans. Electr. Insul."} | |||||
| mechanical | |||||
| @STRING{IEEE_J_MECH = "{IEEE/ASME} Trans. Mechatronics"} | |||||
| @STRING{IEEE_J_MEMS = "J. Microelectromech. Syst."} | |||||
| medical and biological | |||||
| @STRING{IEEE_J_BME = "{IEEE} Trans. Biomed. Eng."} | |||||
| Note: The B-ME journal later dropped the hyphen and became the BME. | |||||
| @STRING{IEEE_J_B-ME = "{IEEE} Trans. Bio-Med. Eng."} | |||||
| @STRING{IEEE_J_BMELC = "{IEEE} Trans. Bio-Med. Electron."} | |||||
| disabled till definition is verified | |||||
| STRING{IEEE_J_CBB = "{IEEE/ACM} Trans. Comput. Biology Bioinformatics"} | |||||
| @STRING{IEEE_J_ITBM = "{IEEE} Trans. Inf. Technol. Biomed."} | |||||
| @STRING{IEEE_J_ME = "{IEEE} Trans. Med. Electron."} | |||||
| @STRING{IEEE_J_MI = "{IEEE} Trans. Med. Imag."} | |||||
| @STRING{IEEE_J_NB = "{IEEE} Trans. Nanobiosci."} | |||||
| @STRING{IEEE_J_NSRE = "{IEEE} Trans. Neural Syst. Rehabil. Eng."} | |||||
| @STRING{IEEE_J_RE = "{IEEE} Trans. Rehabil. Eng."} | |||||
| optics, lightwave and photonics | |||||
| @STRING{IEEE_J_PTL = "{IEEE} Photon. Technol. Lett."} | |||||
| @STRING{IEEE_J_JLT = "J. Lightw. Technol."} | |||||
| physics, electrons, nanotechnology, nuclear and quantum electronics | |||||
| @STRING{IEEE_J_EDL = "{IEEE} Electron Device Lett."} | |||||
| @STRING{IEEE_J_JQE = "{IEEE} J. Quantum Electron."} | |||||
| @STRING{IEEE_J_JSTQE = "{IEEE} J. Sel. Topics Quantum Electron."} | |||||
| @STRING{IEEE_J_ED = "{IEEE} Trans. Electron Devices"} | |||||
| @STRING{IEEE_J_NANO = "{IEEE} Trans. Nanotechnol."} | |||||
| @STRING{IEEE_J_NS = "{IEEE} Trans. Nucl. Sci."} | |||||
| @STRING{IEEE_J_PS = "{IEEE} Trans. Plasma Sci."} | |||||
| reliability | |||||
| IEEE seems to want "Mat." here, not "Mater." | |||||
| @STRING{IEEE_J_DMR = "{IEEE} Trans. Device Mater. Rel."} | |||||
| @STRING{IEEE_J_R = "{IEEE} Trans. Rel."} | |||||
| semiconductors, superconductors, electrochemical and solid state | |||||
| @STRING{IEEE_J_ESSL = "{IEEE/ECS} Electrochem. Solid-State Lett."} | |||||
| @STRING{IEEE_J_JSSC = "{IEEE} J. Solid-State Circuits"} | |||||
| @STRING{IEEE_J_ASC = "{IEEE} Trans. Appl. Supercond."} | |||||
| @STRING{IEEE_J_SM = "{IEEE} Trans. Semicond. Manuf."} | |||||
| sensors | |||||
| @STRING{IEEE_J_SENSOR = "{IEEE} Sensors J."} | |||||
| VLSI | |||||
| @STRING{IEEE_J_VLSI = "{IEEE} Trans. {VLSI} Syst."} | |||||
| IEEE Magazines | |||||
| @STRING{IEEE_M_AES = "{IEEE} Aerosp. Electron. Syst. Mag."} | |||||
| @STRING{IEEE_M_HIST = "{IEEE} Ann. Hist. Comput."} | |||||
| @STRING{IEEE_M_AP = "{IEEE} Antennas Propag. Mag."} | |||||
| @STRING{IEEE_M_ASSP = "{IEEE} {ASSP} Mag."} | |||||
| @STRING{IEEE_M_CD = "{IEEE} Circuits Devices Mag."} | |||||
| @STRING{IEEE_M_CAS = "{IEEE} Circuits Syst. Mag."} | |||||
| @STRING{IEEE_M_COM = "{IEEE} Commun. Mag."} | |||||
| @STRING{IEEE_M_COMSOC = "{IEEE} Commun. Soc. Mag."} | |||||
| @STRING{IEEE_M_CIM = "{IEEE} Comput. Intell. Mag."} | |||||
| CSEM changed to CSE in 1999 | |||||
| @STRING{IEEE_M_CSE = "{IEEE} Comput. Sci. Eng."} | |||||
| @STRING{IEEE_M_CSEM = "{IEEE} Comput. Sci. Eng. Mag."} | |||||
| @STRING{IEEE_M_C = "{IEEE} Computer"} | |||||
| @STRING{IEEE_M_CAP = "{IEEE} Comput. Appl. Power"} | |||||
| @STRING{IEEE_M_CGA = "{IEEE} Comput. Graph. Appl."} | |||||
| @STRING{IEEE_M_CONC = "{IEEE} Concurrency"} | |||||
| @STRING{IEEE_M_CS = "{IEEE} Control Syst. Mag."} | |||||
| @STRING{IEEE_M_DTC = "{IEEE} Des. Test. Comput."} | |||||
| @STRING{IEEE_M_EI = "{IEEE} Electr. Insul. Mag."} | |||||
| @STRING{IEEE_M_ETR = "{IEEE} ElectroTechnol. Rev."} | |||||
| @STRING{IEEE_M_EMB = "{IEEE} Eng. Med. Biol. Mag."} | |||||
| @STRING{IEEE_M_EMR = "{IEEE} Eng. Manag. Rev."} | |||||
| @STRING{IEEE_M_EXP = "{IEEE} Expert"} | |||||
| @STRING{IEEE_M_IA = "{IEEE} Ind. Appl. Mag."} | |||||
| @STRING{IEEE_M_IM = "{IEEE} Instrum. Meas. Mag."} | |||||
| @STRING{IEEE_M_IS = "{IEEE} Intell. Syst."} | |||||
| @STRING{IEEE_M_IC = "{IEEE} Internet Comput."} | |||||
| @STRING{IEEE_M_ITP = "{IEEE} {IT} Prof."} | |||||
| @STRING{IEEE_M_MICRO = "{IEEE} Micro"} | |||||
| @STRING{IEEE_M_MW = "{IEEE} Microw. Mag."} | |||||
| @STRING{IEEE_M_MM = "{IEEE} Multimedia"} | |||||
| @STRING{IEEE_M_NET = "{IEEE} Netw."} | |||||
| IEEE's editorial manual lists "Pers. Commun.", | |||||
| but "Personal Commun. Mag." seems to be what is used in the journals | |||||
| @STRING{IEEE_M_PCOM = "{IEEE} Personal Commun. Mag."} | |||||
| @STRING{IEEE_M_POT = "{IEEE} Potentials"} | |||||
| CAP and PER merged to form PE in 2003 | |||||
| @STRING{IEEE_M_PE = "{IEEE} Power Energy Mag."} | |||||
| @STRING{IEEE_M_PER = "{IEEE} Power Eng. Rev."} | |||||
| @STRING{IEEE_M_PVC = "{IEEE} Pervasive Comput."} | |||||
| @STRING{IEEE_M_RA = "{IEEE} Robot. Autom. Mag."} | |||||
| @STRING{IEEE_M_SAP = "{IEEE} Security Privacy"} | |||||
| @STRING{IEEE_M_SP = "{IEEE} Signal Process. Mag."} | |||||
| @STRING{IEEE_M_S = "{IEEE} Softw."} | |||||
| @STRING{IEEE_M_SPECT = "{IEEE} Spectr."} | |||||
| @STRING{IEEE_M_TS = "{IEEE} Technol. Soc. Mag."} | |||||
| @STRING{IEEE_M_VT = "{IEEE} Veh. Technol. Mag."} | |||||
| @STRING{IEEE_M_WC = "{IEEE} Wireless Commun. Mag."} | |||||
| @STRING{IEEE_M_TODAY = "Today's Engineer"} | |||||
| IEEE Online Publications | |||||
| @STRING{IEEE_O_CSTO = "{IEEE} Commun. Surveys Tuts."} | |||||
| disabled till definition is verified | |||||
| STRING{IEEE_O_DSO = "{IEEE} Distrib. Syst. Online"} | |||||
| -- | |||||
| EOF |
+ 17
- 0
Thesis/abstract_en.tex
View File
| % !TEX encoding = UTF-8 Unicode | |||||
| \thispagestyle{empty} | |||||
| \begin{latin} | |||||
| \centerline{\textbf{\large{Abstract}}} | |||||
| \begin{quote} | |||||
| \small | |||||
| Event history analysis is a classic problem in stochastic process, that recently attracts the researchers' attention in complex networks. The goal is to model the time of events, like check in a restaurant check-in or post a message, given their history, and then control them. In this thesis we try to improve both aspects of the problem... | |||||
| \vskip 0.3cm | |||||
| \textbf{Keywords:} \textit{Event history, complex network, stochastic point process, Hawkes process, spatio-temporal events, optimal control, stochastic differential equations} | |||||
| \end{quote} | |||||
| \end{latin} | |||||
+ 18
- 0
Thesis/abstract_fa.tex
View File
| % !TEX encoding = UTF-8 Unicode | |||||
| \thispagestyle{empty} | |||||
| \centerline{\textbf{\large{چکیده}}} | |||||
| \begin{quote} | |||||
| امروزه تبلیغات برخط بخش زیادی از وبسایتها و برنامههای موبایلی را دربر گرفته است. در این نوع تبلیغات به محض تعامل کاربر با سایت یا برنامه موبایل باید در کسری از ثانیه در مورد اینکه چه تبلیغی به وی نشان داده شود تصمیم گرفته شود\footnote{استاندارد پذیرفته شده در دنیا حدود 100 میلیثانیه است}. در سامانههای تبلیغ برخط، درآمد این سیستمها معمولا پس از کلیک کاربر روی تبلیغ یا تعامل کاربر با تبلیغ صورت میگیرد و لذا روش معمول این است که برای انتخاب تبلیغ برای نمایش به کاربر، ابتدا احتمال کلیک یا تعامل کاربر با تبلیغات مختلف را محاسبه کرده و سپس بر اساس این احتمال و مبلغ درآمد به ازای تبلیغات مختلف، یک تبلیغ را به عنوان تبلیغ برنده انتخاب و به کاربر نمایش میدهند. لذا یکی از مهمترین مسائل در تبلیغات برخط پیشبینی احتمال کلیک کاربر بر روی تبلیغات مختلف است که مورد توجه زیادی در حوزه تحقیقات دانشگاهی قرار گرفته است. محاسبه دقیق این احتمال تعامل، از طرفی باعث نمایش تبلیغات مرتبطتر به کاربران و افزایش رضایت آنها خواهد شد و از طرفی دیگر درآمد سیستمهای تبلیغاتی را افزایش خواهد داد. | |||||
| تحقیقات قبلی در حوزه پیشبینی احتمال کلیک و تعامل، مساله را به یک مساله دستهبندی دودویی تبدیل میکنند و با استفاده از اطلاعات موجود در تاریخچه که به سه دستهی سمت کاربر، سمت تبلیغ دهنده و سمت نمایش دهنده تقسیم میشود، سعی در پیشبینی احتمال تعامل دارند. چالشهایی نظیر نامتوازن بودن کلاسها، تنک بودن دادهها، بعد زیاد و شروع سرد، این مساله را به کلی از مسائل سنتی دستهبندی متفاوت میکنند. روشهای موجود در این حوزه را میتوان به دو دسته روشهای کم عمق و روشهای ژرف دستهبندی کرد. با توجه به سادگی پیادهسازی و قابلیت موازیسازی، روشهای کم عمق در عمل استفاده بیشتری داشتهاند. | |||||
| در این پژوهش، با بررسی مسالهی پیشبینی احتمال نرخ تعامل کاربران با تبلیغات، و همچنین با تاکید بر چالشهای گفته شده، روش جدیدی برای حل این مساله پیشنهاد میدهیم. برای طراحی روش پیشنهادی، از مجموعهی متنوعی از ایدههای موجود و همچنین جدید بهره گرفته و این مدل را در راستای مقاوم بودن در برابر چالشهای مساله، طراحی نموده و با بررسی معیارهای ارزیابی نظیر مساحت تحت منحنی، دقت و بازیابی، عملکرد آن را روی مجموعه دادههای استاندارد میآزماییم. با بررسی نتایج آزمایشها، نتیجه میگیریم مدل پیشنهادی عملکرد قابل قبولی ارائه کرده و در نتیجه قابل آزمایش در شرایط آنلاین و واقعی است. | |||||
| \vskip 1cm | |||||
| \textbf{کلمات کلیدی:} \textiranic{ | |||||
| تبلیغات نمایشی، کاربر، احتمال تعامل، بردارهای تعبیه، تعامل بین ویژگیها | |||||
| } | |||||
| \end{quote} | |||||
+ 13
- 0
Thesis/acknowledge.tex
View File
| %% acknowledgement page | |||||
| %\thispagestyle{empty} | |||||
| %\cleardoublepage % | |||||
| %\vspace{4cm} | |||||
| % | |||||
| %{\nastaliq | |||||
| % تقدیم به بهار...% | |||||
| %} | |||||
| %\newpage | |||||
| %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% | |||||
| %% ستایش | |||||
| %\baselineskip=.750cm | |||||
| % \newpage\clearpage |
+ 69
- 0
Thesis/app1.aux
View File
| \relax | |||||
| \providecommand\zref@newlabel[2]{} | |||||
| \providecommand\hyper@newdestlabel[2]{} | |||||
| \zref@newlabel{zref@29}{\abspage{14}\page{9}\pagevalue{9}} | |||||
| \@writefile{toc}{\contentsline {chapter}{پیوست\nobreakspace {}\numberline {آ}فرآیندهای نقطهای}{9}{appendix.Alph1}} | |||||
| \@writefile{lof}{\addvspace {10\p@ }} | |||||
| \@writefile{lot}{\addvspace {10\p@ }} | |||||
| \newlabel{Chap:App1}{{آ}{9}{فرآیندهای نقطهای}{appendix.Alph1}{}} | |||||
| \@writefile{lof}{\contentsline {figure}{\numberline {آ-1}{\ignorespaces فرآیند پواسن یکبُعدی\relax }}{9}{figure.caption.5}} | |||||
| \newlabel{fig:2dpp}{{آ-1}{9}{فرآیند پواسن یکبُعدی\relax }{figure.caption.5}{}} | |||||
| \citation{williams1991probability} | |||||
| \citation{shalizialmost} | |||||
| \citation{shalizialmost} | |||||
| \@writefile{lof}{\contentsline {figure}{\numberline {آ-2}{\ignorespaces فرآیند پواسن چندبُعدی، استقلال آماری در توزیع نقاط\relax }}{10}{figure.caption.6}} | |||||
| \newlabel{fig:ndpp}{{آ-2}{10}{فرآیند پواسن چندبُعدی، استقلال آماری در توزیع نقاط\relax }{figure.caption.6}{}} | |||||
| \@writefile{toc}{\contentsline {section}{\numberline {آ-1}تعریف فرآیند پواسن}{10}{section.Alph1.1}} | |||||
| \zref@newlabel{footdir@62}{\abspage{15}} | |||||
| \zref@newlabel{zref@30}{\abspage{15}\page{10}\pagevalue{10}} | |||||
| \zref@newlabel{footdir@64}{\abspage{15}} | |||||
| \zref@newlabel{footdir@63}{\abspage{15}} | |||||
| \@setckpt{app1}{ | |||||
| \setcounter{page}{11} | |||||
| \setcounter{equation}{1} | |||||
| \setcounter{enumi}{0} | |||||
| \setcounter{enumii}{0} | |||||
| \setcounter{enumiii}{0} | |||||
| \setcounter{enumiv}{0} | |||||
| \setcounter{footnote}{1} | |||||
| \setcounter{mpfootnote}{2} | |||||
| \setcounter{part}{0} | |||||
| \setcounter{chapter}{1} | |||||
| \setcounter{section}{1} | |||||
| \setcounter{subsection}{0} | |||||
| \setcounter{subsubsection}{0} | |||||
| \setcounter{paragraph}{0} | |||||
| \setcounter{subparagraph}{0} | |||||
| \setcounter{figure}{2} | |||||
| \setcounter{table}{0} | |||||
| \setcounter{parentequation}{0} | |||||
| \setcounter{ALC@unique}{0} | |||||
| \setcounter{ALC@line}{0} | |||||
| \setcounter{ALC@rem}{0} | |||||
| \setcounter{ALC@depth}{0} | |||||
| \setcounter{float@type}{8} | |||||
| \setcounter{algorithm}{0} | |||||
| \setcounter{ContinuedFloat}{0} | |||||
| \setcounter{KVtest}{0} | |||||
| \setcounter{subfigure}{0} | |||||
| \setcounter{subfigure@save}{0} | |||||
| \setcounter{lofdepth}{1} | |||||
| \setcounter{subtable}{0} | |||||
| \setcounter{subtable@save}{0} | |||||
| \setcounter{lotdepth}{1} | |||||
| \setcounter{pp@next@reset}{0} | |||||
| \setcounter{zpage}{10} | |||||
| \setcounter{@pps}{1} | |||||
| \setcounter{@ppsavesec}{1} | |||||
| \setcounter{@ppsaveapp}{0} | |||||
| \setcounter{Item}{0} | |||||
| \setcounter{Hfootnote}{30} | |||||
| \setcounter{Hy@AnnotLevel}{0} | |||||
| \setcounter{bookmark@seq@number}{13} | |||||
| \setcounter{su@anzahl}{0} | |||||
| \setcounter{LT@tables}{0} | |||||
| \setcounter{LT@chunks}{0} | |||||
| \setcounter{footdir@label}{64} | |||||
| \setcounter{shadetheorem}{2} | |||||
| \setcounter{section@level}{1} | |||||
| } |
+ 44
- 0
Thesis/app1.tex
View File
| % !TEX encoding = UTF-8 Unicode | |||||
| \chapter{فرآیندهای نقطهای}\label{Chap:App1} | |||||
| یکی از معروفترین توزیعها در آمار و احتمال، توزیع پواسن است که حالت حدی توزیع دوجملهای است وقتی که تعداد آزمایشها زیاد و احتمال موفقیت کم باشد. اگر تعداد متوسط موفقیتها را $\mu=Np$ بنامیم میتوان نشان داد: | |||||
| \begin{equation} | |||||
| \text{\lr{Pois}} (r|\mu) = \lim_{n\rightarrow\infty} \text{\lr{Bin}}(r|N,p) = \frac{\mu^r e^{-\mu}}{r!} | |||||
| %\mathcal{P} | |||||
| \end{equation} | |||||
| که $\mu$ میانگین توزیع پواسن نیز است. به طور مشابه فرآیند پواسن برای شمارش پدیدههایی مانند تابش ذرات رادیواکتیو، تماسهای گرفته شده با مرکز تلفن یا درخواستها از یک وبسرور کار میرود که به صورت رویدادهایی مستقل در زمان پیوسته اتفاق میافتند، شکل \ref{fig:2dpp} را ببینید. در حالت چندبُعدی میتوان توزیع ستارگان در آسمان یا درختان در جنگل را که هیچ الگو یا نظم خاصی ندارد مانند شکل \ref{fig:ndpp} با فرآیند پواسن مدل کرد. در واقع پدیدههایی که از عوامل مستقل زیادی به وجود میآیند که هر کدام احتمال کمی دارند، به خوبی با فرآیند پواسن مدل میشوند. ویژگی اصلی این فرآیند تصادفی استقلال آماری آن است به طوری که تعداد نقاط در ناحیههایی که با هم اشتراک ندارند از هم مستقل هستند. | |||||
| در این بخش ابتدا تعریف و خواص توزیع پواسن آورده میشود. سپس قضایای مهم در مورد فرآیند پواسن بیان میشود. در بخش بعد انواع فرآیندهایی که از روی پواسن تعریف میشوند مانند فرآیند پواسن نشاندار، فرآیند هاوکس و فرآیند کاوکس آورده میشود. در اتنها دو روش نمونه برداری اوگاتا و باریکسازی شرح داده میشود. | |||||
| \begin{figure} | |||||
| \center | |||||
| \includegraphics{images/2dpp} | |||||
| \caption{فرآیند پواسن یکبُعدی} | |||||
| \label{fig:2dpp} | |||||
| \end{figure} | |||||
| \section{تعریف فرآیند پواسن} | |||||
| \begin{figure} | |||||
| \center | |||||
| \includegraphics{images/poiss-process} | |||||
| \caption{فرآیند پواسن چندبُعدی، استقلال آماری در توزیع نقاط} | |||||
| \label{fig:ndpp} | |||||
| \end{figure} | |||||
| برای تعریف فرآیندهای تصادفی دو دیدگاه وجود دارد؛ مجموعه متغیرهای تصادفی و تابع تصادفی. برای تعریف فرآیند تصادفی ابتدا متغیر تصادفی را تعریف میکنیم \cite{williams1991probability}. | |||||
| \begin{definition}%[ویلیامز \cite{williams1991probability}] | |||||
| متغیر تصادفی $X$ تابعی اندازهپذیر از فضای احتمال $(\Omega,\mathcal{F},P)$ به | |||||
| \trans{فضای اندازهپذیر}{Measurable Space} $(\Xi,\mathcal{E})$ | |||||
| است بدین معنا که نگاشت معکوس $E\in\mathcal{E}$ عضو $\mathcal{F}$ است، $X^{-1}(E) \in \mathcal{F}$. برای تعریف توزیع احتمال متغیر تصادفی، فضای اندازه پذیر را $(\mathbb{R}, \mathcal{B}(\mathbb{R}))$ در نظر میگیرند\footnote{ | |||||
| مجموعه $\mathcal{B}(\mathbb{R})$ از کامل کردن $\{(-\infty,q)|q\in\mathbb{Q}\}$ به دست میآید، یعنی کوچکترین میدان سیگمایی که مجموعه نیمبازههای کسری عضو آن باشند. | |||||
| }. | |||||
| اکنون توزیع تجمعی را میتوان به صورت | |||||
| $F_X(x)=P(X^{-1}(-\infty,x])=P(\{\omega|X(\omega)\leq x\})$ | |||||
| نوشت. | |||||
| \end{definition} | |||||
| از اینجا به بعد فرض میکنیم فضای احتمال $(\Omega,\mathcal{F},P)$ را در اختیار داریم که همه متغیرهای تصادفی در آن قابل تعریف هستند. اکنون تعریف فرآیند تصادفی به صورت مجموعهای از متغیرهای تصادفی را میتوان بیان کرد \cite{shalizialmost}. | |||||
| \begin{definition}%[شالیزی \cite{shalizialmost}] | |||||
| فرآیند تصادفی $\{X_t\}_{t\in \mathcal{T}}$ مجموعهای از متغیرهای تصادفی $X_t$ از فضای احتمال $(\Omega,\mathcal{F},P)$ به فضای اندازهپذیر $(\Xi,\mathcal{E})$ است که با مجموعه $\mathcal{T}$ نمایه میشوند. | |||||
| \end{definition} | |||||
| برای بیان تعریف دوم، باید ابتدا تابع تصادفی و | |||||
| \trans{نمونه مسیر}{Sample path} | |||||
| را تعریف کنیم \cite{shalizialmost}. | |||||
+ 58
- 0
Thesis/app2.aux
View File
| \relax | |||||
| \providecommand\zref@newlabel[2]{} | |||||
| \providecommand\hyper@newdestlabel[2]{} | |||||
| \zref@newlabel{zref@31}{\abspage{16}\page{11}\pagevalue{11}} | |||||
| \@writefile{toc}{\contentsline {chapter}{پیوست\nobreakspace {}\numberline {ب}اثباتها}{11}{appendix.Alph2}} | |||||
| \@writefile{lof}{\addvspace {10\p@ }} | |||||
| \@writefile{lot}{\addvspace {10\p@ }} | |||||
| \newlabel{Chap:App2}{{ب}{11}{اثباتها}{appendix.Alph2}{}} | |||||
| \newlabel{app:4c-lglk}{{ب}{11}{اثبات گزاره \ref {thm:4c-lglk}}{section*.7}{}} | |||||
| \@setckpt{app2}{ | |||||
| \setcounter{page}{13} | |||||
| \setcounter{equation}{0} | |||||
| \setcounter{enumi}{0} | |||||
| \setcounter{enumii}{0} | |||||
| \setcounter{enumiii}{0} | |||||
| \setcounter{enumiv}{0} | |||||
| \setcounter{footnote}{1} | |||||
| \setcounter{mpfootnote}{2} | |||||
| \setcounter{part}{0} | |||||
| \setcounter{chapter}{2} | |||||
| \setcounter{section}{0} | |||||
| \setcounter{subsection}{0} | |||||
| \setcounter{subsubsection}{0} | |||||
| \setcounter{paragraph}{0} | |||||
| \setcounter{subparagraph}{0} | |||||
| \setcounter{figure}{0} | |||||
| \setcounter{table}{0} | |||||
| \setcounter{parentequation}{0} | |||||
| \setcounter{ALC@unique}{0} | |||||
| \setcounter{ALC@line}{0} | |||||
| \setcounter{ALC@rem}{0} | |||||
| \setcounter{ALC@depth}{0} | |||||
| \setcounter{float@type}{8} | |||||
| \setcounter{algorithm}{0} | |||||
| \setcounter{ContinuedFloat}{0} | |||||
| \setcounter{KVtest}{0} | |||||
| \setcounter{subfigure}{0} | |||||
| \setcounter{subfigure@save}{0} | |||||
| \setcounter{lofdepth}{1} | |||||
| \setcounter{subtable}{0} | |||||
| \setcounter{subtable@save}{0} | |||||
| \setcounter{lotdepth}{1} | |||||
| \setcounter{pp@next@reset}{0} | |||||
| \setcounter{zpage}{11} | |||||
| \setcounter{@pps}{1} | |||||
| \setcounter{@ppsavesec}{1} | |||||
| \setcounter{@ppsaveapp}{0} | |||||
| \setcounter{Item}{0} | |||||
| \setcounter{Hfootnote}{30} | |||||
| \setcounter{Hy@AnnotLevel}{0} | |||||
| \setcounter{bookmark@seq@number}{14} | |||||
| \setcounter{su@anzahl}{0} | |||||
| \setcounter{LT@tables}{0} | |||||
| \setcounter{LT@chunks}{0} | |||||
| \setcounter{footdir@label}{64} | |||||
| \setcounter{shadetheorem}{2} | |||||
| \setcounter{section@level}{1} | |||||
| } |
+ 33
- 0
Thesis/app2.tex
View File
| % !TEX encoding = UTF-8 Unicode | |||||
| \chapter{اثباتها}\label{Chap:App2} | |||||
| %================================================================== | |||||
| \section*{اثبات گزاره \ref{thm:4c-lglk}}\label{app:4c-lglk} | |||||
| با استفاده از قانون زنجیر در احتمالات میتوان نوشت | |||||
| \begin{align} | |||||
| &f(\mathcal{D} \vert \theta) = \prod_{i=1}^K f\left((t_i,u_i,p_i)| \mathcal{D}(t_i)\right) \prod_{u=1}^{N} S(T,u) \nonumber | |||||
| \end{align} | |||||
| که $t_0=0$ و $S_u(T)$ احتمال بقای فرآیند $\lambda_u(t)$ بعد از آخرین رویدادش است. | |||||
| \begin{align} | |||||
| S_u(T) = \exp\left(-\int_{t_{\vert\mathcal{D}_u\vert}}^T \lambda_{u}(s) ds\right) \nonumber | |||||
| \end{align} | |||||
| اکنون با استفاده از رابطه فوق میتوان درستنمایی را محاسبه کرد. | |||||
| \begin{align} | |||||
| &f(\mathcal{D} \vert \theta) | |||||
| = \prod_{u=1}^{N} \prod_{i=1}^{\vert\mathcal{D}_u\vert} f\left((t_i,u_i,p_i)| \mathcal{D}(t_i)\right) \prod_{u=1}^{N} S(T,u) \nonumber \\ | |||||
| &= \prod_{u=1}^{N} \prod_{i=1}^{\vert\mathcal{D}_u\vert} \lambda_{u}(t_i) \exp\left(-\int_{t_{i-1}}^{t_i} \lambda_{u}(s) ds\right) f_{u}(p_i | t_i) | |||||
| \prod_{u=1}^{N} S(T,u) \nonumber | |||||
| \end{align} | |||||
| \begin{align} | |||||
| &= \prod_{u=1}^{N} \exp\left(-\int_0^{t_{\vert\mathcal{D}_u\vert}} \lambda_{u}(s) ds\right) \prod_{i=1}^{\vert\mathcal{D}_u\vert} f_{u}(p_i | t_i) \lambda_{u}(t_i) \prod_{u=1}^{N} S(T,u) \nonumber \\ | |||||
| &= \prod_{u=1}^{N} \exp\left(-\int_0^{t_{\vert\mathcal{D}_u\vert}} \lambda_{u}(s) ds\right) S(T,u) | |||||
| \prod_{i=1}^{\vert\mathcal{D}_u\vert} f_{u}(p_i | t_i) \lambda_{u}(t_i) \nonumber\\ | |||||
| &= \prod_{u=1}^{N} \exp\left(-\int_0^T \lambda_{u}(s) ds\right) | |||||
| \prod_{i=1}^{\vert\mathcal{D}_u\vert} f_{u}(p_i | t_i) \lambda_{u}(t_i) \nonumber | |||||
| \\ | |||||
| &= \prod_{u=1}^{N} \exp\left(-\int_0^T \lambda_{u}(s) ds\right) | |||||
| \prod_{u=1}^{N} \prod_{i=1}^{\vert\mathcal{D}_u\vert} f_{u}(p_i | t_i) \lambda_{u}(t_i) \nonumber \\ | |||||
| &=\exp\left(-\int_0^T \sum_{u=1}^N \lambda_u(s) ds \right) \prod_{i=1}^K \lambda_{u_i}(t_i) f_{u_i}(p_i|t_i) \nonumber | |||||
| \end{align} | |||||
+ 183
- 0
Thesis/chap1.aux
View File
| \relax | |||||
| \providecommand\zref@newlabel[2]{} | |||||
| \providecommand\hyper@newdestlabel[2]{} | |||||
| \citation{choi2020online} | |||||
| \citation{yuan2014survey} | |||||
| \zref@newlabel{zref@2}{\abspage{9}\page{2}\pagevalue{2}} | |||||
| \@writefile{toc}{\contentsline {chapter}{فصل\nobreakspace {}\numberline {1}مقدمه}{2}{chapter.1}} | |||||
| \@writefile{lof}{\addvspace {10\p@ }} | |||||
| \@writefile{lot}{\addvspace {10\p@ }} | |||||
| \newlabel{Chap:Chap1}{{1}{2}{مقدمه}{chapter.1}{}} | |||||
| \zref@newlabel{footdir@10}{\abspage{9}} | |||||
| \zref@newlabel{zref@6}{\abspage{9}\page{2}\pagevalue{2}} | |||||
| \zref@newlabel{footdir@8}{\abspage{9}} | |||||
| \zref@newlabel{zref@5}{\abspage{9}\page{2}\pagevalue{2}} | |||||
| \zref@newlabel{footdir@6}{\abspage{9}} | |||||
| \zref@newlabel{zref@4}{\abspage{9}\page{2}\pagevalue{2}} | |||||
| \zref@newlabel{footdir@4}{\abspage{9}} | |||||
| \zref@newlabel{zref@3}{\abspage{9}\page{2}\pagevalue{2}} | |||||
| \zref@newlabel{footdir@14}{\abspage{9}} | |||||
| \zref@newlabel{zref@8}{\abspage{9}\page{2}\pagevalue{2}} | |||||
| \zref@newlabel{footdir@12}{\abspage{9}} | |||||
| \zref@newlabel{zref@7}{\abspage{9}\page{2}\pagevalue{2}} | |||||
| \zref@newlabel{footdir@18}{\abspage{9}} | |||||
| \zref@newlabel{footdir@5}{\abspage{9}} | |||||
| \zref@newlabel{footdir@7}{\abspage{9}} | |||||
| \zref@newlabel{footdir@9}{\abspage{9}} | |||||
| \zref@newlabel{footdir@11}{\abspage{9}} | |||||
| \zref@newlabel{footdir@13}{\abspage{9}} | |||||
| \zref@newlabel{footdir@15}{\abspage{9}} | |||||
| \@writefile{toc}{\contentsline {section}{\numberline {1-1}معرفی انواع معاملات در تبلیغات نمایشی}{3}{section.1.1}} | |||||
| \zref@newlabel{footdir@16}{\abspage{10}} | |||||
| \zref@newlabel{zref@9}{\abspage{10}\page{3}\pagevalue{3}} | |||||
| \zref@newlabel{footdir@19}{\abspage{10}} | |||||
| \zref@newlabel{zref@10}{\abspage{10}\page{3}\pagevalue{3}} | |||||
| \zref@newlabel{footdir@21}{\abspage{10}} | |||||
| \zref@newlabel{zref@11}{\abspage{10}\page{3}\pagevalue{3}} | |||||
| \zref@newlabel{footdir@25}{\abspage{10}} | |||||
| \zref@newlabel{zref@13}{\abspage{10}\page{3}\pagevalue{3}} | |||||
| \zref@newlabel{footdir@23}{\abspage{10}} | |||||
| \zref@newlabel{zref@12}{\abspage{10}\page{3}\pagevalue{3}} | |||||
| \zref@newlabel{footdir@27}{\abspage{10}} | |||||
| \zref@newlabel{zref@14}{\abspage{10}\page{3}\pagevalue{3}} | |||||
| \zref@newlabel{footdir@29}{\abspage{10}} | |||||
| \zref@newlabel{zref@15}{\abspage{10}\page{3}\pagevalue{3}} | |||||
| \zref@newlabel{footdir@31}{\abspage{10}} | |||||
| \zref@newlabel{zref@16}{\abspage{10}\page{3}\pagevalue{3}} | |||||
| \zref@newlabel{footdir@33}{\abspage{10}} | |||||
| \zref@newlabel{footdir@17}{\abspage{10}} | |||||
| \zref@newlabel{footdir@20}{\abspage{10}} | |||||
| \zref@newlabel{footdir@22}{\abspage{10}} | |||||
| \zref@newlabel{footdir@24}{\abspage{10}} | |||||
| \zref@newlabel{footdir@26}{\abspage{10}} | |||||
| \zref@newlabel{footdir@28}{\abspage{10}} | |||||
| \zref@newlabel{footdir@30}{\abspage{10}} | |||||
| \zref@newlabel{footdir@32}{\abspage{10}} | |||||
| \citation{yuan2014survey} | |||||
| \zref@newlabel{footdir@34}{\abspage{11}} | |||||
| \zref@newlabel{zref@17}{\abspage{11}\page{4}\pagevalue{4}} | |||||
| \zref@newlabel{footdir@36}{\abspage{11}} | |||||
| \zref@newlabel{zref@18}{\abspage{11}\page{4}\pagevalue{4}} | |||||
| \zref@newlabel{footdir@38}{\abspage{11}} | |||||
| \zref@newlabel{zref@19}{\abspage{11}\page{4}\pagevalue{4}} | |||||
| \zref@newlabel{footdir@40}{\abspage{11}} | |||||
| \zref@newlabel{zref@20}{\abspage{11}\page{4}\pagevalue{4}} | |||||
| \zref@newlabel{footdir@42}{\abspage{11}} | |||||
| \zref@newlabel{footdir@35}{\abspage{11}} | |||||
| \zref@newlabel{footdir@37}{\abspage{11}} | |||||
| \zref@newlabel{footdir@39}{\abspage{11}} | |||||
| \zref@newlabel{footdir@41}{\abspage{11}} | |||||
| \@writefile{toc}{\contentsline {section}{\numberline {1-2}اجزا و نحوهی اجرای مزایدههای بلادرنگ}{5}{section.1.2}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {1-2-1}کاربر}{5}{subsection.1.2.1}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {1-2-2}ناشر}{5}{subsection.1.2.2}} | |||||
| \zref@newlabel{footdir@43}{\abspage{12}} | |||||
| \zref@newlabel{zref@21}{\abspage{12}\page{5}\pagevalue{5}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {1-2-3}سکوی سمت تامین}{5}{subsection.1.2.3}} | |||||
| \zref@newlabel{footdir@45}{\abspage{12}} | |||||
| \zref@newlabel{zref@22}{\abspage{12}\page{5}\pagevalue{5}} | |||||
| \zref@newlabel{footdir@51}{\abspage{12}} | |||||
| \zref@newlabel{footdir@44}{\abspage{12}} | |||||
| \zref@newlabel{footdir@46}{\abspage{12}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {1-2-4}سکوی سمت نیاز}{6}{subsection.1.2.4}} | |||||
| \zref@newlabel{footdir@47}{\abspage{13}} | |||||
| \zref@newlabel{zref@23}{\abspage{13}\page{6}\pagevalue{6}} | |||||
| \zref@newlabel{footdir@49}{\abspage{13}} | |||||
| \zref@newlabel{zref@24}{\abspage{13}\page{6}\pagevalue{6}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {1-2-5}تبلیغ کننده}{6}{subsection.1.2.5}} | |||||
| \zref@newlabel{footdir@52}{\abspage{13}} | |||||
| \zref@newlabel{zref@25}{\abspage{13}\page{6}\pagevalue{6}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {1-2-6}اجرای فرآیند مزایدههای بلادرنگ}{6}{subsection.1.2.6}} | |||||
| \zref@newlabel{footdir@54}{\abspage{13}} | |||||
| \zref@newlabel{zref@26}{\abspage{13}\page{6}\pagevalue{6}} | |||||
| \zref@newlabel{footdir@56}{\abspage{13}} | |||||
| \zref@newlabel{zref@27}{\abspage{13}\page{6}\pagevalue{6}} | |||||
| \zref@newlabel{footdir@58}{\abspage{13}} | |||||
| \zref@newlabel{footdir@48}{\abspage{13}} | |||||
| \zref@newlabel{footdir@50}{\abspage{13}} | |||||
| \zref@newlabel{footdir@53}{\abspage{13}} | |||||
| \zref@newlabel{footdir@55}{\abspage{13}} | |||||
| \zref@newlabel{footdir@57}{\abspage{13}} | |||||
| \citation{qin2019revenue} | |||||
| \@writefile{lof}{\contentsline {figure}{\numberline {1-1}{\ignorespaces فرآیند مزایدهی بلادرنگ \relax }}{7}{figure.caption.4}} | |||||
| \providecommand*\caption@xref[2]{\@setref\relax\@undefined{#1}} | |||||
| \newlabel{fig:rtb-process}{{1-1}{7}{فرآیند مزایدهی بلادرنگ \relax }{figure.caption.4}{}} | |||||
| \zref@newlabel{footdir@59}{\abspage{14}} | |||||
| \zref@newlabel{zref@28}{\abspage{14}\page{7}\pagevalue{7}} | |||||
| \zref@newlabel{footdir@61}{\abspage{14}} | |||||
| \zref@newlabel{zref@29}{\abspage{14}\page{7}\pagevalue{7}} | |||||
| \zref@newlabel{footdir@63}{\abspage{14}} | |||||
| \zref@newlabel{footdir@60}{\abspage{14}} | |||||
| \zref@newlabel{footdir@62}{\abspage{14}} | |||||
| \citation{reference/ml/LingS17} | |||||
| \citation{pires2019high} | |||||
| \citation{journals/eswa/LikaKH14} | |||||
| \citation{DBLP:journals/corr/abs-1004-3732} | |||||
| \@writefile{toc}{\contentsline {section}{\numberline {1-3}چالشها}{8}{section.1.3}} | |||||
| \zref@newlabel{footdir@64}{\abspage{15}} | |||||
| \zref@newlabel{zref@30}{\abspage{15}\page{8}\pagevalue{8}} | |||||
| \zref@newlabel{footdir@66}{\abspage{15}} | |||||
| \zref@newlabel{zref@31}{\abspage{15}\page{8}\pagevalue{8}} | |||||
| \zref@newlabel{footdir@68}{\abspage{15}} | |||||
| \zref@newlabel{zref@32}{\abspage{15}\page{8}\pagevalue{8}} | |||||
| \zref@newlabel{footdir@70}{\abspage{15}} | |||||
| \zref@newlabel{zref@33}{\abspage{15}\page{8}\pagevalue{8}} | |||||
| \zref@newlabel{footdir@72}{\abspage{15}} | |||||
| \zref@newlabel{zref@34}{\abspage{15}\page{8}\pagevalue{8}} | |||||
| \zref@newlabel{footdir@74}{\abspage{15}} | |||||
| \zref@newlabel{footdir@65}{\abspage{15}} | |||||
| \zref@newlabel{footdir@67}{\abspage{15}} | |||||
| \zref@newlabel{footdir@69}{\abspage{15}} | |||||
| \zref@newlabel{footdir@71}{\abspage{15}} | |||||
| \zref@newlabel{footdir@73}{\abspage{15}} | |||||
| \@writefile{toc}{\contentsline {section}{\numberline {1-4}هدف پژوهش}{9}{section.1.4}} | |||||
| \@writefile{toc}{\contentsline {section}{\numberline {1-5}پرسشهای اساسی پژوهش}{9}{section.1.5}} | |||||
| \@writefile{toc}{\contentsline {section}{\numberline {1-6}ساختار رساله}{9}{section.1.6}} | |||||
| \@setckpt{chap1}{ | |||||
| \setcounter{page}{10} | |||||
| \setcounter{equation}{0} | |||||
| \setcounter{enumi}{3} | |||||
| \setcounter{enumii}{0} | |||||
| \setcounter{enumiii}{0} | |||||
| \setcounter{enumiv}{0} | |||||
| \setcounter{footnote}{5} | |||||
| \setcounter{mpfootnote}{0} | |||||
| \setcounter{part}{0} | |||||
| \setcounter{chapter}{1} | |||||
| \setcounter{section}{6} | |||||
| \setcounter{subsection}{0} | |||||
| \setcounter{subsubsection}{0} | |||||
| \setcounter{paragraph}{0} | |||||
| \setcounter{subparagraph}{0} | |||||
| \setcounter{figure}{1} | |||||
| \setcounter{table}{0} | |||||
| \setcounter{parentequation}{0} | |||||
| \setcounter{ALC@unique}{0} | |||||
| \setcounter{ALC@line}{0} | |||||
| \setcounter{ALC@rem}{0} | |||||
| \setcounter{ALC@depth}{0} | |||||
| \setcounter{float@type}{8} | |||||
| \setcounter{algorithm}{0} | |||||
| \setcounter{ContinuedFloat}{0} | |||||
| \setcounter{KVtest}{0} | |||||
| \setcounter{subfigure}{0} | |||||
| \setcounter{subfigure@save}{0} | |||||
| \setcounter{lofdepth}{1} | |||||
| \setcounter{subtable}{0} | |||||
| \setcounter{subtable@save}{0} | |||||
| \setcounter{lotdepth}{1} | |||||
| \setcounter{pp@next@reset}{0} | |||||
| \setcounter{zpage}{8} | |||||
| \setcounter{@pps}{0} | |||||
| \setcounter{@ppsavesec}{0} | |||||
| \setcounter{@ppsaveapp}{0} | |||||
| \setcounter{Item}{3} | |||||
| \setcounter{Hfootnote}{33} | |||||
| \setcounter{Hy@AnnotLevel}{0} | |||||
| \setcounter{bookmark@seq@number}{13} | |||||
| \setcounter{su@anzahl}{0} | |||||
| \setcounter{LT@tables}{0} | |||||
| \setcounter{LT@chunks}{0} | |||||
| \setcounter{footdir@label}{74} | |||||
| \setcounter{shadetheorem}{0} | |||||
| \setcounter{section@level}{1} | |||||
| } |
+ 2255
- 0
Thesis/chap1.log
File diff suppressed because it is too large
View File
+ 132
- 0
Thesis/chap1.tex
View File
| % !TEX encoding = UTF-8 Unicode | |||||
| \chapter{مقدمه}\label{Chap:Chap1} | |||||
| %================================================================== | |||||
| انسان برای رفع نیازهای خود به اقتصاد وابسته است. برای توسعهی چرخههای اقتصادی، باید عوامل مهمی از قبیل افزایش تولید و گذر از تولید دستی به انبوه و همچنین بازاریابی مناسب را در نظر گرفت. یکی از عوامل دست یافتن به بازاریابی مناسب، انجام تبلیغات صحیح برای محصولات است. | |||||
| امروزه با گسترش اینترنت، شاهد تاثیرگذاری آن بر اکثر جنبههای زندگی بشری، از جمله اقتصاد هستیم. یکی از نمودهای این تاثیرگذاری، ظهور تبلیغات آنلاین در مقابل گونههای سنتیِ آن است. مقرون به صرفه بودن، در دسترس بودن در مقیاس جهانی و قابلیت گرفتن بازخورد مستقیم از کاربران مورد نظر از جمله برتریهای قابل توجه تبلیغات آنلاین است. | |||||
| تبلیغات آنلاین، به شیوههای متنوعی انجام میشود.\cite{choi2020online} تعدادی از گونههای این نوع تبلیغات، وبسایتها، \trans{شبکههای اجتماعی}{Social Networks}، \trans{تبلیغات کلمه کلیدی}{Keyword Advertising}، \trans{بهینهسازی موتورهای جستجو}{SEO} و \trans{تبلیغات نمایشی}{Display Advertising} هستند. | |||||
| در تبلیغات نمایشی، استفاده از \trans{بنر}{Banners}های ثابت، انیمیشنی و ویدیویی و نشان دادن آن به \trans{کاربر}{User} در کادرهای از پیش تعیین شده داخل وبسایتها یا برنامههای موبایل به عنوان روشی کارآمد برای جذب مخاطب به کار میرود؛ اما انتخاب این که کدام بنر در کدام کادر (کدام صفحهی وب) به کدام کاربر نمایش دادهشود، چالش قابل توجهی است. | |||||
| \section{معرفی انواع معاملات در تبلیغات نمایشی} | |||||
| از آنجا که درآمد بسیاری از صاحبان صفحات وب، تنها از تبلیغات نمایشی انجام شده در وبسایتهایشان حاصل میشود، انتخاب نحوهی قرارداد با \trans{تبلیغ کننده}{Advertisier}ها اهمیت زیادی برای آنها دارد.\cite{yuan2014survey} در این بخش به طور مختصر انواع قراردادهای رایج بین تبلیغات کنندهها و صاحبان صفحات وب را توضیح میدهیم. | |||||
| \begin{itemize} | |||||
| \item \textbf{قراردادهای مستقیم} | |||||
| در ابتدای ظهور تبلیغات آنلاین نمایشی، تبلیغ کننده با صاحب وبسایت \trans{قرارداد مستقیم}{Direct Deas} بسته و با انتخاب یک کادر ثابت در وبسایت و یک بنر تبلیغاتی مشخص، تا مدت (یا تعداد کلیک) مشخصی با نمایش دادن تبلیغ یکسان به تمامی کاربرانی که از آن صفحهی به خصوص بازدید میکردند، تبلیغات خود را نمایش میدادند. با وجود این که تعدادی وبسایت هنوز از چنین روشی استفاده میکنند؛ واضح است که به کار گرفتن آن برای تعداد بالای صفحات و تبلیغات، هزینه و زحمت قابل توجهی را به هر دو طرف معامله تحمیل میکند. به دلیل این مشکل، سراغ دستهای از قراردادها میرویم که به \trans{معاملات برنامهریزی شده}{Programmatic Deals} معروفاند. | |||||
| \item \textbf{قراردادهای برنامهریزی شده} | |||||
| در بقیهی روشها، که جزء شاخهی برنامهریزی شده طبقه بندی میشوند، با رعایت کردن یک استاندارد مشترک، میزان هزینه و زحمت مورد نیاز کاهش یافته و فرآیند سریعتر انجام میشود. معاملات برنامهریزی شده به دو دستهی \trans{معاملات تضمین شده}{Guaranteed Deals} و \trans{مزایدهی بلادرنگ}{Realtime Bidding (RTB)} تقسیم میشوند. | |||||
| \begin{itemize} | |||||
| \item \textbf{قراردادهای تضمین شده} | |||||
| در این دسته از قراردادها، هزینه و تعداد بنرهایی که باید به کاربران نشان داده شوند، از پیش تعیین میشود. نکتهی حائز اهمیت در این دسته از قراردادها، اضافه شدن سیستمهایی است که به صورت اتوماتیک بخشهای قابل توجهی از فرآیند نمایش تبلیغ را انجام داده و با حذف دخالت انسانی، هزینهها و زحمات کار را به شدت کاهش میدهند. دو دستهی مهم از این قراردادها، دستهی \trans{قراردادهای تضمین شدهی اتوماتیک}{Automated Guaranteed Deals} و \trans{قراردادهای تضمین شدهی برنامهریزی شده}{Programmatic Guaranteed Deals} نامیده میشوند. | |||||
| \begin{itemize} | |||||
| \item \textbf{قراردادهای تضمین شدهی اتوماتیک} | |||||
| همانطور که در بخش قبل گفته شد، در قراردادهای تضمین شدهی اتوماتیک، تمرکز بر \trans{خودکارسازی}{Automation} فرآیند نمایش تبلیغ است. یکی از مهمترین فواید خودکارسازی نمایش تبلیغ برای تبلیغ کننده، امکان تبلیغ همزمان در چندین وبسایت بدون نیاز به عقد چندین قرارداد است. | |||||
| \item \textbf{قراردادهای تضمین شدهی برنامهریزی شده} | |||||
| در این دسته از قراردادها علاوه بر سادهسازیهایی که در قراردادهای تضمین شدهی اتوماتیک انجام میشود، امکان تنظیمات جزئیتری برای تبلیغ کننده وجود داشته و در نتیجه این دسته از قراردادها بسیار محبوبتر از قراردادهای تضمین شدهی اتوماتیک هستند. در قراردادهای تضمین شدهی برنامه ریزی شده، تبلیغ کننده میتواند با اعمال چندین قاعدهی محدود کننده، نمایش بنر خود را برای کاربران مختلف فیلتر کرده و عملا بنر تبلیغاتی خود را فقط برای کاربرانی با مشخصات از پیش تعیین شده نمایش دهد. به عنوان مثال فرض کنید یک شرکت میتواند فروش کالاهای خود را برای کشورهای خاصی انجام دهد و برای فیلتر کردن کاربران، تنظیماتی را اعمال میکند که با دریافت اطلاعات مرورگر، در صورتی که \trans{آدرس آی پی}{IP Address} کاربر خارج از بازهی سرویس دهی شرکت باشد، از انجام تبلیغ صرف نظر کند. به این ترتیب این شرکت میزان قابل توجهی از هزینههای تبلیغاتی خود را از هدر رفت باز میدارد. | |||||
| \end{itemize} | |||||
| \item \textbf{مزایدهی بلادرنگ} | |||||
| تفاوت مزایدههای بلادرنگ با معاملات تضمین شده، در مشخص کردن قیمت و تعداد دفعات نمایش دادن تبلیغات به کاربران است. در مزایدههای بلادرنگ، هزینهی هر تبلیغ به طور جداگانه در هنگام درخواست بارگیری صفحه توسط کاربر، توسط یک \trans{مزایده}{Auction} بین تبلیغ کنندگان تعیین میشود. | |||||
| \begin{itemize} | |||||
| \item \textbf{مزایدهی بلادرنگ آزاد} | |||||
| در \trans{مزایدههای بلادرنگ آزاد}{Open Realtime Auction}، هربار که یک کاربر به یکی از صفحات دارای کادر مناسب برای تبلیغ وارد میشود، همهی تبلیغ کنندگان میتوانند یک قیمت برای نمایش تبلیغ خود به کاربر، پیشنهاد دهند و تبلیغ دارای بالاترین پیشنهاد قیمت، به کاربر نمایش داده میشود. امروزه این نوع معامله به دلیل هزینهی پایین برای تبلیغ کنندگان و درآمد بالا برای صاحبان صفحات وب، میزان قابل توجهی از تبلیغات کنندگان و صاحبان صفحات وب در سراسر جهان را به خود جذب کرده است. | |||||
| \item \textbf{مزایدهی بلادرنگ خصوصی} | |||||
| در \trans{مزایدههای بلادرنگ خصوصی}{Private Realtime Auction}، تبلیغات کنندگان باید قبل از شروع فرآیند تبلیغ وارد قرارداد شده و با قبول شرایط اولیهای که صاحب صفحات وب پیشنهاد میکند، وارد فرآیند مزایده شود. | |||||
| \end{itemize} | |||||
| \end{itemize} | |||||
| \end{itemize} | |||||
| در این پایان نامه، بر نوع مزایدههای بلادرنگ آزاد تمرکز خواهیم داشت و جزئیات و چالشهای مربوط به آن را بررسی خواهیم کرد. | |||||
| \section{اجزا و نحوهی اجرای مزایدههای بلادرنگ} | |||||
| در عمل، برای انجام مزایدههای بلادرنگ، به اجزا و نقشهای متنوعی نیاز است.\cite{yuan2014survey} در این بخش اصطلاحات استفاده شده در مزایدههای بلادرنگ و همچنین اجزا و نقشهای آن را تعریف کرده و توضیح میدهیم. | |||||
| \subsection{کاربر} | |||||
| تعریف کاربر در مزایدههای بلادرنگ، با تعریفی که در بخش قبل ذکر شد، تفاوت چندانی ندارد. تنها فرق جزئی در این نکته است که اینجا، تمرکز بیشتر روی مرورگری است که کاربر استفاده میکند و اعمالی که در این بخش به کاربر نسبت میدهیم، عملا توسط مرورگر کاربر انجام میشود و خود کاربر اطلاعی از انجام آنها ندارد. | |||||
| \subsection{ناشر} | |||||
| در ادبیات مزایدههای بلادرنگ، \trans{ناشر}{Publisher} به وبسایتی اشاره میکند که در آن امکان انجام تبلیغات وجود دارد و لذا [بخشی از] درآمد این وبسایت از تبلیغات است. از ملزومات اجرای فرآیند مزایدههای بلادرنگ، وجود اسکریپتهای مربوط به سکوی سمت تامین در این صفحه است. | |||||
| \subsection{سکوی سمت تامین} | |||||
| \trans{سکوی سمت تامین}{Supply Side Platform} | |||||
| به بخشی از زیرساخت اطلاق میشود که با تعدادی ناشر قرارداد بسته و از طریق تعدادی اسکریپت که در سایت ناشرها تعبیه کرده است، اجرای فرآیند مزایده را ممکن میسازد. | |||||
| این اسکریپتها، برخی اطلاعات از جمله سوابق مرور کاربر در همهی وبسایتهایی که این اسکریپت در آنها وجود دارد را به سکوی سمت تامین ارسال کرده و در هنگام نیاز به نمایش تبلیغ، اطلاعاتی از جمله موقعیت جغرافیایی، نحوهی اتصال به وبسایت (موبایل، تبلت یا کامپیوتر) و حتی نحوهی ورود به وبسایت (موتور جستجو، ایمیل تبلیغاتی، لینک توصیه شده از طرف کاربر دیگر و ...) را به این سکو ارسال میکند؛ لذا سکوی سمت تامین اطلاعات جامعی از این کاربر در اختیار داشته و بر اساس این اطلاعات، تبلیغات مناسب را در اختیار کاربر قرار دهد. | |||||
| \subsection{سکوی سمت نیاز} | |||||
| \trans{سکوی سمت نیاز}{Demand Side Platform} | |||||
| به بخشی از زیرساخت اطلاق میشود که با تعدادی تبلیغ کننده (بازاریاب) ارتباط داشته و عملا شرکتکنندههای اصلی مزایده، آنها هستند. سکوهای سمت نیاز برای هر \trans{موقعیت قابل تبلیغ}{Impression} وارد مزایده شده و قیمت پیشنهادی خود را برای انجام تبلیغ ارائه میکنند. | |||||
| \subsection{تبلیغ کننده} | |||||
| تبلیغ کننده (\trans{بازاریاب}{Marketer}) در بخش قبلی به صورت کامل تعریف شده است. آنها برای انجام تبلیغ و بازاریابی کالا یا خدماتی که ارائه میدهند، دست به تبلیغ زده و بودجهی قابل توجهی را روانهی زیرساختهای تبلیغاتی میکنند. بازاریابها با سکوهای سمت نیاز قرارداد بسته و تبلیغات خود را به آنها ارائه کرده و به ازای تعداد کلیک کاربران روی تبلیغاتشان، به آنها پرداخت میکنند. به عنوان مثال، سکوی سمت نیاز در قراردادی تضمین میکند تعداد 1000 کلیک بر روی بنر تبلیغاتی یکی از تبلیغ کنندهها تامین کرده و در قبال آن، هزینهای دریافت کند. | |||||
| \subsection{اجرای فرآیند مزایدههای بلادرنگ} | |||||
| فرآیند مزایدهی بلادرنگ، از کاربر شروع میشود. زمانی که کاربر وارد صفحهای متعلق به یک ناشر میشود، مرورگر کاربر یک درخواست برای نمایش وبسایت ناشر ارسال میکند(1). | |||||
| وبسایت ناشر، صفحهی \trans{اچتیامال}{HTML} خود را برای کاربر ارسال کرده و همزمان لینک مربوط به اسکریپت سکوی سمت تامین را در اختیار کاربر میگذارد(2). | |||||
| کاربر برای بارگیری صفحهی اچتیامال دریافتی، سراغ تکتک منابع رفته و هرکدام را بارگیری میکند. برای نمایش اطلاعاتی که در کادر تبلیغ وجود دارد، کاربر یک درخواست \trans{اچتیتیپی}{HTTP} به سکوی سمت تامین ارسال میکند(3). | |||||
| در این مرحله، سکوی سمت تامین وارد عمل شده و موقعیت قابل تبلیغ و اطلاعات کاربر را از قبیل سابقهی کاربر، مشخصات و سابقهی سایت ناشر و اطلاعات مربوط به ابعاد کادر تبلیغ به تمامی سکوهای سمت نیاز در دسترس ارسال میکند(4). | |||||
| هر سکوی سمت نیاز با در نظر گرفتن تبلیغِ خود، با استفاده از روشهای مختلف (که نمونههای آن در فصل 2 توضیح داده میشود) یک قیمت به عنوان هزینهی پیشنهادی نمایش تبلیغ ارائه میدهد. پیشنهادی که بیشترین قیمت را پیشنهاد داده باشد، برندهی مزایده میشود. پیشنهاد برنده با خطچین نمایش داده شده است(5). | |||||
| پس از دریافت هزینههای پیشنهادی سکوهای سمت نیاز، سکوهای سمت تامین بالاترین قیمت را انتخاب کرده و لینک سکوی سمت نیاز برنده را به کاربر ارسال میکند(6). | |||||
| کاربر با کسب اطلاع از آدرس مشخصات سکوی سمت نیاز برنده، برای اطلاع از محل نهایی بنر تبلیغ انتخاب شده، به آن آدرس رجوع میکند(7). | |||||
| سکوی سمت نیاز برنده به درخواست کاربر پاسخ داده و آدرس بنر (که در سرور متعلق به بازاریاب است) را برای کاربر ارسال میکند(8). | |||||
| کاربر به آدرس بنر رجوع میکند(9). | |||||
| سرور بازاریاب بنر تبلیغ را به کاربر ارسال میکند(10). | |||||
| مراحل اجرای این فرآیند در شکل \ref{fig:rtb-process} قابل ملاحظه است. | |||||
| نکتهی قابل توجه در فرآیند مزایدهی بلادرنگ، تفاوت نوع قراردادهای بسته شده بین سکوهای سمت نیاز با تبلیغ کنندهها و سکوهای سمت تامین با ناشران است. سکوهای سمت تامین به ازای \textbf{نمایش} هر تبلیغ به ناشران مبلغی پرداخت میکنند؛ اما سکوهای سمت تامین به ازای هر \textbf{کلیک انجام شده} روی بنرهای تبلیغ کنندهها، مبلغی از آنها دریافت میکنند؛ بنابراین برای تضمین سوددهی این سیستم، باید تبلیغاتی برای نمایش به کاربران انتخاب شوند که احتمال کلیک شدن روی آنها قابل توجه باشد؛ پس تخمین این احتمال که به \trans{نرخ کلیک}{Click Through Rate} معروف است، به یک مسالهی محوری در این فرآیند تبدیل میشود.\cite{qin2019revenue} | |||||
| لازم به ذکر است در برخی قراردادهای دیگر، نوع قرارداد بین سکوهای سمت تامین و تبلیغ کنندگان، به جای تضمین تعداد کلیک انجام شده، تضمین تعداد خرید انجام شده از طریق بنر مربوطه است؛ پس به جای تخمین نرخ کلیک، احتمال انجام خرید از طریق تبلیغ نمایش داده شده تخمین زده میشود که به \trans{نرخ تبدیل}{Convertion Rate} معروف است. در عمل میتوان نرخ تبدیل را ضریبی از نرخ کلیک در نظر گرفت که به دلیل تنک بودن، کار کردن با آن چالش بیشتری دارد. در این پژوهش به دلیل محدودیت در مجموعههای دادهی انتخاب شده، تنها از نرخ کلیک استفاده میکنیم. | |||||
| \begin{figure} | |||||
| \center | |||||
| \includegraphics[width=0.9\textwidth]{images/RTB_Process} | |||||
| \caption{ | |||||
| فرآیند مزایدهی بلادرنگ | |||||
| } | |||||
| \label{fig:rtb-process} | |||||
| \end{figure} | |||||
| %================================================================== | |||||
| \section{چالشها} | |||||
| در تخمین نرخ کلیک و نرخ تبدیل، چالشهایی وجود دارند که کار پژوهش در این موضوع را دچار مشکل میکنند. در این بخش به اختصار در مورد این چالشها بحث میکنیم. | |||||
| \begin{itemize} | |||||
| \item \trans{چالش عدم توازن شدید کلاسها}{High class imbalance challenge} | |||||
| هنگام دستهبندی دودویی در مسالهای که دادهها به صورت نامتوازن هستند، با چالش جدی عدم توازن کلاسها روبرو هستیم.\cite{reference/ml/LingS17} در تبلیغات نمایشی، در بیشتر موارد کاربر روی تبلیغ کلیک نمیکند و یا پس از کلیک، بازدید کاربر از صفحهی مقصد به خرید (تبدیل) منتهی نمیشود و این شرایط باعث میشود این مساله نیز جزء مسائل مواجه با چالش عدم توازن شدید کلاسها باشد. | |||||
| \item \trans{چالش ابعاد بالا}{High dimentionality challenge} | |||||
| به دلیل وجود تعداد ابعاد ورودی بسیار بالا، رویارویی با این مساله با الگوریتمهای سادهی یادگیری ممکن نیست. این مشکل با نام دیگر \trans{نفرین ابعاد}{Curse of dimentionality} نیز معروف است. نفرین ابعاد باعث میشود تعداد پارامترهای مدل بیشتر شده و در نتیجه فرآیند یادگیری آن دچار مشکلات متنوعی شود.\cite{pires2019high} | |||||
| \item \trans{چالش شروع سرد}{Cold start challenge} | |||||
| وقتی یک تبلیغ جدید برای نمایش اضافه میشود، سکوهای سمت نیاز هیچ اطلاعاتی در مورد آن و کاربرهایی که احتمالا به آن تبلیغ علاقه نشان دهند، ندارند؛ لذا تعداد زیادی از موقعیتهای قابل تبلیغ و در نتیجه میزان قابل توجهی هزینه صرف شناسایی تبلیغ جدید میشود. از طرفی، کاربر جدیدی که شروع به بازدید از صفحات مربوط به ناشرین میکند، از طرف سکوهای سمت تامین مورد نظر شناخته شده نیست؛ پس وقت و هزینهی زیادی صرف شناختن سلایق این کاربر جدید میشود. این مشکل در ادبیات \trans{سیستمهای پیشنهاد دهنده}{Recommender systems} به نام شروع سرد معروف است.\cite{journals/eswa/LikaKH14, DBLP:journals/corr/abs-1004-3732} | |||||
| \item چالش سرعت آموزش | |||||
| بسیاری از شرکتهایی که خدمات مربوط به مزایدههای بلادرنگ را ارائه میدهند، به دلیل تغییرات روزانهی زیاد در مجموعههای داده، عمل آموزش مدلهایشان را در فواصل زمانی کوتاه (مثلا هر روز) تکرار میکنند. پس مدلهایی که آموزش آنها زمانبر باشد، قابل استفاده در عمل نخواهند بود؛ لذا علاوه بر چالشهایی که ذکر شد، مدل ارائه شده باید توازنی بین عملکرد مناسب و سرعت آموزش ایجاد کند. | |||||
| \end{itemize} | |||||
| \section{هدف پژوهش} | |||||
| در فرآیند مزایدههای بلادرنگ، تنها نکتهای که در آن اجماع عمومی وجود ندارد، روشی است که با آن نرخ کلیک یا نرخ تبدیل تخمین زده شده و هزینهی پرداختی به هر موقعیت قابل تبلیغ بر مبنای آن محاسبه و پیشنهاد میشود؛ لذا هدف کلی این پژوهش، ارائهی یک مدل یادگیری ماشین برای تخمین نرخ کلیک است. | |||||
| \section{پرسشهای اساسی پژوهش} | |||||
| برای رسیدن به هدف کلی این پژوهش که ارائهی یک راهکار جدید برای تخمین نرخ کلیک است، باید مشخص شود که \textbf{چه راهکاری برای مواجهه با چالشهای موجود، مناسب بوده و میتواند با وجود همهی این چالشها تخمین قابل قبولی از نرخ کلیک ارائه دهد؟} بنابراین، پرسشهای زیر پیشرویمان خواهد بود: | |||||
| \begin{enumerate} | |||||
| \item روشهای موجود برای تخمین نرخ کلیک در تبلیغات نمایشی، کدامند؟ | |||||
| \item هریک از چالشهای مهم تخمین نرخ کلیک، چه تاثیری بر عملکرد روشها میگذارند؟ | |||||
| \item روش مناسبی که با این چالشها رویارو شود، باید چه ویژگیهایی داشته باشد؟ | |||||
| \end{enumerate} | |||||
| \section{ساختار رساله} | |||||
| در فصل دوم این رساله، پس از معرفی برخی از پیشنیازها، روشهای پیشین را معرفی، دستهبندی و مقایسه کرده و در مورد مزایا و معایب هرکدام در رویارویی با چالشهای مربوط به مساله میاندیشیم. در فصل سوم، با توجه به چالشها و کاستیهای روشهای پیشین، مدل پیشنهادی خود را گام به گام طراحی کرده و با ارائهی دلایل شهودی و ریاضی، ایدههای ارائه شده را توجیه میکنیم؛ سپس مدل پیشنهادی را فرمولهبندی کرده و پیشنیازهای لازم برای آموزش آن در چارچوب گرادیان کاهشی را ارائه مینماییم. با توجه به اکتشافی بودن فرآیند طراحی مدل پیشنهادی، بدون تثبیت گامهای ابتدایی، یافتن گامهای بعدی ممکن نخواهد بود؛ لذا با برداشتن هر گام، چگونگی اجرای گام بعدی خودنمایی خواهد کرد. در فصل چهارم، پس از معرفی مجموعههای داده و معیارهای ارزیابی استفاده شده، آزمایشهای گوناگونی را طراحی و اجرا کرده و بر اساس نتایج این آزمایشها، مدل پیشنهادی را از ابعاد مختلف سنجیده و سپس آن را با روشهای پیشین مقایسه میکنیم. در فصل پنجم این رساله، از پژوهش انجام شده نتیجه گیری کرده و گامهایی را برای ادامهی پژوهش در این مسیر معرفی مینماییم. | |||||
+ 312
- 0
Thesis/chap2.aux
View File
| \relax | |||||
| \providecommand\zref@newlabel[2]{} | |||||
| \providecommand\hyper@newdestlabel[2]{} | |||||
| \citation{boser1992} | |||||
| \zref@newlabel{zref@35}{\abspage{17}\page{10}\pagevalue{10}} | |||||
| \@writefile{toc}{\contentsline {chapter}{فصل\nobreakspace {}\numberline {2}پژوهشهای پیشین}{10}{chapter.2}} | |||||
| \@writefile{lof}{\addvspace {10\p@ }} | |||||
| \@writefile{lot}{\addvspace {10\p@ }} | |||||
| \newlabel{Chap:Chap2}{{2}{10}{پژوهشهای پیشین}{chapter.2}{}} | |||||
| \@writefile{toc}{\contentsline {section}{\numberline {2-1}روشهای کلاسیک}{10}{section.2.1}} | |||||
| \zref@newlabel{footdir@75}{\abspage{17}} | |||||
| \zref@newlabel{zref@36}{\abspage{17}\page{10}\pagevalue{10}} | |||||
| \zref@newlabel{footdir@81}{\abspage{17}} | |||||
| \zref@newlabel{footdir@76}{\abspage{17}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {2-1-1}ماشینهای بردار پشتیبان}{11}{subsection.2.1.1}} | |||||
| \zref@newlabel{footdir@79}{\abspage{18}} | |||||
| \zref@newlabel{zref@38}{\abspage{18}\page{11}\pagevalue{11}} | |||||
| \zref@newlabel{footdir@77}{\abspage{18}} | |||||
| \zref@newlabel{zref@37}{\abspage{18}\page{11}\pagevalue{11}} | |||||
| \zref@newlabel{footdir@82}{\abspage{18}} | |||||
| \zref@newlabel{footdir@78}{\abspage{18}} | |||||
| \zref@newlabel{footdir@80}{\abspage{18}} | |||||
| \citation{Gai_piecewise} | |||||
| \citation{lecun_sgd} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{مدل تکهای خطی\cite {Gai_piecewise}}{12}{section*.5}} | |||||
| \zref@newlabel{footdir@83}{\abspage{19}} | |||||
| \zref@newlabel{zref@39}{\abspage{19}\page{12}\pagevalue{12}} | |||||
| \zref@newlabel{footdir@85}{\abspage{19}} | |||||
| \zref@newlabel{zref@40}{\abspage{19}\page{12}\pagevalue{12}} | |||||
| \zref@newlabel{footdir@87}{\abspage{19}} | |||||
| \zref@newlabel{zref@41}{\abspage{19}\page{12}\pagevalue{12}} | |||||
| \zref@newlabel{footdir@89}{\abspage{19}} | |||||
| \zref@newlabel{zref@42}{\abspage{19}\page{12}\pagevalue{12}} | |||||
| \zref@newlabel{footdir@91}{\abspage{19}} | |||||
| \zref@newlabel{footdir@84}{\abspage{19}} | |||||
| \zref@newlabel{footdir@86}{\abspage{19}} | |||||
| \zref@newlabel{footdir@88}{\abspage{19}} | |||||
| \zref@newlabel{footdir@90}{\abspage{19}} | |||||
| \citation{lbfgs_2008} | |||||
| \citation{Graepel_2010} | |||||
| \zref@newlabel{footdir@94}{\abspage{20}} | |||||
| \zref@newlabel{zref@44}{\abspage{20}\page{13}\pagevalue{13}} | |||||
| \zref@newlabel{footdir@92}{\abspage{20}} | |||||
| \zref@newlabel{zref@43}{\abspage{20}\page{13}\pagevalue{13}} | |||||
| \zref@newlabel{footdir@96}{\abspage{20}} | |||||
| \zref@newlabel{zref@45}{\abspage{20}\page{13}\pagevalue{13}} | |||||
| \zref@newlabel{footdir@98}{\abspage{20}} | |||||
| \zref@newlabel{zref@46}{\abspage{20}\page{13}\pagevalue{13}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{مدل بیزی\cite {Graepel_2010}}{13}{section*.6}} | |||||
| \zref@newlabel{footdir@102}{\abspage{20}} | |||||
| \zref@newlabel{zref@48}{\abspage{20}\page{13}\pagevalue{13}} | |||||
| \zref@newlabel{footdir@100}{\abspage{20}} | |||||
| \zref@newlabel{zref@47}{\abspage{20}\page{13}\pagevalue{13}} | |||||
| \zref@newlabel{footdir@106}{\abspage{20}} | |||||
| \zref@newlabel{zref@50}{\abspage{20}\page{13}\pagevalue{13}} | |||||
| \zref@newlabel{footdir@104}{\abspage{20}} | |||||
| \zref@newlabel{zref@49}{\abspage{20}\page{13}\pagevalue{13}} | |||||
| \zref@newlabel{footdir@108}{\abspage{20}} | |||||
| \zref@newlabel{zref@51}{\abspage{20}\page{13}\pagevalue{13}} | |||||
| \zref@newlabel{footdir@110}{\abspage{20}} | |||||
| \zref@newlabel{footdir@93}{\abspage{20}} | |||||
| \zref@newlabel{footdir@95}{\abspage{20}} | |||||
| \zref@newlabel{footdir@97}{\abspage{20}} | |||||
| \zref@newlabel{footdir@99}{\abspage{20}} | |||||
| \zref@newlabel{footdir@101}{\abspage{20}} | |||||
| \zref@newlabel{footdir@103}{\abspage{20}} | |||||
| \zref@newlabel{footdir@105}{\abspage{20}} | |||||
| \zref@newlabel{footdir@107}{\abspage{20}} | |||||
| \zref@newlabel{footdir@109}{\abspage{20}} | |||||
| \zref@newlabel{footdir@111}{\abspage{21}} | |||||
| \zref@newlabel{zref@52}{\abspage{21}\page{14}\pagevalue{14}} | |||||
| \zref@newlabel{footdir@113}{\abspage{21}} | |||||
| \zref@newlabel{zref@53}{\abspage{21}\page{14}\pagevalue{14}} | |||||
| \zref@newlabel{footdir@117}{\abspage{21}} | |||||
| \zref@newlabel{zref@55}{\abspage{21}\page{14}\pagevalue{14}} | |||||
| \zref@newlabel{footdir@115}{\abspage{21}} | |||||
| \zref@newlabel{zref@54}{\abspage{21}\page{14}\pagevalue{14}} | |||||
| \zref@newlabel{footdir@119}{\abspage{21}} | |||||
| \zref@newlabel{footdir@112}{\abspage{21}} | |||||
| \zref@newlabel{footdir@114}{\abspage{21}} | |||||
| \zref@newlabel{footdir@116}{\abspage{21}} | |||||
| \zref@newlabel{footdir@118}{\abspage{21}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {2-1-2}ماشینهای فاکتورگیری}{15}{subsection.2.1.2}} | |||||
| \zref@newlabel{footdir@120}{\abspage{22}} | |||||
| \zref@newlabel{zref@56}{\abspage{22}\page{15}\pagevalue{15}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{ایدهی فیلدها و شیوهی نگرش به دادهها در ماشینهای فاکتورگیری}{15}{section*.7}} | |||||
| \zref@newlabel{footdir@122}{\abspage{22}} | |||||
| \zref@newlabel{zref@57}{\abspage{22}\page{15}\pagevalue{15}} | |||||
| \zref@newlabel{footdir@124}{\abspage{22}} | |||||
| \zref@newlabel{zref@58}{\abspage{22}\page{15}\pagevalue{15}} | |||||
| \zref@newlabel{footdir@126}{\abspage{22}} | |||||
| \zref@newlabel{zref@59}{\abspage{22}\page{15}\pagevalue{15}} | |||||
| \zref@newlabel{footdir@128}{\abspage{22}} | |||||
| \zref@newlabel{zref@60}{\abspage{22}\page{15}\pagevalue{15}} | |||||
| \zref@newlabel{footdir@130}{\abspage{22}} | |||||
| \zref@newlabel{zref@61}{\abspage{22}\page{15}\pagevalue{15}} | |||||
| \zref@newlabel{footdir@134}{\abspage{22}} | |||||
| \zref@newlabel{footdir@121}{\abspage{22}} | |||||
| \zref@newlabel{footdir@123}{\abspage{22}} | |||||
| \zref@newlabel{footdir@125}{\abspage{22}} | |||||
| \zref@newlabel{footdir@127}{\abspage{22}} | |||||
| \zref@newlabel{footdir@129}{\abspage{22}} | |||||
| \zref@newlabel{footdir@131}{\abspage{22}} | |||||
| \citation{Rendle:2010ja} | |||||
| \zref@newlabel{footdir@132}{\abspage{23}} | |||||
| \zref@newlabel{zref@62}{\abspage{23}\page{16}\pagevalue{16}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{ماشینهای فاکتورگیری ساده\cite {Rendle:2010ja}}{16}{section*.8}} | |||||
| \zref@newlabel{footdir@135}{\abspage{23}} | |||||
| \zref@newlabel{zref@63}{\abspage{23}\page{16}\pagevalue{16}} | |||||
| \zref@newlabel{footdir@139}{\abspage{23}} | |||||
| \zref@newlabel{footdir@133}{\abspage{23}} | |||||
| \zref@newlabel{footdir@136}{\abspage{23}} | |||||
| \citation{Juan_fieldawarefm1} | |||||
| \citation{Juan_fieldawarefm2} | |||||
| \zref@newlabel{footdir@137}{\abspage{24}} | |||||
| \zref@newlabel{zref@64}{\abspage{24}\page{17}\pagevalue{17}} | |||||
| \zref@newlabel{footdir@140}{\abspage{24}} | |||||
| \zref@newlabel{zref@65}{\abspage{24}\page{17}\pagevalue{17}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{ماشینهای فاکتورگیری آگاه از فیلد\cite {Juan_fieldawarefm1, Juan_fieldawarefm2}}{17}{section*.9}} | |||||
| \zref@newlabel{footdir@142}{\abspage{24}} | |||||
| \zref@newlabel{footdir@138}{\abspage{24}} | |||||
| \zref@newlabel{footdir@141}{\abspage{24}} | |||||
| \citation{Pan_fieldweightedfm} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{ماشینهای فاکتورگیری با فیلدهای وزندار\cite {Pan_fieldweightedfm}}{18}{section*.10}} | |||||
| \citation{Freudenthaler2011BayesianFM} | |||||
| \zref@newlabel{footdir@143}{\abspage{26}} | |||||
| \zref@newlabel{zref@66}{\abspage{26}\page{19}\pagevalue{19}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{ماشینهای فاکتورگیری تنک}{19}{section*.11}} | |||||
| \zref@newlabel{footdir@145}{\abspage{26}} | |||||
| \zref@newlabel{footdir@144}{\abspage{26}} | |||||
| \citation{Pan_sparsefm} | |||||
| \zref@newlabel{footdir@146}{\abspage{27}} | |||||
| \zref@newlabel{zref@67}{\abspage{27}\page{20}\pagevalue{20}} | |||||
| \zref@newlabel{footdir@148}{\abspage{27}} | |||||
| \zref@newlabel{zref@68}{\abspage{27}\page{20}\pagevalue{20}} | |||||
| \zref@newlabel{footdir@150}{\abspage{27}} | |||||
| \zref@newlabel{zref@69}{\abspage{27}\page{20}\pagevalue{20}} | |||||
| \zref@newlabel{footdir@152}{\abspage{27}} | |||||
| \zref@newlabel{zref@70}{\abspage{27}\page{20}\pagevalue{20}} | |||||
| \zref@newlabel{footdir@154}{\abspage{27}} | |||||
| \zref@newlabel{footdir@147}{\abspage{27}} | |||||
| \zref@newlabel{footdir@149}{\abspage{27}} | |||||
| \zref@newlabel{footdir@151}{\abspage{27}} | |||||
| \zref@newlabel{footdir@153}{\abspage{27}} | |||||
| \citation{Xiao_afm} | |||||
| \zref@newlabel{footdir@155}{\abspage{28}} | |||||
| \zref@newlabel{zref@71}{\abspage{28}\page{21}\pagevalue{21}} | |||||
| \zref@newlabel{footdir@157}{\abspage{28}} | |||||
| \zref@newlabel{zref@72}{\abspage{28}\page{21}\pagevalue{21}} | |||||
| \zref@newlabel{footdir@159}{\abspage{28}} | |||||
| \zref@newlabel{zref@73}{\abspage{28}\page{21}\pagevalue{21}} | |||||
| \zref@newlabel{footdir@161}{\abspage{28}} | |||||
| \zref@newlabel{zref@74}{\abspage{28}\page{21}\pagevalue{21}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{ماشین فاکتورگیری با توجه\cite {Xiao_afm}}{21}{section*.12}} | |||||
| \zref@newlabel{footdir@163}{\abspage{28}} | |||||
| \zref@newlabel{zref@75}{\abspage{28}\page{21}\pagevalue{21}} | |||||
| \zref@newlabel{footdir@165}{\abspage{28}} | |||||
| \zref@newlabel{footdir@156}{\abspage{28}} | |||||
| \zref@newlabel{footdir@158}{\abspage{28}} | |||||
| \zref@newlabel{footdir@160}{\abspage{28}} | |||||
| \zref@newlabel{footdir@162}{\abspage{28}} | |||||
| \zref@newlabel{footdir@164}{\abspage{28}} | |||||
| \citation{srivastava2014dropout} | |||||
| \citation{tikhonov1943stability} | |||||
| \citation{journals/corr/ZhangYS17aa} | |||||
| \zref@newlabel{footdir@168}{\abspage{29}} | |||||
| \zref@newlabel{zref@77}{\abspage{29}\page{22}\pagevalue{22}} | |||||
| \zref@newlabel{footdir@166}{\abspage{29}} | |||||
| \zref@newlabel{zref@76}{\abspage{29}\page{22}\pagevalue{22}} | |||||
| \zref@newlabel{footdir@170}{\abspage{29}} | |||||
| \zref@newlabel{footdir@167}{\abspage{29}} | |||||
| \zref@newlabel{footdir@169}{\abspage{29}} | |||||
| \citation{Chen_deepctr} | |||||
| \citation{he2015residual} | |||||
| \citation{Nair_relu} | |||||
| \citation{Guo_embedding_2016} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {2-1-3}روشهای ژرف}{23}{subsection.2.1.3}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{مدل ژرف پیشبینی نرخ کلیک\cite {Chen_deepctr}}{23}{section*.13}} | |||||
| \zref@newlabel{footdir@171}{\abspage{30}} | |||||
| \zref@newlabel{zref@78}{\abspage{30}\page{23}\pagevalue{23}} | |||||
| \zref@newlabel{footdir@173}{\abspage{30}} | |||||
| \zref@newlabel{zref@79}{\abspage{30}\page{23}\pagevalue{23}} | |||||
| \zref@newlabel{footdir@175}{\abspage{30}} | |||||
| \zref@newlabel{zref@80}{\abspage{30}\page{23}\pagevalue{23}} | |||||
| \zref@newlabel{footdir@183}{\abspage{30}} | |||||
| \zref@newlabel{footdir@172}{\abspage{30}} | |||||
| \zref@newlabel{footdir@174}{\abspage{30}} | |||||
| \zref@newlabel{footdir@176}{\abspage{30}} | |||||
| \citation{ioffe2015batch} | |||||
| \citation{Guo_deepfm1} | |||||
| \citation{Guo_deepfm2} | |||||
| \zref@newlabel{footdir@177}{\abspage{31}} | |||||
| \zref@newlabel{zref@81}{\abspage{31}\page{24}\pagevalue{24}} | |||||
| \zref@newlabel{footdir@179}{\abspage{31}} | |||||
| \zref@newlabel{zref@82}{\abspage{31}\page{24}\pagevalue{24}} | |||||
| \zref@newlabel{footdir@181}{\abspage{31}} | |||||
| \zref@newlabel{zref@83}{\abspage{31}\page{24}\pagevalue{24}} | |||||
| \zref@newlabel{footdir@184}{\abspage{31}} | |||||
| \zref@newlabel{zref@84}{\abspage{31}\page{24}\pagevalue{24}} | |||||
| \zref@newlabel{footdir@186}{\abspage{31}} | |||||
| \zref@newlabel{zref@85}{\abspage{31}\page{24}\pagevalue{24}} | |||||
| \zref@newlabel{footdir@188}{\abspage{31}} | |||||
| \zref@newlabel{zref@86}{\abspage{31}\page{24}\pagevalue{24}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{ماشین فاکتورگیری ژرف\cite {Guo_deepfm1, Guo_deepfm2}}{24}{section*.14}} | |||||
| \zref@newlabel{footdir@190}{\abspage{31}} | |||||
| \zref@newlabel{footdir@178}{\abspage{31}} | |||||
| \zref@newlabel{footdir@180}{\abspage{31}} | |||||
| \zref@newlabel{footdir@182}{\abspage{31}} | |||||
| \zref@newlabel{footdir@185}{\abspage{31}} | |||||
| \zref@newlabel{footdir@187}{\abspage{31}} | |||||
| \zref@newlabel{footdir@189}{\abspage{31}} | |||||
| \citation{Cheng_wideanddeep} | |||||
| \zref@newlabel{footdir@193}{\abspage{32}} | |||||
| \zref@newlabel{zref@88}{\abspage{32}\page{25}\pagevalue{25}} | |||||
| \zref@newlabel{footdir@191}{\abspage{32}} | |||||
| \zref@newlabel{zref@87}{\abspage{32}\page{25}\pagevalue{25}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{مدل وسیع و ژرف\cite {Cheng_wideanddeep}}{25}{section*.15}} | |||||
| \zref@newlabel{footdir@197}{\abspage{32}} | |||||
| \zref@newlabel{zref@90}{\abspage{32}\page{25}\pagevalue{25}} | |||||
| \zref@newlabel{footdir@195}{\abspage{32}} | |||||
| \zref@newlabel{zref@89}{\abspage{32}\page{25}\pagevalue{25}} | |||||
| \zref@newlabel{footdir@199}{\abspage{32}} | |||||
| \zref@newlabel{footdir@192}{\abspage{32}} | |||||
| \zref@newlabel{footdir@194}{\abspage{32}} | |||||
| \zref@newlabel{footdir@196}{\abspage{32}} | |||||
| \zref@newlabel{footdir@198}{\abspage{32}} | |||||
| \citation{Wang_asae} | |||||
| \citation{Ballard_autoencoder} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{خودکدگذار پشته شدهی دارای توجه\cite {Wang_asae}}{26}{section*.16}} | |||||
| \zref@newlabel{footdir@200}{\abspage{33}} | |||||
| \zref@newlabel{zref@91}{\abspage{33}\page{26}\pagevalue{26}} | |||||
| \zref@newlabel{footdir@202}{\abspage{33}} | |||||
| \zref@newlabel{zref@92}{\abspage{33}\page{26}\pagevalue{26}} | |||||
| \zref@newlabel{footdir@208}{\abspage{33}} | |||||
| \zref@newlabel{footdir@201}{\abspage{33}} | |||||
| \zref@newlabel{footdir@203}{\abspage{33}} | |||||
| \zref@newlabel{footdir@206}{\abspage{34}} | |||||
| \zref@newlabel{zref@94}{\abspage{34}\page{27}\pagevalue{27}} | |||||
| \zref@newlabel{footdir@204}{\abspage{34}} | |||||
| \zref@newlabel{zref@93}{\abspage{34}\page{27}\pagevalue{27}} | |||||
| \zref@newlabel{footdir@209}{\abspage{34}} | |||||
| \zref@newlabel{zref@95}{\abspage{34}\page{27}\pagevalue{27}} | |||||
| \zref@newlabel{footdir@211}{\abspage{34}} | |||||
| \zref@newlabel{footdir@205}{\abspage{34}} | |||||
| \zref@newlabel{footdir@207}{\abspage{34}} | |||||
| \zref@newlabel{footdir@210}{\abspage{34}} | |||||
| \citation{boser1992} | |||||
| \citation{Gai_piecewise} | |||||
| \citation{Graepel_2010} | |||||
| \citation{Rendle:2010ja} | |||||
| \citation{Juan_fieldawarefm1} | |||||
| \citation{Juan_fieldawarefm2} | |||||
| \citation{Pan_fieldweightedfm} | |||||
| \citation{Freudenthaler2011BayesianFM} | |||||
| \citation{Pan_sparsefm} | |||||
| \citation{Xiao_afm} | |||||
| \citation{Chen_deepctr} | |||||
| \citation{Guo_deepfm1} | |||||
| \citation{Guo_deepfm2} | |||||
| \citation{Cheng_wideanddeep} | |||||
| \citation{Wang_asae} | |||||
| \@writefile{lot}{\contentsline {table}{\numberline {2-1}{\ignorespaces خلاصهی روشهای اصلی مطالعه شده\relax }}{29}{table.caption.17}} | |||||
| \newlabel{tbl:notation}{{2-1}{29}{خلاصهی روشهای اصلی مطالعه شده\relax }{table.caption.17}{}} | |||||
| \@setckpt{chap2}{ | |||||
| \setcounter{page}{30} | |||||
| \setcounter{equation}{17} | |||||
| \setcounter{enumi}{3} | |||||
| \setcounter{enumii}{0} | |||||
| \setcounter{enumiii}{0} | |||||
| \setcounter{enumiv}{0} | |||||
| \setcounter{footnote}{3} | |||||
| \setcounter{mpfootnote}{0} | |||||
| \setcounter{part}{0} | |||||
| \setcounter{chapter}{2} | |||||
| \setcounter{section}{1} | |||||
| \setcounter{subsection}{3} | |||||
| \setcounter{subsubsection}{0} | |||||
| \setcounter{paragraph}{0} | |||||
| \setcounter{subparagraph}{0} | |||||
| \setcounter{figure}{0} | |||||
| \setcounter{table}{1} | |||||
| \setcounter{parentequation}{0} | |||||
| \setcounter{ALC@unique}{0} | |||||
| \setcounter{ALC@line}{0} | |||||
| \setcounter{ALC@rem}{0} | |||||
| \setcounter{ALC@depth}{0} | |||||
| \setcounter{float@type}{8} | |||||
| \setcounter{algorithm}{0} | |||||
| \setcounter{ContinuedFloat}{0} | |||||
| \setcounter{KVtest}{0} | |||||
| \setcounter{subfigure}{0} | |||||
| \setcounter{subfigure@save}{0} | |||||
| \setcounter{lofdepth}{1} | |||||
| \setcounter{subtable}{0} | |||||
| \setcounter{subtable@save}{0} | |||||
| \setcounter{lotdepth}{1} | |||||
| \setcounter{pp@next@reset}{0} | |||||
| \setcounter{zpage}{27} | |||||
| \setcounter{@pps}{0} | |||||
| \setcounter{@ppsavesec}{0} | |||||
| \setcounter{@ppsaveapp}{0} | |||||
| \setcounter{Item}{3} | |||||
| \setcounter{Hfootnote}{93} | |||||
| \setcounter{Hy@AnnotLevel}{0} | |||||
| \setcounter{bookmark@seq@number}{18} | |||||
| \setcounter{su@anzahl}{0} | |||||
| \setcounter{LT@tables}{0} | |||||
| \setcounter{LT@chunks}{0} | |||||
| \setcounter{footdir@label}{211} | |||||
| \setcounter{shadetheorem}{0} | |||||
| \setcounter{section@level}{3} | |||||
| } |
+ 34816
- 0
Thesis/chap2.log
File diff suppressed because it is too large
View File
BIN
Thesis/chap2.synctex.gz
View File
+ 560
- 0
Thesis/chap2.tex
View File
| % !TEX encoding = UTF-8 Unicode | |||||
| \chapter{پژوهشهای پیشین}\label{Chap:Chap2} | |||||
| در این فصل پژوهشهای پیشین در حوزهی پیشبینی نرخ کلیک را بررسی و طبقه بندی کرده و نقاط قوت و ضعف آنها را بررسی میکنیم. این بررسی را از روشهای کلاسیک یادگیری ماشین آغاز کرده و سپس با معرفی خانوادهای از مدلها به نام ماشین فاکتورگیری و مدلهای مقتبس از آن، این بررسی را ادامه میدهیم؛ سپس به سراغ مدلهای ژرف رفته و پس از آن، با مقایسهی نهایی این مدلها و بررسی مزایا و معایب هریک از آنها، این فصل را به پایان میبریم. | |||||
| \section{روشهای کلاسیک} | |||||
| همانطور که در فصل قبل بیان کردیم، مسالهی پیشبینی نرخ کلیک را میتوان یک مسالهی \trans{دسته بندی}{Classification} که از مسائل پایهای یادگیری ماشین است، در نظر گرفته و لذا از روشهای موجود در ادبیات یادگیری ماشین، برای حل این مساله کمک گرفت. | |||||
| اولین تلاشها برای حل مسالهی پیشبینی نرخ کلیک، به استفاده از روشهای کلاسیک یادگیری ماشین انجامید. هرچند چالشهایی که در فصل قبل معرفی کردیم، عملکرد این روشها را محدود و نتایج آنها را تحت تاثیر قرار میدادند؛ اما به دلیل نبود روش جایگزین، این روشها در بسیاری از موارد به عنوان تنها روشهای ممکن در نظر گرفته شده و برای حل مسالهی پیشبینی نرخ کلیک به کار بسته میشدند. | |||||
| در این بخش به بررسی برخی از این پژوهشها که برخی از آنها قدمت زیادی دارند، میپردازیم. ابتدا استفاده از ماشینهای بردار پشتیبان برای پیشبینی نرخ کلیک را بررسی میکنیم؛ سپس روشهای دیگر این دسته از قبیل رگرسیون تکهای خطی و یک مدل رگرسیون بیزی را معرفی میکنیم. | |||||
| \subsection{ماشینهای بردار پشتیبان} | |||||
| در ادبیات یادگیری ماشین کلاسیک، ماشینهای بردار پشتیبان\cite{boser1992} سابقهی پژوهشی برجسته و مهمی دارند. ماشینهای بردار پشتیبان بر اساس در نظر گرفتن ارتباط خطی بین ورودی و خروجی، مسالهی رگرسیون را حل میکنند. یادگیری پارامترهای ماشین بردار پشتیبان به دلیل استفاده از روشهای \trans{برنامهریزی درجه دوم}{Quadratic Programming} و بهره بردن از \trans{فرم دوگان}{Dual Form} بسیار سریع است. پس از اتمام فرآیند آموزش، مدل ماشین بردار پشتیبان، خروجی مساله را به صورت یک رابطهی خطی ارائه میدهد: | |||||
| \begin{latin} | |||||
| \begin{align} | |||||
| \hat{y}(x) = w_{0} + \sum_{i = 1}^{n} w_{i} x_{i},\qquad w_{0} \in \mathbb{R} ,\quad w \in \mathbb{R}^{n} | |||||
| \end{align} | |||||
| \end{latin} | |||||
| در این رابطه $x$ ورودی، $\hat{y}$ خروجی، $n$ تعداد ابعاد ورودی و $w_{0}$ و $w$ پارامترهای مدل هستند که در فرآیند آموزش تخمین زده میشوند. همانطور که از این رابطه مشخص است، عدم پشتیبانی ماشینهای بردار پشتیبان از ارتباطهای غیر خطی بین ورودی و خروجی باعث سادگی بیش از حد این مدل میشود. در ادبیات یادگیری ماشین کلاسیک، برای حل این مشکل، نسخهی کرنل دار این ماشینها استفاده میشود. در ماشینهای بردار پشتیبان با کرنل چندجملهای درجه دوم، به عبارت بالا یک جملهی دیگر اضافه میشود تا پیچیدگی کافی برای حل مساله را به مدل اضافه کند. رابطهی پیشبینی ماشین بردار پشتیبان با کرنل چندجملهای درجه دوم به صورت زیر است: | |||||
| \begin{latin} | |||||
| \begin{align} | |||||
| \hat{y}(x) = w_{0} + \sum_{i = 1}^{n} w_{i} x_{i} + \sum_{i = 1}^{n - 1}\sum_{j = i + 1}^{n}w^{'}_{i, j}x_{i}x_{j} ,\qquad w_{0} \in \mathbb{R} ,\quad w \in \mathbb{R}^{n} ,\quad w' \in \mathbb{R}^{n \times n} | |||||
| \end{align} | |||||
| \end{latin} | |||||
| که $w'$ پارامترهایی هستند که به این مدل اضافه شدهاند. میتوان جملهی آخر این عبارت را به تاثیر حضور همزمان دو ویژگی مختلف $x_{i}$ و $x_{j}$ در خروجی مدل تعبیر کرد. | |||||
| همانطور که انتظار میرود، این مدل دچار ایراداتی اساسی در طراحی آن است. در صورتی که به پارامترهای این مدل توجه کنیم، متوجه میشویم که تعداد پارامترهای این مدل بسیار زیاد است؛ پس برای تکمیل فرآیند یادگیری برای این تعداد پارامتر، نیاز به تعداد بسیار زیادی داده وجود دارد که چنین تعدادی از دادهها در دسترس نیست. علاوه بر این، در صورتی که به تفسیر جملهی دوم این عبارت توجه کنیم، متوجه میشویم که هرکدام از درایههای ماتریس $w'$ تنها زمانی استفاده (و لذا آموزش داده) میشوند که هر دو ویژگی مربوطه حاضر باشند. این در حالی است که میدانیم بسیاری از جفت ویژگیهای مجموعههای داده در مسالهی پیشبینی نرخ کلیک، تعداد دفعات بسیار کمی در کنار هم رخ داده و در بسیاری از حالات، هرگز به صورت همزمان رخ نمیدهند. این مشکلات توان یادگیری این مدل را به شدت تهدید کرده و لذا در بسیاری از شرایط، نتایج قابل قبولی ارائه نمیدهند. | |||||
| به دلیل همهی مشکلات گفته شده، ماشینهای بردار پشتیبان نقش کمتری در پژوهشهای امروزی در اکثر مسالهها، خصوصا مسالهی پیشبینی نرخ کلیک ایفا میکنند. | |||||
| \subsubsection{مدل تکهای خطی\cite{Gai_piecewise}} | |||||
| در ادامهی بررسی روشهای کلاسیک یادگیری ماشین برای حل مسالهی پیشبینی نرخ کلیک و رویارویی با چالش ابعاد بالا و غیرخطی بودن روابط بین ویژگیها و خروجی، به بررسی مدل تکهای خطی میپردازیم. این مدل قبل از انتشار در مقالات پژوهشی، به مدت قابل توجهی در شرکت \trans{علیبابا}{Alibaba} به عنوان روش اصلی حل مسالهی پیشبینی نرخ کلیک استفاده شده است. | |||||
| از آنجا که جزئیات مسالهی مورد بررسی، نیاز به انعطاف غیر خطی را ایجاب میکند، لذا محققین شرکت علیبابا برای یافتن یک مدل غیرخطی مناسب، تمرکز خود را بر ترکیب مدلهای خطی به شیوهای که بتوانند در کنار هم عملکرد غیرخطی داشته باشند؛ قرار دادند؛پس یک مدل ساده و عمومی از ترکیب مدلهای خطی معرفی کردند. در این مدل، نیمی از پارامترها برای تفکیک فضای داده به بخشهایی که در هر کدام یک یا ترکیبی از چند مدل جزئی در آن عملکرد قابل قبولی داشته باشند؛ و نیمهی دیگر پارامترها را برای آموزش مدلهای جزئی در آن بخشها اختصاص داده شده است. رابطهی ریاضی این مدل کلی به صورت زیر است: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| y = g(\sum_{j=1}^{m}\sigma(u_{j}^{T}x) \eta(w_{j}^{T}x)) | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| که در آن، $\eta$ تابع تصمیمگیری مدلهای جزئی است. $\eta$ میتواند یک تابع توزیع احتمال دودویی مثل تابع \trans{سیگموید}{Sigmoid} باشد. همچنین تابع $\sigma$ میتواند یک تابع وزن دهی چند کلاسه باشد. در سادهترین حالت، تابع \trans{سافت مکس}{Softmax} میتواند این نقش را ایفا کند. بردارهای $u_{j}$ و $w_{j}$ پارامترهای مدل هستند و زیر نویس $j$ نشاندهندهی شمارهی مدلی است که به آن تعلق دارند. ابرپارامتر $m$ تعداد مدلهای جزئی را تعیین میکند که به دلیل جلوگیری از پیچیدگی بیش از حد مدل، اکثرا مقداری نزدیک به 12 دارد. همچنین تابع $g$ یک تابع نرمال ساز احتمال بوده و تنها نقش آن تبدیل تابع به وجود آمده به یک تابع توزیع احتمال معتبر است. | |||||
| این مدل میتواند به وسیلهی تابع خطایی نظیر \trans{قرینهی درستنمایی}{Negative likelihood} و به وسیلهی روشهای گرادیان کاهشی \cite{lecun_sgd} آموزش یابد. | |||||
| همچنین واضح است که در حالت کلی، و با افزایش تعداد مدلهای جزئی، این ساختار توانایی مدل کردن هر تابعی را دارد؛ در نتیجه مشکل پیچیدگی بیش از حد مدل، محققین را وادار به افزودن جملات تنظیم به تابع خطای مدل میکند. در این تحقیق از دو جملهی خطای زیر استفاده میشود: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| ||\theta||_{1} = \sum_{i = 1}^{d} \sum_{j = 1}^{2m} |\theta_{ij}| | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| ||\theta||_{2,1} = \sum_{i = 1}^{d} \sqrt{\sum_{j = 1}^{2m} \theta_{ij}^{2}} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| که در آن $d$ تعداد ابعاد دادهها و | |||||
| $\theta_{-, j}$ | |||||
| شامل $u_{j}$ و $w_{j}$ است. | |||||
| تنظیم نوع اول برای کاهش کلی تعداد پارامترهای غیر صفر و تنظیم نوع دوم باعث فشردگی میزان پارامترها به منظور کسب واریانس کمتر تعریف شدهاست؛ اما اضافه شدن این دو جمله، باعث میشود سطح خطا در فضای پارامترها، سطحی غیر \trans{محدب}{Convex} و غیر \trans{نرم}{Smooth} باشد؛ در نتیجه استفاده از روشهای کاهش گرادیان یا \trans{بیشینهسازی امید ریاضی}{Expectation Maximization} منطقی نیست. برای رفع این اشکال، محققین به روشی مشابه \trans{کواسی-نیوتون با حافظهی محدود}{LBFGS}\cite{lbfgs_2008} روی آورده و مدل را بدین طریق آموزش میدهند. همچنین در این پژوهش تعدادی تکنیک برای کاهش مصرف حافظه و زمان آموزش ارائه شده که این مدل را برای استفاده در صنعت مناسب میسازد. | |||||
| از مزایای این مدل میتوان به قابلیت تغییر قسمتهایی از مدل و انعطاف پذیری آن، پارامترهای تنک و تفسیر پذیری مناسب اشاره کرد. همچنین از معایب این روش میتوان به تعداد پارامتر بالا، کندی در زمان آموزش و تفاوت نسبتا جزئی نتایج آن با نتایج روشهای خطی مثل رگرسیون لجستیک اشاره نمود. | |||||
| \subsubsection{مدل بیزی\cite{Graepel_2010}} | |||||
| در پژوهشی دیگر، محققین شرکت مایکروسافت، برای سیستم \trans{جستجوی حمایت شده}{Sponsored search}ی \trans{بینگ}{Bing}، یک متد پیشبینی نرخ کلیک ارائه دادهاند. خروجی این پژوهش از سال 2009 در مقیاس بالا در جستجوی حمایت شدهی بینگ به کار بسته میشد. | |||||
| در این پژوهش، از تابع \trans{پرابیت}{Probit} (تابع تجمعی احتمال توزیع گاوسی)، برای \trans{نگاشت}{Mapping} از محور حقیقی، به توزیع احتمال استفاده میشود. به همین دلیل به این دسته روشها، \trans{رگرسیون پرابیت}{Probit Regression} گفته میشود. دلیل این نوع نامگذاری، تقابل این دسته از روشها با رگرسیونهای لجستیک است. همانطور که گفته شد، در رگرسیون لجستیک، از تابع سیگموید برای این نگاشت استفاده میشود. | |||||
| در این روش، با فرض گاوسی و مستقل بودن احتمال پیشین هر یک از پارامترهای مدل، مساله را به صورت یک مسالهی رگرسیون خطی در نظر میگیریم: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| p(w) = \prod_{i} N(w_{i}|\mu_{i}, \sigma_{i}^{2}) | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| حال با استفاده از دو متغیر \trans{نهفته}{Latent}ی $s$ و $t$ کار را پیشمی بریم. متغیر تصادفی $s$ به صورت ضرب داخلی بردار ورودیها در بردار وزنها تعریف شده و به صورت قطعی از روی ورودیها و وزنها قابل مقایسه است. متغیر تصادفی $t$ یک متغیر تصادفی گاوسی با میانگینی برابر با مقدار $s$ و واریانسی مشخص تعریف میشود. همچنین، خروجی این مدل ($y$) به وسیلهی یک تابع آستانه مثل تابع علامت روی متغیر $t$ به دست میآید. | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| s=w^{T}x | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| t \sim N(s, \sigma^{2}) | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| y=sign(t) | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| سپس به کمک دو متغیر تصادفی تعریف شده، توزیع احتمال شرطی خروجی نسبت به ورودی را اینگونه فاکتورگیری میکنیم: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| p(y, t, s, w|x) = p(y|t) p(t|s) p(s|x, w) p(w) | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| به دلیل غیر قابل محاسبه بودن توزیع پسین برای وزنها، استفاده از این روابط برای محاسبهی مستقیم مقادیر وزنها ممکن نیست؛ پس با استفاده از الگوریتمهای \trans{پیامرسانی}{Message passing} و تخمین توزیع پسین با توزیع گاوسی، مقادیر وزنها قابل آموزش میشوند. | |||||
| در این پژوهش، اندازهی گام به روز رسانی مقادیر پارامترها را در طول زمان کاهش داده و بدین طریق، آموزش مدل را تسریع میکنند. همچنین فرآیند \trans{اکتشاف}{Expolration} و \trans{بهره برداری}{Exploitation} نیز، بدین وسیله مدل میشود که برای نمونههایی با اطمینان بالا (واریانس پایین) عمل بهره برداری و برای نمونههایی با اطمینان پایین (واریانس بالا) عمل اکتشاف انجام داده میشود؛ به همین دلیل این روش نیز مانند بقیهی روشها، از مشکل شروع سرد رنج میبرد. | |||||
| نتایج عمدهی روشهایی که تا اینجا معرفی کردیم، به دلیل وجود چالشهایی که در فصل قبل مطرح شد، چندان قابل قبول نیستند؛ لذا از سال 2010 به بعد، توجه بخش عمدهای از پژوهشگران به سمت روشهایی تحت عنوان خانوادهی ماشینهای فاکتورگیری جلب شد. | |||||
| \subsection{ماشینهای فاکتورگیری} | |||||
| در این بخش به بررسی پژوهشهای خانوادهی ماشینهای فاکتورگیری میپردازیم. ایدهی اصلی استفاده از ماشینهای فاکتورگیری، استفاده از شیوهی به خصوصی از تنظیم است که باعث میشود مدل، قابلیت یادگیری خواص ترکیبی بین ویژگیهای مختلف و متعدد ورودی را با تعداد محدودی پارامتر داشته باشد. در ادبیات ماشینهای فاکتورگیری، به این خواص ترکیبی، \trans{تعامل}{Interaction} بین ویژگیها گفته میشود. در این بخش چند پژوهش در حوزهی ماشینهای فاکتورگیری از جمله پژوهشی که اولین بار از این ایده برای پیشبینی نرخ کلیک استفاده کرده است را بررسی میکنیم. | |||||
| \subsubsection{ایدهی فیلدها و شیوهی نگرش به دادهها در ماشینهای فاکتورگیری} | |||||
| در همهی پژوهشهای این دسته، نگرش خاصی به دادهها وجود دارد که در این بخش آن را معرفی میکنیم. در اغلب مجموعههای دادهی موجود در ادبیات تخمین نرخ کلیک و همچنین سیستمهای پیشنهاد دهنده، همه یا اکثر ویژگیها به صورت \trans{دستهای}{Categorical} هستند. مدلهای یادگیری ماشین برای برخورد مناسب با این نوع ویژگیها، از روشهای مختلفی از جمله | |||||
| \trans{کدگذاری یک از $k$}{One of k coding} | |||||
| استفاده میکنند. | |||||
| در روش کدگذاری 1 از $k$، ابتدا همهی مقادیر مختلف این ویژگی دستهای لیست شده، سپس به هر کدام یک شماره یا اندیس تخصیص داده میشود؛ سپس برای نمایش دادن حالتی که ویژگی دستهای مقدار $n$ام را داشته باشد، برداری به اندازهی $k$ (تعداد حالات ویژگی دستهای) ایجاد شده و همهی مقادیر آن (بجز خانهی اندیس $n$ام) صفر قرار داده میشود و در خانهی اندیس $n$ام، مقدار 1 قرار داده میشود؛ پس در هر حالت، تنها یکی از درایههای این بردار برابر یک بوده و بقیهی درایهها مقدار صفر دارند؛ به همین دلیل به این بردار، \trans{بردار تک داغ}{One hot vector} هم گفته میشود. | |||||
| در روشهای ماشین فاکتورگیری، به هر یک از ویژگیهای دستهای و بردارهای مربوط به آنها، یک \trans{فیلد}{Field} گفته میشود. همچنین به هر یک از درایههای این بردارها، یک \trans{ویژگی باینری}{Binary feature} گفته میشود. در این مدلها پس از کدگذاری همهی فیلدهای موجود در دادهها، بردارهای تک داغ ساخته شده را به هم چسبانده و یک \trans{بردار چند داغ}{Multi hot vector} ساخته میشود. این بردار به صورت مستقیم به عنوان ورودی مدلهای ماشین فاکتورگیری استفاده میشود. در اغلب مجموعههای دادهی در دسترس، تعداد فیلدها ($f$) بین 10 تا 50 بوده و تعداد ویژگیهای باینری ($n$) بین چند ده هزار تا چند ده میلیون است؛ لذا ورودی ماشینهای فاکتورگیری، بردارهایی به طول چند میلیون هستند که تنها چند ده درایهی غیر صفر دارند. | |||||
| \subsubsection{ماشینهای فاکتورگیری ساده\cite{Rendle:2010ja}} | |||||
| خانوادهی بزرگی از مدلهایی که برای محاسبهی نرخ کلیک استفاده میشوند، \trans{ماشینهای فاکتورگیری}{Factorization Machines} و نسخههای پیشرفتهی آنها هستند. تحقیقات بسیاری با پیادهسازی و پیشنهاد انواع جدید این خانواده، مسالهی پیشبینی نرخ کلیک را حل کرده و بهترین نتایج توسط همین تحقیقات ارائه شدهاند. | |||||
| ایدهی اصلی ماشینهای فاکتورگیری، همانطور که از نام آنها مشخص است، عمل فاکتورگیری ماتریسی است. عمل فاکتورگیری زمانی استفاده میشود که نیاز به تخمین زدن یک ماتریس وجود داشته باشد، اما به دلیل ابعاد بالای این ماتریس، قابلیت یادگیری همهی درایههای آن برای مدل موجود نباشد. مثلا ماشین بردار پشتیبان با کرنل چندجملهای درجه دوم که آن را در بخشهای قبل معرفی کردیم، ماتریس $w'$ که مشخص کنندهی وزن جملههای مرتبه دوم است، دقیقا همین شرایط را داراست؛ پس در پژوهشی که اولین بار ماشینهای فاکتورگیری را معرفی کرد، سراغ همین ماتریس رفته و عمل فاکتورگیری را روی آن انجام دادند. در ماشین فاکتورگیری، به جای این که فرض کنیم همهی درایههای این ماتریس پارامترهای مستقل و قابل یادگیری هستند، این ماتریس را حاصل ضرب یک ماتریس با ابعاد کمتر در ترانهادهی خودش فرض کرده و لذا رتبهی ماتریس $w'$ را کاهش میدهیم: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| w' = v.v^{T} ,\quad v \in \mathbb{R}^{n \times k} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| که در آن $k$ بعد تعبیه بوده و مقدار کمی (حدود 10) دارد؛ پس ماتریس $w'$ از روی ماتریس $v$ ساخته شده و در نتیجه مشکلات ذکر شده در ماشین بردار پشتیبان با کرنل چندجملهای درجه دوم در آن وجود ندارد. عبارت کامل رابطهی ماشینهای فاکتورگیری به این صورت است: | |||||
| \begin{latin} | |||||
| \begin{align} | |||||
| \hat{y}(x) = w_{0} + \sum_{i = 1}^{n} w_{i} x_{i} + \sum_{i = 1}^{n} \sum_{j = i + 1}^{n} w'_{i,j} x_{i} x_{j} ,\quad w'_{i,j} = \sum_{l = 1}^{k} v_{i,l} v_{j,l} , \: v_{i} \in \mathbb{R}^{k} | |||||
| \end{align} | |||||
| \end{latin} | |||||
| تعبیر دیگری که میتوانیم از این روابط داشته باشیم، عملکرد مناسب ماشینهای فاکتورگیری را بهتر نمایان میکند. میتوانیم ماتریس $v$ را به شکل یک \trans{جدول تعبیه}{Embedding Table} در نظر بگیریم؛ در نتیجه به ازای هر فیلد، تنها یکی از سطرهای این جدول انتخاب میشود. (بقیهی سطرها به دلیل اینکه $x_{i}$ مربوطه صفر است، تاثیری در خروجی ندارند.) در نهایت، حاصل ضرب داخلی بردارهای تعبیهی همهی فیلدها دو به دو محاسبه شده و نتایج آن با نتایج جملهی خطی جمع میشود. حاصل هر یک از این ضربهای داخلی، به نام تعامل بین دو ویژگی نیز شناخته میشود. در نهایت با اعمال تابع سیگموید، عدد حاصل به توزیع احتمال کلیک تبدیل میشود. | |||||
| همان طور که گفته شد، در ماشینهای فاکتورگیری علاوه بر ارتباط خطی بین خروجی و همهی ابعاد ورودی، تاثیر تعامل بین ابعاد ورودی نیز در خروجی در نظر گرفته میشود؛ لذا پیچیدگی ماشینهای فاکتورگیری از مدلهای رگرسیون خطی مثل ماشینهای بردار پشتیبان یا رگرسیون لجستیک بیشتر است و قادر به مدل کردن خانوادهی بزرگتری از توابع هستند. | |||||
| یکی از مهمترین فواید عدم استقلال درایههای ماتریس $w'$ از یکدیگر، در زمان مواجهه با دادههای \trans{تنک}{Sparse} مشخص میشود. خصوصا در مسالهی پیشبینی نرخ کلیک که تعداد ابعاد داده بسیار زیاد بوده ولی اکثر ویژگیهای داده به ندرت فعال (غیر صفر) هستند. اگر در اینگونه مسائل همهی ضرایب تعامل بین ویژگیها را مستقل در نظر بگیریم، به تعداد بسیار زیاد و گاها غیر قابل دسترس داده نیاز خواهیم داشت. در مقابل، هنگام استفاده از ماشینهای فاکتورگیری، به دلیل کاهش تعداد پارامترهای قابل یادگیری، با استفاده از تعداد دادهی کمتر، نتایج تعمیمپذیرتری قابل دستیابی هستند. | |||||
| علاوه بر این، در صورتی که در دادههای آموزشی، یک جفت ویژگی به صورت همزمان رخ نداده باشند، یادگیری وزن مربوط به آنها توسط ماشین بردار پشتیبان با کرنل چندجملهای درجه دوم غیر ممکن است. در حالی که در ماشینهای فاکتورگیری، در صورتی که این دو ویژگی به تعداد قابل قبول به صورت مجزا مشاهده شوند، بردارهای تعبیهی مربوط به آنها توسط ماشین فاکتورگیری یاد گرفته شده و لذا محاسبهی تعامل این دو ویژگی با وجود این که قبلا با هم مشاهده نشدهاند، ممکن خواهد بود. این مزیت ماشینهای فاکتورگیری قابلیت تعمیم آنها را افزایش داده و آنها را تا حدودی در مقابل چالش شروع سرد مقاوم میکند. | |||||
| ماشینهای فاکتورگیری ساده، عملکرد قابل توجهی روی مجموعههای دادهی مربوط به نرخ کلیک ارائه کرده و در صنعت نیز مورد استفاده قرار گرفتند؛ اما به دلیل سادگی زیاد، تعمیم آنها از جهات مختلف در دستور کار پژوهشگران قرار گرفت و روشهای متعددی برای تعمیم آنها معرفی شدند. در ادامه به بررسی برخی از این روشها میپردازیم. | |||||
| \subsubsection{ماشینهای فاکتورگیری آگاه از فیلد\cite{Juan_fieldawarefm1, Juan_fieldawarefm2}} | |||||
| ماشینهای فاکتورگیری ساده، برای محاسبهی تعامل بین دو ویژگی، از عمل ضرب داخلی بین بردار تعبیهی این دو ویژگی استفاده میکنند. در نتیجه برای محاسبهی تعامل یک ویژگی از فیلد اول، با یک ویژگی از فیلدهای دوم یا سوم، از بردار تعبیهی یکسانی استفاده شود. محققینی که ماشین فاکتورگیری آگاه از فیلد را معرفی کردند، ادعا میکنند تعامل بین فیلدهای اول و دوم، کاملا از تعامل بین فیلدهای اول و سوم مجزا بوده و میتوان برای آنها از بردارهای تعبیهی متفاوت استفاده کرد. | |||||
| این ادعای این پژوهش را میتوان به صورت دیگر نیز بیان کرد. فرض کنید فضای تعبیهی $A$ برای ویژگیهای فیلد اول و فضای تعبیهی $B$ و $C$ به ترتیب برای ویژگیهای فیلد دوم و سوم باشند. در صورتی که پارامترهای موجود در $A$ برای محاسبهی تعامل با بردارهای $B$ یاد گرفته شوند، یعنی فضای $A$ به طریقی ایجاد شده است که تفاوتهای مربوط به ویژگیهای فیلد دوم را در نظر گرفته است ولی تفاوتهای مربوط به ویژگیهای فیلد سوم از آن حذف شده است؛ پس تعامل محاسبه شده بین $A$ و $C$ نمیتواند تمامی اطلاعات ممکن را دارا باشد. در نتیجه لازم است برای هر فیلد، به تعداد | |||||
| $f - 1$ | |||||
| فضای تعبیه در نظر گرفته و تعامل بین ویژگیهای هر جفت فیلد را، در فضای مربوط به آن جفت فیلد محاسبه کنیم. | |||||
| رابطهی پیشبینی نهایی ماشین آگاه از فیلد، به صورت زیر است: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| \hat{y}_{FFM}(x) = w_{0} + \sum_{i = 1}^{n} w_{i} x_{i} + \sum_{i = 1}^{n} \sum_{j = i + 1}^{n} x_{i}x_{j}<v_{i, F_{j}}, v_{j, F_{i}}> | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| که در آن، | |||||
| $v_{i,F_{j}}$ | |||||
| بردار تعبیهی ویژگی $i$ام در مواجهه با ویژگیهای فیلد مربوط به ویژگی $j$ام بوده و عملگر $<.>$ ضرب داخلی بین دو بردار را محاسبه میکند. | |||||
| همان طور که واضح است که این تغییر باعث افزایش بسیار زیاد تعداد پارامترهای این مدل میشود؛ در نتیجه ماشینهای فاکتورگیری آگاه از فیلد به دلیل تعداد پارامترهای بالا، در مقابل چالشهایی از قبیل شروع سرد و سرعت آموزش، چندان موفق نیستند. | |||||
| \subsubsection{ماشینهای فاکتورگیری با فیلدهای وزندار\cite{Pan_fieldweightedfm}} | |||||
| در ماشینهای فاکتورگیری آگاه از فیلد، از آنجا که برای هر جفت فیلد، یک دسته بردار تعبیه شده در نظر گرفته میشود؛ تعداد پارامترهای مدل بسیار زیاد بوده و این امر باعث بروز مشکلاتی از جمله افزایش زمان آموزش و همچنین بیشتر شدن خطر بیش برازش میشود؛ پس محققین به دنبال یافتن راهی برای کاهش تعداد پارامترها با حفظ پیچیدگی مشکل گشته و در نتیجه ماشینهای فاکتورگیری با فیلدهای وزندار معرفی شدند. | |||||
| در ماشینهای فاکتورگیری با فیلدهای وزندار، به این نکته که میانگین میزان تعامل بین جفتهای مختلف از فیلدها، بسیار متفاوت است؛ توجه ویژهای شده است. به عنوان مثال، اکثر تعاملات بین ویژگیهای فیلد تبلیغ کننده و فیلد ناشر، میزان چشمگیری دارند؛ در حالی که تعاملات بین ویژگیهای فیلد ساعت و فیلد روز هفته، میزان قابل توجهی ندارند. که این تفاوت با توجه به مفهوم این فیلدها، کاملا منطقی به نظر میرسد؛ اما در ماشینهای فاکتورگیری آگاه از فیلد، چنین تفاوتی مدل نمیشود؛ لذا محققین در ماشینهای فاکتورگیری با فیلدهای وزندار، به آن توجه کرده و این تفاوت را به صورت صریح وارد محاسبات کردند. | |||||
| رابطهی پیشبینی نهایی ماشین فاکتورگیری با فیلد وزندار، به صورت زیر است: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| \hat{y}_{FwFM}(x) = w_{0} + \sum_{i = 1}^{n} w_{i} x_{i} + \sum_{i = 1}^{n} \sum_{j = i + 1}^{n} x_{i}x_{j}<v_{i}, v_{j}>r_{F_{i}, F_{j}} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| در این رابطه، $r_{F_{i}, F_{j}}$ نقش مدل کردن قدرت کلی تعاملات بین فیلد $i$ ام و $j$ ام را ایفا میکند. علاوه بر این، یک تفاوت دیگر بین ماشینهای آگاه از فیلد و ماشینهای با فیلدهای وزندار وجود دارد. این تفاوت به تعداد بردارهای تعبیه شدهی مربوط به هر ویژگی باز میگردد. در ماشینهای فاکتورگیری آگاه از فیلد، برای هر ویژگی، به تعداد فیلدهای دیگر بردار تعبیه شده استفاده میشود؛ ولی در ماشینهای فاکتورگیری با فیلدهای وزندار، برای هر ویژگی، تنها یک بردار تعبیهشده استفاده میشود و تفاوت قدرت کلی تعاملات بین فیلدها توسط وزنهای فیلدها ($r$) مدل میشود. | |||||
| لذا ماشینهای فاکتورگیری با فیلدهای وزندار، میتوانند با تعداد پارامترهای بسیار کمتر، عملکرد نسبتا یکسانی با ماشینهای فاکتورگیری آگاه از فیلد کسب کنند. در صورتی که تعداد پارامترهای استفاده شده در دو مدل یکسان در نظر گرفته شود، عملکرد ماشینهای با فیلد وزن دار، به صورت محسوسی بهتر میشود. | |||||
| پژوهشگران این مدل با محاسبهی همبستگی بین وزنهای آموخته شده برای فیلدها ($r$) با \trans{اطلاعات مشترک}{Mutual information} بین هر زوج فیلد و احتمال کلیک (خروجی مدل)، موفقیت آن را نسبت به مدلهای پیشین تایید کردند. | |||||
| با وجود مزایای گفته شده، ماشینهای فاکتورگیری با فیلدهای وزندار به دلیل سادگی، توان مدلسازی محدودی دارند؛ پس محققین به دنبال راهکارهای دیگر برای حل مسالهی تخمین نرخ کلیک گشته و پیشرفتهای دیگری را کسب کردند. | |||||
| \subsubsection{ماشینهای فاکتورگیری تنک} | |||||
| % | |||||
| محققین، پس از بررسی نمونههای مختلفی از ماشینهای فاکتورگیری، متوجه شدند در اکثر نسخههای استفاده شده از این خانواده مدل، تعداد پارامترهای آموخته شده بسیار زیاد بوده و به همین دلیل، خطای این مدلها همچنان قابل توجه است؛ لذا اقدام به بررسی راههایی کردند که بتوان به کمک آنها، تنک بودن مدل را تضمین کرده و در نتیجه به خطای کمتر و تفسیر پذیری بیشتری دست یابند. یکی از این اقدامات، ماشینهای فاکتورگیری تنک است. برای درک بهتر این مدل، بهتر است ابتدا ماشینهای فاکتورگیری بیزی را بررسی کنیم. | |||||
| \begin{itemize} | |||||
| \item{ماشینهای فاکتورگیری بیزی\cite{Freudenthaler2011BayesianFM}} | |||||
| در ادبیات سیستمهای پیشنهاد دهنده، بسیاری از مدلها به دلیل حجم بالای محاسبات، پاسخگو نیستند؛ در نتیجه تحقیقات زیادی در این زمینه برای یافتن مدلهایی با پیچیدگی محاسباتی کمتر اختصاص یافته است. یکی از این تحقیقات، ماشینهای فاکتورگیری بیزی است. چون آموزش ماشینهای فاکتورگیری ساده، به پیچیدگی محاسباتی بالایی نیاز دارد؛ همچنین مقدار $k$ بهینه، جز با آزمون و خطا قابل محاسبه نیست؛ برای آموزش یک مدل مناسب از خانوادهی ماشینهای فاکتورگیری، به زمان محاسبهی بسیار طولانی نیاز است. | |||||
| این در حالی است که میتوان عمل فاکتورگیری را، به جای روشهای مبتنی بر گرادیان، به وسیلهی \trans{نمونه برداری گیبس}{Gibbs Sampling} انجام داد. همچنین در این روشها، میتوان با فرض توزیع پیشین برای هر یک از پارامترها، عمل تنظیم را در این مدلها بهبود بخشید؛ پس ماشینهای فاکتورگیری بیزی، با استفاده از توزیع پیشین برای پارامترهای مدل و همچنین استفاده از نمونه برداری گیبس، با کاهش چشمگیر پیچیدگی محاسباتی و همچنین حفظ عملکرد نهایی (بهبود جزئی) ارائه شدند. | |||||
| در ماشینهای فاکتورگیری بیزی، برای همهی پارامترهای قابل یادگیری مدل، توزیع پیشین گاوسی با پارامترهای غیر ثابت در نظر گرفته میشود. این پارامترهای غیر ثابت را، ابرپارامترهای مدل مینامیم. همچنین برای این ابرپارامترها، توزیع پیشین در نظر گرفته و پارامترهای این توزیعهای پیشین را، \trans{ابر پیشین}{Hyperprior} مینامیم. ابر پیشینها عملا توزیع پیشین برای پارامترهای توزیع پیشینِ پارامترهای مدل هستند. به این تکنیک، \trans{ابر پیشینهای سلسله مراتبی}{Hierarchical hyperpriors} گفته میشود. از فواید استفاده از این تکنیک، میتوان به عدم نیاز به \trans{جستجوی توری}{Grid search} و همچنین تنظیم بیشتر مدل اشاره کرد. به عنوان میانگین توزیع گاوسی پارامترها، یک متغیر تصادفی با توزیع گاوسی و به عنوان عکس واریانس توزیع پارامترها، یک متغیر تصادفی با توزیع گاما در نظر گرفته میشود. | |||||
| به دلیل پیچیدگی بیش از حد، محاسبهی درستنمایی برای خروجی این مدل، قابل انجام نیست؛ پس از طریق نمونه برداری گیبس، پارامترها و هایپر پارامترهای مدل آموخته میشوند. به دلیل پیاده سازی خاص، آموزش این مدل به محاسبات خطی نسبت به $k$ نیاز داشته و به مراتب سریعتر از ماشینهای فاکتورگیری عادی است. این مدل علاوه بر سرعت، از پیچیدگی بیشتری نسبت به ماشینهای فاکتورگیری عادی برخوردار بوده و در نتیجه در دنیای واقعی قابلیت استفادهی بیشتری دارند. | |||||
| \end{itemize} | |||||
| زمانی که ماشینهای فاکتورگیری بیزی، در ادبیات پیشبینی نرخ کلیک به کار گرفته شدند، محققین دریافتند تعداد زیادی از پارامترهای این مدل، مقادیر غیر صفر به خود گرفته و این اتفاق باعث عدم تفسیر پذیری و همچنین عدم تطابق خروجی این مدل با خروجی مورد انتظار از آن میشود. همچنین همانطور که گفته شد، در ماشین فاکتورگیری بیزی، ابر پیشین گاوسی برای میانگینها و ابر پیشین گاما برای عکس واریانسها در نظر گرفته میشود؛ اما توزیع گاوسی، به دلیل محدودیت و تنک بودن شدید دادههای پیشبینی نرخ کلیک، برای این مسائل چندان مناسب نیست. محققین دریافتند در صورت استفاده از توزیع لاپلاس برای میانگین، به دلیل احتمال بیشتر صفر بودن و همچنین داشتن دنبالهی بزرگتر، امکان تطابق بیشتر با دادههای تنک این مسائل افزایش مییابد. | |||||
| در ماشینهای فاکتورگیری تنک\cite{Pan_sparsefm}، با در نظر گرفتن این که تنها حدود $0.15$ درصد از مقادیر ویژگیهای مجموعههای دادهی مورد استفاده غیر صفر هستند، فرض توزیع پیشین گاوسی را برای پارامترهای مدل رد کرده و به جای آن، از توزیع لاپلاس استفاده میکنند. توزیع لاپلاس، دارای دنبالهی سنگینتری نسبت به توزیع گاوسی میباشد، ولی احتمال تولید صفر توسط این توزیع، به مراتب بیشتر از توزیع گاوسی است. | |||||
| به دلیل \trans{ناهموار}{Non-smooth} بودن توزیع لاپلاس، استنباط بیزی در مورد ماشینهای فاکتورگیری تنک غیر قابل انجام است؛ لذا آن را به وسیلهی \trans{مخلوط مقیاسشده}{Scale mixture}ی چگالی توزیعهای گاوسی و نمایی در نظر گرفته و سپس، با استفاده از \trans{زنجیرهی مارکوف مونت کارلو}{Markov Chain Monte Carlo} نسبت به استنباط روی آن اقدام میکنند. | |||||
| یکی از فواید استفاده از مدل بیزی، این است که به جای پیشبینی صرف مقدار نرخ کلیک، برای آن چگالی توزیع محاسبه میشود. با استفاده از این چگالی توزیع، میتوان مواقعی که مدل با اطمینان تصمیم میگیرد و مواقعی که مدل اطمینان خاصی ندارد را از هم تمییز داده و از این تمایز، در تصمیم گیری بین \trans{اکتشاف یا استفاده}{Explore / Exploit} بهره جست. به عبارت دیگر، مدل بیزی امکان رویارویی بهتر با چالش شروع سرد را فراهم میسازد. | |||||
| \subsubsection{ماشین فاکتورگیری با توجه\cite{Xiao_afm}} | |||||
| در سالهای اخیر، استفاده از مفهوم \trans{توجه}{Attention} در شبکههای عصبی، باعث پیشرفت قابل توجهی در نتایج آنها شده و به همین دلیل، در بسیاری از وظایف یادگیری ماشین، از پردازش زبان طبیعی گرفته تا پردازش تصاویر، به صورت گسترده مورد استفاده قرار گرفتند. از طرفی در مسالهی پیشبینی نرخ کلیک، نیاز به اعمال تمایز میان ویژگیهای مرتبه بالاتر از نظر میزان اهمیت احساس میشد؛ پس پژوهشگران در یک پژوهش، اقدام به استفاده از این مفهوم و ترکیب آن با ماشینهای فاکتورگیری کرده و نتایج قابل قبولی نیز گرفتند. در این بخش، به معرفی مدل ماشین فاکتورگیری با توجه پرداخته و جزئیات آن را بررسی میکنیم. | |||||
| طبق مشاهدات قبلی، برخی از ویژگیهای مرتبه دوم در ماشینهای فاکتورگیری، از برخی دیگر اهمیت بسیار بیشتری داشته و برخی از آنها تقریبا هیچ ارتباطی با متغیر هدف ندارند؛ لذا در مدل ماشین فاکتورگیری ساده، که تمایزی بین این دو دسته وجود ندارد، امکان کم توجهی به ویژگیهای مرتبه دوم مهم و توجه بیش از حد به ویژگیهای مرتبه دوم نه چندان مهم (نویز) وجود دارد. این امر باعث تشدید مشکل بیشبرازش در این مدلها میشود. همچنین به دلیل تعداد بالای این ویژگیها، بررسی و ایجاد تمایز بین آنها به صورت دستی ممکن نیست؛ در نتیجه این نیاز احساس میشود که این تفاوتها به صورت خودکار و از روی دادهها استخراج شوند. در ماشینهای فاکتورگیری با فیلدهای وزندار، برای حل این مشکل از وزندهی به تعامل بین فیلدها استفاده میشد؛ اما این برای مقابله با نویز و بیشبرازش کافی نیست و در نتیجه در ماشین فاکتورگیری با توجه از مکانیزم توجه برای این امر استفاده میشود. | |||||
| ماشینهای فاکتورگیری با توجه، دو تفاوت عمده با ماشینهای فاکتورگیری ساده دارند: 1- استفاده از ضرب درایه به درایه به جای ضرب نقطهای برای استخراج ویژگیهای مرتبه دوم؛ 2- استفاده از ماژول توجه برای ایجاد تمایز بین ویژگیهای مرتبه دوم. در این بخش این دو تمایز را توضیح میدهیم. | |||||
| در ماشین فاکتورگیری با توجه، ابتدا بردارهای تعبیهشدهی ویژگیهای مرتبه دوم طبق فرمول زیر محاسبه میشوند: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| \mathcal{E}_{i, j} = (v_{i} \odot v_{j})x_{i}x_{j} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| که در آن عملگر $\odot$ نشاندهندهی ضرب درایه به درایه است. مقادیر توجه، از طریق اعمال یک شبکهی عصبی تک لایه روی این بردارهای تعبیهشده محاسبه میشوند: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| a_{i, j} = Softmax_{i, j}\{\mathbf{h}^{T} ReLU(\mathbf{W}\mathcal{E}_{i, j} + \mathbf{b})\} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| در که در آن عملگر $Softmax_{i, j}\{.\}$ بین همهی جملات دارای $i$ و $j$ مختلف اعمال میشود؛ در نتیجه مجموع $a_{i, j}$ ها همیشه برابر 1 است. | |||||
| سپس این بردارها با استفاده از مکانیزم توجه با هم ترکیب شده و خروجی نهایی ماشین فاکتورگیری با توجه، با اضافه شدن جملات مربوط به رگرسیون خطی، به این صورت تشکیل میشود: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| \hat{y}_{AFM}(x) = w_{0} + \sum_{i=1}^{n} w_{i}x_{i} + \mathbf{P}^{T} \sum_{i=1}^{n-1}\sum_{j=i+1}^{n}a_{i, j}\mathcal{E}_{i, j} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| همان طور که از روابط اخیر مشخص است، شیوهی محاسبهی تعامل در این مدل با روشهای ماشین فاکتورگیری متفاوت بوده و به جای محاسبهی تعاملهای تک بعدی، ابتدا برای هر جفت فیلد، یک بردار تعامل محاسبه شده و سپس از طریق یک ماتریس، بردارها به فضای تک بعدی خروجی نگاشت میشوند. این تفاوت باعث افزایش پیچیدگی این روش و در نتیجه پیشرفت عملکرد در زمان رویارویی با دادههای حجیم میشود؛ اما در مقابل در مواجهه با دادههای تنک یا شرایط شروع سرد، ممکن است این روش دچار مشکل شده و از بیشبرازش رنج ببرد. | |||||
| در نهایت، این مدل بر اساس میانگین مربعات خطا و از طریق روش گرادیان کاهشی تصادفی، بهینهسازی شده و از تکنیک \trans{حذف تصادفی}{dropout}\cite{srivastava2014dropout} برای تنظیم پارامترهای پیشبینی و \trans{تنظیم مرتبه دوم}{L2-Regularization}\cite{tikhonov1943stability} برای پارامترهای مکانیزم توجه استفاده میشود. | |||||
| \subsection{روشهای ژرف} | |||||
| با پیشرفت یادگیری ژرف، امروزه بهترین نتایج در بسیاری از مسائل در زمینهی یادگیری ماشین، توسط مدلهای ژرف کسب میشود. به دلیل قابلیت به کار گیری این مدلها در بسیاری از مسائل و همچنین کسب نتایج قابل قبول این دسته از مدلها، استفاده از آنها در زمینهی تبلیغات نمایشی نیز در حال افزایش است.\cite{journals/corr/ZhangYS17aa} در این بخش به بررسی چند نمونه از پژوهشهایی که از روشهای یادگیری ژرف در ادبیات پیشبینی نرخ کلیک استفاده کردهاند میپردازیم. | |||||
| \subsubsection{مدل ژرف پیشبینی نرخ کلیک\cite{Chen_deepctr}} | |||||
| مدل ژرف پیشبینی نرخ کلیک یکی از مدلهایی است که از تکنیکهای یادگیری ژرف بر روی مسالهی پیشبینی نرخ کلیک استفاده کرده است. در این مدل، ویژگیهای ورودی به دو دستهی ویژگیهای بصری تصویر بنر و و ویژگیهای پایه تقسیم میشوند. | |||||
| ویژگیهای بصری تصویر حاوی مقادیر روشنایی پیکسلها و ویژگیهای پایه حاوی اطلاعاتی مثل: محل نمایش تبلیغ، کمپین تبلیغ، گروه مخاطب تبلیغ، گروه تبلیغ و مشخصات پایهی کاربر (مانند سن و جنسیت) است. در این پژوهش، ویژگیهای بصری توسط یک شبکهی عصبی کانوولوشنی و ویژگیهای پایه توسط یک \trans{شبکه عصبی تماما متصل}{Fully Connected Neural Network} کد میشود؛ سپس ویژگیهای کد شده به وسیلهی یک شبکه عصبی تماما متصل دیگر پردازش شده و از آن نرخ کلیک یا احتمال کلیک کاربر بر روی این بنر، به دست میآید. | |||||
| در فرآیند آموزش این مدل، از الگوریتم گرادیان کاهشی برای کمینه کردن مقدار خطای لگاریتمی بهره جسته میشود. در کنار تابع هزینه، از تنظیم مرتبه دوم برای بهبود تعمیم پذیری این مدل استفاده میشود. | |||||
| همانطور که اشاره شد، مدل ژرف پیشبینی نرخ کلیک شامل سه بخش است: | |||||
| \begin{itemize} | |||||
| \item شبکهی کانوولوشنی | |||||
| همانطور که از نام آن مشخص است، شبکهی کانوولوشنی یک شبکه عصبی کانوولوشنی ژرف است. معماری این شبکه از شبکهی معروف \trans{رز نت}{ResNet}\cite{he2015residual} الهام گرفته شده و شامل 17 لایهی کانوولوشنی میباشد. | |||||
| لایهی اول این شبکهی کانوولوشنی دارای کرنلهای 5 در 5 و بقیه لایههای این شبکه از کرنلهای 3 در 3 تشکیل شدهاند. این بخش از شبکه قبل از آموزش کلی شبکه، توسط تصاویر بنرها و دستهی بنرها (به عنوان برچسب) \trans{پیشآموزش}{Pretrain} میشود. برای این منظور از دو لایهی تماما متصل اضافی در انتهای این شبکه استفاده میشود که ویژگیهای استخراج شده توسط لایههای کانوولوشنی را به برچسب (دستهی بنر) تبدیل کند. این دو لایه پس از اتمام پیشآموزش حذف میشوند. | |||||
| \item شبکهی پایه | |||||
| این بخش از شبکه، شامل تنها یک لایهی تماما متصل بوده و برای کاهش ابعاد بردار ویژگیهای ساده به کار میرود. این لایه دارای 128 نورون با تابع فعالساز \trans{واحد خطی یکسو کننده (رلو)}{ReLU}\cite{Nair_relu} بوده و فضای تنک بردار ویژگیهای ساده را به یک بردار \trans{چگال}{Dense} تبدیل میکند. میتوان گفت عملکرد این لایه همانند استفاده از بردارهای \trans{تعبیه}{Embedding}\cite{Guo_embedding_2016} برای تبدیل ویژگیهای دستهای به بردارهای چگال در روشهایی که پیشتر معرفی کردیم است. | |||||
| \item شبکهی ترکیبی | |||||
| خروجی شبکههای پایه و کانوولوشنی پس از چسبانده شدن به هم و عبور آن از یک لایهی \trans{نرمالسازی دستهای}{Batch Normalization}\cite{ioffe2015batch}، به عنوان ورودی شبکهی ترکیبی استفاده میشوند. این شبکه دارای دو لایه با 256 نورون و یک لایه با تنها یک نورون میباشد. خروجی لایههای اول به وسیلهی تابع فعالساز رلو و لایهی سوم با استفاده از تابع فعالساز سیگموید به فضای غیر خطی منتقل میشوند. | |||||
| \end{itemize} | |||||
| برای کاهش زمان آموزش این مدل، دو تکنیک استفاده میشوند. اول استفاده از یک پیادهسازی سریع برای لایهی تماما متصل تنک است. به دلیل استفاده از کدگذاری 1 از $k$ و همچنین \trans{درهمسازی ویژگیها}{Feature Hashing}، دارای تعداد زیادی ویژگی است که در هر نمونه، غالب آنها برابر صفر هستند. استفاده از این دانش در پیادهسازی لایهی تماما متصل اول در شبکهی پایه باعث بهبود چشمگیر در سرعت آموزش مدل میشود. | |||||
| تکنیک دیگر استفاده شده در این پژوهش، نمونه برداری مناسب برای بهرهگیری بیشتر از حافظه میباشد. در مجموعهدادههای استفاده شده در این پژوهش، تعداد زیادی تصویر یکسان وجود دارد؛ پس میتوان با استفاده از این دانش، نمونه برداری قبل از انجام هر گام از الگوریتم گرادیان کاهشی را به نحوی تغییر داد که تعداد محدودی تصویر یکسان در داخل \trans{دسته آموزش}{Batch} قرار گیرند؛ در نتیجه محاسبهی مشتقات آنها به سادگی و با صرف حداقل حافظهی گرافیکی قابل انجام خواهد بود. | |||||
| \subsubsection{ماشین فاکتورگیری ژرف\cite{Guo_deepfm1, Guo_deepfm2}} | |||||
| در ماشینهای فاکتورگیری ساده یا با توجه، اهمیت خاصی به تعاملهای مرتبه پایین داده میشود؛ در نتیجه مدل به سمت استفاده از تعاملهای مرتبه پایین تشویق میشود و در نتیجه نوعی بایاس در طراحی این خانواده از مدلها وجود دارد؛ اما ممکن است با در نظر نگرفتن این بایاس، تعاملات سطح بالای مناسب و مفیدی از دادهها کشف کنیم. | |||||
| در مقابل ماشینهای فاکتورگیری، که توانایی آنها در مدل کردن مناسب تعاملات مرتبه پایین است، مدلهای ژرف از جمله خانوادهی شبکههای عصبی چند لایه، توانایی بالایی برای مدل کردن تعاملات مرتبه بالا دارند؛ اما به دلیل عدم توجه به تعاملات مرتبه پایین، در مسالهی پیشبینی نرخ کلیک کاربرد چندانی ندارند. ماشینهای فاکتورگیری ژرف، ادغامی از این دو خانواده بوده و با ترکیب هر دو مدل، مدلی با انعطاف بیشتر و بایاس کمتر روی مرتبهی تعاملها ارائه میدهد. | |||||
| در این مدل، دو بخش اصلی وجود دارد: | |||||
| \begin{itemize} | |||||
| \item \textbf{بخش ماشین فاکتورگیری} | |||||
| این بخش تفاوتی با ماشین فاکتورگیری ساده ندارد. ابتدا ورودیهایش که همان ویژگیهای تنک مساله هستند را به بردارهای تعبیه شده تبدیل کرده و سپس با اعمال ضرب داخلی بین این بردارها، تعاملهای را محاسبه کرده و همچنین جملهی خطی را به آن اضافه کرده و خروجی مورد نظر را از روی این مجموع ایجاد میکند. | |||||
| \item \textbf{بخش ژرف} | |||||
| در این بخش از یک شبکه عصبی عادی استفاده میشود. ورودیهای بخش ژرف، همان بردارهای تعبیه شدهی بخش ماشین فاکتورگیری هستند. توابع فعالیت در این بخش اکثرا رلو یا $tanh$ (تانژانت هایپربولیک) بوده و همهی لایههای آن از نوع تماما متصل تشکیل شدهاند. | |||||
| \end{itemize} | |||||
| در ماشین فاکتورگیری ژرف، از این ایده استفاده شده است که بردارهای تعبیه شده در ماشینفاکتورگیری، ویژگیهای مناسبی ایجاد میکنند و به دلیل تنک نبودن و اندازهی کمتر نسبت به ورودیهای اصلی مسالهی پیشبینی نرخ کلیک، برای استفاده به عنوان ورودی یک شبکه عصبی ژرف کاملا مناسب هستند. | |||||
| برای ترکیب این دو مدل، علاوه بر استفاده از ویژگیهای مشترک، خروجیهای آنها نیز باهم جمع شده و به خاطر ماهیت مساله، که تخمین نرخ کلیک است، از مجموع خروجیهای آنها تابع سیگموید گرفته میشود. خروجی تابع سیگموید بین صفر و یک بوده و دقیقا مشابه توزیع احتمال یا نرخ کلیک است. | |||||
| این مدل با استفاده از \trans{خطای لگاریتمی}{Log Loss} و روش \trans{گرادیان کاهشی تصادفی}{Stochastic Gradient Descent} آموزش داده میشود. | |||||
| \subsubsection{مدل وسیع و ژرف\cite{Cheng_wideanddeep}} | |||||
| محققین شرکت \trans{گوگل}{Google}، شبکهی وسیع و ژرف را برای توصیهی اپلیکیشنها در \trans{بازار اپلیکیشن گوگل پلی}{Google Play Application Store} توسعه داده و پژوهش خود را در سال 2016 منتشر کردند. به دلیل شباهت بالای کاربرد پیشبینی نرخ کلیک روی اپلیکیشنها و پیشبینی نرخ کلیک روی تبلیغها، این مدل را مختصرا در این بخش معرفی میکنیم. | |||||
| در مدل وسیع و ژرف، سه بخش اصلی وجود دارد: | |||||
| \begin{itemize} | |||||
| \item مهندسی ویژگیها | |||||
| محققین در این پژوهش، ابتدا تعدادی از ویژگیهای موجود در مجموعههای داده را حذف کرده و سپس ویژگیهای سطح دوم را از روی بعضی از ویژگیهای باقی مانده استخراج کردند. هر یک از ویژگیهای مرتبه دوم، به صورت اشتراک بین دو ویژگی مرتبه اول تعریف شده و میتوان آن را معادل تعامل بین دو ویژگی در ماشینهای فاکتورگیری در نظر گرفت. این ویژگیها پس از تبدیل به ویژگیهای دستهای یا دودویی، به کمک عمل تعبیه، به بردارهای چگال تعبیه تبدیل شده و در بخشهای بعدی این مدل استفاده میشوند. | |||||
| \item بخش وسیع | |||||
| در بخش وسیع، همهی ویژگیهای استخراج شده در بخش قبل کنار هم چسبانده شده و توسط یک تبدیل خطی، به فضای تک بعدی خروجی نگاشت میشوند. | |||||
| \item بخش ژرف | |||||
| در بخش ژرف، بردارهای تعبیه شده به هم چسبانده شده و توسط یک شبکهی عصبی چند لایه به فضای تک بعدی خروجی منتقل میشوند. | |||||
| \end{itemize} | |||||
| خروجی نهایی مدل وسیع و ژرف، از ترکیب خطی خروجیهای بخشهای وسیع و ژرف تشکیل شده و توسط خطای لگاریتمی آموزش داده میشود. | |||||
| این مدل در رویارویی با چالشهایی از قبیل سرعت آزمایش، عملکرد قابل قبولی داشته و میتواند در کسری از ثانیه، اپلیکیشنهای مختلف را برای نمایش به کاربران رتبهبندی کند؛ اما به دلیل نیاز به مهندسی ویژگیها و همچنین تعداد بسیار بالای پارامترها، در مسالهی پیشبینی نرخ کلیک در تبلیغات نمایشی، قابل استفاده نیست؛ اما رویکرد ترکیب یک بخش ژرف و یک بخش غیر ژرف به طوری که ویژگیهای سطح پایین و سطح بالا توسط این دو بخش به صورت مجزا آموخته شوند، در بسیاری از پژوهشهای حوزهی پیشبینی نرخ کلیک در تبلیغات نمایشی (مثل ماشین فاکتورگیری ژرف یا خودکدگذار پشته شدهی دارای توجه) به کار بسته شده است. | |||||
| \subsubsection{خودکدگذار پشته شدهی دارای توجه\cite{Wang_asae}} | |||||
| شبکهی عصبی \trans{خودکدگذار}{Auto Encoder}\cite{Ballard_autoencoder}، یک روش یادگیری ماشین بدون نظارت است که از دو لایهی شبکهی عصبی تشکیل شده است. لایهی اول، دادههای ورودی را به \trans{فضای نهان}{Latent Space} نگاشت کرده و لایهی دوم، آنها را به فضای ورودی باز میگرداند. شبکهی خودکدگذار به این طریق آموزش داده میشود که فاصلهی اقلیدسی دادههای ورودی و خروجی حداقل باشد. در نتیجه یک شبکهی خودکدگذار ایدهآل میتواند ورودیهای خود را بازسازی کند. در صورتی که لایههای این شبکه را به صورت مجزا در نظر بگیریم، لایهی اول عمل \trans{کدگذاری}{Encoding} را انجام داده و لایهی دوم عمل \trans{کدگشایی}{Decoding} را بر عهده میگیرد. | |||||
| در ادبیات یادگیری ماشین، کاربردهای متنوعی برای شبکههای خودکدگذار ارائه شده که یکی از آنها برای استخراج ویژگی بدون نیاز به دادههای برچسب گذاری شده است. اگر پس از آموزش دادن یک خودکدگذار، صرفا از بخش کدگذار آن استفاده کرده و دادههای کد شده را، به ورودی یک خودکدگذار دیگر بدهیم و این فرآیند را چندین بار انجام دهیم، یک \trans{خودکدگذار پشته شده}{Stacked Auto Encoder} به وجود میآید. خودکدگذار پشته شده را میتوان به صورت مرحله به مرحله یا به صورت یکجا آموزش داد. در صورتی که خطای بازسازی خودکدگذار پشته شده کم باشد، میتوان نتیجه گرفت که ویژگیهای استخراج شده در لایهی میانی (پس از کدگذاری) حاوی اکثر اطلاعات مهم دادههای ورودی بوده و به همین دلیل بخش کدگشا قادر به بازسازی دادههای ورودی شده است؛ پس میتوان به جای اطلاعات اصلی، از ویژگیهای استخراج شده در لایهی میانی (که از تعداد ابعاد کمتری برخوردار است) استفاده کرده و در نتیجه از ویژگیهای سطح بالا و چگال مناسب بهره جست. | |||||
| خودکدگذار پشته شدهی دارای توجه، مدلی است که برای پیشبینی نرخ کلیک ارائه شده و به نوعی ترکیبی از ماشین فاکتورگیری با توجه و خودکدگذار پشته شده است. این مدل از دو بخش تشکیل شده است: | |||||
| \begin{itemize} | |||||
| \item بخش ماشین فاکتورگیری با توجه | |||||
| ماشین فاکتورگیری با توجه، همانطور که قبلا بحث شد، یک مدل با پیچیدگی قابل توجه برای پیشبینی نرخ کلیک در تبلیغات نمایشی به شمار میرود. این بخش میتواند از ویژگیهای مرتبه اول و دوم استفاده کرده و همچنین به کمک ساختار توجه، توازن را در میان ویژگیهای مرتبه دوم رعایت کند. | |||||
| \item بخش خودکدگذار پشته شده | |||||
| خودکدگذار پشته شده همانطور که گفته شد، میتواند ویژگیهای سطح بالا و فشرده استخراج کند. در این بخش، ابتدا ویژگیهای تنک را به بردارهای تعبیهشده تبدیل کرده و سپس آنها را کدگذاری و سپس کدگشایی میکنیم. | |||||
| \end{itemize} | |||||
| در فرآیند آموزش، ویژگیهای لایهی میانی بخش خودکدگذار پشته شده و ویژگیهای مرتبه اول و دوم (که خروجی ماشین فاکتورگیری با توجه هستند) را به هم چسبانده و سپس توسط یک شبکهی عصبی تک لایه، آنها را به فضای تک بعدی خروجی نگاشت میکنیم. | |||||
| برای آموزش خودکدگذار پشته شدهی باتوجه، خطای مدلسازی (خطای لگاریتمی) را با خطای بازسازی خودکدگذار جمع کرده و سپس از الگوریتم گرادیان کاهشی برای آموزش سراسری مدل استفاده میکنیم. | |||||
| مدل خودکدگذار پشته شدهی با توجه به دلیل استفاده از ویژگیهای سطح بالا در کنار ویژگیهای سطح پایین، بر روی مجموعههای دادهی با حجم بالا، عملکرد بهتری از بسیاری از مدلهای دیگر ارائه میدهد. همچنین به دلیل استفادهی چندگانه از بردارهای تعبیه شده، سرعت یادگیری اولیهی این مدل بهتر از سایر روشهای مبنی بر بردارهای تعبیه است. | |||||
| در این بخش، تعدادی از روشهایی که در ادبیات پیشبینی نرخ کلیک استفاده شدهاند را معرفی و بررسی کردیم. خلاصهای از مدلهای ذکر شده و همچنین مقایسهی کلی مزایا و معایب آنها در جدول \ref{tbl:notation} نمایش داده شده است. | |||||
| \begin{table}[] | |||||
| % set vertical spacing between rows | |||||
| %\renewcommand{\arraystretch}{1.2} | |||||
| %\linespread{1.2}\selectfont\centering | |||||
| \caption{خلاصهی روشهای اصلی مطالعه شده} | |||||
| \label{tbl:notation} | |||||
| %\begin{latin} | |||||
| \scriptsize | |||||
| \begin{center} | |||||
| \begin{tabular}{|c|c|c|c|c|} | |||||
| \hline | |||||
| نام مدل & نقاط قوت & نقاط ضعف & سال و مرجع \\ \hline | |||||
| %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% | |||||
| ماشین بردار پشتیبان (کرنل چند جملهای) | |||||
| & | |||||
| سرعت انجام بالا | |||||
| & | |||||
| تعداد پارامترهای بسیار بالا | |||||
| & | |||||
| 1992\cite{boser1992} | |||||
| \\ \hline | |||||
| %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% | |||||
| مدل تکهای خطی | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| انعطافپذیری \\ | |||||
| پارامترهای تنک \\ | |||||
| تفسیرپذیری مناسب | |||||
| \end{tabular} | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| تعداد پارامتر زیاد \\ | |||||
| آموزش کند \\ | |||||
| تنظیم سخت ابرپارامترها | |||||
| \end{tabular} | |||||
| & | |||||
| 2017\cite{Gai_piecewise} | |||||
| \\ \hline | |||||
| %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% | |||||
| مدل رگرسیون بیزی | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| امکان برقراری تعادل بین \\ | |||||
| اکتشاف و بهرهبرداری | |||||
| \end{tabular} | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| انعطاف پذیری کم \\ | |||||
| نیاز به دادههای زیاد | |||||
| \end{tabular} | |||||
| & | |||||
| 2009\cite{Graepel_2010} | |||||
| \\ \hline | |||||
| %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% | |||||
| ماشین فاکتورگیری | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| مدلسازی تعاملهای مرتبه دوم \\ | |||||
| تعداد کم پارامترهای مستقل | |||||
| \end{tabular} | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| بیتوجهی به روابط کلی بین فیلدها \\ | |||||
| خطر بیشبرازش | |||||
| \end{tabular} | |||||
| & | |||||
| 2010\cite{Rendle:2010ja} | |||||
| \\ \hline | |||||
| %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% | |||||
| ماشین فاکتورگیری آگاه از فیلد | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| مدلسازی تفاوت بین فیلدها | |||||
| \end{tabular} | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| تعداد بالای پارامترها \\ | |||||
| احتمال بالای بیشبرازش | |||||
| \end{tabular} | |||||
| & | |||||
| 2016\cite{Juan_fieldawarefm1, Juan_fieldawarefm2} | |||||
| \\ \hline | |||||
| %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| ماشین فاکتورگیری با فیلدهای وزندار | |||||
| \end{tabular} | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| کنترل تعداد پارامترها \\ | |||||
| مدلسازی تفاوت کلی فیلدها | |||||
| \end{tabular} | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| توان مدلسازی محدود \\ | |||||
| عدم مدلسازی تعاملهای مرتبه بالا | |||||
| \end{tabular} | |||||
| & | |||||
| 2018\cite{Pan_fieldweightedfm} | |||||
| \\ \hline | |||||
| %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| ماشین فاکتورگیری بیزی | |||||
| \end{tabular} | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| امکان برقراری تعادل بین \\ | |||||
| اکتشاف و بهرهبرداری | |||||
| \end{tabular} | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| استنباط غیر قابل محاسبه \\ | |||||
| پیشفرض نامناسب گاوسی | |||||
| \end{tabular} | |||||
| & | |||||
| 2011\cite{Freudenthaler2011BayesianFM} | |||||
| \\ \hline | |||||
| %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| ماشین فاکتورگیری تنک | |||||
| \end{tabular} | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| تفسیر پذیری بالا \\ | |||||
| تنک بودن مدل | |||||
| \end{tabular} | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| استنباط غیر قابل محاسبه \\ | |||||
| استفاده از تخمین برای محاسبهی توزیع | |||||
| \end{tabular} | |||||
| & | |||||
| 2016\cite{Pan_sparsefm} | |||||
| \\ \hline | |||||
| %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% | |||||
| ماشین فاکتورگیری با توجه | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| افزایش پیچیدگی مدل \\ | |||||
| افزایش تفسیرپذیری مدل | |||||
| \end{tabular} | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| احتمال بیشبرازش \\ | |||||
| نیاز به دادههای زیاد | |||||
| \end{tabular} | |||||
| & | |||||
| 2017\cite{Xiao_afm} | |||||
| \\ \hline | |||||
| %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% | |||||
| مدل ژرف پیشبینی نرخ کلیک | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| توانایی مدل تعاملات مرتبه بالا \\ | |||||
| تعمیم پذیری مناسب | |||||
| \end{tabular} | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| نیاز به تصویر بنر تبلیغ \\ | |||||
| امکان بیشبرازش به دلیل کمبود داده \\ | |||||
| عدم مواجهه با چالش شروع سرد | |||||
| \end{tabular} | |||||
| & | |||||
| 2016\cite{Chen_deepctr} | |||||
| \\ \hline | |||||
| %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% | |||||
| ماشین فاکتورگیری ژرف | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| مدلسازی تعاملات مرتبه بالا \\ | |||||
| عدم وجود بایاس در مرتبه تعاملات | |||||
| \end{tabular} | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| تعداد زیاد ابرپارامتر \\ | |||||
| تفسیرپذیری پایین | |||||
| \end{tabular} | |||||
| & | |||||
| 2017\cite{Guo_deepfm1, Guo_deepfm2} | |||||
| \\ \hline | |||||
| %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% | |||||
| مدل وسیع و ژرف | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| پیادهسازی سریع \\ | |||||
| توان مدلسازی مناسب | |||||
| \end{tabular} | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| نیاز به مهندسی ویژگیها \\ | |||||
| تعداد بالای پارامترها | |||||
| \end{tabular} | |||||
| & | |||||
| 2016\cite{Cheng_wideanddeep} | |||||
| \\ \hline | |||||
| %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% | |||||
| خودکدگذار پشته شدهی با توجه | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| توانایی مدلسازی مناسب\\ | |||||
| اشتراک بالای پارامترها | |||||
| \end{tabular} | |||||
| & | |||||
| \begin{tabular}[c]{@{}c@{}} | |||||
| تعداد زیاد پارامترها \\ | |||||
| احتمال بیشبرازش | |||||
| \end{tabular} | |||||
| & | |||||
| 2018\cite{Wang_asae} | |||||
| \\ \hline | |||||
| %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% | |||||
| \end{tabular} | |||||
| %\end{latin} | |||||
| \end{center} | |||||
| \end{table} | |||||
+ 143
- 0
Thesis/chap3.aux
View File
| \relax | |||||
| \providecommand\zref@newlabel[2]{} | |||||
| \providecommand\hyper@newdestlabel[2]{} | |||||
| \zref@newlabel{zref@96}{\abspage{37}\page{30}\pagevalue{30}} | |||||
| \@writefile{toc}{\contentsline {chapter}{فصل\nobreakspace {}\numberline {3}روش پیشنهادی}{30}{chapter.3}} | |||||
| \@writefile{lof}{\addvspace {10\p@ }} | |||||
| \@writefile{lot}{\addvspace {10\p@ }} | |||||
| \newlabel{Chap:Chap3}{{3}{30}{روش پیشنهادی}{chapter.3}{}} | |||||
| \@writefile{toc}{\contentsline {section}{\numberline {3-1}تعبیهی ویژگیها}{30}{section.3.1}} | |||||
| \citation{ShannonWeaver49} | |||||
| \citation{Naumov_embedding_dim} | |||||
| \zref@newlabel{footdir@212}{\abspage{38}} | |||||
| \zref@newlabel{zref@97}{\abspage{38}\page{31}\pagevalue{31}} | |||||
| \zref@newlabel{footdir@214}{\abspage{38}} | |||||
| \zref@newlabel{zref@98}{\abspage{38}\page{31}\pagevalue{31}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {3-1-1}بررسی ابعاد بردارهای تعبیه به کمک نظریهی اطلاعات}{31}{subsection.3.1.1}} | |||||
| \zref@newlabel{footdir@216}{\abspage{38}} | |||||
| \zref@newlabel{zref@99}{\abspage{38}\page{31}\pagevalue{31}} | |||||
| \newlabel{entropy_source}{{3.1}{31}{بررسی ابعاد بردارهای تعبیه به کمک نظریهی اطلاعات}{equation.3.1.1}{}} | |||||
| \newlabel{entropy_embedding}{{3.2}{31}{بررسی ابعاد بردارهای تعبیه به کمک نظریهی اطلاعات}{equation.3.1.2}{}} | |||||
| \zref@newlabel{footdir@218}{\abspage{38}} | |||||
| \zref@newlabel{footdir@213}{\abspage{38}} | |||||
| \zref@newlabel{footdir@215}{\abspage{38}} | |||||
| \zref@newlabel{footdir@217}{\abspage{38}} | |||||
| \newlabel{prop_mutual}{{3.4}{32}{بررسی ابعاد بردارهای تعبیه به کمک نظریهی اطلاعات}{equation.3.1.4}{}} | |||||
| \newlabel{prop_entropy}{{3.5}{32}{بررسی ابعاد بردارهای تعبیه به کمک نظریهی اطلاعات}{equation.3.1.5}{}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {3-1-2}بررسی ابعاد بردارهای تعبیه به کمک مفاهیم شهودی یادگیری ماشین و یادگیری ژرف}{33}{subsection.3.1.2}} | |||||
| \zref@newlabel{footdir@219}{\abspage{41}} | |||||
| \zref@newlabel{zref@100}{\abspage{41}\page{34}\pagevalue{34}} | |||||
| \zref@newlabel{footdir@221}{\abspage{41}} | |||||
| \zref@newlabel{footdir@220}{\abspage{41}} | |||||
| \@writefile{toc}{\contentsline {section}{\numberline {3-2}محاسبهی تعامل}{35}{section.3.2}} | |||||
| \citation{Ginart_MixedDimEmb} | |||||
| \citation{he2017neural} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {3-2-1}نگاشت خطی بردارهای تعبیه به فضای همبعد}{36}{subsection.3.2.1}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {3-2-2}محاسبهی تعامل به کمک شبکهی عصبی}{36}{subsection.3.2.2}} | |||||
| \zref@newlabel{footdir@222}{\abspage{43}} | |||||
| \zref@newlabel{zref@101}{\abspage{43}\page{36}\pagevalue{36}} | |||||
| \zref@newlabel{footdir@224}{\abspage{43}} | |||||
| \zref@newlabel{zref@102}{\abspage{43}\page{36}\pagevalue{36}} | |||||
| \zref@newlabel{footdir@230}{\abspage{43}} | |||||
| \zref@newlabel{footdir@223}{\abspage{43}} | |||||
| \zref@newlabel{footdir@225}{\abspage{43}} | |||||
| \zref@newlabel{footdir@228}{\abspage{44}} | |||||
| \zref@newlabel{zref@104}{\abspage{44}\page{37}\pagevalue{37}} | |||||
| \zref@newlabel{footdir@226}{\abspage{44}} | |||||
| \zref@newlabel{zref@103}{\abspage{44}\page{37}\pagevalue{37}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {3-2-3}تعاملهای چندبعدی به جای تعاملهای چندگانه}{37}{subsection.3.2.3}} | |||||
| \zref@newlabel{footdir@231}{\abspage{44}} | |||||
| \zref@newlabel{footdir@227}{\abspage{44}} | |||||
| \zref@newlabel{footdir@229}{\abspage{44}} | |||||
| \zref@newlabel{footdir@232}{\abspage{45}} | |||||
| \zref@newlabel{zref@105}{\abspage{45}\page{38}\pagevalue{38}} | |||||
| \zref@newlabel{footdir@236}{\abspage{45}} | |||||
| \zref@newlabel{footdir@233}{\abspage{45}} | |||||
| \citation{maas2013leakyrelu} | |||||
| \zref@newlabel{footdir@234}{\abspage{46}} | |||||
| \zref@newlabel{zref@106}{\abspage{46}\page{39}\pagevalue{39}} | |||||
| \zref@newlabel{footdir@237}{\abspage{46}} | |||||
| \zref@newlabel{zref@107}{\abspage{46}\page{39}\pagevalue{39}} | |||||
| \@writefile{toc}{\contentsline {section}{\numberline {3-3}استفاده از بردارهای تعبیه و تعامل برای تخمین نرخ کلیک}{39}{section.3.3}} | |||||
| \zref@newlabel{footdir@239}{\abspage{46}} | |||||
| \zref@newlabel{zref@108}{\abspage{46}\page{39}\pagevalue{39}} | |||||
| \zref@newlabel{footdir@241}{\abspage{46}} | |||||
| \zref@newlabel{footdir@235}{\abspage{46}} | |||||
| \zref@newlabel{footdir@238}{\abspage{46}} | |||||
| \zref@newlabel{footdir@240}{\abspage{46}} | |||||
| \zref@newlabel{footdir@242}{\abspage{47}} | |||||
| \zref@newlabel{zref@109}{\abspage{47}\page{40}\pagevalue{40}} | |||||
| \zref@newlabel{footdir@244}{\abspage{47}} | |||||
| \zref@newlabel{zref@110}{\abspage{47}\page{40}\pagevalue{40}} | |||||
| \zref@newlabel{footdir@246}{\abspage{47}} | |||||
| \zref@newlabel{zref@111}{\abspage{47}\page{40}\pagevalue{40}} | |||||
| \zref@newlabel{footdir@248}{\abspage{47}} | |||||
| \zref@newlabel{footdir@243}{\abspage{47}} | |||||
| \zref@newlabel{footdir@245}{\abspage{47}} | |||||
| \zref@newlabel{footdir@247}{\abspage{47}} | |||||
| \zref@newlabel{footdir@249}{\abspage{48}} | |||||
| \zref@newlabel{zref@112}{\abspage{48}\page{41}\pagevalue{41}} | |||||
| \zref@newlabel{footdir@251}{\abspage{48}} | |||||
| \zref@newlabel{footdir@250}{\abspage{48}} | |||||
| \zref@newlabel{footdir@252}{\abspage{49}} | |||||
| \zref@newlabel{zref@113}{\abspage{49}\page{42}\pagevalue{42}} | |||||
| \zref@newlabel{footdir@256}{\abspage{49}} | |||||
| \zref@newlabel{zref@115}{\abspage{49}\page{42}\pagevalue{42}} | |||||
| \zref@newlabel{footdir@254}{\abspage{49}} | |||||
| \zref@newlabel{zref@114}{\abspage{49}\page{42}\pagevalue{42}} | |||||
| \@writefile{toc}{\contentsline {section}{\numberline {3-4}جمعبندی روش پیشنهادی}{42}{section.3.4}} | |||||
| \zref@newlabel{footdir@258}{\abspage{49}} | |||||
| \zref@newlabel{footdir@253}{\abspage{49}} | |||||
| \zref@newlabel{footdir@255}{\abspage{49}} | |||||
| \zref@newlabel{footdir@257}{\abspage{49}} | |||||
| \@writefile{lot}{\contentsline {table}{\numberline {3-1}{\ignorespaces خلاصهی ایدههای استفاده شده در روش پیشنهادی\relax }}{43}{table.caption.18}} | |||||
| \newlabel{tbl:ideas}{{3-1}{43}{خلاصهی ایدههای استفاده شده در روش پیشنهادی\relax }{table.caption.18}{}} | |||||
| \@setckpt{chap3}{ | |||||
| \setcounter{page}{44} | |||||
| \setcounter{equation}{23} | |||||
| \setcounter{enumi}{2} | |||||
| \setcounter{enumii}{0} | |||||
| \setcounter{enumiii}{0} | |||||
| \setcounter{enumiv}{0} | |||||
| \setcounter{footnote}{3} | |||||
| \setcounter{mpfootnote}{0} | |||||
| \setcounter{part}{0} | |||||
| \setcounter{chapter}{3} | |||||
| \setcounter{section}{4} | |||||
| \setcounter{subsection}{0} | |||||
| \setcounter{subsubsection}{0} | |||||
| \setcounter{paragraph}{0} | |||||
| \setcounter{subparagraph}{0} | |||||
| \setcounter{figure}{0} | |||||
| \setcounter{table}{1} | |||||
| \setcounter{parentequation}{0} | |||||
| \setcounter{ALC@unique}{0} | |||||
| \setcounter{ALC@line}{0} | |||||
| \setcounter{ALC@rem}{0} | |||||
| \setcounter{ALC@depth}{0} | |||||
| \setcounter{float@type}{8} | |||||
| \setcounter{algorithm}{0} | |||||
| \setcounter{ContinuedFloat}{0} | |||||
| \setcounter{KVtest}{0} | |||||
| \setcounter{subfigure}{0} | |||||
| \setcounter{subfigure@save}{0} | |||||
| \setcounter{lofdepth}{1} | |||||
| \setcounter{subtable}{0} | |||||
| \setcounter{subtable@save}{0} | |||||
| \setcounter{lotdepth}{1} | |||||
| \setcounter{pp@next@reset}{0} | |||||
| \setcounter{zpage}{42} | |||||
| \setcounter{@pps}{0} | |||||
| \setcounter{@ppsavesec}{0} | |||||
| \setcounter{@ppsaveapp}{0} | |||||
| \setcounter{Item}{7} | |||||
| \setcounter{Hfootnote}{112} | |||||
| \setcounter{Hy@AnnotLevel}{0} | |||||
| \setcounter{bookmark@seq@number}{28} | |||||
| \setcounter{su@anzahl}{0} | |||||
| \setcounter{LT@tables}{0} | |||||
| \setcounter{LT@chunks}{0} | |||||
| \setcounter{footdir@label}{258} | |||||
| \setcounter{shadetheorem}{1} | |||||
| \setcounter{section@level}{1} | |||||
| } |
+ 353
- 0
Thesis/chap3.tex
View File
| % !TEX encoding = UTF-8 Unicode | |||||
| \chapter{روش پیشنهادی}\label{Chap:Chap3} | |||||
| در فصل قبل، روشهای حل مسالهی پیشبینی نرخ کلیک را دستهبندی کرده و تعدادی از پژوهشهای مهم هر دسته را بررسی و مقایسه کرده و با بیان مزایا و کاستیهای هر کدام، دید مناسبی از دشواریها و چالشهای این مساله کسب کردیم. | |||||
| در این فصل، با در نظر گرفتن چالشهای مسالهی پیشبینی نرخ کلیک و همچنین با توجه به ایرادات یا کاستیهای مشترک روشهای پیشین، اقدام به طراحی یک مدل جدید، برای حل این مساله مینماییم. برای طراحی این مدل جدید، اقدام به معرفی ایدههای جدید و همچنین بهرهگیری از برخی ایدههای موجود در ادبیات یادگیری ماشین کرده و در هر گام، با توجه به چالشهای ذاتی مساله و همچنین محدودیتهای ناشی از گامهای قبلی، روش پیشنهادی را توسعه میدهیم. | |||||
| \section{تعبیهی ویژگیها} | |||||
| از آنجا که استفاده از بردارهای تعبیه شده، امری ضروری برای بهرهگیری از ویژگیهای دستهای موجود در مجموعههای دادهی پیشبینی نرخ کلیک به شمار میرود، طراحی مدل پیشنهادی را از همین بخش آغاز مینماییم. | |||||
| در فصل قبل با مطالعهی تعداد قابل توجهی از روشهای پیشین، مشاهده کردیم که همهی این پژوهشها، در یک اصل مشترک هستند. همهی این روشها، با استفاده از ترفند تعبیه، ویژگیهای دستهای ورودی را به بردارهای چگال قابل یادگیری تبدیل کرده و سپس این بردارها را برای استفاده در بقیهی قسمتهای مدل، به کار میبندند. نکتهی دیگرِ قابل توجه و مشترک در همهی این روشها، استفاده از بردارهای تعبیه با بعد یکسان برای ویژگیهای همهی فیلدها است. | |||||
| میتوانیم استفاده از بردارهای همبعد را به این صورت تعبیر کنیم که در این مدلها، برای هر فیلد یک فضای $k$ بعدی در نظر گرفته شده و تمامی ویژگیها (حالتها)ی این فیلد، به عنوان نقاطی در این فضای $k$ بعدی جای میگیرند. به عنوان مثال، در صورتی که فیلد $F_{a}$ دارای 3 حالت مختلف و فیلد $F_{b}$ دارای 1000 حالت مختلف باشند، در فضای تعبیهی فیلد اول ($E_{a}$) سه نقطه (یا سه بردار $k$ بعدی) و همچنین در فضای تعبیهی فیلد دوم ($E_{b}$) هزار نقطه (یا بردار $k$ بعدی) حضور خواهند داشت؛ پس جایگیری نقاط در فضای $E_{b}$ نسبت به جایگیری نقاط در فضای $E_{a}$ شرایط فشردهتری دارد. | |||||
| با ملاحظهی نکتهی فوق، این سوال به وجود میآید که \textbf{آیا تعبیهی ویژگیهای همهی فیلدها در فضای دارای ابعاد یکسان (که همهی روشهای پیشین در انجام آن اتفاق دارند)، بهترین تصمیم ممکن است؟} برای پاسخ به این سوال، میتوانیم از دو روش مختلف استفاده کنیم. روش اول، استفاده از نگرش مرسوم در \trans{نظریهی اطلاعات}{Information Theory} برای اندازهگیری اطلاعات موجود در این بردارها و روش دوم، بررسی شهودی این مساله، با توجه به مفاهیم مرسوم در ادبیات یادگیری ماشین و \trans{یادگیری ژرف}{Deep Learning} است. | |||||
| \subsection{بررسی ابعاد بردارهای تعبیه به کمک نظریهی اطلاعات} | |||||
| در نظریهی اطلاعات\cite{ShannonWeaver49}، \trans{آنتروپی}{Entropy} یک ویژگی دستهای (فیلد)، به صورت زیر محاسبه میشود: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| H(F) = - \sum_{i = 1}^{|F|}{p_{i}log_{2}(p_{i})}\label{entropy_source} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| که در آن $|F|$ تعداد دستهها و $p_{i}$ احتمال وقوع حالت $i$ام این ویژگی هستند. | |||||
| در صورتی که این ویژگی دستهای را در فضای $k$ بعدی تعبیه کنیم و هریک از عناصر موجود در بردارهای تعبیه، دارای $s$ بیت باشند، میتوانیم آنتروپی بردار تعبیهشده را محاسبه کنیم: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| H(E) = - \sum_{i = 1}^{2^{ks}}{p_{i}log_{2}(p_{i})}\label{entropy_embedding} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| که در آن $p_{i}$ احتمال یک بودن بیت $i$ام این بردار است. | |||||
| با مقایسهی دو رابطهی \ref{entropy_source} و \ref{entropy_embedding} میتوانیم میزان اطلاعات موجود در آن فیلد را، با میزان اطلاعات قابل بیان توسط بردار تعبیه شده مقایسه کنیم. | |||||
| در پژوهش \cite{Naumov_embedding_dim} با فرض هم احتمال بودن توزیع حالتهای ویژگی دستهای و همچنین هم احتمال بودن توزیع بیتهای بردار تعبیه شده، مقایسهی فوق را انجام داده و در نتیجه به رابطهی زیر رسیدند: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| log_{2}(|F|) = k . s | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| میتوان این رابطه را به این صورت تعبیر کرد که برای تناسب اطلاعات موجود در ویژگی دستهای و بردار تعبیه شدهی مربوطه، باید بعد تخصیص داده شده به آن بردار با لگاریتم کاردینالیتی مجموعهی حالات مختلف انتخاب آن متناسب باشد؛ پس فیلدی که کاردینالیتی بالاتری داشته باشد، باید در فضای دارای ابعاد بیشتر تعبیه شود. | |||||
| با در نظر گرفتن این نکته که مورد استفادهی اصلی بردارهای تعبیه شده در مدلهای یادگیری ماشین و یادگیری ژرف است، میتوان رابطهی بالا را نقد کرد. در رابطهی گفته شده، فرض شده است که همهی اطلاعات موجود در فیلد باید در بردارهای تعبیه شده موجود باشد. همچنین فرض شده است که از همهی بیتهای بردارهای تعبیه شده برای ذخیرهی این اطلاعات استفاده میشود. این در حالی است که در یادگیری ماشین و یادگیری ژرف، هیچ یک از این دو فرض صحت ندارند. مدلهای یادگیری ماشین و یادگیری ژرف، به جای همهی اطلاعات موجود در ویژگی دستهای، تنها به اطلاعات مشترک این ویژگی با متغیر هدف (خروجی) نیاز داشته و همچنین، از بردارهای تعبیه شده این انتظار میرود که به جای فشردهسازی حداکثری، دارای فواصل کم بین ویژگیهای مشابه و فواصل زیاد بین ویژگیهای متفاوت باشد. در نتیجه مدلهای گفته شده، بتوانند از اطلاعات موجود در این بردارها به صورت مطلوب استفاده کنند. | |||||
| با وجود این فرضهای اشتباه و فرض سادهکنندهی توزیع یکنواخت، این روابط تنها با افزودن چند ضریب قابل اصلاح است. فرض میکنیم اطلاعات مشترک بین متغیر هدف و هریک از فیلدها، به صورت ضریب ثابتی ($\mu$) از اطلاعات موجود در آن فیلد باشد. همچنین، فرض میکنیم هر چند ($\delta$) بردار تعبیه، به دلیل شباهت مفهوم مربوطه، در محل یکسانی از فضای تعبیه جا بگیرند. | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| I(y, F_{i}) = H(F_{i}) \times \mu = log_{2}(\frac{|F_{i}|}{\delta}) \times \mu \label{prop_mutual} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| همچنین فرض میکنیم برای مطلوب بودن فضای تعبیه، انتظار میرود تنها از کسر ثابتی ($\kappa$) از ظرفیت بیتهای موجود در بردار تعبیه استفاده شود. | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| H(E) = k . s . \kappa \label{prop_entropy} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| حال با برابر قرار دادن روابط \ref{prop_mutual} و \ref{prop_entropy}، به این رابطه میرسیم: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| k = log_{2}(\frac{|F_{i}|}{\delta}) \times \frac{\mu}{s \times \kappa} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| که میتوان آن را به صورت زیر هم نوشت: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| k = \omega . \ln(|F_{i}|) + \epsilon | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| که در آن، با معرفی پارامترهای $\omega$ و $\epsilon$ همهی ضرایب ثابت را یک جا جمع میکنیم. حال از طریق رابطهی فوق، میتوانیم ابعاد مناسب برای تعبیهی هر فیلد را محاسبه کنیم. | |||||
| \subsection{بررسی ابعاد بردارهای تعبیه به کمک مفاهیم شهودی یادگیری ماشین و یادگیری ژرف} | |||||
| در بخش قبل، به کمک مفاهیم نظریهی اطلاعات، رابطهای برای تخصیص مناسب بعد به فیلدها ارائه کنیم. در این بخش، با بهرهگیری از شهود و همچنین برخی از مفاهیم مورد استفاده در ادبیات یادگیری ماشین و یادگیری ژرف، نسبت به توجیه، نقد و اصلاح رابطهی ارائه شده اقدام میکنیم. | |||||
| فرض کنید یک ویژگی دستهای توسط بردارهایی تعبیه میشود و یک مدل شبکه عصبی، با استفاده از اطلاعات موجود در این بردارها، نسبت به تخمین یک متغیر هدف اقدام میکند. چون واحدهای سازندهی شبکههای عصبی، نورونهای خطی هستند، در شرایطی که بیشبرازش شدید موجود نباشد، این شبکه مرز تصمیمگیری نرمی خواهد داشت. به این معنا که نقاطیکه در کنار هم تعبیه شدهاند، به احتمال بسیار زیاد به یک کلاس تخصیص داده خواهند شد. | |||||
| در صورتی که بعد تعبیهی این مدل را افزایش دهیم، این نقاط میتوانند از هم دورتر شده و لذا چگالی نقاط در این فضا کاهش مییابد. با کاهش چگالی نقاط، مدل قادر خواهد بود این نقاط را با دقت بیشتری از هم جدا کرده و لذا در صورت زیاده روی در افزایش بعد تعبیه، شباهت بین این نقاط توسط مدل قابل درک نخواهد بود. این پدیده میتواند یکی از شکلهای بیشبرازش را ایجاد کند. | |||||
| در مقابل، اگر بعد تعبیهی این مدل را کاهش دهیم، این نقاط به هم نزدیکتر شده و لذا چگالی نقاط در این فضا افزایش مییابد. با افزایش چگالی نقاط، مدل توانایی جداسازی این نقاط از هم را از دست میدهد. در نتیجه توان مدلسازی مدل کاهش یافته و عملا کیفیت عملکرد مدل افت خواهد کرد. | |||||
| از مثال بالا، میتوانیم این مفهوم را برداشت کنیم که برای دسترسی به بهترین عملکرد ممکن، چگالی نقاط در فضای تعبیه باید مقدار معینی داشته باشد. برای درک بهتر این مفهوم، میتوانیم تعریف فیزیکی چگالی را در نظر گرفته و سعی کنیم رابطهای برای بعد تعبیه به دست آوریم. | |||||
| از آنجا که تعریف فیزیکی چگالی، از تقسیم تعداد ذرات به حجم محاسبه میشود، ولی فضای تعبیه حجم بینهایت دارد، مجبوریم این تعریف را تا حدودی تغییر دهیم. اعمال تکنیکهای تنظیم بر پارامترهای تعبیه، باعث محدود شدن محل هندسی بردارهای تعبیه شده میشوند و لذا میتوانیم فرض کنیم همهی پارامترهای تعبیه، در بازهی $(-\frac{L}{2}, \frac{L}{2})$ محدود خواهند بود؛ پس اگر بعد تعبیه را $k$ و تعداد نقاطی که در این فضا تعبیه میشوند را $n$ در نظر بگیریم، میتوانیم چگالی متوسط این نقاط را محاسبه کنیم: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| density(E) = \frac{n}{L^{k}} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| حال اگر در یک مدل که بیش از یک ویژگی دستهای ورودی دارد، مقدار چگالی را برای فضای تعبیهی همهی فیلدها یکسان در نظر بگیریم: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| \frac{|F_{i}|}{L^{k_{i}}} = \frac{|F_{j}|}{L^{k_{j}}} = c.t.e. | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| با لگاریتم گرفتن از رابطهی فوق میتوانیم: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| \ln(|F_{i}|) - k_{i} \ln(L) = \ln(|F_{j}|) - k_{j} \ln(L) = c | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| که در آن $c$ یک عدد ثابت بوده و خواهیم داشت: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| \forall i: k_{i} = \frac{\ln(|F_{i}|) - c}{ln(L)} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| با تغییر دادن پارامترها، میتوان این رابطه را به شکل زیر در آورد: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| \forall i: k_{i} = \omega \times \ln(|F_{i}|) + \epsilon | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| که رابطهی اخیر، کاملا بر رابطهی به دست آمده به کمک مفاهیم نظریهی اطلاعات مطابقت دارد. | |||||
| رابطهی به دست آمده، نسبت به کاردینالیتی فیلد، صعودی است. به این معنا که فیلد دارای دستههای بیشتر، لزوما در فضای دارای بعدهای بالاتر تعبیه خواهد شد؛ پس در صورتی که مدلی از این رابطه برای تخصیص پارامترهای تعبیه به فیلدهای ورودی استفاده کند، همیشه تعداد پارامترهای بیشتری به فیلدهایی که کاردینالیتی بالاتر دارند در نظر میگیرد. اگر بخواهیم یک مثال افراطی از این مساله را مطرح کنیم، میتوانیم فیلدهای \trans{شناسه}{ID} را در نظر بگیریم. فیلد شناسه، به ویژگیهایی گفته میشود که در هر رکورد از مجموعهی داده، یک مقدار متفاوت به خود گرفته و لذا هرگز در مجموعهی داده تکرار نمیشوند. هر چند چنین ویژگیهایی از نظر نظریهی اطلاعات، دارای آنتروپی و اطلاعات زیادی هستند، اما واضح است که به دلیل عدم تکرار (یا تکرار بسیار کم) آنها در مجموعهی داده، یادگیری از آنها را غیر ممکن ساخته و لذا تخصیص پارامترهای زیاد به این ویژگیها، باعث هدر رفتن قدرت محاسباتی و همچنین افزایش خطر بیشبرازش میشود. | |||||
| برای اصلاح این مشکل، میتوانیم رابطهی فوق را به شکل زیر تغییر دهیم: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| \forall i: k_{i} = \omega \times \ln(|F_{i}|) \times \frac{|Dataset| - |F_{i}|}{|Dataset|} + \epsilon | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| که در آن $|Dataset|$ تعداد رکوردهای موجود در مجموعهی داده است. همانطور که مشخص است، کسر $\frac{|Dataset| - |F_{i}|}{|Dataset|}$ در صورتی که $|F_{i}|$ نسبت به تعداد رکوردهای مجموعهی داده، مقدار کمی داشته باشد، تقریبا برابر یک بوده و تاثیر چندانی روی نتیجهی رابطه نمیگذارد؛ اما در صورتی که $|F_{i}|$ نسبت به $|Dataset|$ قابل مقایسه باشد، این کسر میزان کمتر از یک به خود گرفته و لذا بعد تعبیه را برای این ویژگیها کاهش میدهد. به عبارت دیگر، برای ویژگیهایی که تعداد تکرار موجودیتهای آنها در مجموعهی داده کم باشد، بعد تعبیه را کمی کاهش میدهیم. در حالت افراطی ویژگیهای شناسه، که در آنها $|F_{i}|$ تقریبا با $|Dataset|$ برابر است، میزان این کسر تقریبا برابر صفر شده و لذا بعد تعبیه برای این ویژگیها به حداقل کاهش مییابد. | |||||
| با توجه به نکات مطرح شده، در این پژوهش بعد تعبیهی هریک از ویژگیهای دستهای، از رابطهی نهایی زیر محاسبه خواهد شد: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| \forall_{1 \le i \le f}: Dim(F_{i}) = \omega \times \ln(|F_{i}|) \times \frac{|Dataset| - |F_{i}|}{|Dataset|} + \epsilon | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| که در آن، $f$ تعداد فیلدهای ورودی است. همچنین، پارامترهای مربوط به تعبیهی فیلدهای مدل را به صورت زیر تعریف میکنیم: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| \forall_{1 \le i \le f}:\mathbf{E}_{i} \in \mathbb{R}^{|F_{i}|\times Dim(|F_{i}|)} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| حال اگر $x_{i}$ اندیس ویژگی فعال در فیلد $i$ام باشد، بردارهای تعبیه شدهی مدل به این صورت تعریف میشوند: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| \forall_{1 \le i \le f}:e_{i} = \mathbf{E}_{i}^{x_{i}} \in \mathbb{R}^{Dim(|F_{i}|)} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| در این بخش از دو زاویهی متفاوت به مسالهی محاسبهی بعد تعبیه برای فیلدهای ورودی نگریسته و به یک نتیجهی یکسان رسیدیم. نتایج هر دو بررسی، پرسشی را که در ابتدای این بخش مطرح کرده بودیم را رد کرده و لذا برخلاف همهی روشهای پیشین، در این پژوهش فیلدهای مختلف ورودی را در فضاهایی با ابعاد متفاوت تعبیه کرده و مدل محاسباتی خود را، بر مبنای این بردارهای تعبیه شده، طراحی مینماییم. | |||||
| \section{محاسبهی تعامل} | |||||
| در ادبیات پیشبینی نرخ کلیک، مفهوم تعامل، به ویژگیهای درجه دوم (یا بیشتر)ی اشاره میکند که نشان دهندهی تاثیر رخداد همزمان دو (یا چند) ویژگی باینری بر تصمیمات مدل هستند. به عبارت دیگر، تمامی اطلاعاتی که مدل از رخداد همزمان دو ویژگی باینری نیاز دارد، باید از طریق تعامل بین این دو ویژگی تامین شود. بدون در نظر گرفتن مفهوم تعامل، اکثر روشهای موجود در ادبیات پیشبینی نرخ کلیک، به یک مدل خطی و ساده کاهش یافته و این مساله، اهمیت بالای این مفهوم را میرساند. | |||||
| در اکثر روشهای معرفی شدهی پیشین که از مفهوم تعامل برای افزایش قابلیت مدلسازی استفاده میکنند، برای محاسبهی میزان تعامل از مکانیزمهای بسیار سادهای نظیر ضرب داخلی (در روشهای مبتنی بر ماشین فاکتورگیری ساده)، یا ضرب درایه به درایه و سپس ترکیب خطی از نتایج حاصل از آن (در روشهای مبتنی بر ماشین فاکتورگیری با توجه) استفاده میکنند. در نتیجه همهی این مدلها از نیاز به استفاده از بردارهای تعبیهی هم بعد برای همهی فیلدها (که در بخش قبل نشان دادیم ویژگی مناسبی نیست) رنج میبرند. | |||||
| به دلیل محدودیت عملگرهای ضرب داخلی و ضرب درایه به درایه به استفاده از بردارهای تعبیهی هم بعد، در این پژوهش نمیتوانیم به صورت مستقیم از این عملگرها برای محاسبهی میزان تعامل بین ویژگیهای فیلدهای مختلف بهره ببریم؛ در نتیجه باید راه دیگری برای پیادهسازی مفهوم تعامل بیابیم. در این بخش دو روش ممکن برای محاسبهی مقادیر تعامل را معرفی میکنیم. | |||||
| \subsection{نگاشت خطی بردارهای تعبیه به فضای همبعد} | |||||
| در پژوهش \cite{Ginart_MixedDimEmb}، یک روش ساده برای مقابله با این مشکل معرفی شده است. میدانیم ضرب ماتریسی بردارهای یک فضای $k_{in}$ بعدی، در یک ماتریس با ابعاد $k_{in} \times k_{out}$، یک نگاشت خطی بین فضای $k_{in}$ بعدی گفته شده و یک فضای $k_{out}$ بعدی جدید است. یعنی اگر $n$ بردار از فضای اول را در سطرهای ماتریس $X$ قرار دهیم و همچنین ماتریس $W_{k_{in} \times k_{out}}$ را از سمت راست در $X$ ضرب کنیم، حاصل این عمل نگاشت این بردارها در یک فضای جدید $k_{out}$ بعدی خواهد بود: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| Y_{n \times k_{out}} = X_{n \times k_{in}} W_{k_{in} \times k_{out}} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| در صورتی که $k_{in} < k_{out}$ باشد، نقاط در فضای $Y$ تنها به یک زیرفضا (منیفولد) از این فضای $k_{out}$ بعدی محدود شده و از تمام پیچیدگی موجود در این فضا استفاده نخواهد شد. همچنین در صورتی که $k_{in} > k_{out}$ باشد، نقاط در فضای $Y$ به صورت فشردهتری حضور داشته و میتوان گفت میزانی از اطلاعات نهفته در این نقاط، از دست خواهد رفت. | |||||
| در پژوهش فوق، پیشنهاد شده است که پس از ایجاد بردارهای تعبیه در فضاهای با ابعاد مختلف، با استفاده از تعدادی تبدیل ماتریسی خطی، همهی این فضاها را به فضای $k$ بعدی مشترک نگاشت کنیم؛ سپس مقادیر تعامل را مانند ماشینهای فاکتورگیری، به کمک عملگر ضرب داخلی محاسبه کنیم. چون ابعاد ماتریسهای گفته شده و در نتیجه تعداد پارامترهای آنها در مقایسه با تعداد پارامترهای جدولهای تعبیه ناچیز خواهد بود، لذا به سادگی میتوانیم این پارامترها را به کمک روشهای گرادیان کاهشی بیاموزیم. | |||||
| \subsection{محاسبهی تعامل به کمک شبکهی عصبی} | |||||
| در پژوهش \cite{he2017neural} که در ادبیات سیستمهای پیشنهاد دهنده انجام شده است، برای محاسبهی تعامل بین دو ویژگی کاربر و کالا، که به مسالهی \trans{فیلتر کردن مشترک}{Collaborative Filtering} معروف است، از ایدهی متفاوتی استفاده شده است. لازم به ذکر است این پژوهش، چندین روش مختلف و ترکیب آنها را معرفی کرده است، در صورتی که در این پژوهش، تنها به یکی از این روشها رجوع کرده و از ایدهی موجود در آن بهره میجوییم. | |||||
| برای محاسبهی تعامل بین دو بردار تعبیه شده، لزومی بر استفاده از عملگر ضرب داخلی وجود ندارد، بلکه میتوان از یک \trans{شبکهی عصبی چند لایه}{Multi Layer Perceptron} بهره جست. مهمترین ویژگی شبکههای عصبی چند لایه، توانایی تخمین همهی توابع است. یعنی در صورتی که یک شبکهی عصبی چند لایه، به تعداد کافی نورون داشته باشد و همچنین با مقدار کافی داده آموزش داده شود، میتواند روابط موجود بین این دادهها را با میزان خطای \trans{دلخواه}{Arbitrary} فرا گرفته و تخمین بزند؛ لذا به شبکههای عصبی چند لایه، \trans{تخمین زنندهی سراسری}{Global Approximator} نیز گفته میشود. | |||||
| در پژوهش فوق، پس از تعبیهی دو ویژگی موجود در مجموعهی داده، بردارهای تعبیه شده را به هم چسبانده و سپس از یک شبکهی عصبی چند لایه برای محاسبهی تعامل استفاده میشود. به دلیل سادگی و تطبیق پذیری شبکههای عصبی چندلایه، در این پژوهش نیز از این شبکهها برای محاسبهی تعامل بین ویژگیها بهره خواهیم جست. | |||||
| \subsection{تعاملهای چندبعدی به جای تعاملهای چندگانه} | |||||
| یکی از مزایای ماشینهای فاکتورگیری، سادگی پیادهسازی تعاملهای چندگانه است. تعاملهای چندگانه، به محاسبهی مفهوم تعامل بیشتر از دو ویژگی به صورت همزمان اشاره میکند. در ماشینهای فاکتورگیری، به دلیل محاسبهی تعامل به صورت ضرب داخلی، به سادگی میتوان عمل محاسبهی تعامل را به بیش از دو ویژگی تعمیم داد. به عنوان مثال، رابطهی زیر تعامل میان سه ویژگی در یک ماشین فاکتورگیری (مرتبه سوم) را نشان میدهد: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| I_{i, j, l} = \sum_{m = 1}^{k} e_{i_{m}}e_{j_{m}}e_{l_{m}} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| که در آن $k$ بعد تعبیهی مشترک همهی فیلدها است. به این ترتیب، ماشینهای فاکتورگیری ساده و بسیاری از مشتقات آن، به سادگی قابلیت محاسبهی تعامل چندگانه را دارا هستند. تعامل چندگانه قابلیت مدلسازی را افزایش داده و البته خطر بیشبرازش را افزایش میدهد. | |||||
| در این پژوهش، میتوانیم تعامل چندگانه را به سادگی با به هم چسباندن بیش از دو بردار تعبیه شده و تخصیص یک شبکهی عصبی به چند تایی مرتب فیلدهای انتخاب شده پیادهسازی کنیم؛ اما انجام این کار باعث افزایش بیرویهی پیچیدگی مدل و کاهش مقیاس پذیری روش پیشنهادی خواهد شد. | |||||
| ایدهای که برای رویارویی با این مشکل در این پژوهش معرفی میکنیم، استفاده از تعاملهای چندبعدی است. همهی روشهای پیشین به دلیل محدودیتهای ساختاری، مفهوم تعامل را به یک مفهوم تک بعدی که رابطهی آن با احتمال کلیک خطی است، تقلیل دادهاند. این در حالی است که میتوانیم مفهوم تعامل را به صورت زیر تعریف کرده و تعمیم دهیم: | |||||
| \begin{definition} | |||||
| تعامل بین دو فیلد، بردار نهفتهای است که تمامی اطلاعاتی که در زوج مرتب آن دو فیلد وجود دارد و برای تخمین نرخ کلیک مورد نیاز است را به صورت فشرده نمایش میدهد. | |||||
| \end{definition} | |||||
| تعریف فوق دو تفاوت عمده با تعریف تعامل در خانوادهی ماشینهای فاکتورگیری دارد: | |||||
| \begin{enumerate} | |||||
| \item \textbf{چندبعدی بودن} | |||||
| تعامل بین دو فیلد میتواند به جای تک بعدی بودن، چند بعدی باشد و در نتیجه رفتاری مانند بردارهای نهان در شبکههای عصبی داشته باشد. به این معنی که فضای چندبعدی ایجاد شده توسط تعامل بین دو فیلد، میتواند حاوی اطلاعاتی باشد که بخشهای دیگر مدل، آن را به صورت یک ویژگی سطح بالا دریافت کرده و لذا قادر به استخراج میزان بیشتری اطلاعات از این بردار نهان چندبعدی خواهند بود. | |||||
| \item \textbf{رابطهی غیر خطی} | |||||
| در ماشینهای فاکتورگیری، فرض شده است که مجموع همهی تعامل بین فیلدهای مختلف، با افزوده شدن به جملات خطی رگرسیون، به صورت مستقیم احتمال کلیک را تخمین میزنند. این در حالی است که با در نظر گرفتن مفهوم تعامل به عنوان ویژگیهای نهان در یک مدل ژرف، میتوان روابط پیچیدهتری نسبت به رابطهی خطی بین تعامل بین فیلدها و احتمال کلیک کشف نمود؛ پس لزومی ندارد که از رابطهی بین احتمال کلیک و تعاملهای بین ویژگیها را به یک رابطهی خطی تقلیل دهیم. | |||||
| \end{enumerate} | |||||
| با در نظر گرفتن تفاوتهای گفته شده، میتوان ساختار پیشنهادی را ارائه کرد، ولی پیش از معرفی نهایی ساختار پیشنهادی، پرسشی که ممکن است در این مرحله به ذهن برسد را مطرح کرده و پاسخ میدهیم. | |||||
| \begin{itemize} | |||||
| \item \textbf{پرسش} | |||||
| چرا به جای تعامل چندبعدی، با افزایش تعداد لایهها در شبکههای تعامل، از تعامل تک بعدی استفاده نکنیم؟ این گونه به نظر میرسد که در صورتی که تعداد لایههای شبکههای تعامل را افزایش دهیم، مدل میتواند تعاملهای چندبعدی گفته شده را در یکی از لایههای نهان داخل همین شبکههای تعامل فرا گرفته و سپس با استخراج اطلاعات مفید آن، تعامل را به صورت تک بعدی به بخشهای دیگر مدل انتقال دهد؛ در نتیجه معرفی تعامل چندبعدی به نظر بیدلیل میرسد. | |||||
| \item \textbf{پاسخ} | |||||
| با توجه به تعریف بالا برای مفهوم تعامل، این مفهوم مربوط به اطلاعات مشترکی است که بین ویژگیهای دو فیلد وجود دارند؛ پس در نظر گرفتن \trans{تنگنا}{Bottleneck}ی تک بعدی، باعث محدودیت شده و ممکن است این اطلاعات مشترک برای عبور از این تنگنا فیلتر شده و بخش مهمی از این اطلاعات از دست برود. | |||||
| دلیل دیگر استفاده از تعاملهای چندبعدی، به اشکالی که قبلا معرفی کردیم یعنی عدم مقیاس پذیری مدل پیشنهادی در صورت استفاده از تعاملهای چندگانه باز میگردد. در صورتی که اطلاعات مهمی در تعامل سه فیلد یا بیشتر وجود داشته باشد، در تعاملهای تک بعدی این اطلاعات در تنگنای فوق حذف شده و مدل قادر به استخراج اطلاعات مربوط به تعامل چندگانه نخواهد بود. این در حالی است که اگر اجازه دهیم بردارهای تعامل، چند بعدی باشند، مدل میتواند از کنار هم قرار دادن تعاملهای دوگانه، تعاملهای مرتبهی بالاتر را به صورت \trans{ضمنی}{Implicit} محاسبه کرده و از آن برای پیشبینی نرخ کلیک بهره ببرد. عملا با در نظر گرفتن تعاملهای چندبعدی، نیاز به استفاده از تعاملهای چندگانه حذف شده و لذا مقیاس پذیری مدل افزایش مییابد. | |||||
| \end{itemize} | |||||
| با استدلالهای گفته شده، روش محاسبهی بردارهای تعامل بین فیلدهای ورودی تکمیل شده و لذا در این بخش، با اشاره به برخی جزئیات، این بخش مهم از روش پیشنهادی را جمع بندی میکنیم. | |||||
| در بخش قبل بردارهای تعبیه شدهی مدل را تعریف کردیم. اگر در مجموعهی داده، $f$ فیلد داشته باشیم، بردارهای تعبیهی فیلدها را با | |||||
| $\{e_{1}, e_{2}, \dots, e_{f}\}$ | |||||
| نمایش میدهیم. چون تعامل بین ویژگیهای هر دو فیلد محاسبه میشود، نیاز به $\frac{f(f - 1)}{2}$ شبکهی عصبی تعامل خواهیم داشت. برای سادگی نامگذاری، این شبکهها را به صورت زیر نامگذاری میکنیم: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| \forall_{1 \le i < j \le f}, InteractionNet_{i, j} : \RR^{Dim(|F_{i}|) + Dim(|F_{j}|)} \rightarrow \RR^{Dim_{Int}} | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| شبکهی $InteractionNet_{i, j}$ چندلایه بوده و تعداد نورونهای هر لایه، به صورت خطی کاهش مییابد تا از $Dim(|F_{i}|) + Dim(|F_{j}|)$ بعد به $Dim_{Int}$ بعد برسد. تعداد لایههای همهی این شبکهها برابر $Depth_{Interaction}$ است. در فصل بعد با انجام آزمایشهایی، تعداد لایهها و همچنین بعد بردارهای تعامل مناسب را به دست خواهیم آورد. | |||||
| تابع فعالساز همهی لایههای این شبکهها (بجز لایهی آخر) را \trans{واحد خطی یکسو کنندهی نشت کننده}{LeakyReLU}\cite{maas2013leakyrelu} در نظر میگیریم. دلیل استفاده از این تابع، انتقال بهتر گرادیان به لایههای پایینتر است. در لایهی آخر این شبکهها، برای استفاده در بخشهای دیگر مدل، از هیچ تابع فعالسازی استفاده نمیکنیم. در این پژوهش مقادیر بردارهای تعامل را به شکل زیر نامگذاری و محاسبه میکنیم: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| \forall_{1 \le i < j \le f}, I_{i, j} = InteractionNet_{i, j}(e_{i}: e_{j}) | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| \section{استفاده از بردارهای تعبیه و تعامل برای تخمین نرخ کلیک} | |||||
| در بخشهای قبل، شیوهی تعبیهی ویژگیها و همچنین نحوهی محاسبهی تعامل بین بردارهای تعبیه شده در روش پیشنهادی را معرفی کردیم. در این قسمت تنها بخش باقی ماندهی مدل را معرفی میکنیم. این بخش \trans{شبکهی سر}{Head Network} نام دارد و مسئول استفاده از همهی ویژگیهایی که تا اینجا تعریف کردیم و پیشبینی نرخ کلیک به کمک این ویژگیها است. | |||||
| در تعدادی از پژوهشهای پیشین که از مدلهای ژرف استفاده کردهاند، برای محاسبهی نرخ کلیک از دو دسته ویژگی مهم استفاده میشود: | |||||
| \begin{enumerate} | |||||
| \item \textbf{ویژگیهای مرتبه پایین} | |||||
| ویژگیهای مرتبه پایین در مدلهای ژرف مبتنی بر ماشین فاکتورگیری، شامل جملهی بایاس، جملات خطی و همچنین تعاملهای مرتبه دوم است. همانطور که مشخص است، این ویژگیها نقش اساسی در شکل دهی به تابع تصمیمگیری مدلها دارند. این ویژگیها به دلیل سادگی در محاسبه و همچنین نقش ساده و مشخص در پیشبینی نرخ کلیک، به سادگی نیز آموزش یافته و به همین دلیل با تعداد دادههای کم نیز قابل یادگیری هستند. | |||||
| \item \textbf{ویژگیهای مرتبه بالا} | |||||
| با گسترش روشهای ژرف، محققین متوجه توانایی بالای این روشها برای استخراج \trans{ویژگیهای نهان}{Latent Features} و استفاده از آنها یا استفاده از سایر ویژگیهای مرتبه بالا شدند. مدلهای ژرف، در صورتی که دادههای کافی در اختیار داشته باشند، قادر خواهند بود ویژگیهای نهان مفیدی ساخته و آنها را برای محاسبهی متغیر هدف به کار ببرند؛ در نتیجه بسیاری از پژوهشهای پیشین برای پیشبینی نرخ کلیک، از این مزیت بهره جستهاند. | |||||
| ویژگیهای مرتبه بالا در مدلهای پیشبینی نرخ کلیک، شامل تعاملهای مرتبه بالا بین بردارهای تعبیه و همچنین ویژگیهای نهان که در برخی پژوهشها به آنها \trans{تعاملهای ضمنی}{Implicit Interactions} نیز گفته میشود، هستند. استدلال این نامگذاری، این نکته است که مقادیر تعامل، به صورت \trans{صریح}{Explicit} فرمولهبندی و محاسبه میشوند. در حالی که مدلهای ژرف، میتوانند ویژگیهای نهانی محاسبهکنند که عملا تفاوتی با مقادیر تعامل بین ویژگیها ندارند، اما فرموله بندی صریحی برای آنها وجود ندارد؛ در نتیجه مدلهای ژرف بر حسب نیاز، این ویژگیها را استخراج کرده و از آنها استفاده میکنند؛ لذا میتوان این ویژگیها را نسخهی غیر صریح یا ضمنی (و همچنین پیچیدهتر) مفهوم تعامل در نظر گرفت. | |||||
| ویژگیهای مرتبه بالا برای یادگیری، به دادههای بیشتری نیاز داشته و شامل اطلاعات بیشتری هستند؛ اما آموزش آنها علاوه بر محاسبات بیشتر، نیاز به طراحی دقیقتر و چالشهای مختلف، به مراقبت ویژه در مقابل خطر بیشبرازش نیاز دارند. | |||||
| \end{enumerate} | |||||
| همانطور که گفته شد، در بسیاری از پژوهشهای ژرف پیشین، از هر دو دستهی این ویژگیها استفاده میشود. دستهی اول، شکل کلی تابع تصمیمگیری را ترسیم کرده و دستهی دوم، به مدل کمک میکنند که این تابع را به طرز دقیقتری شکل داده و انعطاف کافی برای مدلسازی را به آن بیافزاید. | |||||
| در این پژوهش نیز، از همین شیوه بهره جسته و از دو دسته ویژگی مختلف برای استفادهی شبکهی سر استفاده میکنیم. انتظار داریم این عمل هم در شرایط شروع سرد و هم در مقابل مشکل بیشبرازش باعث بهبود کلی عملکرد مدل شود؛ پس ورودی شبکهی سر، شامل دو بخش است: | |||||
| \begin{itemize} | |||||
| \item \textbf{بردارهای تعبیه} | |||||
| شبکهی سر، برای پیشبینی نرخ کلیک، نیاز به ویژگیهای مرتبه پایین دارد. به دلیل عدم استفاده از جملات رگرسیون خطی، تنها ویژگیهای مرتبه پایینی که در اختیار داریم، خود بردارهای تعبیه است؛ بنابراین همهی بردارهای تعبیه را به هم چسبانده و به عنوان ورودی اول شبکهی سر استفاده میکنیم. | |||||
| \item \textbf{بردارهای تعامل} | |||||
| همچنین، شبکهی سر برای استخراج ویژگیهای نهان و تخمین دقیق مرز تصمیمگیری، نیاز به ویژگیهای مرتبه بالا دارد. برای تامین این ویژگیهای مرتبهی بالا، همهی بردارهای تعامل که توسط شبکههای تعامل محاسبه شدهاند را به هم چسبانده و به عنوان ورودی دوم شبکهی سر استفاده میکنیم. | |||||
| \end{itemize} | |||||
| شبکهی سر، یک شبکهی عصبی چند لایه است که بجز لایهی آخر، تعداد نورونهای همهی لایههای آن ثابت بوده و در آن از واحدهای خطی یکسوکنندهی نشت کننده به عنوان تابع فعالساز استفاده میکنیم. تعداد لایههای این شبکه را با $Depth_{HeadNet}$ و تعداد نورونهای هر لایه را با $Width_{HeadNet}$ نشان میدهیم. لایهی آخر این شبکه برای محاسبهی احتمال کلیک، دارای تنها یک نورون بوده و از تابع فعالساز سیگموید برای آن استفاده میکنیم. | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| \hat{y} = HeadNet(e_{1}: e_{2}:\dots:e_{f}:I_{1, 2}:I_{1, 3}:\dots:I_{f-1, f}) | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| چون مسالهی پیشبینی احتمال کلیک، جزو مسائل دستهبندی دو کلاسه است، پس میتوانیم مدل پیشنهادی را با تابع هزینهی خطای لگاریتمی آموزش دهیم. خطای لگاریتمی از طریق رابطهی زیر محاسبه میشود: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| LogLoss(y, \hat{y}) = - y \log(\hat{y}) - (1 - y)\log(1 - \hat{y}) | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| همانطور که از رابطهی خطای لگاریتمی مشخص است، این تابع برای نمونههای دو دسته، وزن یکسان در نظر میگیرد؛ اما در نظر گرفتن وزن یکسان برای هر دو دسته، در شرایطی که عدم توازن بین دستهها وجود دارد، میتواند باعث شود مرز تصمیم گیری به سمت \trans{دستهی اقلیت}{Minority Class} حرکت کرده و در نتیجه عملکرد مدل را برای نمونههای این دسته تضعیف کند. برای مقابله با این مشکل، روشهای متعددی ارائه شده است. در این پژوهش، از وزندهی تابع خطا استفاده میکنیم. وزندهی تابع خطا به این صورت است که خطای نمونههای کلاس اکثریت را در یک ضریب کوچک و خطای نمونههای دستهی اقلیت را در یک ضریب بیشتر ضرب میکنیم؛ در نتیجه میزان تاثیر دو کلاس بر تابع خطا یکسان شده و در نتیجه مشکل عدم توازن بین کلاسها تا حدود زیادی حل میشود. خطای لگاریتمی در صورتی که از وزن دهی استفاده کنیم، به شکل زیر در میآید: | |||||
| \begin{latin} | |||||
| \begin{equation} | |||||
| LogLoss(y, \hat{y}) = - y \log(\hat{y}) W_{Click} - (1 - y)\log(1 - \hat{y}) (1 - W_{Click}) | |||||
| \end{equation} | |||||
| \end{latin} | |||||
| که در آن $W_{Click}$ نسبت تعداد نمونههای کلیک نشده در کل مجموعهی داده است. | |||||
| تمامی قسمتهای روش پیشنهادی، مشتق پذیر هستند. پس میتوانیم همهی این قسمتها را \trans{سر تا سر}{End To End} با روشهای \trans{گرادیان کاهشی دستهای}{Mini-Batch Gradient Descent} آموزش دهیم. برای انجام این کار، از روش \trans{آدام}{ADAptive Moment estimation} استفاده میکنیم. | |||||
| \section{جمعبندی روش پیشنهادی} | |||||
| در جدول \ref{tbl:ideas} با جمعبندی ایدههای استفاده شده در روش پیشنهادی و مزایای آنها در مقابل چالشهای مساله و همچنین معایب یا چالشهای احتمالی هر کدام، این فصل را به پایان میبریم. | |||||
| \begin{table}[!ht] | |||||
| \caption{خلاصهی ایدههای استفاده شده در روش پیشنهادی} | |||||
| \label{tbl:ideas} | |||||
| %\begin{latin} | |||||
| \scriptsize | |||||
| \begin{center} | |||||
| \begin{tabular}{|c|c|c|c|} | |||||
| \hline | |||||
| تکنیک مورد استفاده & | |||||
| چالش مورد نظر & | |||||
| مزایا در مقابل این چالش & | |||||
| معایب و محدودیتها \\ \hline | |||||
| \multirow{4}{*}{تعبیه در ابعاد متفاوت} & | |||||
| ابعاد بالا & | |||||
| \begin{tabular}[c]{@{}c@{}}کاهش پارامترهای غیر ضروری\\ و جلوگیری از خطر بیشبرازش\end{tabular} & | |||||
| \multirow{2}{*}{\begin{tabular}[c]{@{}c@{}}استفاده از عملگرهای معمول برای\\ محاسبهی تعامل امکان پذیر نیست\end{tabular}} \\ \cline{2-3} | |||||
| & | |||||
| شروع سرد & | |||||
| افزایش سرعت یادگیری به کمک تعبیهی موثر & | |||||
| \\ \cline{2-4} | |||||
| & | |||||
| سرعت آموزش & | |||||
| پارامترهای کمتر و افزایش سرعت آموزش & | |||||
| \multirow{2}{*}{\begin{tabular}[c]{@{}c@{}}نیاز به مشخص کردن رابطهای\\ برای ابعاد بردارهای تعبیهی هر فیلد\end{tabular}} \\ \cline{2-3} | |||||
| & | |||||
| سرعت اجرا & | |||||
| محاسبات کمتر و افزایش سرعت پیشبینی & | |||||
| \\ \hline | |||||
| \multirow{3}{*}{\begin{tabular}[c]{@{}c@{}}محاسبهی تعامل به کمک\\ شبکههای عصبی چند لایه\end{tabular}} & | |||||
| مدلسازی بهتر & | |||||
| استخراج تعاملها با پیچیدگی بیشتر & | |||||
| افزایش جزئی خطر بیشبرازش \\ \cline{2-4} | |||||
| & | |||||
| شروع سرد & | |||||
| \begin{tabular}[c]{@{}c@{}}بهره گیری از فضای چگال بردارهای\\ تعبیه برای محاسبهی تعامل\end{tabular} & | |||||
| \multirow{2}{*}{لزوم استفاده از تنظیم} \\ \cline{2-3} | |||||
| & | |||||
| سرعت اجرا & | |||||
| \begin{tabular}[c]{@{}c@{}}وجود پیادهسازیهای سریع\\ برای شبکههای عصبی چند لایه\end{tabular} & | |||||
| \\ \hline | |||||
| \multirow{2}{*}{تعاملهای چند بعدی} & | |||||
| مدلسازی بهتر & | |||||
| وجود اطلاعات بیشتر در بردارهای تعامل & | |||||
| \multirow{2}{*}{افزایش جزئی خطر بیشبرازش} \\ \cline{2-3} | |||||
| & | |||||
| مدلسازی بهتر & | |||||
| عدم نیاز به تعاملهای چندگانه & | |||||
| \\ \hline | |||||
| \multirow{3}{*}{\begin{tabular}[c]{@{}c@{}}ترکیب بردارهای\\ تعبیه و تعامل\end{tabular}} & | |||||
| مدلسازی بهتر & | |||||
| \begin{tabular}[c]{@{}c@{}}وجود اطلاعات مفید در ویژگیهای\\ مرتبه پایین و مرتبه بالا\end{tabular} & | |||||
| \multirow{3}{*}{افزایش جزئی خطر بیشبرازش} \\ \cline{2-3} | |||||
| & | |||||
| شروع سرد & | |||||
| \begin{tabular}[c]{@{}c@{}}حضور ویژگیهای مرتبه پایین در صورت\\ عدم حضور ویژگیهای مرتبه بالا\end{tabular} & | |||||
| \\ \cline{2-3} | |||||
| & | |||||
| سرعت آموزش & | |||||
| رسیدن گرادیان از مسیرهای متعدد به بردارهای تعبیه & | |||||
| \\ \hline | |||||
| وزن دهی تابع خطا & | |||||
| عدم توازن بین دستهها & | |||||
| جلوگیری از بایاس شدن مدل به سمت دستهی اکثریت & | |||||
| کاهش جزئی سرعت همگرایی \\ \hline | |||||
| \end{tabular} | |||||
| \end{center} | |||||
| \end{table} | |||||
+ 156
- 0
Thesis/chap4.aux
View File
| \relax | |||||
| \providecommand\zref@newlabel[2]{} | |||||
| \providecommand\hyper@newdestlabel[2]{} | |||||
| \zref@newlabel{zref@116}{\abspage{51}\page{44}\pagevalue{44}} | |||||
| \@writefile{toc}{\contentsline {chapter}{فصل\nobreakspace {}\numberline {4}یافتههای پژوهش}{44}{chapter.4}} | |||||
| \@writefile{lof}{\addvspace {10\p@ }} | |||||
| \@writefile{lot}{\addvspace {10\p@ }} | |||||
| \newlabel{Chap:Chap4}{{4}{44}{یافتههای پژوهش}{chapter.4}{}} | |||||
| \@writefile{toc}{\contentsline {section}{\numberline {4-1}مجموعههای داده}{44}{section.4.1}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {4-1-1}آوتبرین}{44}{subsection.4.1.1}} | |||||
| \zref@newlabel{footdir@259}{\abspage{51}} | |||||
| \zref@newlabel{zref@117}{\abspage{51}\page{44}\pagevalue{44}} | |||||
| \zref@newlabel{footdir@261}{\abspage{51}} | |||||
| \zref@newlabel{footdir@260}{\abspage{51}} | |||||
| \zref@newlabel{footdir@262}{\abspage{52}} | |||||
| \zref@newlabel{zref@118}{\abspage{52}\page{45}\pagevalue{45}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{آوتبرین پیشپردازش شده}{45}{section*.19}} | |||||
| \zref@newlabel{footdir@264}{\abspage{52}} | |||||
| \zref@newlabel{footdir@263}{\abspage{52}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {4-1-2}کرایتیو}{46}{subsection.4.1.2}} | |||||
| \zref@newlabel{footdir@265}{\abspage{53}} | |||||
| \zref@newlabel{zref@119}{\abspage{53}\page{46}\pagevalue{46}} | |||||
| \zref@newlabel{footdir@267}{\abspage{53}} | |||||
| \zref@newlabel{zref@120}{\abspage{53}\page{46}\pagevalue{46}} | |||||
| \zref@newlabel{footdir@269}{\abspage{53}} | |||||
| \zref@newlabel{zref@121}{\abspage{53}\page{46}\pagevalue{46}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{کرایتیو-22}{46}{section*.20}} | |||||
| \zref@newlabel{footdir@271}{\abspage{53}} | |||||
| \zref@newlabel{footdir@266}{\abspage{53}} | |||||
| \zref@newlabel{footdir@268}{\abspage{53}} | |||||
| \zref@newlabel{footdir@270}{\abspage{53}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{کرایتیو-21}{47}{section*.21}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{کرایتیو-20}{47}{section*.22}} | |||||
| \@writefile{toc}{\contentsline {section}{\numberline {4-2}معیارهای ارزیابی}{47}{section.4.2}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {4-2-1}خطای لگاریتمی}{47}{subsection.4.2.1}} | |||||
| \zref@newlabel{footdir@272}{\abspage{54}} | |||||
| \zref@newlabel{zref@122}{\abspage{54}\page{47}\pagevalue{47}} | |||||
| \zref@newlabel{footdir@274}{\abspage{54}} | |||||
| \zref@newlabel{zref@123}{\abspage{54}\page{47}\pagevalue{47}} | |||||
| \zref@newlabel{footdir@276}{\abspage{54}} | |||||
| \zref@newlabel{footdir@273}{\abspage{54}} | |||||
| \zref@newlabel{footdir@275}{\abspage{54}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {4-2-2}مساحت تحت منحنی}{48}{subsection.4.2.2}} | |||||
| \zref@newlabel{footdir@279}{\abspage{55}} | |||||
| \zref@newlabel{zref@125}{\abspage{55}\page{48}\pagevalue{48}} | |||||
| \zref@newlabel{footdir@277}{\abspage{55}} | |||||
| \zref@newlabel{zref@124}{\abspage{55}\page{48}\pagevalue{48}} | |||||
| \zref@newlabel{footdir@281}{\abspage{55}} | |||||
| \zref@newlabel{zref@126}{\abspage{55}\page{48}\pagevalue{48}} | |||||
| \zref@newlabel{footdir@283}{\abspage{55}} | |||||
| \zref@newlabel{zref@127}{\abspage{55}\page{48}\pagevalue{48}} | |||||
| \zref@newlabel{footdir@285}{\abspage{55}} | |||||
| \zref@newlabel{footdir@278}{\abspage{55}} | |||||
| \zref@newlabel{footdir@280}{\abspage{55}} | |||||
| \zref@newlabel{footdir@282}{\abspage{55}} | |||||
| \zref@newlabel{footdir@284}{\abspage{55}} | |||||
| \@writefile{toc}{\contentsline {section}{\numberline {4-3}روشهای تنظیم پارامترها}{49}{section.4.3}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {4-3-1}تنظیم مرتبهی دوم}{49}{subsection.4.3.1}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{تنظیم مرتبهی دوم روی پارامترهای تعبیه}{49}{section*.23}} | |||||
| \@writefile{lof}{\contentsline {figure}{\numberline {4-1}{\ignorespaces مساحت تحت نمودار، به ازای مقادیر مختلف ضریب تنظیم مرتبهی دوم برای پارامترهای تعبیهی مدل \relax }}{50}{figure.caption.24}} | |||||
| \newlabel{fig:l2reg_on_emb}{{4-1}{50}{مساحت تحت نمودار، به ازای مقادیر مختلف ضریب تنظیم مرتبهی دوم برای پارامترهای تعبیهی مدل \relax }{figure.caption.24}{}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{تنظیم مرتبهی دوم روی پارامترهای شبکههای تعامل}{50}{section*.25}} | |||||
| \@writefile{lof}{\contentsline {figure}{\numberline {4-2}{\ignorespaces مساحت تحت نمودار، به ازای مقادیر مختلف ضریب تنظیم مرتبهی دوم برای پارامترهای شبکههای تعامل \relax }}{51}{figure.caption.26}} | |||||
| \newlabel{fig:l2reg_on_int}{{4-2}{51}{مساحت تحت نمودار، به ازای مقادیر مختلف ضریب تنظیم مرتبهی دوم برای پارامترهای شبکههای تعامل \relax }{figure.caption.26}{}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{تنظیم مرتبهی دوم روی پارامترهای شبکهی سر}{51}{section*.27}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {4-3-2}حذف تصادفی}{51}{subsection.4.3.2}} | |||||
| \@writefile{lof}{\contentsline {figure}{\numberline {4-3}{\ignorespaces مساحت تحت نمودار، به ازای مقادیر مختلف ضریب تنظیم مرتبهی دوم برای پارامترهای شبکهی سر \relax }}{52}{figure.caption.28}} | |||||
| \newlabel{fig:l2reg_on_head}{{4-3}{52}{مساحت تحت نمودار، به ازای مقادیر مختلف ضریب تنظیم مرتبهی دوم برای پارامترهای شبکهی سر \relax }{figure.caption.28}{}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{حذف تصادفی پارامترهای تعبیه}{52}{section*.29}} | |||||
| \@writefile{lof}{\contentsline {figure}{\numberline {4-4}{\ignorespaces مساحت تحت نمودار، به ازای مقادیر مختلف نرخ حذف تصادفی در پارامترهای تعبیهی مدل \relax }}{53}{figure.caption.30}} | |||||
| \newlabel{fig:dropout_on_emb}{{4-4}{53}{مساحت تحت نمودار، به ازای مقادیر مختلف نرخ حذف تصادفی در پارامترهای تعبیهی مدل \relax }{figure.caption.30}{}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{حذف تصادفی پارامترهای شبکههای تعامل}{53}{section*.31}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{حذف تصادفی پارامترهای شبکهی سر}{53}{section*.33}} | |||||
| \@writefile{lof}{\contentsline {figure}{\numberline {4-5}{\ignorespaces مساحت تحت نمودار، به ازای مقادیر مختلف نرخ حذف تصادفی در پارامترهای شبکههای تعامل \relax }}{54}{figure.caption.32}} | |||||
| \newlabel{fig:dropout_on_int}{{4-5}{54}{مساحت تحت نمودار، به ازای مقادیر مختلف نرخ حذف تصادفی در پارامترهای شبکههای تعامل \relax }{figure.caption.32}{}} | |||||
| \@writefile{lof}{\contentsline {figure}{\numberline {4-6}{\ignorespaces مساحت تحت نمودار، به ازای مقادیر مختلف نرخ حذف تصادفی در پارامترهای شبکهی سر \relax }}{54}{figure.caption.34}} | |||||
| \newlabel{fig:dropout_on_head}{{4-6}{54}{مساحت تحت نمودار، به ازای مقادیر مختلف نرخ حذف تصادفی در پارامترهای شبکهی سر \relax }{figure.caption.34}{}} | |||||
| \@writefile{lof}{\contentsline {figure}{\numberline {4-7}{\ignorespaces مساحت تحت نمودار، به ازای تعداد لایههای مختلف شبکههای تعامل و همچنین مقادیر مختلف بعد بردارهای تعامل \relax }}{55}{figure.caption.35}} | |||||
| \newlabel{fig:InteractionNet_experiment}{{4-7}{55}{مساحت تحت نمودار، به ازای تعداد لایههای مختلف شبکههای تعامل و همچنین مقادیر مختلف بعد بردارهای تعامل \relax }{figure.caption.35}{}} | |||||
| \@writefile{toc}{\contentsline {section}{\numberline {4-4}سایر آزمایشها}{55}{section.4.4}} | |||||
| \zref@newlabel{footdir@286}{\abspage{62}} | |||||
| \zref@newlabel{zref@128}{\abspage{62}\page{55}\pagevalue{55}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {4-4-1}تعداد لایههای شبکههای تعامل و بعد بردارهای تعامل}{55}{subsection.4.4.1}} | |||||
| \zref@newlabel{footdir@288}{\abspage{62}} | |||||
| \zref@newlabel{footdir@287}{\abspage{62}} | |||||
| \citation{t-sne} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {4-4-2}تعداد لایهها و نورونهای شبکهی سر}{56}{subsection.4.4.2}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {4-4-3}بررسی فضای تعبیه}{56}{subsection.4.4.3}} | |||||
| \@writefile{lof}{\contentsline {figure}{\numberline {4-8}{\ignorespaces مساحت تحت نمودار، به ازای تعداد لایههای مختلف شبکههای تعامل و همچنین مقادیر مختلف بعد بردارهای تعامل روی مجموعه دادهی کرایتیو-22 \relax }}{57}{figure.caption.36}} | |||||
| \newlabel{fig:HeadNet_experiment1}{{4-8}{57}{مساحت تحت نمودار، به ازای تعداد لایههای مختلف شبکههای تعامل و همچنین مقادیر مختلف بعد بردارهای تعامل روی مجموعه دادهی کرایتیو-22 \relax }{figure.caption.36}{}} | |||||
| \@writefile{lof}{\contentsline {figure}{\numberline {4-9}{\ignorespaces مساحت تحت نمودار، به ازای تعداد لایههای مختلف شبکههای تعامل و همچنین مقادیر مختلف بعد بردارهای تعامل روی مجموعه دادهی آوتبرین \relax }}{57}{figure.caption.37}} | |||||
| \newlabel{fig:HeadNet_experiment2}{{4-9}{57}{مساحت تحت نمودار، به ازای تعداد لایههای مختلف شبکههای تعامل و همچنین مقادیر مختلف بعد بردارهای تعامل روی مجموعه دادهی آوتبرین \relax }{figure.caption.37}{}} | |||||
| \@writefile{lof}{\contentsline {figure}{\numberline {4-10}{\ignorespaces نمایی از فضای تعبیهی استخراج شده از فیلد موقعیت جغرافیایی در مجموعهی دادهی آوتبرین توسط روش پیشنهادی \relax }}{58}{figure.caption.38}} | |||||
| \newlabel{fig:GeoLocEmb}{{4-10}{58}{نمایی از فضای تعبیهی استخراج شده از فیلد موقعیت جغرافیایی در مجموعهی دادهی آوتبرین توسط روش پیشنهادی \relax }{figure.caption.38}{}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {4-4-4}مقایسه با روشهای پیشین}{59}{subsection.4.4.4}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{مجموعه دادهی آوتبرین}{59}{section*.39}} | |||||
| \@writefile{lot}{\contentsline {table}{\numberline {4-1}{\ignorespaces مقایسهی نهایی عملکرد روی مجموعهی آوتبرین\relax }}{59}{table.caption.40}} | |||||
| \newlabel{tbl:outbrain_results}{{4-1}{59}{مقایسهی نهایی عملکرد روی مجموعهی آوتبرین\relax }{table.caption.40}{}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{مجموعه دادهی کرایتیو-22}{60}{section*.41}} | |||||
| \@writefile{lot}{\contentsline {table}{\numberline {4-2}{\ignorespaces مقایسهی نهایی عملکرد روی مجموعهی کرایتیو-22\relax }}{60}{table.caption.42}} | |||||
| \newlabel{tbl:criteo22_results}{{4-2}{60}{مقایسهی نهایی عملکرد روی مجموعهی کرایتیو-22\relax }{table.caption.42}{}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{مجموعه دادهی کرایتیو-21}{61}{section*.43}} | |||||
| \@writefile{lot}{\contentsline {table}{\numberline {4-3}{\ignorespaces مقایسهی نهایی عملکرد روی مجموعهی کرایتیو-21\relax }}{61}{table.caption.44}} | |||||
| \newlabel{tbl:criteo21_results}{{4-3}{61}{مقایسهی نهایی عملکرد روی مجموعهی کرایتیو-21\relax }{table.caption.44}{}} | |||||
| \@writefile{toc}{\contentsline {subsubsection}{مجموعه دادهی کرایتیو-20}{62}{section*.45}} | |||||
| \@writefile{lot}{\contentsline {table}{\numberline {4-4}{\ignorespaces مقایسهی نهایی عملکرد روی مجموعهی کرایتیو-20\relax }}{63}{table.caption.46}} | |||||
| \newlabel{tbl:criteo20_results}{{4-4}{63}{مقایسهی نهایی عملکرد روی مجموعهی کرایتیو-20\relax }{table.caption.46}{}} | |||||
| \@setckpt{chap4}{ | |||||
| \setcounter{page}{64} | |||||
| \setcounter{equation}{0} | |||||
| \setcounter{enumi}{2} | |||||
| \setcounter{enumii}{0} | |||||
| \setcounter{enumiii}{0} | |||||
| \setcounter{enumiv}{0} | |||||
| \setcounter{footnote}{1} | |||||
| \setcounter{mpfootnote}{0} | |||||
| \setcounter{part}{0} | |||||
| \setcounter{chapter}{4} | |||||
| \setcounter{section}{4} | |||||
| \setcounter{subsection}{4} | |||||
| \setcounter{subsubsection}{0} | |||||
| \setcounter{paragraph}{0} | |||||
| \setcounter{subparagraph}{0} | |||||
| \setcounter{figure}{10} | |||||
| \setcounter{table}{4} | |||||
| \setcounter{parentequation}{0} | |||||
| \setcounter{ALC@unique}{0} | |||||
| \setcounter{ALC@line}{0} | |||||
| \setcounter{ALC@rem}{0} | |||||
| \setcounter{ALC@depth}{0} | |||||
| \setcounter{float@type}{8} | |||||
| \setcounter{algorithm}{0} | |||||
| \setcounter{ContinuedFloat}{0} | |||||
| \setcounter{KVtest}{0} | |||||
| \setcounter{subfigure}{0} | |||||
| \setcounter{subfigure@save}{0} | |||||
| \setcounter{lofdepth}{1} | |||||
| \setcounter{subtable}{0} | |||||
| \setcounter{subtable@save}{0} | |||||
| \setcounter{lotdepth}{1} | |||||
| \setcounter{pp@next@reset}{0} | |||||
| \setcounter{zpage}{55} | |||||
| \setcounter{@pps}{0} | |||||
| \setcounter{@ppsavesec}{0} | |||||
| \setcounter{@ppsaveapp}{0} | |||||
| \setcounter{Item}{7} | |||||
| \setcounter{Hfootnote}{124} | |||||
| \setcounter{Hy@AnnotLevel}{0} | |||||
| \setcounter{bookmark@seq@number}{43} | |||||
| \setcounter{su@anzahl}{0} | |||||
| \setcounter{LT@tables}{0} | |||||
| \setcounter{LT@chunks}{0} | |||||
| \setcounter{footdir@label}{288} | |||||
| \setcounter{shadetheorem}{1} | |||||
| \setcounter{section@level}{3} | |||||
| } |
+ 415
- 0
Thesis/chap4.tex
View File
| % !TEX encoding = UTF-8 Unicode | |||||
| \chapter{یافتههای پژوهش}\label{Chap:Chap4} | |||||
| %================================================================== | |||||
| در این بخش ابتدا مجموعههای دادهی مورد استفاده را معرفی کرده و مختصرا در مورد خصوصیات آنها بحث میکنیم؛ سپس برخی از معیارهای ارزیابی مهم در این حوزه را معرفی کرده و دلایل انتخاب این معیارها را شرح میدهیم. پس از آن، روشهای مورد استفاده در این پژوهش برای تنظیم پارامترها را توضیح میداده و با انجام آزمایشهایی، بهترین مقادیر را برای ابرپارامترهای مدل به دست میآوریم؛ سپس با طراحی و اجرای چندین آزمایش، عملکرد روش پیشنهادی را با برخی از روشهای پیشین مقایسه کرده و به برخی سوالات احتمالی پاسخ میدهیم. | |||||
| \section{مجموعههای داده} | |||||
| در این بخش به معرفی و بررسی مجموعه دادههای مورد استفاده در این پژوهش میپردازیم. لازم به ذکر است پیشپردازشهای مختلفی که به خاطر محدودیتهای سختافزاری اعمال میکنیم، باعث میشود نتوانیم نتایج به دست آمده را با نتایج گزارش شده توسط پژوهشهای پیشین مقایسه کنیم. پس به کمک پیادهسازیهای موجود از این پژوهشها، عملکرد آنها را روی مجموعههای دادهی ایجاد شده محاسبه خواهیم کرد. | |||||
| \subsection{آوتبرین} | |||||
| همانطور که گفته شد، در سال 2016 شرکت آوتبرین با برگزاری یک چالش در سایت \trans{کگل}{kaggle.com}، مجموعهدادهی خود را منتشر کرد. در این مجموعه داده، هر بار که کاربری به صفحهی سایت یک ناشر مراجعه کرده است، 2 الی 12 بنر تبلیغاتی به وی نمایش داده شده، که کاربر روی یکی از آنها کلیک کرده است. میانگین تعداد تبلیغ در این مجموعهی داده، 5.16 تبلیغ در هر مراجعه است. | |||||
| یکی از ویژگیهای مجموعهدادهی آوتبرین، وجود اطلاعات جانبی متنوع در مورد صفحاتی است که تبلیغات در آنها به نمایش گذاشته شدهاند. این صفحات طبق یک طبقهبندی موضوعی، به 97 دسته تقسیم شدهاند. اطلاعاتی نیز در مورد ذکر شدن نام برخی موجودیتها در هر صفحه و میزان اطمینان در مورد آن فراهم شده است. اطلاعات متنوعی نیز از نویسنده، ناشر و زمان انتشار هر صفحه وجود دارد. همچنین اطلاعات مربوط به تبلیغ کننده و کمپین تبلیغاتی برای هر تبلیغ نیز موجود است. | |||||
| در این مجموعه داده، اطلاعات حجیمی نیز در مورد مشاهدهی صفحات مختلف توسط کاربران ارائه شده است. این اطلاعات شامل زمان دقیق مراجعه، پلتفرم (کامپیوتر، موبایل یا تبلت)، محل جغرافیایی و منبع ترافیک (مستقیم، جستجو یا شبکههای اجتماعی) هر بازدید هستند. این اطلاعات به دلیل حجم بالا و تعداد زیاد (نزدیک به 2 میلیارد) بازدید از صفحات مختلف وب بسیار حجیم هستند. این مجموعهداده، شامل اطلاعات جمع آوری شده در طول دو هفته (14 روز) از بازدیدها، نمایش تبلیغها و کلیکها در تعدادی سایت پر بازدید است. | |||||
| در این مجموعهداده، همهی اطلاعات به صورت \trans{ناشناس شده}{Anonimized} ارائه شده و حتی نام سایتها، نوع دستههای موضوعی صفحات نیز ذکر نشده و اطلاعات آن به صورت شناسهی گمنام در اختیار محققین قرار گرفته است. تنها ویژگی غیر ناشناس در این مجموعهی داده، موقعیت جغرافیایی کاربران است که البته برای حفظ حریم خصوصی کاربران، به سطح کشور یا استان / ایالت محدود شده است. | |||||
| \subsubsection{آوتبرین پیشپردازش شده} | |||||
| همانطور که گفته شد، تعداد بسیار زیاد ویژگیها و دادهها، باعث بروز محدودیتهای سختافزاری متعددی در انجام آزمایش روی این مجموعهی داده میشود؛ به همین دلیل در این پژوهش با حذف تعداد زیادی از این ویژگیها، نسخهی سبکتری از این مجموعهی داده استخراج کرده و از آن به عنوان یک مجموعهدادهی کوچک برای انجام مقایسهها بهره میجوییم. | |||||
| در اولین قدم، تعداد دادههای موجود در این مجموعهی داده را به کمک روشهای نمونه برداری، به 87 میلیون کاهش میدهیم؛ سپس ویژگیهایی از این مجموعهی داده که دستهای نیستند را حذف میکنیم. همچنین، تعدادی از ویژگیهای دستهای که تعداد دستههای بسیار زیادی دارند را از این مجموعهی داده حذف مینماییم. تعداد ویژگیهای دستهای باقی مانده در این مجموعهی داده 12 بوده و این ویژگیها شامل موارد: شناسهی کمپین تبلیغاتی، شناسهی تبلیغ کننده، پلتفرم، موقعیت جغرافیایی، شناسهی صفحه، شناسهی ناشر، شناسهی موضوع صفحه، شناسهی دستهی صفحه، شناسهی صفحهی منبع، شناسهی ناشر صفحهی منبع، شناسهی موضوع صفحهی منبع و شناسهی دستهی صفحهی منبع هستند. | |||||
| مجموع تعداد ویژگیهای باینری استخراج شده از این مجموعهی داده 53727 است. لازم به ذکر است سبک بودن این مجموعه داده، به دلیل تعداد کم دادهها نیست؛ بلکه این مجموعهی داده به این دلیل سبک خوانده میشود که تعداد ویژگیهای آن بسیار کمتر از سایر مجموعههای داده است. | |||||
| حدود 19 درصد از دادههای این مجموعه در دستهی کلیک شده و بقیهی دادهها در دستهی کلیک نشده طبقه بندی شدهاند. | |||||
| \subsection{کرایتیو} | |||||
| یکی از شرکتهای فعال در حوزهی تبلیغات نمایشی آنلاین، \trans{کرایتیو}{Criteo} است. این شرکت با استفاده از مزایدههای بلادرنگ تبلیغات مشتریان خود (سکوی نیاز) را بین مشتریان دیگر خود (سکوی تامین) توزیع میکند. در سال 2014 این شرکت اطلاعات مربوط به 7 روز از ترافیک خود را در قالب یک چالش در سایت کگل منتشر کرد. | |||||
| این مجموعهداده، از 13 ویژگی (ناشناس) عددی، که طبق اعلام خود شرکت اکثر این ویژگیها از نوع تعداد هستند؛ و 26 ویژگی ناشناس دستهای، که به صورت \trans{درهمسازی شده}{Hashed} ارائه شده اند، تشکیل شده است. این مجموعهداده، شامل تعدادی \trans{مقادیر گم شده}{Missing values} بوده و مانند مجموعهدادهی آوتبرین، اطلاعات آن به صورت ناشناس ارائه شدهاند. | |||||
| این مجموعهی داده شامل بیش از 45 میلیون رکورد بوده که کاربران در 26 درصد از این نمونهها روی بنر تبلیغاتی کلیک کردهاند. با وجود کمتر بودن تعداد دادهها در این مجموعهی داده و شدت کمتر عدم توازن بین کلاسها، تعداد ویژگیهای زیاد و همچنین تنک بودن بسیاری از این ویژگیها باعث میشوند این مجموعهی داده یک چالش واقعی برای روشهای پیشبینی نرخ کلیک به شمار رود. | |||||
| مجموع تعداد ویژگیهای باینری استخراج شده از بخش دستهای این مجموعهی داده، به بیش از 33 میلیون میرسد؛ بنابراین استفاده از همهی این ویژگیها محدودیتهای سختافزاری زیادی را به وجود میآورد. به همین دلیل، مجموعههای دادهی کرایتیو-22، کرایتیو-21 و کرایتیو-20 را از این مجموعهی داده استخراج کرده و تمامی آزمایشهای مربوطه را با این سه مجموعهی داده انجام میدهیم. | |||||
| \subsubsection{کرایتیو-22} | |||||
| با حذف 4 ویژگی دستهای که بیشترین کاردینالیتی را دارند، از مجموعه دادهی کرایتیو و همچنین حذف همهی ویژگیهای عددی که با ساختار روش پیشنهادی و اکثر روشهای پیشین سازگار نیستند، به مجموعهی دادهی کرایتیو-22 میرسیم. مجموع تعداد ویژگیهای باینری استخراج شده از این مجموعهی داده، تا حدود 2.7 میلیون کاهش مییابد. | |||||
| \subsubsection{کرایتیو-21} | |||||
| مثل مجموعه دادهی کرایتیو-22، مجموعه دادهی کرایتیو-21 هم از مجموعه دادهی کرایتیو ساخته میشود. در مجموعه دادهی کرایتیو-21، 5 ویژگی دارای کاردینالیتی بیشتر را حذف کرده و مجموع تعداد ویژگیهای باینری را به حدود 570 هزار میرسانیم. | |||||
| \subsubsection{کرایتیو-20} | |||||
| همانطور که انتظار میرود، مجموعه دادهی کرایتیو-20، دارای تنها 20 ویژگی دستهای بوده و مجموع تعداد ویژگیهای باینری در آن حدود 280 هزار است. | |||||
| لازم به تذکر است که تعداد دادهها و درصد کلی کلیک در هر سه مجموعه دادهی ساخته شده یکسان و برابر با مجموعه دادهی کرایتیو است. | |||||
| \section{معیارهای ارزیابی} | |||||
| همانطور که در فصل اول گفته شد، مسالهی پیشبینی نرخ کلیک به دلیل ویژگیهای متعدد، از جمله عدم توازن کلاسها، پر تعداد اما تنک بودن ویژگیها و برخی مشکلات دیگر، مسالهای خاص است؛ لذا برای ارزیابی راهحلهایی که برای این مساله پیشنهاد میشوند، به معیارهای ارزیابی به خصوصی نیاز داریم. در این بخش به معرفی معیارهای ارزیابی مورد استفاده در این پژوهش میپردازیم و دلیل استفاده از برخی از این معیارها را بیان مینماییم. | |||||
| \subsection{خطای لگاریتمی} | |||||
| خطای لگاریتمی یا\trans{آنتروپی متقابل}{Cross Entropy}، یکی از مهمترین معیارهای استفادهشده در حوزهی پیشبینی نرخ کلیک است. در مدلهایی که خروجی آنها برابر احتمال کلیک است، مقدار این خطا، با \trans{قرینهی لگاریتم درستنمایی}{Negative Log Likelihood} این مدلها برابر است. در نتیجه با شهود و درک احتمالاتی از این مساله کاملا تطابق دارد. | |||||
| در صورتی که از این خطا استفاده کنیم، حتی اگر دادهای توسط مدل درست دستهبندی شود، باز هم امکان دارد به آن خطایی تخصیص دهیم. در صورتی خطای آنتروپی متقابل برابر صفر میشود که علاوه بر طبقهبندی درست همهی دادهها، به همهی آنها احتمال کاملا باینری اختصاص دهد؛در نتیجه مدل به سمتی پیش میرود که خطا در احتمال پیشبینیشده را کمتر و کمتر کند. | |||||
| خطای لگاریتمی به دلیل مشتق پذیر بودن، میتواند به عنوان تابع هزینهی مدلهایی که از گرادیان کاهشی استفاده میکنند، به کار گرفته شود. همانطور که در فصل قبل گفته شد، با وزندار کردن این تابع خطا، میتوانیم مدلها را نسبت به عدم توازن بین کلاسها مقاوم کنیم. | |||||
| \subsection{مساحت تحت منحنی} | |||||
| در ادبیات یادگیری ماشین، معیارهای \trans{نرخ مثبت درست}{TPR} و \trans{نرخ مثبت غلط}{FPR} کاربردهای بسیاری دارند. نرخ مثبت درست به نرخ عملکرد صحیح در کلاس مثبت و نرخ مثبت غلط به نرخ عملکرد اشتباه در کلاس منفی اشاره میکنند. این مقادیر طبق تعریف، همیشه بین صفر و یک هستند. در مدلهایی که برای دستهبندی دو کلاسه، از یک حد آستانه بهره میجویند، با تغییر دادن مقدار حد آستانه، میتوانند تعادلی بین نرخ مثبت درست و نرخ مثبت غلط بیابند. | |||||
| یک منحنی پر کاربرد در یادگیری ماشین، منحنی \trans{راک}{ROC} است. برای رسم این منحنی، ابتدا مدل را روی همهی دادههای تست اجرا کرده و مقادیر احتمال را برای همهی دادهها به دست میآوریم؛ سپس آنها را بر اساس احتمال کلیک صعودی، مرتب میکنیم. از نقطهی بالا و راست منحنی شروع کرده و هر بار، در صورتی که دادهی مربوطه جزو کلاس منفی باشد، یک گام به سمت چپ و در صورتی که مربوط به کلاس مثبت باشد، یک گام به سمت پایین حرکت میکنیم. اندازهی گامهای به سمت چپ، برابر معکوس تعداد دادههای منفی و اندازهی گامهای به سمت راست، برابر معکوس تعداد دادههای مثبت است؛ لذا پس از مشاهدهی همهی دادهها، باید به نقطهی چپ و پایین منحنی رسیده باشیم. هر قدر این منحنی به سمت بالا و چپ تمایل داشتهباشد، به این معنی است که مدل تحت حد آستانههای مختلف، عملکرد متوازن و قابل قبولی دارد. همچنین نرمال بودن نرخ مثبت درست و نرخ مثبت غلط باعث میشود هیچ مشکلی از جانب غیر متناسب بودن کلاسها عملکرد این معیار را تهدید نکند. در صورتی که مساحت تحت پوشش منحنی راک را محاسبه کنیم، میتوانیم از آن به عنوان یک معیار عددی کاملا مناسب برای نظارت بر مدلهای یادگیری ماشین استفاده کنیم. مساحت تحت منحنی راک یا \trans{مساحت تحت منحنی}{Area Under Curve} عددی نرمال بین صفر و یک بوده ولی مقادیر کمتر از نیم برای آن غیر معقول است. | |||||
| یکی از نکات مهم در مورد معیار مساحت تحت منحنی، تعبیر احتمالاتی آن است. این معیار نشان دهندهی احتمال تخصیص امتیاز (احتمال کلیک) بیشتر به یک نمونهی (تصادفی) از کلاس مثبت، نسبت به یک نمونهی (تصادفی) از کلاس منفی است. به عنوان مثال، اگر میزان مساحت تحت منحنی برای یک مدل، برابر 75 درصد باشد، اگر یک دادهی تصادفی از کلاس مثبت و یک دادهی تصادفی از کلاس منفی انتخاب کرده و امتیاز این مدل برای این دو داده را محاسبه کنیم، به احتمال 75 درصد، امتیاز تخصیص داده شده به دادهی کلاس مثبت، بیشتر از احتمال تخصیص داده شده به دادهی کلاس منفی خواهد بود. این خاصیت مهم، باعث میشود مدلی که مساحت تحت منحنی بیشتری دارد، برای اعمالی نظیر مرتب کردن اولویتدار، عملکرد بهتری داشته باشند. چون مسالهی پیشبینی نرخ کلیک، در تبلیغات نمایشی عملا برای مرتب کردن اولویتدار بنرهای تبلیغاتی، بر اساس احتمال کلیک کاربران بر روی آنها طراحی شده است، لذا مدلی که مساحت تحت منحنی قابل قبولی داشته باشد، برای استفادهی صنعتی دراین مساله گزینهی مناسبی خواهد بود. | |||||
| همهی دلایل ذکر شده، باعث میشوند در این پژوهش از این معیار به عنوان معیار اصلی ارزیابی مدل استفاده کنیم. | |||||
| % اما علاوه بر این معیار، از معیارهای \trans{دقت}{Precision}، \trans{بازیابی}{Recall} و \trans{امتیاز اف 1}{F1 Measure} که میانگین هارمونیک دقت و بازیابی است نیز برای تایید نتایج گزارش شده استفاده میکنیم. | |||||
| \section{روشهای تنظیم پارامترها} | |||||
| هر یک از روشهای ژرف که در فصل دوم معرفی کردیم و همچنین بسیاری از روشهای دیگر، به دلیل جلوگیری از بیشبرازش، از روشهای تنظیم پارامترها استفاده میکنند. در این بخش چند روش تنظیم پارامتر که در این پژوهش استفاده کردهایم را به طور مختصر معرفی کرده و با انجام آزمایشهایی، بهترین مقادیر ابرپارامترهای مربوط به آنها را انتخاب میکنیم. | |||||
| \subsection{تنظیم مرتبهی دوم} | |||||
| در تنظیم مرتبهی دوم، میزان خطای نهایی مدل را با ضریبی از مجموع توان دوم مقادیر پارامترهای مدل جمع میکنند. این عمل باعث میشود مدل به استفاده از پارامترهای کوچکتر ترغیب شود، که این امر به نوبهی خود باعث کاهش پیچیدگی مدل و همچنین کاهش خطر بیشبرازش میشود. تنظیم مرتبهی دوم را میتوان در قسمتهای مختلف مدل از قبیل پارامترهای تعبیه، پارامترهای شبکههای تعامل و همچنین پارامترهای شبکهی سر اعمال کرد. | |||||
| \subsubsection{تنظیم مرتبهی دوم روی پارامترهای تعبیه} | |||||
| با اعمال تنظیم مرتبهی دوم بر پارامترهای تعبیه، مدل را به استفاده از بردارهای تعبیهی کوچکتر ترغیب میکنیم. این عمل باعث سادهتر شدن فضاهای تعبیهی مدل شده و در نتیجه خطر بیشبرازش مدل را کاهش میدهد. | |||||
| در آزمایشی چندین مقدار مختلف برای ضریب تنظیم مرتبهی دوم روی پارامترهای تعبیه در نظر گرفته و مدل پیشنهادی را روی مجموعههای دادهی کرایتیو-20 و کرایتیو-22 آموزش دادیم. شکل \ref{fig:l2reg_on_emb} مقادیر مساحت تحت نمودار در این آزمایش را نشان میدهد. | |||||
| \begin{figure} | |||||
| \center | |||||
| \includegraphics[width=0.9\textwidth]{images/Embedding_L2Reg} | |||||
| \caption{ | |||||
| مساحت تحت نمودار، به ازای مقادیر مختلف ضریب تنظیم مرتبهی دوم برای پارامترهای تعبیهی مدل | |||||
| } | |||||
| \label{fig:l2reg_on_emb} | |||||
| \end{figure} | |||||
| همانطور که مشخص است، برای مجموعه دادهی کرایتیو-20، که تعداد ویژگی کمتری دارد، تنظیم مرتبهی دوم پارامترهای تعبیه کمکی به عملکرد مدل نمیکند؛ اما مقادیر بسیار اندک در ضریب تنظیم مرتبهی دوم روی پارامترهای تعبیه، باعث بهبود عملکرد مدل روی مجموعه دادهی کرایتیو-22 میشود. از این آزمایش این نتیجه را برداشت میکنیم که تنظیم مرتبهی دوم، در مجموعههای دادهی با تعداد ویژگی زیاد، میتواند خطر بیشبرازش را کاهش دهد. | |||||
| \subsubsection{تنظیم مرتبهی دوم روی پارامترهای شبکههای تعامل} | |||||
| شبکههای تعامل، بخش مهمی از پیچیدگی مدل پیشنهادی را ایجاد میکنند. با اعمال تنظیم مرتبهی دوم روی پارامترهای این شبکهها، مدل را به استخراج روابط ساده و موثر بین بردارهای تعبیه ترغیب کرده و انتظار داریم این کار خطر بیشبرازش مدل را کاهش دهد. | |||||
| در آزمایشی، چندین مقدار مختلف برای ضریب تنظیم مرتبهی دوم روی پارامترهای شبکههای تعامل در نظر گرفته و مدل پیشنهادی را روی مجموعههای دادهی کرایتیو-20 و کرایتیو-22 آموزش میدهیم. شکل \ref{fig:l2reg_on_int} مقادیر مساحت تحت نمودار در این آزمایش را نشان میدهد. | |||||
| \begin{figure} | |||||
| \center | |||||
| \includegraphics[width=0.9\textwidth]{images/InteractionNet_L2Reg} | |||||
| \caption{ | |||||
| مساحت تحت نمودار، به ازای مقادیر مختلف ضریب تنظیم مرتبهی دوم برای پارامترهای شبکههای تعامل | |||||
| } | |||||
| \label{fig:l2reg_on_int} | |||||
| \end{figure} | |||||
| همانطور که مشخص است، برای مجموعه دادهی کرایتیو-20، که تعداد ویژگی کمتری دارد، تنظیم مرتبهی دوم پارامترهای شبکههای تعامل، عملکرد مدل را تضعیف میکند؛ اما مقادیر متوسط ضریب تنظیم مرتبهی دوم روی پارامترهای شبکههای تعامل، باعث بهبود عملکرد مدل روی مجموعه دادهی کرایتیو-22 میشود. از این آزمایش نیز برداشت میکنیم که تنظیم مرتبهی دوم، در مجموعههای دادهی با تعداد ویژگی زیاد، موثر بوده و خطر بیشبرازش را کاهش میدهد. | |||||
| \subsubsection{تنظیم مرتبهی دوم روی پارامترهای شبکهی سر} | |||||
| شبکهی سر، نقش مهم استخراج ویژگیهای سطح بالا از روی بردارهای تعبیه و همچنین بردارهای تعامل مدل را دارد؛ بنابراین با انجام عمل تنظیم مرتبهی دوم روی پارامترهای آن، سعی در کاهش خطر بیشبرازش مدل مینماییم. | |||||
| در آزمایشی، چندین مقدار مختلف برای ضریب تنظیم مرتبهی دوم روی پارامترهای شبکهی سر در نظر گرفته و مدل پیشنهادی را روی مجموعههای دادهی کرایتیو-20 و کرایتیو-22 آموزش میدهیم. شکل \ref{fig:l2reg_on_head} مقادیر مساحت تحت نمودار در این آزمایش را نشان میدهد. | |||||
| \begin{figure} | |||||
| \center | |||||
| \includegraphics[width=0.9\textwidth]{images/HeadNet_L2Reg} | |||||
| \caption{ | |||||
| مساحت تحت نمودار، به ازای مقادیر مختلف ضریب تنظیم مرتبهی دوم برای پارامترهای شبکهی سر | |||||
| } | |||||
| \label{fig:l2reg_on_head} | |||||
| \end{figure} | |||||
| همانطور که مشخص است و بر خلاف تصور اولیه، اعمال تنظیم مرتبهی دوم روی پارامترهای شبکهی سر، بر بهبود عملکرد مدل در هیچ یک از مجموعههای دادهی کرایتیو-20 و کرایتیو-22 کمک نمیکند. این نتیجه میتواند به این دلیل رخ دهد که شبکهی سر برای مدلسازی مناسب، نیاز به پیچیدگی زیادی داشته و در نتیجه با اعمال ضرایب تنظیم، دچار افت عملکرد میشود. | |||||
| \subsection{حذف تصادفی} | |||||
| در شبکههای عصبی ژرف، برای جلوگیری از خطر بیشبرازش و همچنین ترغیب مدلها به یادگیری چندگانه و قابل اطمینان، از تکنیک حذف تصادفی استفاده میکنند. در حذف تصادفی، مقادیر خروجی برخی از نورونهای شبکه را در زمان آموزش با صفر جایگزین کرده و در نتیجه میزانی از پیچیدگی مدل را کاهش میدهیم. این امر باعث میشود شبکه برای حفظ عملکرد خود، همهی ویژگیهای نهانی که در تصمیمگیری مدل موثر هستند را به صورت چندگانه فرا بگیرد. یادگیری چندگانه به این معنی است که به جای یک نورون، چندین نورون مسئول تشخیص هر ویژگی نهان شده و در نتیجه با حضور یا عدم حضور تنها یکی از ویژگیها، رفتار مدل تفاوت چندانی نمیکند. واضح است که این تغییر باعث کاهش واریانس مدل و در نتیجه کاهش خطر بیشبرازش در مدل میشود. | |||||
| تکنیک حذف تصادفی را میتوان در قسمتهای مختلف مدل از جمله بردارهای تعبیه، شبکههای تعامل و همچنین شبکهی سر اعمال کرده و انتظار میرود مانند تنظیم مرتبهی دوم، باعث بهبود عملکرد مدل در مجموعههای دادهی حجیم شود. | |||||
| \subsubsection{حذف تصادفی پارامترهای تعبیه} | |||||
| با اعمال تکنیک حذف تصادفی روی پارامترهای تعبیه، باعث کاهش پیچیدگی مدل در این بخش شده و لذا مدل را وادار به یادگیری ساختار سادهتر و کاراتر در پارامترهای تعبیه میکنیم. | |||||
| در آزمایشی، با اعمال این تکنیک روی پارامترهای تعبیه، میزان تاثیر آن را بر عملکرد مدل روی مجموعههای دادهی کرایتیو-20 و کرایتیو-22 اندازهگیری میکنیم. شکل \ref{fig:dropout_on_emb} مساحت تحت نمودار مدل را در این آزمایش نشان میدهد. | |||||
| \begin{figure} | |||||
| \center | |||||
| \includegraphics[width=0.9\textwidth]{images/Embedding_dropout} | |||||
| \caption{ | |||||
| مساحت تحت نمودار، به ازای مقادیر مختلف نرخ حذف تصادفی در پارامترهای تعبیهی مدل | |||||
| } | |||||
| \label{fig:dropout_on_emb} | |||||
| \end{figure} | |||||
| همانطور که انتظار میرفت، مقادیر کم نرخ حذف تصادفی باعث بهبود جزئی عملکرد مدل در مجموعه دادهی کرایتیو-22 میشوند؛ اما باز هم در مجموعه دادهی کرایتیو-20، کوچک بودن مدل باعث میشود اعمال تکنیک حذف تصادفی، تاثیر مثبتی بر عملکرد مدل نداشته باشد. | |||||
| \subsubsection{حذف تصادفی پارامترهای شبکههای تعامل} | |||||
| شبکههای تعامل به دلیل این که از بردارهای تعبیه استفاده میکنند و برخی از بردارهای تعبیه به دلیل چالش شروع سرد، مقادیر مناسبی ندارند، میتوانند باعث بروز مشکل بیشبرازش شوند. با اعمال تکنیک حذف تصادفی روی پارامترهای شبکههای تعامل، خطر بیشبرازش مدل را در این بخشها کاهش میدهیم. | |||||
| در آزمایشی، با اعمال این تکنیک روی پارامترهای شبکههای تعامل، میزان تاثیر آن را بر عملکرد مدل روی مجموعههای دادهی کرایتیو-20 و کرایتیو-22 اندازهگیری میکنیم. شکل \ref{fig:dropout_on_int} مساحت تحت نمودار مدل را در این آزمایش نشان میدهد. | |||||
| \begin{figure} | |||||
| \center | |||||
| \includegraphics[width=0.9\textwidth]{images/InteractionNet_dropout} | |||||
| \caption{ | |||||
| مساحت تحت نمودار، به ازای مقادیر مختلف نرخ حذف تصادفی در پارامترهای شبکههای تعامل | |||||
| } | |||||
| \label{fig:dropout_on_int} | |||||
| \end{figure} | |||||
| در مجموعه دادهی کرایتیو-20 به دلیل سادگی مدل، حذف تصادفی پارامترهای شبکههای تعامل کمکی به بهبود عملکرد مدل نمیکند؛ اما در مجموعه دادهی کرایتیو-22، که ابعاد مدل نیز درخور تعداد ویژگیهای مجموعهی داده رشد کرده است، مقادیر متوسط نرخ حذف تصادفی، باعث بهبود عملکرد مدل میشوند. همچنین میتوانیم رفتار تصادفی تکنیک حذف تصادفی را عامل اصلی ناهموار بودن نتایج در آزمایش فوق در نظر بگیریم. | |||||
| \subsubsection{حذف تصادفی پارامترهای شبکهی سر} | |||||
| تکنیک حذف تصادفی، در مدلهای ژرف کاربرد بیشتری از مدلهای غیر ژرف دارد؛ در نتیجه انتظار میرود تاثیر اعمال این تکنیک در بخشهای ژرف مدل، احساس شود. | |||||
| در آزمایشی، با اعمال تکنیک حذف تصادفی روی پارامترهای شبکهی سر، میزان تاثیر آن را بر عملکرد مدل روی مجموعه دادههای کرایتیو-20 و کرایتیو-22 اندازهگیری میکنیم. شکل \ref{fig:dropout_on_head} مساحت تحت نمودار مدل را در این آزمایش نشان میدهد. | |||||
| \begin{figure} | |||||
| \center | |||||
| \includegraphics[width=0.9\textwidth]{images/HeadNet_dropout} | |||||
| \caption{ | |||||
| مساحت تحت نمودار، به ازای مقادیر مختلف نرخ حذف تصادفی در پارامترهای شبکهی سر | |||||
| } | |||||
| \label{fig:dropout_on_head} | |||||
| \end{figure} | |||||
| همانطور که از نتایج این آزمایش مشخص است، مقادیر اندک نرخ حذف تصادفی باعث بهبود عملکرد مدل بر مجموعه دادهی کرایتیو-22 میشود؛ اما مثل آزمایشهای قبل، مجموعه دادهی کرایتیو-20 به دلیل سادگی بیش از حد مدل، نیازی به اعمال روشهای تنظیم احساس نشده و با افزایش نرخ حذف تصادفی، عملکرد مدل پیوسته کاهش مییابد. | |||||
| \section{سایر آزمایشها} | |||||
| در بخش قبل با انجام چندین آزمایش، بهترین مقادیر برای \trans{ابرپارامتر}{Hyper-Parameter}های مربوط به تنظیم را یافته و تاثیر اعمال هرکدام از روشهای تنظیم را بر مدل بررسی کردیم. در این بخش، با طراحی و انجام چند آزمایش دیگر، سایر ابرپارامترهای مدل را بررسی کرده و مقادیر مناسب را برای آنها خواهیم یافت. | |||||
| \subsection{تعداد لایههای شبکههای تعامل و بعد بردارهای تعامل} | |||||
| برای تعیین تعداد لایهها در شبکههای تعامل و همچنین بعد بردارهای تعامل، که تنها ابرپارامترهای موجود در ساختار شبکههای تعامل هستند، آزمایشی روی مجموعه دادهی آوتبرین پیشپردازش شده طراحی و اجرا میکنیم. در این آزمایش، تعداد لایههای شبکههای تعامل را از یک تا چهار تغییر داده و برای هر حالت، بعد بردارهای تعامل را از یک تا چهار تغییر میدهیم. نتایج این آزمایش را در شکل \ref{fig:InteractionNet_experiment} مشاهده میکنید. | |||||
| \begin{figure} | |||||
| \center | |||||
| \includegraphics[width=0.9\textwidth]{images/InteractionNet_Layers_Interaction_Dim} | |||||
| \caption{ | |||||
| مساحت تحت نمودار، به ازای تعداد لایههای مختلف شبکههای تعامل و همچنین مقادیر مختلف بعد بردارهای تعامل | |||||
| } | |||||
| \label{fig:InteractionNet_experiment} | |||||
| \end{figure} | |||||
| همانطور که از نتایج این آزمایش مشخص است، زمانی که بعد بردارهای تعبیه از 1 بیشتر باشند، عملکرد مدل بهبود مییابد. پس میتوانیم از این نتیجه، برداشت کنیم افزایش ابعاد بردارهای تعبیه، ایدهی موثری برای بهبود عملکرد مدل است. همچنین قابل ملاحظه است که تعداد لایههای شبکههای تعامل، رابطهی واضحی با عملکرد مدل در این مجموعهی داده ندارد. | |||||
| \subsection{تعداد لایهها و نورونهای شبکهی سر} | |||||
| شبکهی سر، همانطور که در بخشهای قبل گفته شد، نقش تصمیمگیری نهایی مدل را بر عهده دارد. تنظیم دقیق تعداد لایهها و نورونهای این شبکه، میتواند میزان پیچیدگی مدل و توان مدلسازی آن را تحت تاثیر قرار دهد؛ پس با طراحی آزمایشی، میزان تاثیر تعداد لایهها و همچنین تعداد نورونهای هر لایه از این شبکه را بین مقادیر مختلف تغییر داده و عملکرد مدل را روی مجموعه دادهی کرایتیو-22 با مساحت تحت منحنی میسنجیم. نتایج این آزمایش در شکل \ref{fig:HeadNet_experiment1} قابل مشاهده است. | |||||
| همچنین این آزمایش را روی مجموعه دادهی آوتبرین هم تکرار کرده و به دلیل سرعت بالای اجرا بر روی این مجموعه داده، مقادیر متنوعتری را از این ابرپارامترها میآزماییم. در شکل \ref{fig:HeadNet_experiment2} مساحت تحت منحنی را برای مدل در این آزمایش گزارش کردهایم. | |||||
| همانطور که از نتایج آزمایشهای فوق مشخص است، تاثیر تعداد لایههای شبکهی سر، تنها در یکی از مجموعههای داده و آنهم به صورت محدود مشاهده میشود؛ اما با افزایش تعداد نورونهای هر لایه از شبکهی سر، عملکرد مدل به صورت مداوم بهبود مییابد. میتوانیم از این نتایج این نکته را برداشت کنیم که به دلیل استخراج ویژگیهای مرتبه اول (بردارهای تعبیه) و دوم (بردارهای تعامل) مناسب، مدل به عمق زیادی برای پیشبینی نرخ کلیک نیاز ندارد؛ اما با افزایش تعداد نورونهای هر لایه از شبکهی سر، مدل میتواند جزئیات بیشتری از این ویژگیها استخراج کرده و مرز تصمیمگیری را دقیقتر ترسیم کند. | |||||
| \begin{figure} | |||||
| \center | |||||
| \includegraphics[width=0.9\textwidth]{images/HeadNet_Experiment1} | |||||
| \caption{ | |||||
| مساحت تحت نمودار، به ازای تعداد لایههای مختلف شبکههای تعامل و همچنین مقادیر مختلف بعد بردارهای تعامل روی مجموعه دادهی کرایتیو-22 | |||||
| } | |||||
| \label{fig:HeadNet_experiment1} | |||||
| \end{figure} | |||||
| \begin{figure} | |||||
| \center | |||||
| \includegraphics[width=0.9\textwidth]{images/HeadNet_Experiment2} | |||||
| \caption{ | |||||
| مساحت تحت نمودار، به ازای تعداد لایههای مختلف شبکههای تعامل و همچنین مقادیر مختلف بعد بردارهای تعامل روی مجموعه دادهی آوتبرین | |||||
| } | |||||
| \label{fig:HeadNet_experiment2} | |||||
| \end{figure} | |||||
| \subsection{بررسی فضای تعبیه} | |||||
| یکی از پرسشهای مهمی که ممکن است در مورد نتایج این پژوهش به وجود بیاید، تاثیر استفاده از تکنیکهای مختلف روی کیفیت فضای بردارهای تعبیه است. \textbf{آیا متغیر در نظر گرفتن ابعاد بردارهای تعبیه و همچنین تخصیص چندین مسیر مختلف برای انتقال گرادیان به متغیرهای تعبیهی مدل، باعث شکلگیری یک فضای تعبیهی مفید میشود؟} | |||||
| برای پاسخ به این پرسش، به تنها فیلد درهمسازی نشدهی مجموعه دادهی آوتبرین که موقعیت جغرافیایی است، رجوع میکنیم. این فیلد نشان دهندهی کشور، استان یا ایالتی است که آدرس آیپی کاربر به آن ناحیه تعلق دارد. میتوانیم فرض کنیم استانها و ایالتهای مختلف یک کشور، به دلیل شباهت فرهنگی و زبانی، تاثیر مشابهی در برخورد کاربران با تبلیغات آنلاین داشته باشند؛ در نتیجه انتظار داریم استانها یا ایالتهای مختلف یک کشور، در فضای تعبیهی این فیلد، نزدیک به هم باشند. | |||||
| چون فضای تعبیهی این فیلد بیش از دو بعد دارد، نمیتوانیم بردارهای تعبیه را به صورت خام نمایش دهیم؛ پس از یک روش کاهش ابعاد\cite{t-sne} به نام $T-SNE$ استفاده میکنیم و این بردارها را به فضای دو بعدی منتقل میکنیم. الگوریتم $T-SNE$ به نحوی کار میکند که فاصلهی نقاط در فضای خروجی، مانند همین فواصل در فضای ورودی بوده و عملا نقاط نزدیک به هم، پس از کاهش ابعاد باز هم نزدیک به هم قرار گرفته و نقاط دور از هم، پس از کاهش ابعاد همچنان دور از یکدیگر باشند. | |||||
| در شکل \ref{fig:GeoLocEmb} نتایج این آزمایش را مشاهده مینمایید. قابل توجه است این شکل پس از کاهش ابعاد این فضا توسط الگوریتم $T-SNE$ به دو بعد رسم شده است. | |||||
| \begin{figure} | |||||
| \center | |||||
| \includegraphics[width=0.9\textwidth]{images/GeoLoc} | |||||
| \caption{ | |||||
| نمایی از فضای تعبیهی استخراج شده از فیلد موقعیت جغرافیایی در مجموعهی دادهی آوتبرین توسط روش پیشنهادی | |||||
| } | |||||
| \label{fig:GeoLocEmb} | |||||
| \end{figure} | |||||
| برای سادگی مشاهدهی نتایج، استانها و ایالتهای مختلف هر کشور را به یک رنگ خاص نمایش دادهایم. همان طور که انتظار داشتیم، نقاط هم رنگ نزدیک به هم و به صورت خوشههای با اندازههای متغیر قرار گرفتهاند. این آزمایش به ما نشان میدهد همانطور که انتظار داشتیم، اقدامات انجام شده به منظور بهبود کیفیت فضای تعبیه، موثر بوده و مدل پیشنهادی، در ایجاد و استفاده از فضاهای تعبیهی مفید، موفق شده است. | |||||
| \subsection{مقایسه با روشهای پیشین} | |||||
| پس از تنظیم مقادیر ابرپارامترها و اطمینان از عملکرد مدل پیشنهادی، نوبت به مقایسهی آن با برخی از روشهای پیشین میرسد. به دلیل محدودیتهای سختافزاری، این مقایسه را به ماشینهای فاکتورگیری ساده و همچنین ماشینهای فاکتورگیری ژرف محدود میکنیم. قابل ذکر است ماشینهای فاکتورگیری ساده، نمایندهی روشهای غیر ژرف و ماشینهای فاکتورگیری ژرف، نمایندهی روشهای ژرف در این مقایسه هستند. | |||||
| \subsubsection{مجموعه دادهی آوتبرین} | |||||
| در جدول \ref{tbl:outbrain_results} نتایج مقایسهی مدل پیشنهادی با روشهای پیشین را در مجموعهی دادهی آوتبرین مشاهده میکنید. | |||||
| \begin{table}[!ht] | |||||
| \caption{مقایسهی نهایی عملکرد روی مجموعهی آوتبرین} | |||||
| \label{tbl:outbrain_results} | |||||
| %\begin{latin} | |||||
| \scriptsize | |||||
| \begin{center} | |||||
| \begin{tabular}{|c|c|} \hline | |||||
| {نام و جزئیات مدل} & | |||||
| {مساحت تحت منحنی (درصد)} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}\textbf{ماشین فاکتورگیری ساده}\\ بعد بردارهای تعبیه = 9\end{tabular}} & | |||||
| {\textbf{$74.22$}} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ژرف\\ بعد بردارهای تعبیه = 10\\ تعداد لایهها = 3\\ تعداد نورونهای هر لایه = 20\end{tabular}} & | |||||
| {$72.27$} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ژرف\\ بعد بردارهای تعبیه = 10\\ تعداد لایهها = 3\\ تعداد نورونهای هر لایه = 100\end{tabular}} & | |||||
| {$73.00$} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ژرف\\ بعد بردارهای تعبیه = 10\\ تعداد لایهها = 3\\ تعداد نورونهای هر لایه = 400\end{tabular}} & | |||||
| {$73.44$} \\ \hline | |||||
| {\textbf{روش پیشنهادی}} & | |||||
| {\textbf{$74.13$}} \\ \hline | |||||
| \end{tabular} | |||||
| \end{center} | |||||
| \end{table} | |||||
| همان طور که از نتایج قابل مشاهده است، مدل پیشنهادی و ماشین فاکتورگیری ساده، عملکردی مناسب و نزدیک به هم ارائه کردهاند. این نکته قابل توجه است که ماشین فاکتورگیری ژرف، در مجموعه دادهی آوتبرین عملکرد مناسبی ندارد. این در حالی است که روش ژرف پیشنهادی، حتی با وجود تعداد بسیار کم ویژگیهای این مجموعه داده، میتواند عملکردی بسیار نزدیک به ماشین فاکتورگیری ساده (مدل غیر ژرف) ارائه کند. این نتیجه نشان میدهد روشهای تنظیم استفاده شده، عملکرد قابل قبولی داشته و جلوی بیشبرازش مدل پیشنهادی را گرفتهاند. | |||||
| \subsubsection{مجموعه دادهی کرایتیو-22} | |||||
| در جدول \ref{tbl:criteo22_results} نتایج مقایسهی روش پیشنهادی و ماشین فاکتورگیری ساده را، در مجموعه دادهی کرایتیو-22 مشاهده میکنید. لازم به ذکر است اجرای مدل ماشین فاکتورگیری ژرف در این مجموعه داده، به دلیل تعداد پارامترهای بسیار بالا قابل انجام نبوده و به ناچار، مقایسه در این مجموعه داده را تنها بین روش پیشنهادی و روش ماشین فاکتورگیری ساده انجام میدهیم. | |||||
| \begin{table}[!ht] | |||||
| \caption{مقایسهی نهایی عملکرد روی مجموعهی کرایتیو-22} | |||||
| \label{tbl:criteo22_results} | |||||
| %\begin{latin} | |||||
| \scriptsize | |||||
| \begin{center} | |||||
| \begin{tabular}{|c|c|c|c|c|} \hline | |||||
| {نام و جزئیات مدل} & | |||||
| {مساحت تحت منحنی (درصد)} & | |||||
| {دقت (درصد)} & | |||||
| {بازیابی (درصد)} & | |||||
| {اف 1 (درصد)} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ساده\\ بعد بردارهای تعبیه = 5\end{tabular}} & | |||||
| {\textbf{$75.41$}} & | |||||
| {$56.55$} & | |||||
| {$34.58$} & | |||||
| {$42.92$} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ساده\\ بعد بردارهای تعبیه = 10\\ \end{tabular}} & | |||||
| {$74.75$} & | |||||
| {$54.89$} & | |||||
| {$35.42$} & | |||||
| {$43.06$} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ساده\\ بعد بردارهای تعبیه = 40\\ \end{tabular}} & | |||||
| {$72.38$} & | |||||
| {$50.12$} & | |||||
| {$37.20$} & | |||||
| {$42.70$} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ساده\\ بعد بردارهای تعبیه = 100\\ \end{tabular}} & | |||||
| {$70.30$} & | |||||
| {$46.92$} & | |||||
| {$38.32$} & | |||||
| {$42.19$} \\ \hline | |||||
| {\textbf{روش پیشنهادی}} & | |||||
| {$76.08$} & | |||||
| {$43.07$} & | |||||
| {$70.39$} & | |||||
| {$53.44$} \\ \hline | |||||
| \end{tabular} | |||||
| \end{center} | |||||
| \end{table} | |||||
| نتایج این آزمایش نشان میدهد ماشین فاکتورگیری ساده، با افزایش بعد تعبیه، دچار مشکل بیشبرازش شده و عملکرد آن افت میکند. همچنین واضح است که روش پیشنهادی عملکرد بهتری را ارائه میکند. | |||||
| \subsubsection{مجموعه دادهی کرایتیو-21} | |||||
| در جدول \ref{tbl:criteo21_results} عملکرد روش پیشنهادی را با روشهای ماشین فاکتورگیری ساده و ماشین فاکتورگیری ژرف مقایسه میکنیم. | |||||
| \begin{table}[!ht] | |||||
| \caption{مقایسهی نهایی عملکرد روی مجموعهی کرایتیو-21} | |||||
| \label{tbl:criteo21_results} | |||||
| %\begin{latin} | |||||
| \scriptsize | |||||
| \begin{center} | |||||
| \begin{tabular}{|c|c|c|c|c|} \hline | |||||
| {نام و جزئیات مدل} & | |||||
| {مساحت تحت منحنی (درصد)} & | |||||
| {دقت (درصد)} & | |||||
| {بازیابی (درصد)} & | |||||
| {اف 1 (درصد)} | |||||
| \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ساده\\ بعد بردارهای تعبیه = 5\end{tabular}} & | |||||
| {\textbf{$75.83$}} & | |||||
| {$58.77$} & | |||||
| {$31.73$} & | |||||
| {$41.21$} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ساده\\ بعد بردارهای تعبیه = 10\\ \end{tabular}} & | |||||
| {$75.49$} & | |||||
| {$57.75$} & | |||||
| {$32.49$} & | |||||
| {$41.59$} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ساده\\ بعد بردارهای تعبیه = 40\\ \end{tabular}} & | |||||
| {$73.68$} & | |||||
| {$53.60$} & | |||||
| {$34.40$} & | |||||
| {$41.91$} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ساده\\ بعد بردارهای تعبیه = 100\\ \end{tabular}} & | |||||
| {$71.71$} & | |||||
| {$50.14$} & | |||||
| {$35.08$} & | |||||
| {$41.28$} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ژرف\\ بعد بردارهای تعبیه = 10\\ تعداد لایهها = 3\\ تعداد نورونهای هر لایه = 20\end{tabular}} & | |||||
| {$74.85$} & | |||||
| {$32.71$} & | |||||
| {$91.81$} & | |||||
| {$48.23$} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ژرف\\ بعد بردارهای تعبیه = 10\\ تعداد لایهها = 3\\ تعداد نورونهای هر لایه = 100\end{tabular}} & | |||||
| {$76.01$} & | |||||
| {$38.16$} & | |||||
| {$82.51$} & | |||||
| {$52.18$} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ژرف\\ بعد بردارهای تعبیه = 10\\ تعداد لایهها = 3\\ تعداد نورونهای هر لایه = 400\end{tabular}} & | |||||
| {$76.24$} & | |||||
| {$42.21$} & | |||||
| {$73.34$} & | |||||
| {$53.58$} \\ \hline | |||||
| {\textbf{روش پیشنهادی}} & | |||||
| {\textbf{$76.70$}} & | |||||
| {$43.70$} & | |||||
| {$69.94$} & | |||||
| {$53.79$} \\ \hline | |||||
| \end{tabular} | |||||
| \end{center} | |||||
| \end{table} | |||||
| همانطور که از نتایج مشخص است، روش پیشنهادی در این مجموعه داده، عملکرد بهتری نسبت به ماشینهای فاکتورگیری ساده و ماشینهای فاکتورگیری ژرف به نمایش گذاشته است. | |||||
| \subsubsection{مجموعه دادهی کرایتیو-20} | |||||
| در جدول \ref{tbl:criteo20_results} عملکرد نهایی روش پیشنهادی را با روشهای ماشین فاکتورگیری ساده و ماشین فاکتورگیری ژرف بر روی مجموعه دادهی کرایتیو-20 مقایسه میکنیم. | |||||
| \begin{table}[!ht] | |||||
| \caption{مقایسهی نهایی عملکرد روی مجموعهی کرایتیو-20} | |||||
| \label{tbl:criteo20_results} | |||||
| %\begin{latin} | |||||
| \scriptsize | |||||
| \begin{center} | |||||
| \begin{tabular}{|c|c|c|c|c|} \hline | |||||
| {نام و جزئیات مدل} & | |||||
| {مساحت تحت منحنی (درصد)} & | |||||
| {دقت (درصد)} & | |||||
| {بازیابی (درصد)} & | |||||
| {اف 1 (درصد)} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ساده\\ بعد بردارهای تعبیه = 5\end{tabular}} & | |||||
| {\textbf{$75.57$}} & | |||||
| {$59.20$} & | |||||
| {$30.35$} & | |||||
| {$40.12$} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ساده\\ بعد بردارهای تعبیه = 10\\ \end{tabular}} & | |||||
| {$75.30$} & | |||||
| {$58.22$} & | |||||
| {$31.13$} & | |||||
| {$40.56$} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ساده\\ بعد بردارهای تعبیه = 40\\ \end{tabular}} & | |||||
| {$73.62$} & | |||||
| {$54.24$} & | |||||
| {$32.93$} & | |||||
| {$40.98$} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ساده\\ بعد بردارهای تعبیه = 100\\ \end{tabular}} & | |||||
| {$71.75$} & | |||||
| {$50.62$} & | |||||
| {$34.32$} & | |||||
| {$40.90$} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ژرف\\ بعد بردارهای تعبیه = 10\\ تعداد لایهها = 3\\ تعداد نورونهای هر لایه = 20\end{tabular}} & | |||||
| {$74.70$} & | |||||
| {$42.85$} & | |||||
| {$66.45$} & | |||||
| {$52.10$} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ژرف\\ بعد بردارهای تعبیه = 10\\ تعداد لایهها = 3\\ تعداد نورونهای هر لایه = 100\end{tabular}} & | |||||
| {$75.44$} & | |||||
| {$55.94$} & | |||||
| {$32.06$} & | |||||
| {$40.76$} \\ \hline | |||||
| {\begin{tabular}[c]{@{}c@{}}ماشین فاکتورگیری ژرف\\ بعد بردارهای تعبیه = 10\\ تعداد لایهها = 3\\ تعداد نورونهای هر لایه = 400\end{tabular}} & | |||||
| {$75.45$} & | |||||
| {$33.64$} & | |||||
| {$90.63$} & | |||||
| {$49.07$} \\ \hline | |||||
| {\textbf{روش پیشنهادی}} & | |||||
| {\textbf{$76.37$}} & | |||||
| {$42.76$} & | |||||
| {$68.61$} & | |||||
| {$53.44$} \\ \hline | |||||
| \end{tabular} | |||||
| \end{center} | |||||
| \end{table} | |||||
| همانطور که از نتایج قابل مشاهده است، مدل پیشنهادی در این مجموعه داده نیز عملکرد بهتری نشان داده و روشهای ماشین فاکتورگیری ساده و همچنین ماشین فاکتورگیری ژرف را پشت سر گذاشته است. | |||||
+ 61
- 0
Thesis/chap5.aux
View File
| \relax | |||||
| \providecommand\zref@newlabel[2]{} | |||||
| \providecommand\hyper@newdestlabel[2]{} | |||||
| \zref@newlabel{zref@129}{\abspage{71}\page{64}\pagevalue{64}} | |||||
| \@writefile{toc}{\contentsline {chapter}{فصل\nobreakspace {}\numberline {5}جمع بندی و کارهای آتی}{64}{chapter.5}} | |||||
| \@writefile{lof}{\addvspace {10\p@ }} | |||||
| \@writefile{lot}{\addvspace {10\p@ }} | |||||
| \newlabel{Chap:Chap5}{{5}{64}{جمع بندی و کارهای آتی}{chapter.5}{}} | |||||
| \@writefile{toc}{\contentsline {section}{\numberline {5-1}کارهای آتی}{64}{section.5.1}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {5-1-1}ارائهی پیادهسازی کارا}{65}{subsection.5.1.1}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {5-1-2}طراحی مدل برای استفاده در شرایط آنلاین}{65}{subsection.5.1.2}} | |||||
| \@writefile{toc}{\contentsline {subsection}{\numberline {5-1-3}یافتن راهی برای ایجاد تعادل بین اکتشاف و بهرهبرداری}{65}{subsection.5.1.3}} | |||||
| \@setckpt{chap5}{ | |||||
| \setcounter{page}{66} | |||||
| \setcounter{equation}{0} | |||||
| \setcounter{enumi}{2} | |||||
| \setcounter{enumii}{0} | |||||
| \setcounter{enumiii}{0} | |||||
| \setcounter{enumiv}{0} | |||||
| \setcounter{footnote}{1} | |||||
| \setcounter{mpfootnote}{0} | |||||
| \setcounter{part}{0} | |||||
| \setcounter{chapter}{5} | |||||
| \setcounter{section}{1} | |||||
| \setcounter{subsection}{3} | |||||
| \setcounter{subsubsection}{0} | |||||
| \setcounter{paragraph}{0} | |||||
| \setcounter{subparagraph}{0} | |||||
| \setcounter{figure}{0} | |||||
| \setcounter{table}{0} | |||||
| \setcounter{parentequation}{0} | |||||
| \setcounter{ALC@unique}{0} | |||||
| \setcounter{ALC@line}{0} | |||||
| \setcounter{ALC@rem}{0} | |||||
| \setcounter{ALC@depth}{0} | |||||
| \setcounter{float@type}{8} | |||||
| \setcounter{algorithm}{0} | |||||
| \setcounter{ContinuedFloat}{0} | |||||
| \setcounter{KVtest}{0} | |||||
| \setcounter{subfigure}{0} | |||||
| \setcounter{subfigure@save}{0} | |||||
| \setcounter{lofdepth}{1} | |||||
| \setcounter{subtable}{0} | |||||
| \setcounter{subtable@save}{0} | |||||
| \setcounter{lotdepth}{1} | |||||
| \setcounter{pp@next@reset}{0} | |||||
| \setcounter{zpage}{64} | |||||
| \setcounter{@pps}{0} | |||||
| \setcounter{@ppsavesec}{0} | |||||
| \setcounter{@ppsaveapp}{0} | |||||
| \setcounter{Item}{7} | |||||
| \setcounter{Hfootnote}{124} | |||||
| \setcounter{Hy@AnnotLevel}{0} | |||||
| \setcounter{bookmark@seq@number}{48} | |||||
| \setcounter{su@anzahl}{0} | |||||
| \setcounter{LT@tables}{0} | |||||
| \setcounter{LT@chunks}{0} | |||||
| \setcounter{footdir@label}{288} | |||||
| \setcounter{shadetheorem}{1} | |||||
| \setcounter{section@level}{2} | |||||
| } |
+ 21
- 0
Thesis/chap5.tex
View File
| % !TEX encoding = UTF-8 Unicode | |||||
| \chapter{جمع بندی و کارهای آتی}\label{Chap:Chap5} | |||||
| %================================================================== | |||||
| در فصل اول این پایاننامه، به معرفی مسالهی پیشبینی احتمال تعامل کاربران با تبلیغات نمایشی آنلاین و پیشنیازهای آن پرداختیم؛سپس چالشهای موجود پیرامون این مساله را معرفی کردیم. در فصل دوم با بررسی پژوهشهای پیشین، متوجه شدیم استفاده از بردارهای تعبیهی با ابعاد یکسان، یکی از خصوصیتهای مشترک همهی این پژوهشها است. | |||||
| در فصل سوم با وارسی بیشتر این مساله از دو زاویهی مختلف، به این نتیجهی یکسان رسیدیم که این خصوصیت مشترک، میتواند یک اشتباه رایج باشد. پس به طراحی یک مدل پیشبینی نرخ کلیک پرداختیم که از بردارهای تعبیه با ابعاد متفاوت استفاده کند؛ اما این فرض، باعث ایجاد محدودیت در محاسبهی تعامل در روش پیشنهادی شد. به کمک ایدهای از یک پژوهش دیگر، شیوهی محاسبهی تعامل را نیز در مدل پیشنهادی طراحی نمودیم و بقیهی قسمتهای مدل را بر اساس شرایط مساله طراحی کرده و در فصل چهارم، این مدل را در شرایط گوناگون آزمودیم. نتایج این آزمایشها را مقایسه کرده و نتیجه گرفتیم روش پیشنهادی، از سایر روشهای موجود در ادبیات پیشبینی نرخ کلیک عملکرد بهتری دارد. | |||||
| \section{کارهای آتی} | |||||
| معرفی یک روش پیشنهادی که عملکرد مناسبی روی مجموعههای دادهی موجود داشته باشد، تنها آغاز یک مسیر پژوهشی است. برای مفید واقع شدن پژوهش انجام شده، نیاز به برداشتن گامهای دیگری است که در این بخش به معرفی برخی از این گامها میپردازیم. | |||||
| \subsection{ارائهی پیادهسازی کارا} | |||||
| همانطور که در فصل اول بررسی شد، سرعت اجرای فرآیند مزایدهی بلادرنگ بسیار بالا است؛ پس مدلهای پیشبینی نرخ کلیک، باید در زمان بسیار کوتاهی، نرخ کلیک کاربر بر تعداد بسیار زیادی از بنرهای تبلیغاتی را تخمین بزنند. این امر باعث میشود ارائهی یک پیادهسازی سریع و کارا، یکی از مهمترین گامهای لازم برای ادامهی این پژوهش به شمار رود. | |||||
| \subsection{طراحی مدل برای استفاده در شرایط آنلاین} | |||||
| شرایط آنلاین به شرایطی گفته میشود که در آن لیست موجودیتهای هر فیلد، هر لحظه قابل رشد باشد. یعنی هر لحظه ممکن باشد یک کاربر جدید وارد چرخه شده یا یک بنر تبلیغاتی جدید ایجاد شود. این تنها شرایطی است که میتوان میزان مقاومت یک مدل پیشبینی نرخ کلیک را در برابر چالش شروع سرد اندازهگیری نمود؛ اما برای آزمودن روش پیشنهادی در چنین شرایطی، باید تغییراتی در ساختار آن لحاظ شود. به عنوان مثال، در شرایط آفلاین، تعداد سطرهای ماتریسهای تعبیه همیشه ثابت است؛ اما در صورت آنلاین بودن شرایط، ابعاد این ماتریسها هر لحظه میتوانند رشد کنند. چگونگی مقداردهی اولیهی سطرهای جدید این ماتریسها یکی از پرسشهایی است که برای ادامهی مسیر این پژوهش، باید پاسخ داده شوند. | |||||
| \subsection{یافتن راهی برای ایجاد تعادل بین اکتشاف و بهرهبرداری} | |||||
| در بسیاری از مسائل دنیای واقعی، چالش موازنهی بین اکتشاف و بهرهبرداری خودنمایی میکند. به عنوان مثال، یک مدل پیشبینی نرخ کلیک که در شرایط آنلاین کار میکند، هر بار باید تصمیم بگیرد که \textbf{آیا بنر تبلیغاتی دارای بیشترین احتمال کلیک را به کاربر نمایش دهد، یا بنر جدیدی که هنوز اطلاعات خاصی در مورد رفتار کاربران با آن وجود ندارد؟} | |||||
| یافتن راهی برای برقراری این موازنه، یک گام دیگر در ادامهی راه این پژوهش خواهد بود. | |||||
+ 52
- 0
Thesis/confirm.aux
View File
| \relax | |||||
| \providecommand\zref@newlabel[2]{} | |||||
| \providecommand\hyper@newdestlabel[2]{} | |||||
| \@setckpt{confirm}{ | |||||
| \setcounter{page}{3} | |||||
| \setcounter{equation}{0} | |||||
| \setcounter{enumi}{0} | |||||
| \setcounter{enumii}{0} | |||||
| \setcounter{enumiii}{0} | |||||
| \setcounter{enumiv}{0} | |||||
| \setcounter{footnote}{0} | |||||
| \setcounter{mpfootnote}{0} | |||||
| \setcounter{part}{0} | |||||
| \setcounter{chapter}{0} | |||||
| \setcounter{section}{0} | |||||
| \setcounter{subsection}{0} | |||||
| \setcounter{subsubsection}{0} | |||||
| \setcounter{paragraph}{0} | |||||
| \setcounter{subparagraph}{0} | |||||
| \setcounter{figure}{0} | |||||
| \setcounter{table}{0} | |||||
| \setcounter{parentequation}{0} | |||||
| \setcounter{ALC@unique}{0} | |||||
| \setcounter{ALC@line}{0} | |||||
| \setcounter{ALC@rem}{0} | |||||
| \setcounter{ALC@depth}{0} | |||||
| \setcounter{float@type}{8} | |||||
| \setcounter{algorithm}{0} | |||||
| \setcounter{ContinuedFloat}{0} | |||||
| \setcounter{KVtest}{0} | |||||
| \setcounter{subfigure}{0} | |||||
| \setcounter{subfigure@save}{0} | |||||
| \setcounter{lofdepth}{1} | |||||
| \setcounter{subtable}{0} | |||||
| \setcounter{subtable@save}{0} | |||||
| \setcounter{lotdepth}{1} | |||||
| \setcounter{pp@next@reset}{0} | |||||
| \setcounter{zpage}{0} | |||||
| \setcounter{@pps}{0} | |||||
| \setcounter{@ppsavesec}{0} | |||||
| \setcounter{@ppsaveapp}{0} | |||||
| \setcounter{Item}{0} | |||||
| \setcounter{Hfootnote}{0} | |||||
| \setcounter{Hy@AnnotLevel}{0} | |||||
| \setcounter{bookmark@seq@number}{0} | |||||
| \setcounter{su@anzahl}{0} | |||||
| \setcounter{LT@tables}{0} | |||||
| \setcounter{LT@chunks}{0} | |||||
| \setcounter{footdir@label}{0} | |||||
| \setcounter{shadetheorem}{0} | |||||
| \setcounter{section@level}{0} | |||||
| } |
+ 26
- 0
Thesis/confirm.tex
View File
| % !TEX encoding = UTF-8 Unicode | |||||
| \thispagestyle{empty} | |||||
| \begin{center} | |||||
| \Large{دانشگاه صنعتی شریف} \\ | |||||
| \Large{\fadepart} | |||||
| \vskip 1cm | |||||
| \large{\fatype{} \falevel} | |||||
| \vskip 2cm | |||||
| \textbf{\Large{\fatitle}} | |||||
| \vskip 2cm | |||||
| نگارش: \faAuthor | |||||
| \end{center} | |||||
| \vskip 4cm | |||||
| \bgroup | |||||
| \def\arraystretch{2.5}% | |||||
| \begin{tabular}{p{2.5cm}p{6.5cm}p{5cm}} | |||||
| استاد راهنما:& | |||||
| \fasupervisor & | |||||
| امضاء: \\ | |||||
| داور داخلی:& | |||||
| \momtaheninFirst & | |||||
| امضاء: \\ | |||||
| داور خارجی:& | |||||
| \momtahenouFirst & | |||||
| امضاء: \\ | |||||
| \end{tabular} |
+ 52
- 0
Thesis/cover_en.aux
View File
| \relax | |||||
| \providecommand\zref@newlabel[2]{} | |||||
| \providecommand\hyper@newdestlabel[2]{} | |||||
| \@setckpt{cover_en}{ | |||||
| \setcounter{page}{78} | |||||
| \setcounter{equation}{0} | |||||
| \setcounter{enumi}{2} | |||||
| \setcounter{enumii}{0} | |||||
| \setcounter{enumiii}{0} | |||||
| \setcounter{enumiv}{38} | |||||
| \setcounter{footnote}{1} | |||||
| \setcounter{mpfootnote}{0} | |||||
| \setcounter{part}{0} | |||||
| \setcounter{chapter}{5} | |||||
| \setcounter{section}{1} | |||||
| \setcounter{subsection}{3} | |||||
| \setcounter{subsubsection}{0} | |||||
| \setcounter{paragraph}{0} | |||||
| \setcounter{subparagraph}{0} | |||||
| \setcounter{figure}{0} | |||||
| \setcounter{table}{0} | |||||
| \setcounter{parentequation}{0} | |||||
| \setcounter{ALC@unique}{0} | |||||
| \setcounter{ALC@line}{0} | |||||
| \setcounter{ALC@rem}{0} | |||||
| \setcounter{ALC@depth}{0} | |||||
| \setcounter{float@type}{8} | |||||
| \setcounter{algorithm}{0} | |||||
| \setcounter{ContinuedFloat}{0} | |||||
| \setcounter{KVtest}{0} | |||||
| \setcounter{subfigure}{0} | |||||
| \setcounter{subfigure@save}{0} | |||||
| \setcounter{lofdepth}{1} | |||||
| \setcounter{subtable}{0} | |||||
| \setcounter{subtable@save}{0} | |||||
| \setcounter{lotdepth}{1} | |||||
| \setcounter{pp@next@reset}{0} | |||||
| \setcounter{zpage}{64} | |||||
| \setcounter{@pps}{0} | |||||
| \setcounter{@ppsavesec}{0} | |||||
| \setcounter{@ppsaveapp}{0} | |||||
| \setcounter{Item}{7} | |||||
| \setcounter{Hfootnote}{124} | |||||
| \setcounter{Hy@AnnotLevel}{0} | |||||
| \setcounter{bookmark@seq@number}{51} | |||||
| \setcounter{su@anzahl}{0} | |||||
| \setcounter{LT@tables}{0} | |||||
| \setcounter{LT@chunks}{0} | |||||
| \setcounter{footdir@label}{288} | |||||
| \setcounter{shadetheorem}{1} | |||||
| \setcounter{section@level}{2} | |||||
| } |
+ 23
- 0
Thesis/cover_en.tex
View File
| % !TEX encoding = UTF-8 Unicode | |||||
| \thispagestyle{empty} | |||||
| \begin{center} | |||||
| \begin{latin} | |||||
| \includegraphics{logo} | |||||
| \begin{large} | |||||
| Sharif University of Technology \\ \enDep{} | |||||
| \vskip 0.8cm | |||||
| \enlevel{} \entype{} \\ \enmajor{} | |||||
| \end{large} | |||||
| \vskip 3cm | |||||
| {Topic} \\ \large{ \textbf{\entitle}} | |||||
| \vskip 3 cm | |||||
| {By} \\ \large{\enAuthor} | |||||
| \vskip 0.75 cm | |||||
| {Supervisor} \\ \large{\ensupervisor} | |||||
| \vskip 1cm | |||||
| \large{\engdate} | |||||
| \end{latin} | |||||
| \end{center} | |||||
+ 52
- 0
Thesis/cover_fa.aux
View File
| \relax | |||||
| \providecommand\zref@newlabel[2]{} | |||||
| \providecommand\hyper@newdestlabel[2]{} | |||||
| \@setckpt{cover_fa}{ | |||||
| \setcounter{page}{2} | |||||
| \setcounter{equation}{0} | |||||
| \setcounter{enumi}{0} | |||||
| \setcounter{enumii}{0} | |||||
| \setcounter{enumiii}{0} | |||||
| \setcounter{enumiv}{0} | |||||
| \setcounter{footnote}{0} | |||||
| \setcounter{mpfootnote}{0} | |||||
| \setcounter{part}{0} | |||||
| \setcounter{chapter}{0} | |||||
| \setcounter{section}{0} | |||||
| \setcounter{subsection}{0} | |||||
| \setcounter{subsubsection}{0} | |||||
| \setcounter{paragraph}{0} | |||||
| \setcounter{subparagraph}{0} | |||||
| \setcounter{figure}{0} | |||||
| \setcounter{table}{0} | |||||
| \setcounter{parentequation}{0} | |||||
| \setcounter{ALC@unique}{0} | |||||
| \setcounter{ALC@line}{0} | |||||
| \setcounter{ALC@rem}{0} | |||||
| \setcounter{ALC@depth}{0} | |||||
| \setcounter{float@type}{8} | |||||
| \setcounter{algorithm}{0} | |||||
| \setcounter{ContinuedFloat}{0} | |||||
| \setcounter{KVtest}{0} | |||||
| \setcounter{subfigure}{0} | |||||
| \setcounter{subfigure@save}{0} | |||||
| \setcounter{lofdepth}{1} | |||||
| \setcounter{subtable}{0} | |||||
| \setcounter{subtable@save}{0} | |||||
| \setcounter{lotdepth}{1} | |||||
| \setcounter{pp@next@reset}{0} | |||||
| \setcounter{zpage}{0} | |||||
| \setcounter{@pps}{0} | |||||
| \setcounter{@ppsavesec}{0} | |||||
| \setcounter{@ppsaveapp}{0} | |||||
| \setcounter{Item}{0} | |||||
| \setcounter{Hfootnote}{0} | |||||
| \setcounter{Hy@AnnotLevel}{0} | |||||
| \setcounter{bookmark@seq@number}{0} | |||||
| \setcounter{su@anzahl}{0} | |||||
| \setcounter{LT@tables}{0} | |||||
| \setcounter{LT@chunks}{0} | |||||
| \setcounter{footdir@label}{0} | |||||
| \setcounter{shadetheorem}{0} | |||||
| \setcounter{section@level}{0} | |||||
| } |
+ 23
- 0
Thesis/cover_fa.tex
View File
| % !TEX encoding = UTF-8 Unicode | |||||
| \begin{center} | |||||
| \thispagestyle{empty} | |||||
| \includegraphics{logo} | |||||
| \begin{large} | |||||
| دانشگاه صنعتی شریف \\ \fadepart{} | |||||
| \vskip 0.8cm | |||||
| \fatype{} \falevel{} \\ \famajor{} | |||||
| \end{large} | |||||
| \vskip 2cm | |||||
| {\large{عنوان رساله}} | |||||
| \vskip 0.5cm | |||||
| {\titlefont{\textbf{\fatitle}}} | |||||
| \vskip 2 cm | |||||
| \large{نگارش} \\ \Large{\faAuthor} | |||||
| \vskip 0.75cm | |||||
| \large{استاد راهنما} \\ \Large{\fasupervisor} | |||||
| \vskip 2cm | |||||
| \large{\fadate} | |||||
| \end{center} | |||||
+ 41
- 0
Thesis/definitions.tex
View File
| \newcommand{\redqueen}{\lr{\textsc{RedQueen}}\xspace} | |||||
| \newcommand{\cheshire}{\lr{\textsc{Cheshire}}\xspace} | |||||
| \newcommand{\dataset}{{\cal D}} | |||||
| \newcommand{\fracpartial}[2]{\frac{\partial #1}{\partial #2}} | |||||
| \newcommand{\eg}{\emph{e.g.}} | |||||
| \newcommand{\ie}{\emph{i.e.}} | |||||
| \newcommand{\RR}{\mathbb{R}} % Real numbers | |||||
| \newcommand{\PP}{\mathbb{P}} % Probability | |||||
| \newcommand{\EE}{\mathbb{E}} % Expectation | |||||
| \newcommand{\lambdab}{\boldsymbol{\lambda}} | |||||
| \newcommand{\gammab}{\boldsymbol{\gamma}} | |||||
| \newcommand{\Ab}{\bm{A}} | |||||
| \newcommand{\Bb}{\bm{B}} | |||||
| \newcommand{\Cb}{\bm{C}} | |||||
| \newcommand{\Db}{\bm{D}} | |||||
| \newcommand{\Ib}{\bm{I}} | |||||
| \newcommand{\Mb}{\bm{M}} | |||||
| \newcommand{\Nb}{\bm{N}} | |||||
| \newcommand{\Pb}{\bm{P}} | |||||
| \newcommand{\Ecal}{\mathcal{E}} | |||||
| \newcommand{\Fcal}{\mathcal{F}} | |||||
| \newcommand{\Gcal}{\mathcal{G}} | |||||
| \newcommand{\Hcal}{\mathcal{H}} | |||||
| \newcommand{\Ncal}{\mathcal{N}} | |||||
| \newcommand{\Vcal}{\mathcal{V}} | |||||
| \newcommand{\II}{\mathbb{I}} | |||||
| \newcommand{\ub}{\bm{u}} | |||||
| \newcommand{\ib}{\bm{i}} | |||||
| \newcommand{\diag}{\mathop{\mathrm{diag}}} | |||||
| \newcommand{\cbr}[1]{\left\{#1\right\}} | |||||
| % algorithm environment | |||||
| \renewcommand{\algorithmicrequire}{\textbf{Input:}} | |||||
| \renewcommand{\algorithmicensure}{\textbf{Output:}} | |||||
| % colon beginning of algorithm number | |||||
| \captionsetup[algorithm]{labelsep=colon} | |||||
| % custom dot | |||||
| \newcommand*{\Cdot}{\raisebox{-0.45ex}{\scalebox{1.15}{$\cdot$}}} | |||||
| \newcommand*{\Ldot}{\raisebox{-0.2ex}{\scalebox{1.15}{$\cdot$}}} |
BIN
Thesis/images/Embedding_L2Reg.png
View File
{kind=link}

BIN
Thesis/images/Embedding_dropout.png
View File
{kind=link}
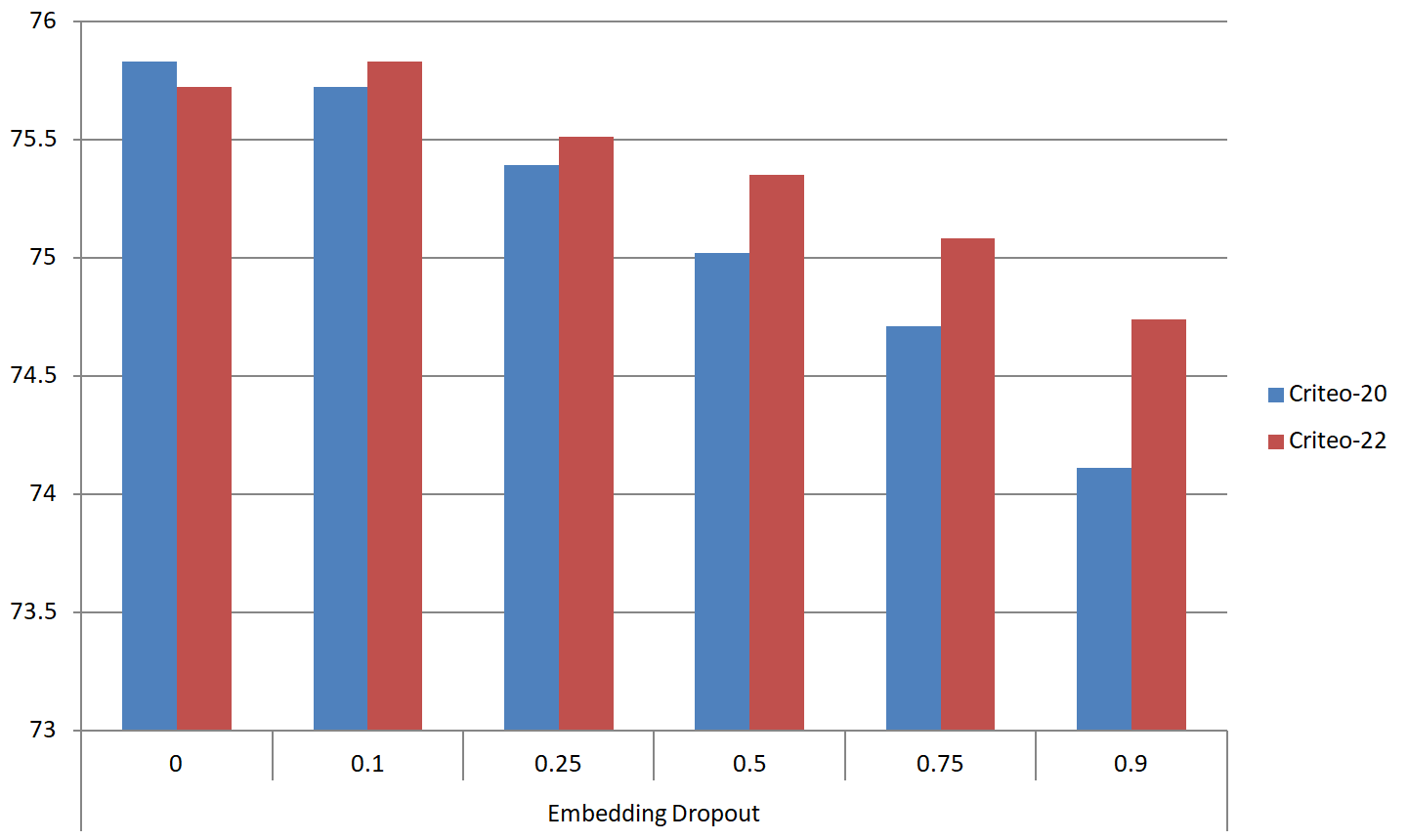
BIN
Thesis/images/GeoLoc.png
View File
{kind=link}
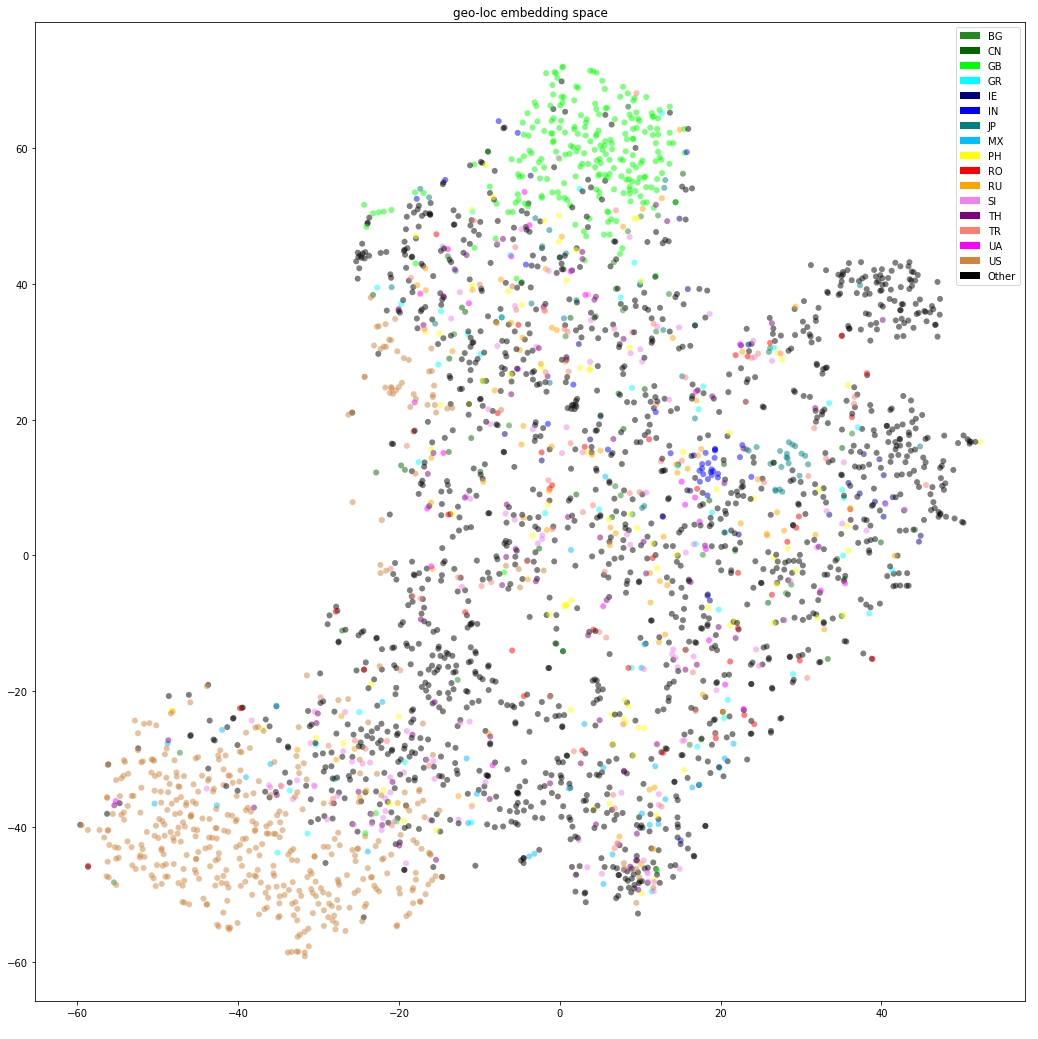
BIN
Thesis/images/HeadNet_Experiment1.png
View File
{kind=link}
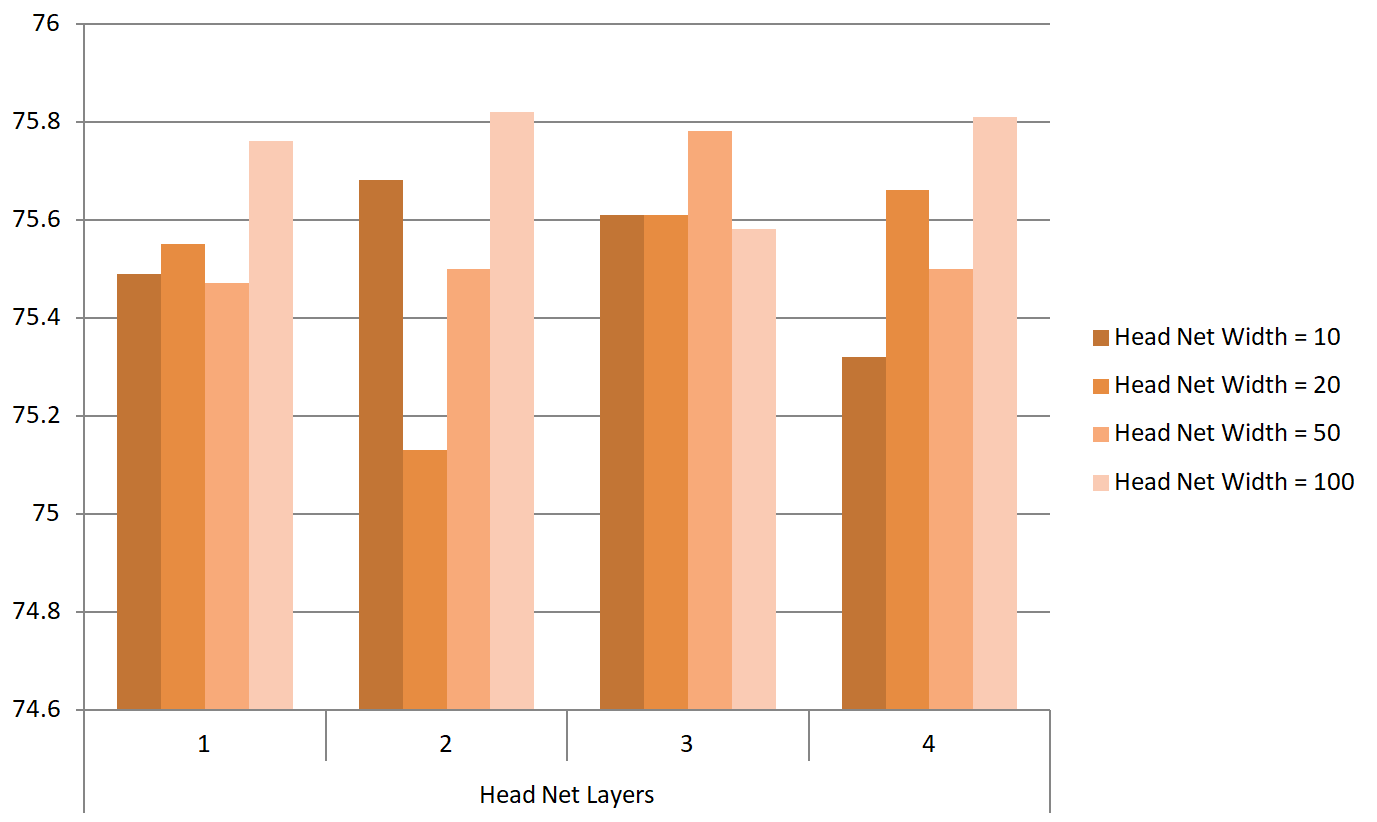
BIN
Thesis/images/HeadNet_Experiment2.png
View File
{kind=link}
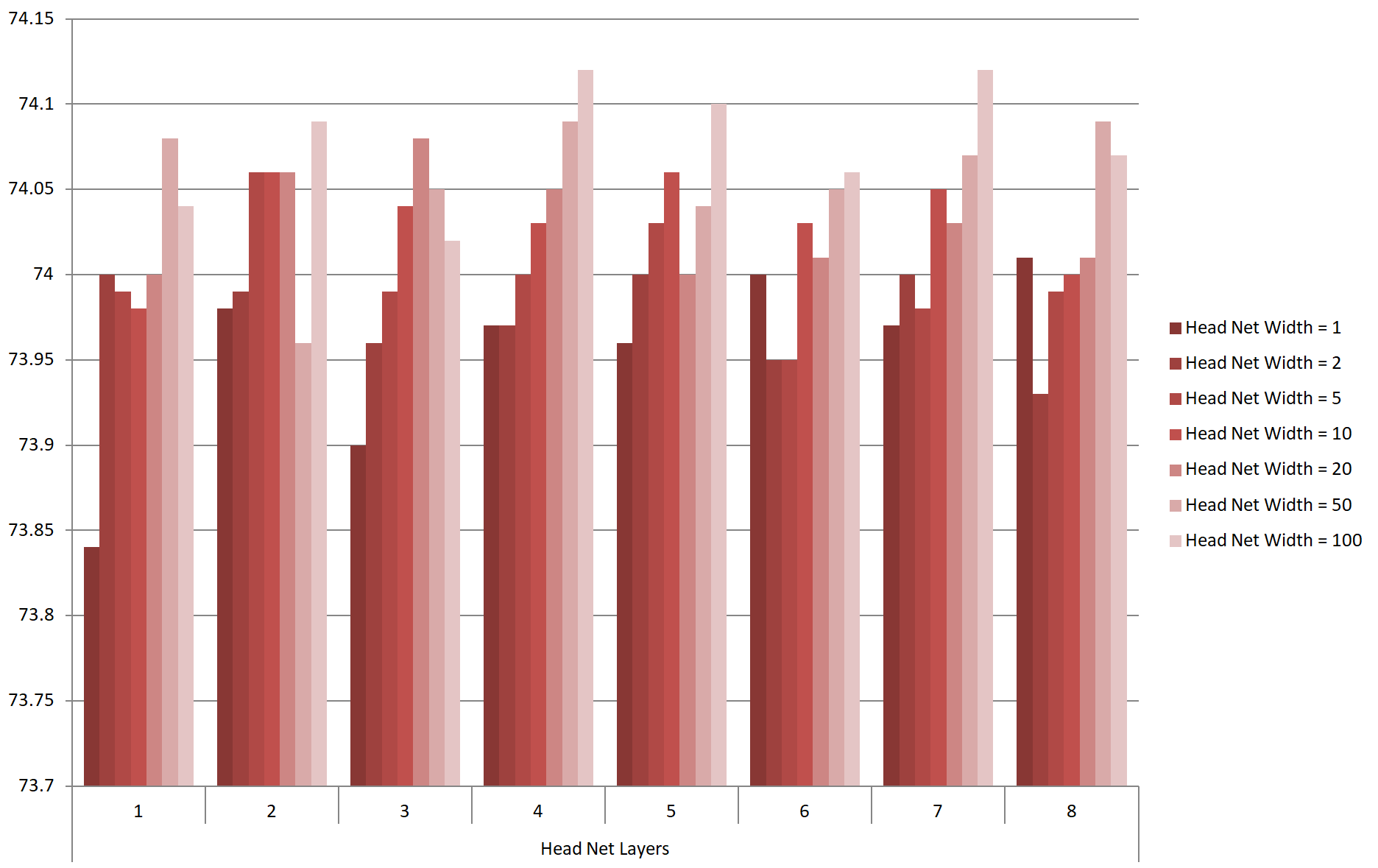
BIN
Thesis/images/HeadNet_L2Reg.png
View File
{kind=link}
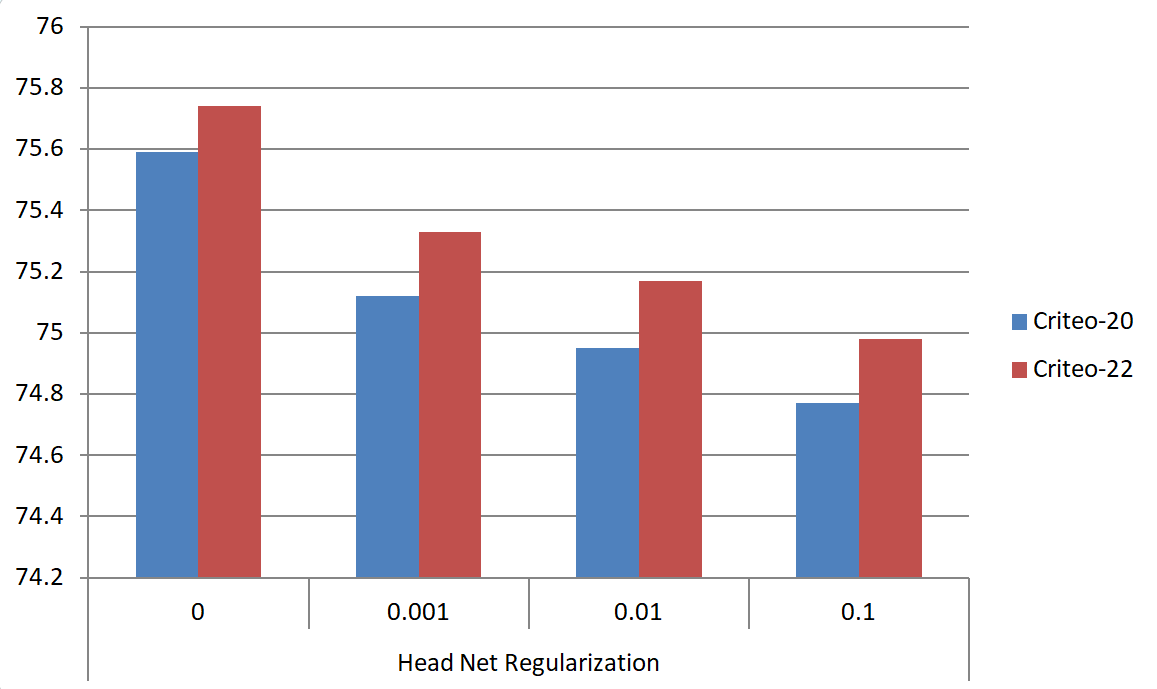
BIN
Thesis/images/HeadNet_dropout.png
View File
{kind=link}
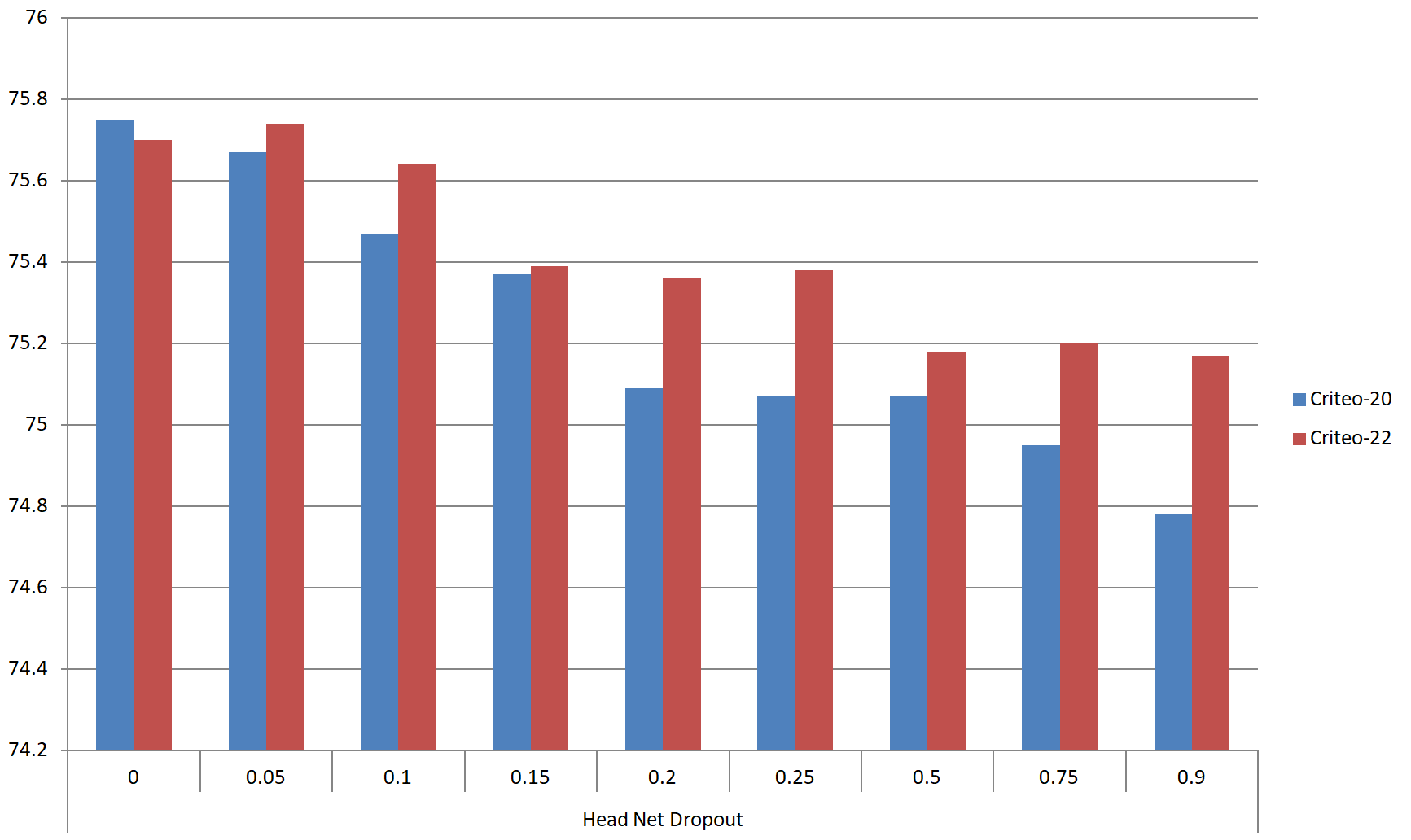
BIN
Thesis/images/InteractionNet_L2Reg.png
View File
{kind=link}
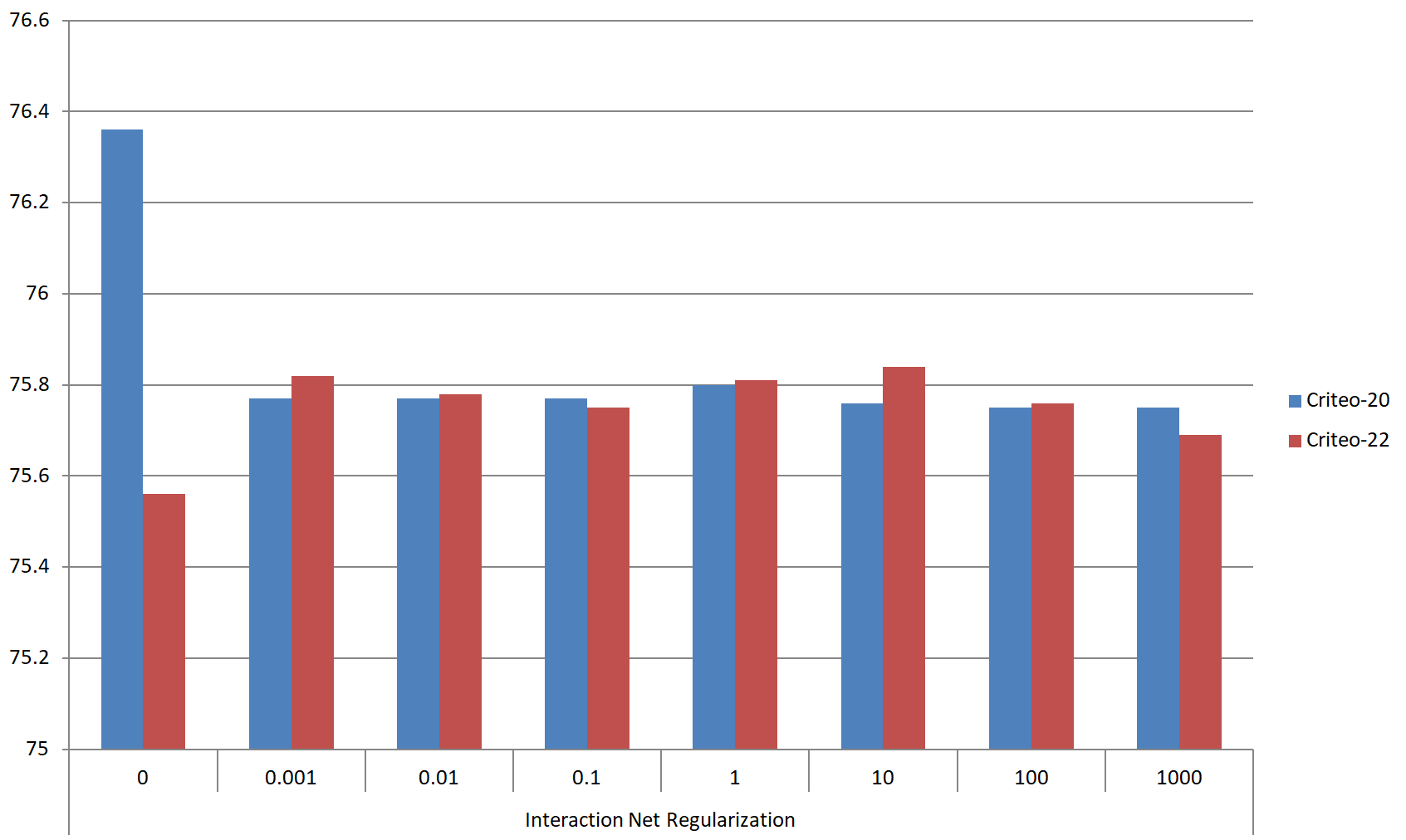
BIN
Thesis/images/InteractionNet_Layers_Interaction_Dim.png
View File
{kind=link}
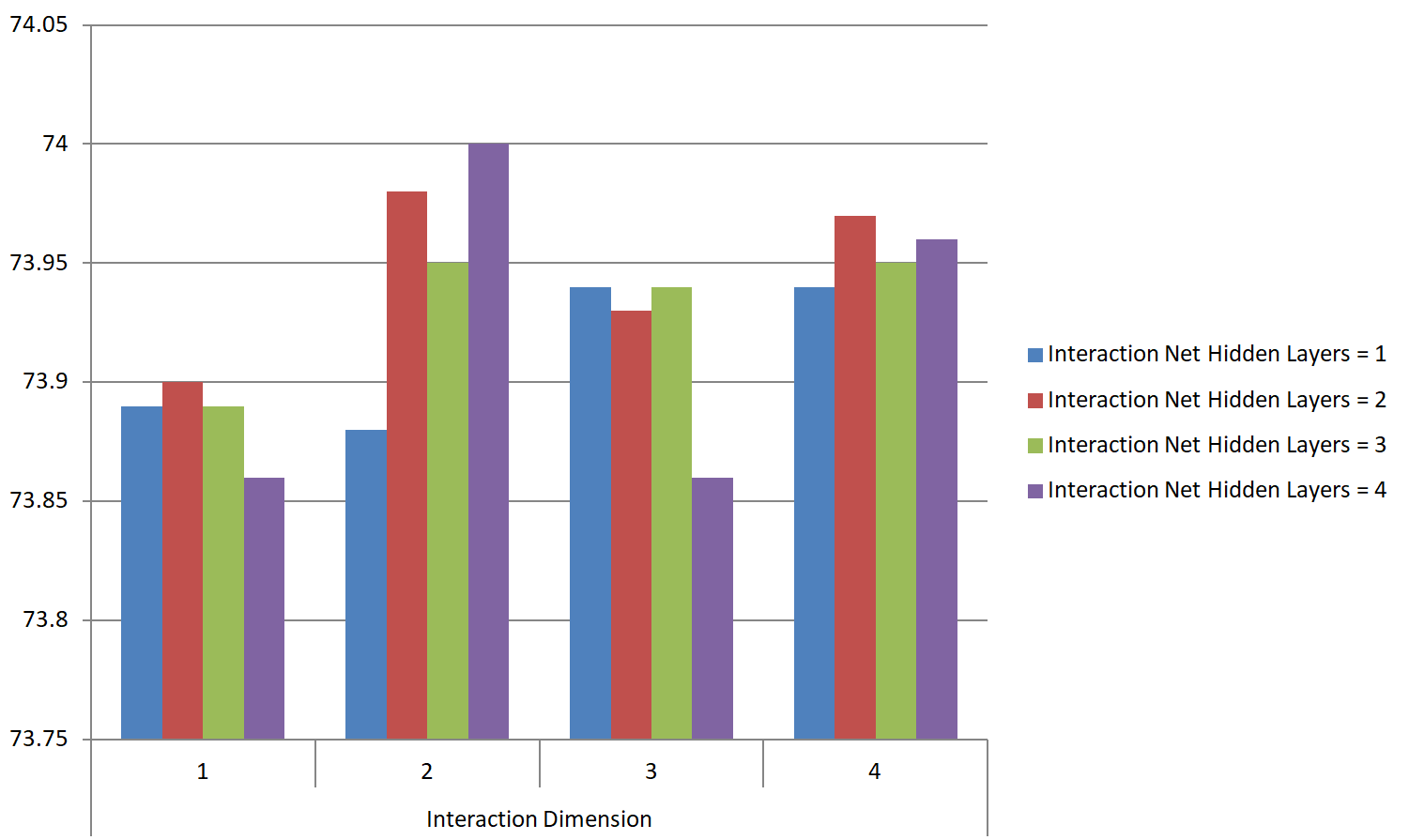
BIN
Thesis/images/InteractionNet_dropout.png
View File
{kind=link}
BIN
Thesis/images/RTB_Process.png
View File
{kind=link}
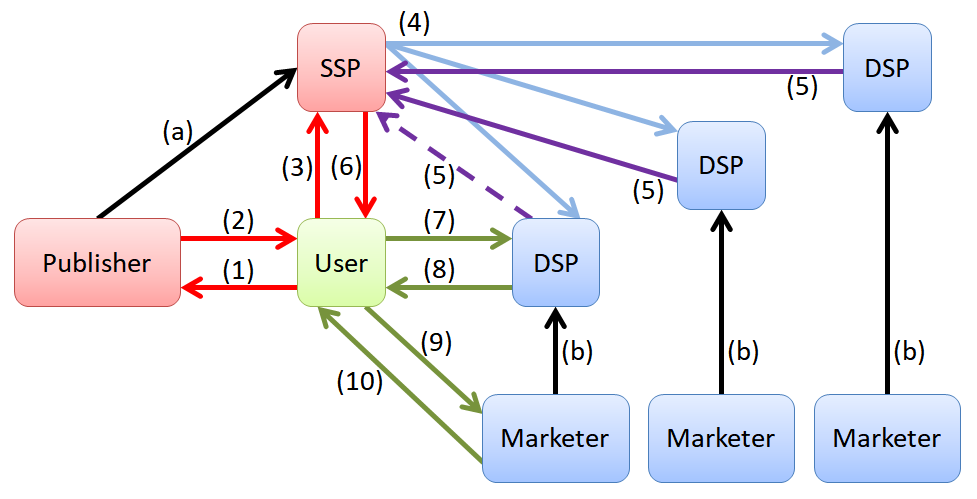
BIN
Thesis/images/logo.pdf
View File
+ 24
- 0
Thesis/info.log
View File
| This is XeTeX, Version 3.14159265-2.6-0.99998 (TeX Live 2017/W32TeX) (preloaded format=xelatex 2019.7.31) 12 JUL 2021 15:54 | |||||
| entering extended mode | |||||
| restricted \write18 enabled. | |||||
| %&-line parsing enabled. | |||||
| **./info.tex | |||||
| (./info.tex | |||||
| LaTeX2e <2017-04-15> | |||||
| Babel <3.10> and hyphenation patterns for 84 language(s) loaded. | |||||
| ) | |||||
| ! Emergency stop. | |||||
| <*> ./info.tex | |||||
| *** (job aborted, no legal \end found) | |||||
| Here is how much of TeX's memory you used: | |||||
| 23 strings out of 493005 | |||||
| 186 string characters out of 6132076 | |||||
| 61634 words of memory out of 5000000 | |||||
| 4096 multiletter control sequences out of 15000+600000 | |||||
| 3640 words of font info for 14 fonts, out of 8000000 for 9000 | |||||
| 1348 hyphenation exceptions out of 8191 | |||||
| 7i,0n,6p,95b,8s stack positions out of 5000i,500n,10000p,200000b,80000s | |||||
| No pages of output. |
+ 24
- 0
Thesis/info.tex
View File
| % !TEX encoding = UTF-8 Unicode | |||||
| \newcommand{\fatype}{رساله} | |||||
| \newcommand{\fatitle}{پیشبینی احتمال تعامل کاربران در تبلیغات نمایشی} | |||||
| \newcommand{\faAuthor}{محمدرضا رضائی} | |||||
| \newcommand{\fasupervisor}{حمیدرضا ربیعی} | |||||
| \newcommand{\fadate}{\text{زمستان 1399}} | |||||
| \newcommand{\famajor}{هوش مصنوعی} | |||||
| \newcommand{\falevel}{ارشد} | |||||
| \newcommand{\fadepart}{دانشکده مهندسی کامپیوتر} | |||||
| \newcommand{\entype}{Thesis} | |||||
| \newcommand{\entitle}{User Convertion Prediction In Display Advertisement} | |||||
| \newcommand{\enAuthor}{Mohammadreza Rezaei} | |||||
| \newcommand{\ensupervisor}{Hamid R. Rabiee} | |||||
| \newcommand{\engdate}{Winter 2021} | |||||
| \newcommand{\enmajor}{Artificial Intelligence} | |||||
| \newcommand{\enlevel}{M.Sc.} | |||||
| \newcommand{\enDep}{Department of Computer Engineering} | |||||
| \newcommand{\momtaheninFirst}{مهدیه سلیمانی} | |||||
| %\newcommand{\momtaheninSecond}{دکتر الف} | |||||
| \newcommand{\momtahenouFirst}{مصطفی صالحی} | |||||
| %\newcommand{\momtahenouSecond}{دکتر ج} | |||||
| %\newcommand{\momtahenouThird}{دکتر د} |
+ 24
- 0
Thesis/missfont.log
View File
| mktextfm IRXLotus/OT | |||||
| mktextfm IRXLotus/OT | |||||
| mktextfm IRXLotus/OT | |||||
| mktextfm IRXLotus/OT | |||||
| mktextfm HMXYas/OT | |||||
| mktextfm HMXYas/OT | |||||
| mktextfm HMXYas/OT | |||||
| mktextfm HMXYas/OT | |||||
| mktextfm HMXYas/OT | |||||
| mktextfm HMXYas/OT | |||||
| mktextfm HMXYas/OT | |||||
| mktextfm HMXYas/OT | |||||
| mktextfm HMXYas/OT | |||||
| mktextfm HMXYas/OT | |||||
| mktextfm HMXYas/OT | |||||
| mktextfm HMXYas/OT | |||||
| mktextfm HMXTitr/OT | |||||
| mktextfm HMXTitr/OT | |||||
| mktextfm HMXTitr/OT | |||||
| mktextfm HMXTitr/OT | |||||
| mktextfm HMXTitr/OT | |||||
| mktextfm HMXTitr/OT | |||||
| mktextfm HMXTitr/OT | |||||
| mktextfm HMXTitr/OT |
+ 93
- 0
Thesis/references.aux
View File
| \relax | |||||
| \providecommand\zref@newlabel[2]{} | |||||
| \providecommand\hyper@newdestlabel[2]{} | |||||
| \bibstyle{IEEEtran} | |||||
| \bibdata{IEEEabrv,references} | |||||
| \bibcite{choi2020online}{1} | |||||
| \bibcite{yuan2014survey}{2} | |||||
| \bibcite{qin2019revenue}{3} | |||||
| \bibcite{reference/ml/LingS17}{4} | |||||
| \bibcite{pires2019high}{5} | |||||
| \bibcite{journals/eswa/LikaKH14}{6} | |||||
| \bibcite{DBLP:journals/corr/abs-1004-3732}{7} | |||||
| \bibcite{boser1992}{8} | |||||
| \@writefile{toc}{\contentsline {chapter}{مراجع}{66}{section*.47}} | |||||
| \bibcite{Gai_piecewise}{9} | |||||
| \bibcite{lecun_sgd}{10} | |||||
| \bibcite{lbfgs_2008}{11} | |||||
| \bibcite{Graepel_2010}{12} | |||||
| \bibcite{Rendle:2010ja}{13} | |||||
| \bibcite{Juan_fieldawarefm1}{14} | |||||
| \bibcite{Juan_fieldawarefm2}{15} | |||||
| \bibcite{Pan_fieldweightedfm}{16} | |||||
| \bibcite{Freudenthaler2011BayesianFM}{17} | |||||
| \bibcite{Pan_sparsefm}{18} | |||||
| \bibcite{Xiao_afm}{19} | |||||
| \bibcite{srivastava2014dropout}{20} | |||||
| \bibcite{tikhonov1943stability}{21} | |||||
| \bibcite{journals/corr/ZhangYS17aa}{22} | |||||
| \bibcite{Chen_deepctr}{23} | |||||
| \bibcite{he2015residual}{24} | |||||
| \bibcite{Nair_relu}{25} | |||||
| \bibcite{Guo_embedding_2016}{26} | |||||
| \bibcite{ioffe2015batch}{27} | |||||
| \bibcite{Guo_deepfm1}{28} | |||||
| \bibcite{Guo_deepfm2}{29} | |||||
| \bibcite{Cheng_wideanddeep}{30} | |||||
| \bibcite{Wang_asae}{31} | |||||
| \bibcite{Ballard_autoencoder}{32} | |||||
| \bibcite{ShannonWeaver49}{33} | |||||
| \bibcite{Naumov_embedding_dim}{34} | |||||
| \bibcite{Ginart_MixedDimEmb}{35} | |||||
| \bibcite{he2017neural}{36} | |||||
| \bibcite{maas2013leakyrelu}{37} | |||||
| \bibcite{t-sne}{38} | |||||
| \@setckpt{references}{ | |||||
| \setcounter{page}{71} | |||||
| \setcounter{equation}{0} | |||||
| \setcounter{enumi}{2} | |||||
| \setcounter{enumii}{0} | |||||
| \setcounter{enumiii}{0} | |||||
| \setcounter{enumiv}{38} | |||||
| \setcounter{footnote}{1} | |||||
| \setcounter{mpfootnote}{0} | |||||
| \setcounter{part}{0} | |||||
| \setcounter{chapter}{5} | |||||
| \setcounter{section}{1} | |||||
| \setcounter{subsection}{3} | |||||
| \setcounter{subsubsection}{0} | |||||
| \setcounter{paragraph}{0} | |||||
| \setcounter{subparagraph}{0} | |||||
| \setcounter{figure}{0} | |||||
| \setcounter{table}{0} | |||||
| \setcounter{parentequation}{0} | |||||
| \setcounter{ALC@unique}{0} | |||||
| \setcounter{ALC@line}{0} | |||||
| \setcounter{ALC@rem}{0} | |||||
| \setcounter{ALC@depth}{0} | |||||
| \setcounter{float@type}{8} | |||||
| \setcounter{algorithm}{0} | |||||
| \setcounter{ContinuedFloat}{0} | |||||
| \setcounter{KVtest}{0} | |||||
| \setcounter{subfigure}{0} | |||||
| \setcounter{subfigure@save}{0} | |||||
| \setcounter{lofdepth}{1} | |||||
| \setcounter{subtable}{0} | |||||
| \setcounter{subtable@save}{0} | |||||
| \setcounter{lotdepth}{1} | |||||
| \setcounter{pp@next@reset}{0} | |||||
| \setcounter{zpage}{64} | |||||
| \setcounter{@pps}{0} | |||||
| \setcounter{@ppsavesec}{0} | |||||
| \setcounter{@ppsaveapp}{0} | |||||
| \setcounter{Item}{7} | |||||
| \setcounter{Hfootnote}{124} | |||||
| \setcounter{Hy@AnnotLevel}{0} | |||||
| \setcounter{bookmark@seq@number}{49} | |||||
| \setcounter{su@anzahl}{0} | |||||
| \setcounter{LT@tables}{0} | |||||
| \setcounter{LT@chunks}{0} | |||||
| \setcounter{footdir@label}{288} | |||||
| \setcounter{shadetheorem}{1} | |||||
| \setcounter{section@level}{2} | |||||
| } |
+ 707
- 0
Thesis/references.bib
View File
| @inproceedings{boser1992, | |||||
| added-at = {2011-04-06T14:59:36.000+0200}, | |||||
| address = {Pittsburgh, PA, USA}, | |||||
| author = {Boser, Bernhard E. and Guyon, Isabelle M. and Vapnik, Vladimir N.}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/2f4c8abb0eea7de4431f51c6dd3f3eb55/utahell}, | |||||
| booktitle = {Proceedings of the 5th Annual Workshop on Computational Learning Theory (COLT'92)}, | |||||
| description = {A training algorithm for optimal margin classifiers}, | |||||
| editor = {Haussler, David}, | |||||
| interhash = {81c1ca02cfdb4006d4ae602fcbbafcd3}, | |||||
| intrahash = {f4c8abb0eea7de4431f51c6dd3f3eb55}, | |||||
| keywords = {learning svm}, | |||||
| month = {July}, | |||||
| pages = {144--152}, | |||||
| publisher = {ACM Press}, | |||||
| timestamp = {2011-12-16T16:31:14.000+0100}, | |||||
| title = {A Training Algorithm for Optimal Margin Classifiers}, | |||||
| url = {http://doi.acm.org/10.1145/130385.130401}, | |||||
| year = 1992 | |||||
| } | |||||
| @article{Gai_piecewise, | |||||
| added-at = {2018-08-13T00:00:00.000+0200}, | |||||
| author = {Gai, Kun and Zhu, Xiaoqiang and Li, Han and Liu, Kai and Wang, Zhe}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/20a9312f3a5b0481928e589477d7dee81/dblp}, | |||||
| ee = {http://arxiv.org/abs/1704.05194}, | |||||
| interhash = {2c5f2e3b8e0a358d4b4d24835a6b5a33}, | |||||
| intrahash = {0a9312f3a5b0481928e589477d7dee81}, | |||||
| journal = {CoRR}, | |||||
| keywords = {dblp}, | |||||
| timestamp = {2018-08-14T13:15:00.000+0200}, | |||||
| title = {Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction.}, | |||||
| url = {http://dblp.uni-trier.de/db/journals/corr/corr1704.html#GaiZLLW17}, | |||||
| volume = {abs/1704.05194}, | |||||
| year = 2017 | |||||
| } | |||||
| @article{lecun_sgd, | |||||
| abstract = {Multilayer neural networks trained with the back-propagation algorithm constitute the best example of a successful gradient based learning technique. Given an appropriate network architecture, gradient-based learning algorithms can be used to synthesize a complex decision surface that can classify high-dimensional patterns, such as handwritten characters, with minimal preprocessing. This paper reviews various methods applied to handwritten character recognition and compares them on a standard handwritten digit recognition task. Convolutional neural networks, which are specifically designed to deal with the variability of 2D shapes, are shown to outperform all other techniques. Real-life document recognition systems are composed of multiple modules including field extraction, segmentation recognition, and language modeling. A new learning paradigm, called graph transformer networks (GTN), allows such multimodule systems to be trained globally using gradient-based methods so as to minimize an overall performance measure. Two systems for online handwriting recognition are described. Experiments demonstrate the advantage of global training, and the flexibility of graph transformer networks. A graph transformer network for reading a bank cheque is also described. It uses convolutional neural network character recognizers combined with global training techniques to provide record accuracy on business and personal cheques. It is deployed commercially and reads several million cheques per day}, | |||||
| added-at = {2019-01-05T14:54:07.000+0100}, | |||||
| author = {LeCun, Y. and Bottou, L. and Bengio, Y. and Haffner, P.}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/28417f8e20e96a98703486b82a09583c7/slicside}, | |||||
| doi = {10.1109/5.726791}, | |||||
| interhash = {7a82cccacd23cf06b25ff5325a6c86c7}, | |||||
| intrahash = {8417f8e20e96a98703486b82a09583c7}, | |||||
| issn = {0018-9219}, | |||||
| journal = {Proceedings of the IEEE}, | |||||
| keywords = {ba-2018-hahnrico}, | |||||
| number = 11, | |||||
| pages = {2278-2324}, | |||||
| timestamp = {2019-01-05T14:54:07.000+0100}, | |||||
| title = {Gradient-based learning applied to document recognition}, | |||||
| volume = 86, | |||||
| year = 1998 | |||||
| } | |||||
| @article{lbfgs_2008, | |||||
| added-at = {2020-02-17T00:00:00.000+0100}, | |||||
| author = {Xiao, Yunhai and Wei, Zengxin and Wang, Zhiguo}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/29a414487321cd8049eb9f34c3e8e2e61/dblp}, | |||||
| ee = {https://doi.org/10.1016/j.camwa.2008.01.028}, | |||||
| interhash = {d843677026f4d5722d2500525d47b5ca}, | |||||
| intrahash = {9a414487321cd8049eb9f34c3e8e2e61}, | |||||
| journal = {Comput. Math. Appl.}, | |||||
| keywords = {dblp}, | |||||
| number = 4, | |||||
| pages = {1001-1009}, | |||||
| timestamp = {2020-02-18T11:38:42.000+0100}, | |||||
| title = {A limited memory BFGS-type method for large-scale unconstrained optimization.}, | |||||
| url = {http://dblp.uni-trier.de/db/journals/cma/cma56.html#XiaoWW08}, | |||||
| volume = 56, | |||||
| year = 2008 | |||||
| } | |||||
| @inproceedings{Graepel_2010, | |||||
| added-at = {2019-04-03T00:00:00.000+0200}, | |||||
| author = {Graepel, Thore and Candela, Joaquin Quiñonero and Borchert, Thomas and Herbrich, Ralf}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/2b008aa80a83b88a6e5fee59caa9b6493/dblp}, | |||||
| booktitle = {ICML}, | |||||
| crossref = {conf/icml/2010}, | |||||
| editor = {Fürnkranz, Johannes and Joachims, Thorsten}, | |||||
| ee = {https://icml.cc/Conferences/2010/papers/901.pdf}, | |||||
| interhash = {2a83b4cd23188992c5b7a4023eedcebe}, | |||||
| intrahash = {b008aa80a83b88a6e5fee59caa9b6493}, | |||||
| keywords = {dblp}, | |||||
| pages = {13-20}, | |||||
| publisher = {Omnipress}, | |||||
| timestamp = {2019-04-04T11:48:32.000+0200}, | |||||
| title = {Web-Scale Bayesian Click-Through rate Prediction for Sponsored Search Advertising in Microsoft's Bing Search Engine.}, | |||||
| url = {http://dblp.uni-trier.de/db/conf/icml/icml2010.html#GraepelCBH10}, | |||||
| year = 2010 | |||||
| } | |||||
| @inproceedings{Rendle:2010ja, | |||||
| added-at = {2019-05-21T10:10:49.000+0200}, | |||||
| author = {Rendle, Steffen}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/265ab448242aaaeb060a8b9ed87204423/sxkdz}, | |||||
| booktitle = {Proceedings of the 2010 IEEE International Conference on Data Mining}, | |||||
| doi = {10.1109/ICDM.2010.127}, | |||||
| interhash = {425e17658c7386e5b35c505a1ed89aff}, | |||||
| intrahash = {65ab448242aaaeb060a8b9ed87204423}, | |||||
| issn = {2374-8486}, | |||||
| keywords = {imported}, | |||||
| month = dec, | |||||
| pages = {995--1000}, | |||||
| publisher = {IEEE}, | |||||
| series = {ICDM '10}, | |||||
| timestamp = {2019-05-21T10:10:49.000+0200}, | |||||
| title = {{Factorization Machines}}, | |||||
| url = {http://ieeexplore.ieee.org/document/5694074/}, | |||||
| year = 2010 | |||||
| } | |||||
| @inproceedings{Juan_fieldawarefm1, | |||||
| added-at = {2018-11-06T00:00:00.000+0100}, | |||||
| author = {Juan, Yu-Chin and Zhuang, Yong and Chin, Wei-Sheng and Lin, Chih-Jen}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/2fbb5958a0b0b3ab03c7423e84cc08d9c/dblp}, | |||||
| booktitle = {RecSys}, | |||||
| crossref = {conf/recsys/2016}, | |||||
| editor = {Sen, Shilad and Geyer, Werner and Freyne, Jill and Castells, Pablo}, | |||||
| ee = {https://doi.org/10.1145/2959100.2959134}, | |||||
| interhash = {b512083d1729eed87424afe44ebc8677}, | |||||
| intrahash = {fbb5958a0b0b3ab03c7423e84cc08d9c}, | |||||
| isbn = {978-1-4503-4035-9}, | |||||
| keywords = {dblp}, | |||||
| pages = {43-50}, | |||||
| publisher = {ACM}, | |||||
| timestamp = {2018-11-07T12:40:54.000+0100}, | |||||
| title = {Field-aware Factorization Machines for CTR Prediction.}, | |||||
| url = {http://dblp.uni-trier.de/db/conf/recsys/recsys2016.html#JuanZCL16}, | |||||
| year = 2016 | |||||
| } | |||||
| @article{Juan_fieldawarefm2, | |||||
| added-at = {2018-08-13T00:00:00.000+0200}, | |||||
| author = {Juan, Yuchin and Lefortier, Damien and Chapelle, Olivier}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/29ef509381d1eb3ebd24239efc195f9fb/dblp}, | |||||
| ee = {http://arxiv.org/abs/1701.04099}, | |||||
| interhash = {1a419341131eb2bc20e6ac71713d7a6d}, | |||||
| intrahash = {9ef509381d1eb3ebd24239efc195f9fb}, | |||||
| journal = {CoRR}, | |||||
| keywords = {dblp}, | |||||
| timestamp = {2018-08-14T13:16:14.000+0200}, | |||||
| title = {Field-aware Factorization Machines in a Real-world Online Advertising System.}, | |||||
| url = {http://dblp.uni-trier.de/db/journals/corr/corr1701.html#JuanLC17}, | |||||
| volume = {abs/1701.04099}, | |||||
| year = 2017 | |||||
| } | |||||
| @article{Pan_fieldweightedfm, | |||||
| added-at = {2018-08-13T00:00:00.000+0200}, | |||||
| author = {Pan, Junwei and Xu, Jian and Ruiz, Alfonso Lobos and Zhao, Wenliang and Pan, Shengjun and Sun, Yu and Lu, Quan}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/203e245bd5b30499fbdd6ff6b60c4b022/dblp}, | |||||
| ee = {http://arxiv.org/abs/1806.03514}, | |||||
| interhash = {13c7bf6b08564f96ec471e2b42a90218}, | |||||
| intrahash = {03e245bd5b30499fbdd6ff6b60c4b022}, | |||||
| journal = {CoRR}, | |||||
| keywords = {dblp}, | |||||
| timestamp = {2018-08-14T13:11:25.000+0200}, | |||||
| title = {Field-weighted Factorization Machines for Click-Through Rate Prediction in Display Advertising.}, | |||||
| url = {http://dblp.uni-trier.de/db/journals/corr/corr1806.html#abs-1806-03514}, | |||||
| volume = {abs/1806.03514}, | |||||
| year = 2018 | |||||
| } | |||||
| @inproceedings{Pan_sparsefm, | |||||
| added-at = {2019-02-11T00:00:00.000+0100}, | |||||
| author = {Pan, Zhen and Chen, Enhong and Liu, Qi and Xu, Tong and Ma, Haiping and Lin, Hongjie}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/2a22be9a0667f11266d704e178d8a2b6e/dblp}, | |||||
| booktitle = {ICDM}, | |||||
| crossref = {conf/icdm/2016}, | |||||
| editor = {Bonchi, Francesco and Domingo-Ferrer, Josep and Baeza-Yates, Ricardo and Zhou, Zhi-Hua and Wu, Xindong}, | |||||
| ee = {http://doi.ieeecomputersociety.org/10.1109/ICDM.2016.0051}, | |||||
| interhash = {639e5eb01646b897aeb0dc3257588811}, | |||||
| intrahash = {a22be9a0667f11266d704e178d8a2b6e}, | |||||
| keywords = {dblp}, | |||||
| pages = {400-409}, | |||||
| publisher = {IEEE Computer Society}, | |||||
| timestamp = {2019-10-17T13:02:53.000+0200}, | |||||
| title = {Sparse Factorization Machines for Click-through Rate Prediction.}, | |||||
| url = {http://dblp.uni-trier.de/db/conf/icdm/icdm2016.html#PanCLXML16}, | |||||
| year = 2016 | |||||
| } | |||||
| @inproceedings{Freudenthaler2011BayesianFM, | |||||
| title={Bayesian Factorization Machines}, | |||||
| author={Freudenthaler, C., Schmidt-Thieme, L., and Rendle, S}, | |||||
| booktitle={In Proceedings of the NIPS Workshop on Sparse Representation and Low-rank Approximation}, | |||||
| year={2011} | |||||
| } | |||||
| @article{Xiao_afm, | |||||
| added-at = {2018-08-13T00:00:00.000+0200}, | |||||
| author = {Xiao, Jun and Ye, Hao and He, Xiangnan and Zhang, Hanwang and Wu, Fei and Chua, Tat-Seng}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/2b66b4732b35617644835daba33d1a916/dblp}, | |||||
| ee = {http://arxiv.org/abs/1708.04617}, | |||||
| interhash = {4f5c499774291dc0e9184e781c365c05}, | |||||
| intrahash = {b66b4732b35617644835daba33d1a916}, | |||||
| journal = {CoRR}, | |||||
| keywords = {dblp}, | |||||
| timestamp = {2018-08-14T13:52:58.000+0200}, | |||||
| title = {Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks.}, | |||||
| url = {http://dblp.uni-trier.de/db/journals/corr/corr1708.html#abs-1708-04617}, | |||||
| volume = {abs/1708.04617}, | |||||
| year = 2017 | |||||
| } | |||||
| @article{srivastava2014dropout, | |||||
| abstract = {{Deep neural nets with a large number of parameters are very powerful machine learning systems. However, overfitting is a serious problem in such networks. Large networks are also slow to use, making it difficult to deal with overfitting by combining the predictions of many different large neural nets at test time. Dropout is a technique for addressing this problem. The key idea is to randomly drop units (along with their connections) from the neural network during training. This prevents units from co-adapting too much. During training, dropout samples from an exponential number of different "thinned" networks. At test time, it is easy to approximate the effect of averaging the predictions of all these thinned networks by simply using a single unthinned network that has smaller weights. This significantly reduces overfitting and gives major improvements over other regularization methods. We show that dropout improves the performance of neural networks on supervised learning tasks in vision, speech recognition, document classification and computational biology, obtaining state-of-the-art results on many benchmark data sets.}}, | |||||
| added-at = {2017-07-19T15:29:59.000+0200}, | |||||
| author = {Srivastava, Nitish and Hinton, Geoffrey and Krizhevsky, Alex and Sutskever, Ilya and Salakhutdinov, Ruslan}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/20715644d640cdaad9258133625cc5fe9/andreashdez}, | |||||
| citeulike-article-id = {13833631}, | |||||
| citeulike-linkout-0 = {http://portal.acm.org/citation.cfm?id=2670313}, | |||||
| interhash = {bdad866eb5fd8994c2aeae46af6def20}, | |||||
| intrahash = {0715644d640cdaad9258133625cc5fe9}, | |||||
| issn = {1532-4435}, | |||||
| journal = {J. Mach. Learn. Res.}, | |||||
| keywords = {imported}, | |||||
| month = jan, | |||||
| number = 1, | |||||
| pages = {1929--1958}, | |||||
| posted-at = {2016-04-29 18:36:35}, | |||||
| priority = {0}, | |||||
| publisher = {JMLR.org}, | |||||
| timestamp = {2017-07-19T15:31:02.000+0200}, | |||||
| title = {{Dropout: A Simple Way to Prevent Neural Networks from Overfitting}}, | |||||
| url = {http://portal.acm.org/citation.cfm?id=2670313}, | |||||
| volume = 15, | |||||
| year = 2014 | |||||
| } | |||||
| @inproceedings{tikhonov1943stability, | |||||
| title={On the stability of inverse problems}, | |||||
| author={Tikhonov, Andrey Nikolayevich}, | |||||
| booktitle={Dokl. Akad. Nauk SSSR}, | |||||
| volume={39}, | |||||
| pages={195--198}, | |||||
| year={1943} | |||||
| } | |||||
| @inproceedings{Chen_deepctr, | |||||
| added-at = {2020-04-08T00:00:00.000+0200}, | |||||
| author = {Chen, Junxuan and Sun, Baigui and Li, Hao and Lu, Hongtao and Hua, Xian-Sheng}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/2381b8348cc449d46692ef7e7830a51b7/dblp}, | |||||
| booktitle = {ACM Multimedia}, | |||||
| crossref = {conf/mm/2016}, | |||||
| editor = {Hanjalic, Alan and Snoek, Cees and Worring, Marcel and Bulterman, Dick C. A. and Huet, Benoit and Kelliher, Aisling and Kompatsiaris, Yiannis and Li, Jin}, | |||||
| ee = {https://doi.org/10.1145/2964284.2964325}, | |||||
| interhash = {f065025197d2320d883e2cc079fa7ac6}, | |||||
| intrahash = {381b8348cc449d46692ef7e7830a51b7}, | |||||
| isbn = {978-1-4503-3603-1}, | |||||
| keywords = {dblp}, | |||||
| pages = {811-820}, | |||||
| publisher = {ACM}, | |||||
| timestamp = {2020-04-09T11:42:00.000+0200}, | |||||
| title = {Deep CTR Prediction in Display Advertising.}, | |||||
| url = {http://dblp.uni-trier.de/db/conf/mm/mm2016.html#ChenSLLH16}, | |||||
| year = 2016 | |||||
| } | |||||
| @misc{he2015residual, | |||||
| abstract = {Deeper neural networks are more difficult to train. We present a residual | |||||
| learning framework to ease the training of networks that are substantially | |||||
| deeper than those used previously. We explicitly reformulate the layers as | |||||
| learning residual functions with reference to the layer inputs, instead of | |||||
| learning unreferenced functions. We provide comprehensive empirical evidence | |||||
| showing that these residual networks are easier to optimize, and can gain | |||||
| accuracy from considerably increased depth. On the ImageNet dataset we evaluate | |||||
| residual nets with a depth of up to 152 layers---8x deeper than VGG nets but | |||||
| still having lower complexity. An ensemble of these residual nets achieves | |||||
| 3.57% error on the ImageNet test set. This result won the 1st place on the | |||||
| ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 | |||||
| and 1000 layers. | |||||
| The depth of representations is of central importance for many visual | |||||
| recognition tasks. Solely due to our extremely deep representations, we obtain | |||||
| a 28% relative improvement on the COCO object detection dataset. Deep residual | |||||
| nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, | |||||
| where we also won the 1st places on the tasks of ImageNet detection, ImageNet | |||||
| localization, COCO detection, and COCO segmentation.}, | |||||
| added-at = {2017-05-15T22:38:25.000+0200}, | |||||
| author = {He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/2d0b3536c45de7324284739a24006de6a/axel.vogler}, | |||||
| description = {Deep Residual Learning for Image Recognition}, | |||||
| interhash = {3066b045c86a0b721a053f73eb50cd95}, | |||||
| intrahash = {d0b3536c45de7324284739a24006de6a}, | |||||
| keywords = {deep-learning res-net}, | |||||
| note = {cite arxiv:1512.03385Comment: Tech report}, | |||||
| timestamp = {2017-05-15T22:38:25.000+0200}, | |||||
| title = {Deep Residual Learning for Image Recognition}, | |||||
| url = {http://arxiv.org/abs/1512.03385}, | |||||
| year = 2015 | |||||
| } | |||||
| @inproceedings{Nair_relu, | |||||
| added-at = {2019-04-03T00:00:00.000+0200}, | |||||
| author = {Nair, Vinod and Hinton, Geoffrey E.}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/2059683ca9b2457d248942520babbe000/dblp}, | |||||
| booktitle = {ICML}, | |||||
| crossref = {conf/icml/2010}, | |||||
| editor = {Fürnkranz, Johannes and Joachims, Thorsten}, | |||||
| ee = {https://icml.cc/Conferences/2010/papers/432.pdf}, | |||||
| interhash = {acefcb0a5d1a937232f02f3fe0d5ab86}, | |||||
| intrahash = {059683ca9b2457d248942520babbe000}, | |||||
| keywords = {dblp}, | |||||
| pages = {807-814}, | |||||
| publisher = {Omnipress}, | |||||
| timestamp = {2019-04-04T11:48:32.000+0200}, | |||||
| title = {Rectified Linear Units Improve Restricted Boltzmann Machines.}, | |||||
| url = {http://dblp.uni-trier.de/db/conf/icml/icml2010.html#NairH10}, | |||||
| year = 2010 | |||||
| } | |||||
| @article{Guo_embedding_2016, | |||||
| added-at = {2018-08-13T00:00:00.000+0200}, | |||||
| author = {Guo, Cheng and Berkhahn, Felix}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/24f27494e7e90a5cbe32c726f3b729495/dblp}, | |||||
| ee = {http://arxiv.org/abs/1604.06737}, | |||||
| interhash = {6e2f004f0eaeff1b3ae92bbb7662dc33}, | |||||
| intrahash = {4f27494e7e90a5cbe32c726f3b729495}, | |||||
| journal = {CoRR}, | |||||
| keywords = {dblp}, | |||||
| timestamp = {2018-08-14T13:14:38.000+0200}, | |||||
| title = {Entity Embeddings of Categorical Variables.}, | |||||
| url = {http://dblp.uni-trier.de/db/journals/corr/corr1604.html#GuoB16}, | |||||
| volume = {abs/1604.06737}, | |||||
| year = 2016 | |||||
| } | |||||
| @misc{ioffe2015batch, | |||||
| abstract = {Training Deep Neural Networks is complicated by the fact that the | |||||
| distribution of each layer's inputs changes during training, as the parameters | |||||
| of the previous layers change. This slows down the training by requiring lower | |||||
| learning rates and careful parameter initialization, and makes it notoriously | |||||
| hard to train models with saturating nonlinearities. We refer to this | |||||
| phenomenon as internal covariate shift, and address the problem by normalizing | |||||
| layer inputs. Our method draws its strength from making normalization a part of | |||||
| the model architecture and performing the normalization for each training | |||||
| mini-batch. Batch Normalization allows us to use much higher learning rates and | |||||
| be less careful about initialization. It also acts as a regularizer, in some | |||||
| cases eliminating the need for Dropout. Applied to a state-of-the-art image | |||||
| classification model, Batch Normalization achieves the same accuracy with 14 | |||||
| times fewer training steps, and beats the original model by a significant | |||||
| margin. Using an ensemble of batch-normalized networks, we improve upon the | |||||
| best published result on ImageNet classification: reaching 4.9% top-5 | |||||
| validation error (and 4.8% test error), exceeding the accuracy of human raters.}, | |||||
| added-at = {2018-07-09T15:43:42.000+0200}, | |||||
| author = {Ioffe, Sergey and Szegedy, Christian}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/2bd6078b46e07f6e32cc0462a28ad929b/analyst}, | |||||
| description = {[1502.03167] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift}, | |||||
| interhash = {bf2b461f54850dbae02a295b9f5e799b}, | |||||
| intrahash = {bd6078b46e07f6e32cc0462a28ad929b}, | |||||
| keywords = {2015 arxiv deep-learning paper}, | |||||
| note = {cite arxiv:1502.03167}, | |||||
| timestamp = {2018-07-09T15:43:42.000+0200}, | |||||
| title = {Batch Normalization: Accelerating Deep Network Training by Reducing | |||||
| Internal Covariate Shift}, | |||||
| url = {http://arxiv.org/abs/1502.03167}, | |||||
| year = 2015 | |||||
| } | |||||
| @inproceedings{Guo_deepfm1, | |||||
| added-at = {2019-08-20T00:00:00.000+0200}, | |||||
| author = {Guo, Huifeng and Tang, Ruiming and Ye, Yunming and Li, Zhenguo and He, Xiuqiang}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/28c60cf7c56f3788385adec2feff31eb8/dblp}, | |||||
| booktitle = {IJCAI}, | |||||
| crossref = {conf/ijcai/2017}, | |||||
| editor = {Sierra, Carles}, | |||||
| ee = {https://doi.org/10.24963/ijcai.2017/239}, | |||||
| interhash = {45dbc7efa61cb111c8e3e6b86fcbc1e9}, | |||||
| intrahash = {8c60cf7c56f3788385adec2feff31eb8}, | |||||
| isbn = {978-0-9992411-0-3}, | |||||
| keywords = {dblp}, | |||||
| pages = {1725-1731}, | |||||
| publisher = {ijcai.org}, | |||||
| timestamp = {2019-08-21T11:50:23.000+0200}, | |||||
| title = {DeepFM: A Factorization-Machine based Neural Network for CTR Prediction.}, | |||||
| url = {http://dblp.uni-trier.de/db/conf/ijcai/ijcai2017.html#GuoTYLH17}, | |||||
| year = 2017 | |||||
| } | |||||
| @article{Guo_deepfm2, | |||||
| added-at = {2018-08-13T00:00:00.000+0200}, | |||||
| author = {Guo, Huifeng and Tang, Ruiming and Ye, Yunming and Li, Zhenguo and He, Xiuqiang and Dong, Zhenhua}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/280f0da037e5fe04038cdadd5f576f2c3/dblp}, | |||||
| ee = {http://arxiv.org/abs/1804.04950}, | |||||
| interhash = {9bf85b0369ba8fdc3234a6ab5c0b0efe}, | |||||
| intrahash = {80f0da037e5fe04038cdadd5f576f2c3}, | |||||
| journal = {CoRR}, | |||||
| keywords = {dblp}, | |||||
| timestamp = {2018-08-14T13:49:28.000+0200}, | |||||
| title = {DeepFM: An End-to-End Wide and Deep Learning Framework for CTR Prediction.}, | |||||
| url = {http://dblp.uni-trier.de/db/journals/corr/corr1804.html#abs-1804-04950}, | |||||
| volume = {abs/1804.04950}, | |||||
| year = 2018 | |||||
| } | |||||
| @inproceedings{Cheng_wideanddeep, | |||||
| added-at = {2018-11-06T00:00:00.000+0100}, | |||||
| author = {Cheng, Heng-Tze and Koc, Levent and Harmsen, Jeremiah and Shaked, Tal and Chandra, Tushar and Aradhye, Hrishi and Anderson, Glen and Corrado, Greg and Chai, Wei and Ispir, Mustafa and Anil, Rohan and Haque, Zakaria and Hong, Lichan and Jain, Vihan and Liu, Xiaobing and Shah, Hemal}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/2efca753e4be0e74da92bf8099da61ea8/dblp}, | |||||
| booktitle = {DLRS@RecSys}, | |||||
| crossref = {conf/recsys/2016dlrs}, | |||||
| editor = {Karatzoglou, Alexandros and Hidasi, Balázs and Tikk, Domonkos and Shalom, Oren Sar and Roitman, Haggai and Shapira, Bracha and Rokach, Lior}, | |||||
| ee = {https://doi.org/10.1145/2988450.2988454}, | |||||
| interhash = {c8766e5f4191faa5750e5e06e508a520}, | |||||
| intrahash = {efca753e4be0e74da92bf8099da61ea8}, | |||||
| isbn = {978-1-4503-4795-2}, | |||||
| keywords = {dblp}, | |||||
| pages = {7-10}, | |||||
| publisher = {ACM}, | |||||
| timestamp = {2018-11-07T12:41:02.000+0100}, | |||||
| title = {Wide and Deep Learning for Recommender Systems.}, | |||||
| url = {http://dblp.uni-trier.de/db/conf/recsys/dlrs2016.html#Cheng0HSCAACCIA16}, | |||||
| year = 2016 | |||||
| } | |||||
| @article{Wang_asae, | |||||
| added-at = {2020-09-22T00:00:00.000+0200}, | |||||
| author = {Wang, Qianqian and Liu, Fang'ai and Xing, Shuning and Zhao, Xiaohui}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/25c758b41e113ef62b5ca3bab13069584/dblp}, | |||||
| ee = {https://www.wikidata.org/entity/Q57300381}, | |||||
| interhash = {55f89635b4315ec35f8b3f946914d866}, | |||||
| intrahash = {5c758b41e113ef62b5ca3bab13069584}, | |||||
| journal = {Comput. Math. Methods Medicine}, | |||||
| keywords = {dblp}, | |||||
| pages = {8056541:1-8056541:11}, | |||||
| timestamp = {2020-09-23T11:34:11.000+0200}, | |||||
| title = {A New Approach for Advertising CTR Prediction Based on Deep Neural Network via Attention Mechanism.}, | |||||
| url = {http://dblp.uni-trier.de/db/journals/cmmm/cmmm2018.html#WangLXZ18}, | |||||
| volume = 2018, | |||||
| year = 2018 | |||||
| } | |||||
| @inproceedings{Ballard_autoencoder, | |||||
| added-at = {2012-12-12T00:00:00.000+0100}, | |||||
| author = {Ballard, Dana H.}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/23a1bf479c829398d544f4ad84e8c7657/dblp}, | |||||
| booktitle = {AAAI}, | |||||
| crossref = {conf/aaai/1987}, | |||||
| editor = {Forbus, Kenneth D. and Shrobe, Howard E.}, | |||||
| ee = {http://www.aaai.org/Library/AAAI/1987/aaai87-050.php}, | |||||
| interhash = {c616c959bdfa632f6961529154757f25}, | |||||
| intrahash = {3a1bf479c829398d544f4ad84e8c7657}, | |||||
| keywords = {dblp}, | |||||
| pages = {279-284}, | |||||
| publisher = {Morgan Kaufmann}, | |||||
| timestamp = {2018-06-21T11:48:19.000+0200}, | |||||
| title = {Modular Learning in Neural Networks.}, | |||||
| url = {http://dblp.uni-trier.de/db/conf/aaai/aaai87.html#Ballard87}, | |||||
| year = 1987 | |||||
| } | |||||
| @book{ShannonWeaver49, | |||||
| added-at = {2008-09-16T23:39:07.000+0200}, | |||||
| address = {Urbana and Chicago}, | |||||
| author = {Shannon, Claude E. and Weaver, Warren}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/2fc189b21087056440c3194e3be26261b/brian.mingus}, | |||||
| booktitle = {The Mathematical Theory of Communication}, | |||||
| description = {CCNLab BibTeX}, | |||||
| interhash = {ddf5810ad302fbd007f99a3b4fb0fae3}, | |||||
| intrahash = {fc189b21087056440c3194e3be26261b}, | |||||
| keywords = {stats}, | |||||
| publisher = {University of Illinois Press}, | |||||
| timestamp = {2008-09-16T23:41:10.000+0200}, | |||||
| title = {The Mathematical Theory of Communication}, | |||||
| year = 1949 | |||||
| } | |||||
| @article{Naumov_embedding_dim, | |||||
| added-at = {2019-01-31T00:00:00.000+0100}, | |||||
| author = {Naumov, Maxim}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/2eccf1f0dfafd15cb01a6fbb1419a6735/dblp}, | |||||
| ee = {http://arxiv.org/abs/1901.02103}, | |||||
| interhash = {25df713996088bf05e247e8f192bb27d}, | |||||
| intrahash = {eccf1f0dfafd15cb01a6fbb1419a6735}, | |||||
| journal = {CoRR}, | |||||
| keywords = {dblp}, | |||||
| timestamp = {2019-02-01T11:37:02.000+0100}, | |||||
| title = {On the Dimensionality of Embeddings for Sparse Features and Data.}, | |||||
| url = {http://dblp.uni-trier.de/db/journals/corr/corr1901.html#abs-1901-02103}, | |||||
| volume = {abs/1901.02103}, | |||||
| year = 2019 | |||||
| } | |||||
| @inproceedings{he2017neural, | |||||
| added-at = {2020-06-21T20:57:25.000+0200}, | |||||
| address = {Republic and Canton of Geneva, CHE}, | |||||
| author = {He, Xiangnan and Liao, Lizi and Zhang, Hanwang and Nie, Liqiang and Hu, Xia and Chua, Tat-Seng}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/26abc7ad98fdfc7d6494a09058988c85b/sdo}, | |||||
| booktitle = {Proceedings of the 26th International Conference on World Wide Web}, | |||||
| doi = {10.1145/3038912.3052569}, | |||||
| interhash = {500610c9f82426e50dbabe0ced94c2e9}, | |||||
| intrahash = {6abc7ad98fdfc7d6494a09058988c85b}, | |||||
| isbn = {9781450349130}, | |||||
| keywords = {collaborative deep factorization feedback filtering implicit learning matrix networks neural}, | |||||
| location = {Perth, Australia}, | |||||
| numpages = {10}, | |||||
| pages = {173–182}, | |||||
| publisher = {International World Wide Web Conferences Steering Committee}, | |||||
| series = {WWW ’17}, | |||||
| timestamp = {2020-06-21T20:57:25.000+0200}, | |||||
| title = {Neural Collaborative Filtering}, | |||||
| url = {https://doi.org/10.1145/3038912.3052569}, | |||||
| year = 2017 | |||||
| } | |||||
| @inproceedings{maas2013leakyrelu, | |||||
| title={Rectifier nonlinearities improve neural network acoustic models}, | |||||
| author={Maas, Andrew L and Hannun, Awni Y and Ng, Andrew Y}, | |||||
| booktitle={Proc. icml}, | |||||
| volume={30}, | |||||
| number={1}, | |||||
| pages={3}, | |||||
| year={2013}, | |||||
| organization={Citeseer} | |||||
| } | |||||
| @article{t-sne, | |||||
| added-at = {2017-01-24T11:10:59.000+0100}, | |||||
| author = {van der Maaten, Laurens and Hinton, Geoffrey}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/28b9aebb404ad4a4c6a436ea413550b30/nosebrain}, | |||||
| interhash = {370ba8b9e1909b61880a6f47c93bcd49}, | |||||
| intrahash = {8b9aebb404ad4a4c6a436ea413550b30}, | |||||
| journal = {Journal of Machine Learning Research}, | |||||
| keywords = {data t-sne visualization}, | |||||
| pages = {2579--2605}, | |||||
| timestamp = {2017-01-24T11:10:59.000+0100}, | |||||
| title = {Visualizing Data using {t-SNE} }, | |||||
| url = {http://www.jmlr.org/papers/v9/vandermaaten08a.html}, | |||||
| volume = 9, | |||||
| year = 2008 | |||||
| } | |||||
| @article{Ginart_MixedDimEmb, | |||||
| added-at = {2019-09-27T00:00:00.000+0200}, | |||||
| author = {Ginart, Antonio and Naumov, Maxim and Mudigere, Dheevatsa and Yang, Jiyan and Zou, James}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/2c5035c95f2b669264227e6d5ce35497a/dblp}, | |||||
| ee = {http://arxiv.org/abs/1909.11810}, | |||||
| interhash = {a2574b7523b570e6928cd2d28506206b}, | |||||
| intrahash = {c5035c95f2b669264227e6d5ce35497a}, | |||||
| journal = {CoRR}, | |||||
| keywords = {dblp}, | |||||
| timestamp = {2019-09-28T11:37:55.000+0200}, | |||||
| title = {Mixed Dimension Embeddings with Application to Memory-Efficient Recommendation Systems.}, | |||||
| url = {http://dblp.uni-trier.de/db/journals/corr/corr1909.html#abs-1909-11810}, | |||||
| volume = {abs/1909.11810}, | |||||
| year = 2019 | |||||
| } | |||||
| @article{choi2020online, | |||||
| added-at = {2020-07-31T00:00:00.000+0200}, | |||||
| author = {Choi, Hana and Mela, Carl F. and Balseiro, Santiago R. and Leary, Adam}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/22abdd5a8fcbecc6f6c6dcff05bd30dd8/dblp}, | |||||
| ee = {https://doi.org/10.1287/isre.2019.0902}, | |||||
| interhash = {4449e1306bf6c274e9d57342192c0bc8}, | |||||
| intrahash = {2abdd5a8fcbecc6f6c6dcff05bd30dd8}, | |||||
| journal = {Inf. Syst. Res.}, | |||||
| keywords = {dblp}, | |||||
| number = 2, | |||||
| pages = {556-575}, | |||||
| timestamp = {2020-08-01T11:38:28.000+0200}, | |||||
| title = {Online Display Advertising Markets: A Literature Review and Future Directions.}, | |||||
| url = {http://dblp.uni-trier.de/db/journals/isr/isr31.html#ChoiMBL20}, | |||||
| volume = 31, | |||||
| year = 2020 | |||||
| } | |||||
| @INPROCEEDINGS{yuan2014survey, author={Yuan, Yong and Wang, Feiyue and Li, Juanjuan and Qin, Rui}, booktitle={Proceedings of 2014 IEEE International Conference on Service Operations and Logistics, and Informatics}, title={A survey on real time bidding advertising}, year={2014}, volume={}, number={}, pages={418-423}, doi={10.1109/SOLI.2014.6960761}} | |||||
| @inproceedings{qin2019revenue, | |||||
| added-at = {2019-10-18T00:00:00.000+0200}, | |||||
| author = {Qin, Rui and Ni, Xiaochun and Yuan, Yong and Li, Juanjuan and Wang, Fei-Yue}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/24e703bb84e53b4b34f5168c32d365ddf/dblp}, | |||||
| booktitle = {SMC}, | |||||
| crossref = {conf/smc/2017}, | |||||
| ee = {https://doi.org/10.1109/SMC.2017.8122644}, | |||||
| interhash = {b57212f4c4a7349707a060f9b3005db9}, | |||||
| intrahash = {4e703bb84e53b4b34f5168c32d365ddf}, | |||||
| isbn = {978-1-5386-1645-1}, | |||||
| keywords = {dblp}, | |||||
| pages = {438-443}, | |||||
| publisher = {IEEE}, | |||||
| timestamp = {2019-10-19T11:40:41.000+0200}, | |||||
| title = {Revenue models for demand side platforms in real time bidding advertising.}, | |||||
| url = {http://dblp.uni-trier.de/db/conf/smc/smc2017.html#QinNYLW17}, | |||||
| year = 2017 | |||||
| } | |||||
| @incollection{reference/ml/LingS17, | |||||
| added-at = {2017-04-18T00:00:00.000+0200}, | |||||
| author = {Ling, Charles X. and Sheng, Victor S.}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/244fcb6ab821f14b0318d4f1c26db9723/dblp}, | |||||
| booktitle = {Encyclopedia of Machine Learning and Data Mining}, | |||||
| crossref = {reference/ml/2017}, | |||||
| editor = {Sammut, Claude and Webb, Geoffrey I.}, | |||||
| ee = {http://dx.doi.org/10.1007/978-1-4899-7687-1_110}, | |||||
| interhash = {e976e365819bfb5007ab4e447b8db77c}, | |||||
| intrahash = {44fcb6ab821f14b0318d4f1c26db9723}, | |||||
| isbn = {978-1-4899-7687-1}, | |||||
| keywords = {dblp}, | |||||
| pages = {204-205}, | |||||
| publisher = {Springer}, | |||||
| timestamp = {2017-04-19T11:47:40.000+0200}, | |||||
| title = {Class Imbalance Problem.}, | |||||
| url = {http://dblp.uni-trier.de/db/reference/ml/ml2017.html#LingS17}, | |||||
| year = 2017 | |||||
| } | |||||
| @misc{pires2019high, | |||||
| title={High dimensionality: The latest challenge to data analysis}, | |||||
| author={A. M. Pires and J. A. Branco}, | |||||
| year={2019}, | |||||
| eprint={1902.04679}, | |||||
| archivePrefix={arXiv}, | |||||
| primaryClass={stat.ME} | |||||
| } | |||||
| @article{journals/eswa/LikaKH14, | |||||
| added-at = {2018-11-14T00:00:00.000+0100}, | |||||
| author = {Lika, Blerina and Kolomvatsos, Kostas and Hadjiefthymiades, Stathes}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/2fc178a46831b1274c383c7f59a6e45a1/dblp}, | |||||
| ee = {https://www.wikidata.org/entity/Q56699601}, | |||||
| interhash = {75c03e661d776a34045e2aa7f6f25623}, | |||||
| intrahash = {fc178a46831b1274c383c7f59a6e45a1}, | |||||
| journal = {Expert Syst. Appl.}, | |||||
| keywords = {dblp}, | |||||
| number = 4, | |||||
| pages = {2065-2073}, | |||||
| timestamp = {2018-11-15T12:09:50.000+0100}, | |||||
| title = {Facing the cold start problem in recommender systems.}, | |||||
| url = {http://dblp.uni-trier.de/db/journals/eswa/eswa41.html#LikaKH14}, | |||||
| volume = 41, | |||||
| year = 2014 | |||||
| } | |||||
| @article{DBLP:journals/corr/abs-1004-3732, | |||||
| author = {Zi{-}Ke Zhang and | |||||
| Chuang Liu and | |||||
| Yi{-}Cheng Zhang and | |||||
| Tao Zhou}, | |||||
| title = {Solving the Cold-Start Problem in Recommender Systems with Social | |||||
| Tags}, | |||||
| journal = {CoRR}, | |||||
| volume = {abs/1004.3732}, | |||||
| year = {2010}, | |||||
| url = {http://arxiv.org/abs/1004.3732}, | |||||
| archivePrefix = {arXiv}, | |||||
| eprint = {1004.3732}, | |||||
| timestamp = {Mon, 13 Aug 2018 16:46:35 +0200}, | |||||
| biburl = {https://dblp.org/rec/journals/corr/abs-1004-3732.bib}, | |||||
| bibsource = {dblp computer science bibliography, https://dblp.org} | |||||
| } | |||||
| @article{journals/corr/ZhangYS17aa, | |||||
| added-at = {2018-11-19T00:00:00.000+0100}, | |||||
| author = {Zhang, Shuai and Yao, Lina and Sun, Aixin}, | |||||
| biburl = {https://www.bibsonomy.org/bibtex/24638a74008191211151c5f5b989deaf6/dblp}, | |||||
| ee = {http://arxiv.org/abs/1707.07435}, | |||||
| interhash = {b9deeb062ab460de31016200e0fe712d}, | |||||
| intrahash = {4638a74008191211151c5f5b989deaf6}, | |||||
| journal = {CoRR}, | |||||
| keywords = {dblp}, | |||||
| timestamp = {2018-11-20T11:37:21.000+0100}, | |||||
| title = {Deep Learning based Recommender System: A Survey and New Perspectives.}, | |||||
| url = {http://dblp.uni-trier.de/db/journals/corr/corr1707.html#ZhangYS17aa}, | |||||
| volume = {abs/1707.07435}, | |||||
| year = 2017 | |||||
| } | |||||
+ 114
- 0
Thesis/references.log
View File
| This is XeTeX, Version 3.14159265-2.6-0.99998 (TeX Live 2017/W32TeX) (preloaded format=xelatex 2019.7.31) 15 FEB 2021 14:38 | |||||
| entering extended mode | |||||
| restricted \write18 enabled. | |||||
| %&-line parsing enabled. | |||||
| **./references.tex | |||||
| (./references.tex | |||||
| LaTeX2e <2017-04-15> | |||||
| Babel <3.10> and hyphenation patterns for 84 language(s) loaded. | |||||
| ! Undefined control sequence. | |||||
| l.6 \phantomsection | |||||
| % hyperref: enable hyperlinking from the table of conten... | |||||
| The control sequence at the end of the top line | |||||
| of your error message was never \def'ed. If you have | |||||
| misspelled it (e.g., `\hobx'), type `I' and the correct | |||||
| spelling (e.g., `I\hbox'). Otherwise just continue, | |||||
| and I'll forget about whatever was undefined. | |||||
| ! LaTeX Error: \bibname undefined. | |||||
| See the LaTeX manual or LaTeX Companion for explanation. | |||||
| Type H <return> for immediate help. | |||||
| ... | |||||
| l.8 \renewcommand{\bibname} | |||||
| {\rl{مراجع}} % title of the bibliography cha... | |||||
| Try typing <return> to proceed. | |||||
| If that doesn't work, type X <return> to quit. | |||||
| ! Undefined control sequence. | |||||
| l.9 \chapter | |||||
| *{مراجع} % custom chapter, because in latin env, title goes... | |||||
| The control sequence at the end of the top line | |||||
| of your error message was never \def'ed. If you have | |||||
| misspelled it (e.g., `\hobx'), type `I' and the correct | |||||
| spelling (e.g., `I\hbox'). Otherwise just continue, | |||||
| and I'll forget about whatever was undefined. | |||||
| ! LaTeX Error: Missing \begin{document}. | |||||
| See the LaTeX manual or LaTeX Companion for explanation. | |||||
| Type H <return> for immediate help. | |||||
| ... | |||||
| l.9 \chapter* | |||||
| {مراجع} % custom chapter, because in latin env, title goes... | |||||
| You're in trouble here. Try typing <return> to proceed. | |||||
| If that doesn't work, type X <return> to quit. | |||||
| Missing character: There is no * in font nullfont! | |||||
| Missing character: There is no م in font nullfont! | |||||
| Missing character: There is no ر in font nullfont! | |||||
| Missing character: There is no ا in font nullfont! | |||||
| Missing character: There is no ج in font nullfont! | |||||
| Missing character: There is no ع in font nullfont! | |||||
| ! LaTeX Error: \chapter undefined. | |||||
| See the LaTeX manual or LaTeX Companion for explanation. | |||||
| Type H <return> for immediate help. | |||||
| ... | |||||
| l.11 \renewcommand{\chapter} | |||||
| [2]{} % disable the automatic chapter | |||||
| Try typing <return> to proceed. | |||||
| If that doesn't work, type X <return> to quit. | |||||
| ! LaTeX Error: Environment latin undefined. | |||||
| See the LaTeX manual or LaTeX Companion for explanation. | |||||
| Type H <return> for immediate help. | |||||
| ... | |||||
| l.12 \begin{latin} | |||||
| % can use \setRTLbibitems in newer versions of xerpersian | |||||
| Your command was ignored. | |||||
| Type I <command> <return> to replace it with another command, | |||||
| or <return> to continue without it. | |||||
| \bibdata{IEEEabrv,references} | |||||
| No file references.bbl. | |||||
| ! LaTeX Error: \begin{document} ended by \end{latin}. | |||||
| See the LaTeX manual or LaTeX Companion for explanation. | |||||
| Type H <return> for immediate help. | |||||
| ... | |||||
| l.14 \end{latin} | |||||
| Your command was ignored. | |||||
| Type I <command> <return> to replace it with another command, | |||||
| or <return> to continue without it. | |||||
| ) | |||||
| ! Emergency stop. | |||||
| <*> ./references.tex | |||||
| *** (job aborted, no legal \end found) | |||||
| Here is how much of TeX's memory you used: | |||||
| 10 strings out of 493005 | |||||
| 89 string characters out of 6132076 | |||||
| 61634 words of memory out of 5000000 | |||||
| 4082 multiletter control sequences out of 15000+600000 | |||||
| 3640 words of font info for 14 fonts, out of 8000000 for 9000 | |||||
| 1348 hyphenation exceptions out of 8191 | |||||
| 8i,0n,6p,189b,35s stack positions out of 5000i,500n,10000p,200000b,80000s | |||||
| No pages of output. |
+ 16
- 0
Thesis/references.tex
View File
| % !TEX encoding = UTF-8 Unicode | |||||
| \bibliographystyle{IEEEtran} %alpha or amsalpha or ieeetr. Control options of this style are put in IEEEtran_biboptions.bib file and activated just after \begin{document} | |||||
| % IEEEtranSA | |||||
| %\printglossaries | |||||
| \cleardoublepage % terminates the current paragraph and page, the same way as a report document. | |||||
| \phantomsection % hyperref: enable hyperlinking from the table of contents to this point | |||||
| \addcontentsline{toc}{chapter}{مراجع} % add a line in the Table of Contents (first option, toc), it will be like the ones created by chapters (second option, chapter) | |||||
| \renewcommand{\bibname}{\rl{مراجع}} % title of the bibliography chapter for the report and book styles. redefine \refname for the references section of an article | |||||
| \chapter*{مراجع} % custom chapter, because in latin env, title goes LTR | |||||
| { %Disable chapter command for bibliography just in this block! | |||||
| \renewcommand{\chapter}[2]{} % disable the automatic chapter | |||||
| \begin{latin} % can use \setRTLbibitems in newer versions of xerpersian | |||||
| \bibliography{IEEEabrv,references} % IEEEtran_biboptions provides the customization options activated before by \bstctlcite | |||||
| \end{latin} | |||||
| } | |||||
| % IEEEtran_biboptions, |
+ 124
- 0
Thesis/sharif-glossary.tex
View File
| % !TEX encoding = UTF-8 Unicode | |||||
| \glsdisablehyper % disable hyperlinks | |||||
| \newglossarystyle{persian-to-english}{% | |||||
| % \glossarystyle{listdotted}% the base style | |||||
| % put the glossary in a two column page and description (as in listdotted style) environment: | |||||
| \renewenvironment{theglossary}% | |||||
| {\begin{multicols}{2}\begingroup \flushleft }% | |||||
| {\endgroup \end{multicols}}% | |||||
| % \renewenvironment{theglossary}{}{}% | |||||
| % have nothing after \begin{theglossary}: | |||||
| \renewcommand*{\glossaryheader}{}% | |||||
| % have nothing between glossary groups: | |||||
| \renewcommand*{\glsgroupheading}[1]{}% | |||||
| \renewcommand*{\glsgroupskip}{}% | |||||
| % set how each entry should appear: \glossaryentryfield{label}{formatted name}{description}{symbol}{number list} | |||||
| \renewcommand*{\glossaryentryfield}[5]{% | |||||
| \glstarget{##1}{##2}% persian term | |||||
| \dotfill%dots | |||||
| \space \lr{##3} \\% | |||||
| % \dotfill% | |||||
| % \space {##5} \\%translation term | |||||
| }% | |||||
| % set how sub-entries appear: | |||||
| \renewcommand*{\glossarysubentryfield}[6]{% | |||||
| \glossaryentryfield{##2}{##3}{##4}{##5}{##6}% | |||||
| }% | |||||
| } | |||||
| % ========= Glossary styles (put in files) ========= | |||||
| \newglossarystyle{english-to-persian}{% | |||||
| % \glossarystyle{listdotted}% the base style | |||||
| % put the glossary in a two column page and description (as in listdotted style) environment: | |||||
| \renewenvironment{theglossary}% | |||||
| {\begin{multicols}{2}\begingroup \flushright }% | |||||
| {\endgroup \end{multicols}}% | |||||
| % \renewenvironment{theglossary}{\Latin{}}{\Persian{}}% | |||||
| % have nothing after \begin{theglossary}: | |||||
| \renewcommand*{\glossaryheader}{}% | |||||
| % have nothing between glossary groups: | |||||
| \renewcommand*{\glsgroupheading}[1]{}% | |||||
| \renewcommand*{\glsgroupskip}{}% | |||||
| % set how each entry should appear: | |||||
| \renewcommand*{\glossaryentryfield}[5]{% | |||||
| \glstarget{##1}{##2}% persian term | |||||
| \dotfill%dots | |||||
| \space \rl{##3} \\%translation term | |||||
| }% | |||||
| % set how sub-entries appear: | |||||
| \renewcommand*{\glossarysubentryfield}[6]{% | |||||
| \glossaryentryfield{##2}{##3}{##4}{##5}{##6}% | |||||
| }% | |||||
| } | |||||
| % ========= GLOSSARIES ========= | |||||
| \newglossary{p2e-terms}{fa.gls}{fa.glo}{واژهنامه فارسی به انگلیسی} % persian to english | |||||
| \newglossary{e2p-terms}{en.gls}{en.glo}{English to Persian Glossary} % english to persian | |||||
| \newcommand{\newtrans}[3][]{% params: persian, english translations, first optional is a key | |||||
| \newtranspl[#1]{#2}{#3}{#2ها}% | |||||
| } | |||||
| \newcommand{\newtranspl}[4][]{% params: persian, english, plural form of persian, first optional is a key | |||||
| \ifthenelse{\isempty{#1}}{\def\key{#2}}{\def\key{#1}}% | |||||
| \newglossaryentry{en:\key}{type={e2p-terms}, name={#3}, description={#2}}% english glossary | |||||
| % \newglossaryentry{fa:\key}{type={p2e-terms}, name={#2}, description={#3}}% persian glossary | |||||
| \newglossaryentry{fa:\key}{type={p2e-terms}, name={#2}, plural={#4}, description={#3}}% persian glossary | |||||
| } | |||||
| % ========= END OF GLOSSARIES ========= | |||||
| % Show a translation and footnote it. | |||||
| % Params (the same as \glsdisplayfirst):{text}{description}{symbol}{insert} | |||||
| % insert can possibly be filled with some notes on the translation. | |||||
| \newcommand{\showTransFirst}[4]{% translation for the first time | |||||
| \ifthenelse{\isempty{#4}}% | |||||
| {\textit{#1}\LTRfootnote{ #2}}% if #4 is empty (no notes) | |||||
| %%%{\textit{#1}\LTRfootnote{{#2} #4}}% if #4 is not empty | |||||
| {\textiranic{#1}\LTRfootnote{{#2} #4}}% if #4 is not empty | |||||
| %{\textit{#1}\footnote{ \lr{#2}؛ #4}}% if #4 is not empty | |||||
| } | |||||
| \newcommand{\showTrans}[4]{% translation for next times | |||||
| \ifthenelse{\isempty{#4}}% | |||||
| {{#1}}% if #4 is empty (no notes) | |||||
| {\textit{#1}\footnote{#4}}% if #4 is not empty | |||||
| } | |||||
| \defglsdisplayfirst[p2e-terms]{\showTransFirst{#1}{#2}{#3}{#4}}% protect fragile commands | |||||
| \defglsdisplay[p2e-terms]{\showTrans{#1}{#2}{#3}{#4}} | |||||
| % Symbol may temporarily used to keep some notes on the translation. | |||||
| % It must be replaced with a user1 key which now raises error, texlive must be upgraded. | |||||
| \newcommand{\term}[2][]{% | |||||
| \glsadd{en:#2}% | |||||
| \ifthenelse{\isempty{#1}}{\gls{fa:#2}}{\gls{fa:#2}[#1]}% | |||||
| } | |||||
| \newcommand{\termpl}[2][]{% | |||||
| \glsadd{en:#2}% | |||||
| \ifthenelse{\isempty{#1}}{\glspl{fa:#2}}{\glspl{fa:#2}[#1]}% | |||||
| } | |||||
| %=========== Print Glossaries =============== | |||||
| % see: http://www.parsilatex.com/forum/SMF/index.php?topic=345.0 | |||||
| %\glossarystyle{persian-to-english} | |||||
| %\def\glossaryname{واژهنامه فارسی به انگلیسی} | |||||
| %\printglossaries | |||||
| \newcommand{\printpersianglossary}[1][واژهنامه فارسی به انگلیسی]{{% | |||||
| \phantomsection % hyperref: enable hyperlinking from the table of contents to this point | |||||
| \addcontentsline{toc}{chapter}{#1} % add a line in the Table of Contents (first option, toc), it will be like the ones | |||||
| \renewcommand{\glossarymark}[1]{\markboth{##1}}% correct handling of page header | |||||
| \printglossary[type={p2e-terms},style={persian-to-english},title={#1}]% | |||||
| }} | |||||
| \newcommand{\printenglishglossary}[1][واژهنامه انگلیسی به فارسی]{{% | |||||
| \phantomsection % hyperref: enable hyperlinking from the table of contents to this point | |||||
| \addcontentsline{toc}{chapter}{#1} % add a line in the Table of Contents (first option, toc), it will be like the ones | |||||
| \renewcommand{\glossarymark}[1]{\markboth{##1}}% correct handling of page header | |||||
| \begin{latin}% | |||||
| \printglossary[type={e2p-terms},style={english-to-persian},title={\rl{#1}}]% | |||||
| \end{latin}% | |||||
| }} | |||||
| % Reset the first-use flag of the transaltion glossareis | |||||
| \newcommand{\resettranslations}{\glsresetall[e2p-terms,p2e-terms]} |
+ 143
- 0
Thesis/sharif-thesis.sty
View File
| % !TEX encoding = UTF-8 Unicode | |||||
| % Originally designed by Jafar Muhammadi and modified by Ali Zarezade | |||||
| \ProvidesPackage{sharif-thesis} | |||||
| %======================================================= | |||||
| % Packages | |||||
| %======================================================= | |||||
| \usepackage{geometry} | |||||
| \usepackage{amsthm,amssymb,amsmath,bm} | |||||
| \usepackage{algorithmic,algorithm} | |||||
| \usepackage{multicol} | |||||
| \usepackage{multirow} | |||||
| \usepackage{graphicx} | |||||
| \usepackage{adjustbox} | |||||
| \usepackage{subfig} | |||||
| \usepackage{fancyhdr} | |||||
| \usepackage[font=small,format=plain]{caption} | |||||
| \usepackage[table]{xcolor} | |||||
| \usepackage{enumerate} | |||||
| \usepackage{setspace} | |||||
| \usepackage{xspace} % to use \xspace | |||||
| \usepackage{shadethm} % shaded theorem | |||||
| \usepackage{xifthen} % used in glossary style | |||||
| \usepackage[hang,splitrule,bottom]{footmisc} % footnote setup | |||||
| \usepackage{zref-perpage} % footnote per-page numbering | |||||
| \usepackage{appendix} % for more control over appendices | |||||
| % Do not change order of the following packages! | |||||
| \usepackage{hyperref} | |||||
| \usepackage[xindy,acronym,nonumberlist=true]{glossaries} | |||||
| \usepackage{xepersian} | |||||
| %======================================================= | |||||
| % General setup | |||||
| %======================================================= | |||||
| \graphicspath{{images/}} | |||||
| %======================================================= | |||||
| % Page setup | |||||
| %======================================================= | |||||
| \geometry{top=3cm,right=3.5cm,bottom=2.5cm,left=2.5cm} | |||||
| %======================================================= | |||||
| % Table of content setup | |||||
| %======================================================= | |||||
| \SepMark{-} | |||||
| \makeatletter | |||||
| \def\@chapter[#1]#2{\ifnum \c@secnumdepth >\m@ne | |||||
| \refstepcounter{chapter}% | |||||
| \typeout{\@chapapp\space\thechapter.}% | |||||
| \addcontentsline{toc}{chapter}% | |||||
| {\@chapapp~\protect\numberline{\thechapter}#1}% | |||||
| \else | |||||
| \addcontentsline{toc}{chapter}{#1}% | |||||
| \fi | |||||
| \chaptermark{#1}% | |||||
| \addtocontents{lof}{\protect\addvspace{10\p@}}% | |||||
| \addtocontents{lot}{\protect\addvspace{10\p@}}% | |||||
| \if@twocolumn | |||||
| \@topnewpage[\@makechapterhead{#2}]% | |||||
| \else | |||||
| \@makechapterhead{#2}% | |||||
| \@afterheading | |||||
| \fi} | |||||
| \renewcommand*\l@section{\@dottedtocline{1}{3.5em}{2.3em}} | |||||
| \renewcommand*\l@subsection{\@dottedtocline{2}{5.8em}{3.2em}} | |||||
| \makeatother | |||||
| %======================================================= | |||||
| % Paragraph setup | |||||
| %======================================================= | |||||
| \linespread{1.3} | |||||
| \setlength{\parindent}{0pt} %The indent of the paragraph first line | |||||
| \setlength{\parskip}{7pt} %Befor paragraph space | |||||
| \frenchspacing | |||||
| %======================================================= | |||||
| % Font setup | |||||
| %======================================================= | |||||
| \settextfont[Scale=1.27,ItalicFont=IRXLotus-Italic]{IRXLotus} | |||||
| \setiranicfont[Scale=1.27]{IRXLotus-Italic} | |||||
| \setdigitfont[Scale=1.27]{IRXLotus} | |||||
| \defpersianfont\nastaliq[Scale=2]{IranNastaliq} | |||||
| \defpersianfont\chapternumber[Scale=3]{HMXYas} | |||||
| \defpersianfont\titr[Scale=1]{HMXTitr} | |||||
| \defpersianfont\titlefont[Scale=1.8]{HMXYas} | |||||
| %======================================================= | |||||
| % Equation setup | |||||
| %======================================================= | |||||
| % use dot instead of dash for equation numbering | |||||
| \renewcommand{\theequation}{\thechapter.\arabic{equation}} | |||||
| %% change equations font size | |||||
| %\DeclareMathSizes{12}{10}{9}{9} | |||||
| %======================================================= | |||||
| % Glossary setup | |||||
| %%======================================================= | |||||
| \newcommand{\trans}[3][]{ | |||||
| \newtrans{#2}{#3}% add to glossary | |||||
| \term[#1]{#2}%cite the added word | |||||
| } | |||||
| %======================================================= | |||||
| % Footnote setup | |||||
| %======================================================= | |||||
| % rest footnote number in each page | |||||
| \zmakeperpage{footnote} | |||||
| \interfootnotelinepenalty=10000 | |||||
| % correct footnote horizontal spacing | |||||
| \addtolength{\footskip}{0cm} | |||||
| \setlength{\footnotemargin}{0.2 cm} | |||||
| \setlength{\footnotesep}{0.3 cm} | |||||
| %======================================================= | |||||
| % Theorem setup | |||||
| %%======================================================= | |||||
| \theoremstyle{definition} | |||||
| \newshadetheorem{theorem}{قضیه} | |||||
| \newshadetheorem{definition}[theorem]{تعریف} | |||||
| \newshadetheorem{proposition}[theorem]{گزاره} | |||||
| \newshadetheorem{lemma}[theorem]{لم} | |||||
| %======================================================= | |||||
| % Header Footer setup | |||||
| %======================================================= | |||||
| \pagestyle{fancy} | |||||
| \fancyhead{} | |||||
| %\fancyfoot{\hline\scriptsize\lr{\copyright} کلیه حقوق این سند محفوظ بوده و متعلق به دانشگاه صنعتی شریف میباشد.} | |||||
| \lhead{\fatitle - \thepage} | |||||
| \rhead{} | |||||
| \lfoot{} | |||||
| \rfoot{} | |||||
+ 21
- 0
Thesis/texput.log
View File
| This is XeTeX, Version 3.14159265-2.6-0.99998 (TeX Live 2017/W32TeX) (preloaded format=xelatex 2019.7.31) 31 JUL 2019 15:26 | |||||
| entering extended mode | |||||
| restricted \write18 enabled. | |||||
| %&-line parsing enabled. | |||||
| **sharif-thesis.tex | |||||
| ! Emergency stop. | |||||
| <*> sharif-thesis.tex | |||||
| *** (job aborted, file error in nonstop mode) | |||||
| Here is how much of TeX's memory you used: | |||||
| 2 strings out of 493005 | |||||
| 23 string characters out of 6132076 | |||||
| 61634 words of memory out of 5000000 | |||||
| 4077 multiletter control sequences out of 15000+600000 | |||||
| 3640 words of font info for 14 fonts, out of 8000000 for 9000 | |||||
| 1348 hyphenation exceptions out of 8191 | |||||
| 0i,0n,0p,1b,6s stack positions out of 5000i,500n,10000p,200000b,80000s | |||||
| No pages of output. |
+ 0
- 0
Thesis/thesis.acn
View File
+ 1
- 0
Thesis/thesis.acr
View File
| \null |
+ 2
- 0
Thesis/thesis.alg
View File
| Warning: File 'thesis.acn' is empty. | |||||
| Have you used any entries defined in glossary 'acronym'? |
+ 58
- 0
Thesis/thesis.aux
View File
| \relax | |||||
| \providecommand\zref@newlabel[2]{} | |||||
| \providecommand\hyper@newdestlabel[2]{} | |||||
| \providecommand\HyperFirstAtBeginDocument{\AtBeginDocument} | |||||
| \HyperFirstAtBeginDocument{\ifx\hyper@anchor\@undefined | |||||
| \global\let\oldcontentsline\contentsline | |||||
| \gdef\contentsline#1#2#3#4{\oldcontentsline{#1}{#2}{#3}} | |||||
| \global\let\oldnewlabel\newlabel | |||||
| \gdef\newlabel#1#2{\newlabelxx{#1}#2} | |||||
| \gdef\newlabelxx#1#2#3#4#5#6{\oldnewlabel{#1}{{#2}{#3}}} | |||||
| \AtEndDocument{\ifx\hyper@anchor\@undefined | |||||
| \let\contentsline\oldcontentsline | |||||
| \let\newlabel\oldnewlabel | |||||
| \fi} | |||||
| \fi} | |||||
| \global\let\hyper@last\relax | |||||
| \gdef\HyperFirstAtBeginDocument#1{#1} | |||||
| \providecommand*\HyPL@Entry[1]{} | |||||
| \@input{cover_fa.aux} | |||||
| \HyPL@Entry{0<</S/D>>} | |||||
| \providecommand \oddpage@label [2]{} | |||||
| \providecommand\@newglossary[4]{} | |||||
| \@newglossary{main}{glg}{gls}{glo} | |||||
| \@newglossary{acronym}{alg}{acr}{acn} | |||||
| \@newglossary{p2e-terms}{glg}{fa.gls}{fa.glo} | |||||
| \@newglossary{e2p-terms}{glg}{en.gls}{en.glo} | |||||
| \providecommand\@glsorder[1]{} | |||||
| \providecommand\@istfilename[1]{} | |||||
| \@istfilename{thesis.xdy} | |||||
| \@glsorder{word} | |||||
| \@input{confirm.aux} | |||||
| \HyPL@Entry{2<</P(\376\377\006\042)>>} | |||||
| \zref@newlabel{footdir@1}{\abspage{3}} | |||||
| \zref@newlabel{zref@1}{\abspage{3}\page{آ}\pagevalue{1}} | |||||
| \zref@newlabel{footdir@3}{\abspage{3}} | |||||
| \zref@newlabel{footdir@2}{\abspage{3}} | |||||
| \HyPL@Entry{3<</P(\376\377\006\050)>>} | |||||
| \HyPL@Entry{4<</P(\376\377\006\176)>>} | |||||
| \HyPL@Entry{5<</P(\376\377\006\052)>>} | |||||
| \HyPL@Entry{6<</P(\376\377\006\053)>>} | |||||
| \HyPL@Entry{7<</S/D>>} | |||||
| \@input{chap1.aux} | |||||
| \@input{chap2.aux} | |||||
| \@input{chap3.aux} | |||||
| \@input{chap4.aux} | |||||
| \@input{chap5.aux} | |||||
| \@input{references.aux} | |||||
| \@writefile{toc}{\contentsline {chapter}{واژهنامه فارسی به انگلیسی}{71}{section*.49}} | |||||
| \@writefile{toc}{\contentsline {chapter}{واژهنامه انگلیسی به فارسی}{74}{section*.52}} | |||||
| \@input{cover_en.aux} | |||||
| \providecommand\@xdylanguage[2]{} | |||||
| \@xdylanguage{p2e-terms}{english} | |||||
| \providecommand\@gls@codepage[2]{} | |||||
| \@gls@codepage{p2e-terms}{utf8} | |||||
| \providecommand\@xdylanguage[2]{} | |||||
| \@xdylanguage{e2p-terms}{english} | |||||
| \providecommand\@gls@codepage[2]{} | |||||
| \@gls@codepage{e2p-terms}{utf8} |
+ 315
- 0
Thesis/thesis.bbl
View File
| % Generated by IEEEtran.bst, version: 1.14 (2015/08/26) | |||||
| \begin{thebibliography}{10} | |||||
| \providecommand{\url}[1]{#1} | |||||
| \csname url@samestyle\endcsname | |||||
| \providecommand{\newblock}{\relax} | |||||
| \providecommand{\bibinfo}[2]{#2} | |||||
| \providecommand{\BIBentrySTDinterwordspacing}{\spaceskip=0pt\relax} | |||||
| \providecommand{\BIBentryALTinterwordstretchfactor}{4} | |||||
| \providecommand{\BIBentryALTinterwordspacing}{\spaceskip=\fontdimen2\font plus | |||||
| \BIBentryALTinterwordstretchfactor\fontdimen3\font minus | |||||
| \fontdimen4\font\relax} | |||||
| \providecommand{\BIBforeignlanguage}[2]{{% | |||||
| \expandafter\ifx\csname l@#1\endcsname\relax | |||||
| \typeout{** WARNING: IEEEtran.bst: No hyphenation pattern has been}% | |||||
| \typeout{** loaded for the language `#1'. Using the pattern for}% | |||||
| \typeout{** the default language instead.}% | |||||
| \else | |||||
| \language=\csname l@#1\endcsname | |||||
| \fi | |||||
| #2}} | |||||
| \providecommand{\BIBdecl}{\relax} | |||||
| \BIBdecl | |||||
| \bibitem{choi2020online} | |||||
| \BIBentryALTinterwordspacing | |||||
| H.~Choi, C.~F. Mela, S.~R. Balseiro, and A.~Leary, ``Online display advertising | |||||
| markets: A literature review and future directions.'' \emph{Inf. Syst. Res.}, | |||||
| vol.~31, no.~2, pp. 556--575, 2020. [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/journals/isr/isr31.html#ChoiMBL20} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{yuan2014survey} | |||||
| Y.~Yuan, F.~Wang, J.~Li, and R.~Qin, ``A survey on real time bidding | |||||
| advertising,'' in \emph{Proceedings of 2014 IEEE International Conference on | |||||
| Service Operations and Logistics, and Informatics}, 2014, pp. 418--423. | |||||
| \bibitem{qin2019revenue} | |||||
| \BIBentryALTinterwordspacing | |||||
| R.~Qin, X.~Ni, Y.~Yuan, J.~Li, and F.-Y. Wang, ``Revenue models for demand side | |||||
| platforms in real time bidding advertising.'' in \emph{SMC}.\hskip 1em plus | |||||
| 0.5em minus 0.4em\relax IEEE, 2017, pp. 438--443. [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/conf/smc/smc2017.html#QinNYLW17} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{reference/ml/LingS17} | |||||
| \BIBentryALTinterwordspacing | |||||
| C.~X. Ling and V.~S. Sheng, ``Class imbalance problem.'' in \emph{Encyclopedia | |||||
| of Machine Learning and Data Mining}, C.~Sammut and G.~I. Webb, Eds.\hskip | |||||
| 1em plus 0.5em minus 0.4em\relax Springer, 2017, pp. 204--205. [Online]. | |||||
| Available: \url{http://dblp.uni-trier.de/db/reference/ml/ml2017.html#LingS17} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{pires2019high} | |||||
| A.~M. Pires and J.~A. Branco, ``High dimensionality: The latest challenge to | |||||
| data analysis,'' 2019. | |||||
| \bibitem{journals/eswa/LikaKH14} | |||||
| \BIBentryALTinterwordspacing | |||||
| B.~Lika, K.~Kolomvatsos, and S.~Hadjiefthymiades, ``Facing the cold start | |||||
| problem in recommender systems.'' \emph{Expert Syst. Appl.}, vol.~41, no.~4, | |||||
| pp. 2065--2073, 2014. [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/journals/eswa/eswa41.html#LikaKH14} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{DBLP:journals/corr/abs-1004-3732} | |||||
| \BIBentryALTinterwordspacing | |||||
| Z.~Zhang, C.~Liu, Y.~Zhang, and T.~Zhou, ``Solving the cold-start problem in | |||||
| recommender systems with social tags,'' \emph{CoRR}, vol. abs/1004.3732, | |||||
| 2010. [Online]. Available: \url{http://arxiv.org/abs/1004.3732} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{boser1992} | |||||
| \BIBentryALTinterwordspacing | |||||
| B.~E. Boser, I.~M. Guyon, and V.~N. Vapnik, ``A training algorithm for optimal | |||||
| margin classifiers,'' in \emph{Proceedings of the 5th Annual Workshop on | |||||
| Computational Learning Theory (COLT'92)}, D.~Haussler, Ed.\hskip 1em plus | |||||
| 0.5em minus 0.4em\relax Pittsburgh, PA, USA: ACM Press, July 1992, pp. | |||||
| 144--152. [Online]. Available: \url{http://doi.acm.org/10.1145/130385.130401} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{Gai_piecewise} | |||||
| \BIBentryALTinterwordspacing | |||||
| K.~Gai, X.~Zhu, H.~Li, K.~Liu, and Z.~Wang, ``Learning piece-wise linear models | |||||
| from large scale data for ad click prediction.'' \emph{CoRR}, vol. | |||||
| abs/1704.05194, 2017. [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/journals/corr/corr1704.html#GaiZLLW17} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{lecun_sgd} | |||||
| Y.~LeCun, L.~Bottou, Y.~Bengio, and P.~Haffner, ``Gradient-based learning | |||||
| applied to document recognition,'' \emph{Proceedings of the IEEE}, vol.~86, | |||||
| no.~11, pp. 2278--2324, 1998. | |||||
| \bibitem{lbfgs_2008} | |||||
| \BIBentryALTinterwordspacing | |||||
| Y.~Xiao, Z.~Wei, and Z.~Wang, ``A limited memory bfgs-type method for | |||||
| large-scale unconstrained optimization.'' \emph{Comput. Math. Appl.}, | |||||
| vol.~56, no.~4, pp. 1001--1009, 2008. [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/journals/cma/cma56.html#XiaoWW08} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{Graepel_2010} | |||||
| \BIBentryALTinterwordspacing | |||||
| T.~Graepel, J.~Q. Candela, T.~Borchert, and R.~Herbrich, ``Web-scale bayesian | |||||
| click-through rate prediction for sponsored search advertising in microsoft's | |||||
| bing search engine.'' in \emph{ICML}, J.~Fürnkranz and T.~Joachims, | |||||
| Eds.\hskip 1em plus 0.5em minus 0.4em\relax Omnipress, 2010, pp. 13--20. | |||||
| [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/conf/icml/icml2010.html#GraepelCBH10} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{Rendle:2010ja} | |||||
| \BIBentryALTinterwordspacing | |||||
| S.~Rendle, ``{Factorization Machines},'' in \emph{Proceedings of the 2010 IEEE | |||||
| International Conference on Data Mining}, ser. ICDM '10.\hskip 1em plus 0.5em | |||||
| minus 0.4em\relax IEEE, Dec. 2010, pp. 995--1000. [Online]. Available: | |||||
| \url{http://ieeexplore.ieee.org/document/5694074/} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{Juan_fieldawarefm1} | |||||
| \BIBentryALTinterwordspacing | |||||
| Y.-C. Juan, Y.~Zhuang, W.-S. Chin, and C.-J. Lin, ``Field-aware factorization | |||||
| machines for ctr prediction.'' in \emph{RecSys}, S.~Sen, W.~Geyer, J.~Freyne, | |||||
| and P.~Castells, Eds.\hskip 1em plus 0.5em minus 0.4em\relax ACM, 2016, pp. | |||||
| 43--50. [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/conf/recsys/recsys2016.html#JuanZCL16} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{Juan_fieldawarefm2} | |||||
| \BIBentryALTinterwordspacing | |||||
| Y.~Juan, D.~Lefortier, and O.~Chapelle, ``Field-aware factorization machines in | |||||
| a real-world online advertising system.'' \emph{CoRR}, vol. abs/1701.04099, | |||||
| 2017. [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/journals/corr/corr1701.html#JuanLC17} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{Pan_fieldweightedfm} | |||||
| \BIBentryALTinterwordspacing | |||||
| J.~Pan, J.~Xu, A.~L. Ruiz, W.~Zhao, S.~Pan, Y.~Sun, and Q.~Lu, ``Field-weighted | |||||
| factorization machines for click-through rate prediction in display | |||||
| advertising.'' \emph{CoRR}, vol. abs/1806.03514, 2018. [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/journals/corr/corr1806.html#abs-1806-03514} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{Freudenthaler2011BayesianFM} | |||||
| S.-T.~L. Freudenthaler, C. and S.~Rendle, ``Bayesian factorization machines,'' | |||||
| in \emph{In Proceedings of the NIPS Workshop on Sparse Representation and | |||||
| Low-rank Approximation}, 2011. | |||||
| \bibitem{Pan_sparsefm} | |||||
| \BIBentryALTinterwordspacing | |||||
| Z.~Pan, E.~Chen, Q.~Liu, T.~Xu, H.~Ma, and H.~Lin, ``Sparse factorization | |||||
| machines for click-through rate prediction.'' in \emph{ICDM}, F.~Bonchi, | |||||
| J.~Domingo-Ferrer, R.~Baeza-Yates, Z.-H. Zhou, and X.~Wu, Eds.\hskip 1em plus | |||||
| 0.5em minus 0.4em\relax IEEE Computer Society, 2016, pp. 400--409. [Online]. | |||||
| Available: | |||||
| \url{http://dblp.uni-trier.de/db/conf/icdm/icdm2016.html#PanCLXML16} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{Xiao_afm} | |||||
| \BIBentryALTinterwordspacing | |||||
| J.~Xiao, H.~Ye, X.~He, H.~Zhang, F.~Wu, and T.-S. Chua, ``Attentional | |||||
| factorization machines: Learning the weight of feature interactions via | |||||
| attention networks.'' \emph{CoRR}, vol. abs/1708.04617, 2017. [Online]. | |||||
| Available: | |||||
| \url{http://dblp.uni-trier.de/db/journals/corr/corr1708.html#abs-1708-04617} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{srivastava2014dropout} | |||||
| \BIBentryALTinterwordspacing | |||||
| N.~Srivastava, G.~Hinton, A.~Krizhevsky, I.~Sutskever, and R.~Salakhutdinov, | |||||
| ``{Dropout: A Simple Way to Prevent Neural Networks from Overfitting},'' | |||||
| \emph{J. Mach. Learn. Res.}, vol.~15, no.~1, pp. 1929--1958, Jan. 2014. | |||||
| [Online]. Available: \url{http://portal.acm.org/citation.cfm?id=2670313} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{tikhonov1943stability} | |||||
| A.~N. Tikhonov, ``On the stability of inverse problems,'' in \emph{Dokl. Akad. | |||||
| Nauk SSSR}, vol.~39, 1943, pp. 195--198. | |||||
| \bibitem{journals/corr/ZhangYS17aa} | |||||
| \BIBentryALTinterwordspacing | |||||
| S.~Zhang, L.~Yao, and A.~Sun, ``Deep learning based recommender system: A | |||||
| survey and new perspectives.'' \emph{CoRR}, vol. abs/1707.07435, 2017. | |||||
| [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/journals/corr/corr1707.html#ZhangYS17aa} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{Chen_deepctr} | |||||
| \BIBentryALTinterwordspacing | |||||
| J.~Chen, B.~Sun, H.~Li, H.~Lu, and X.-S. Hua, ``Deep ctr prediction in display | |||||
| advertising.'' in \emph{ACM Multimedia}, A.~Hanjalic, C.~Snoek, M.~Worring, | |||||
| D.~C.~A. Bulterman, B.~Huet, A.~Kelliher, Y.~Kompatsiaris, and J.~Li, | |||||
| Eds.\hskip 1em plus 0.5em minus 0.4em\relax ACM, 2016, pp. 811--820. | |||||
| [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/conf/mm/mm2016.html#ChenSLLH16} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{he2015residual} | |||||
| \BIBentryALTinterwordspacing | |||||
| K.~He, X.~Zhang, S.~Ren, and J.~Sun, ``Deep residual learning for image | |||||
| recognition,'' 2015, cite arxiv:1512.03385Comment: Tech report. [Online]. | |||||
| Available: \url{http://arxiv.org/abs/1512.03385} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{Nair_relu} | |||||
| \BIBentryALTinterwordspacing | |||||
| V.~Nair and G.~E. Hinton, ``Rectified linear units improve restricted boltzmann | |||||
| machines.'' in \emph{ICML}, J.~Fürnkranz and T.~Joachims, Eds.\hskip 1em | |||||
| plus 0.5em minus 0.4em\relax Omnipress, 2010, pp. 807--814. [Online]. | |||||
| Available: \url{http://dblp.uni-trier.de/db/conf/icml/icml2010.html#NairH10} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{Guo_embedding_2016} | |||||
| \BIBentryALTinterwordspacing | |||||
| C.~Guo and F.~Berkhahn, ``Entity embeddings of categorical variables.'' | |||||
| \emph{CoRR}, vol. abs/1604.06737, 2016. [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/journals/corr/corr1604.html#GuoB16} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{ioffe2015batch} | |||||
| \BIBentryALTinterwordspacing | |||||
| S.~Ioffe and C.~Szegedy, ``Batch normalization: Accelerating deep network | |||||
| training by reducing internal covariate shift,'' 2015, cite arxiv:1502.03167. | |||||
| [Online]. Available: \url{http://arxiv.org/abs/1502.03167} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{Guo_deepfm1} | |||||
| \BIBentryALTinterwordspacing | |||||
| H.~Guo, R.~Tang, Y.~Ye, Z.~Li, and X.~He, ``Deepfm: A factorization-machine | |||||
| based neural network for ctr prediction.'' in \emph{IJCAI}, C.~Sierra, | |||||
| Ed.\hskip 1em plus 0.5em minus 0.4em\relax ijcai.org, 2017, pp. 1725--1731. | |||||
| [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/conf/ijcai/ijcai2017.html#GuoTYLH17} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{Guo_deepfm2} | |||||
| \BIBentryALTinterwordspacing | |||||
| H.~Guo, R.~Tang, Y.~Ye, Z.~Li, X.~He, and Z.~Dong, ``Deepfm: An end-to-end wide | |||||
| and deep learning framework for ctr prediction.'' \emph{CoRR}, vol. | |||||
| abs/1804.04950, 2018. [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/journals/corr/corr1804.html#abs-1804-04950} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{Cheng_wideanddeep} | |||||
| \BIBentryALTinterwordspacing | |||||
| H.-T. Cheng, L.~Koc, J.~Harmsen, T.~Shaked, T.~Chandra, H.~Aradhye, | |||||
| G.~Anderson, G.~Corrado, W.~Chai, M.~Ispir, R.~Anil, Z.~Haque, L.~Hong, | |||||
| V.~Jain, X.~Liu, and H.~Shah, ``Wide and deep learning for recommender | |||||
| systems.'' in \emph{DLRS@RecSys}, A.~Karatzoglou, B.~Hidasi, D.~Tikk, O.~S. | |||||
| Shalom, H.~Roitman, B.~Shapira, and L.~Rokach, Eds.\hskip 1em plus 0.5em | |||||
| minus 0.4em\relax ACM, 2016, pp. 7--10. [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/conf/recsys/dlrs2016.html#Cheng0HSCAACCIA16} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{Wang_asae} | |||||
| \BIBentryALTinterwordspacing | |||||
| Q.~Wang, F.~Liu, S.~Xing, and X.~Zhao, ``A new approach for advertising ctr | |||||
| prediction based on deep neural network via attention mechanism.'' | |||||
| \emph{Comput. Math. Methods Medicine}, vol. 2018, pp. | |||||
| 8\,056\,541:1--8\,056\,541:11, 2018. [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/journals/cmmm/cmmm2018.html#WangLXZ18} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{Ballard_autoencoder} | |||||
| \BIBentryALTinterwordspacing | |||||
| D.~H. Ballard, ``Modular learning in neural networks.'' in \emph{AAAI}, K.~D. | |||||
| Forbus and H.~E. Shrobe, Eds.\hskip 1em plus 0.5em minus 0.4em\relax Morgan | |||||
| Kaufmann, 1987, pp. 279--284. [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/conf/aaai/aaai87.html#Ballard87} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{ShannonWeaver49} | |||||
| C.~E. Shannon and W.~Weaver, \emph{The Mathematical Theory of | |||||
| Communication}.\hskip 1em plus 0.5em minus 0.4em\relax Urbana and Chicago: | |||||
| University of Illinois Press, 1949. | |||||
| \bibitem{Naumov_embedding_dim} | |||||
| \BIBentryALTinterwordspacing | |||||
| M.~Naumov, ``On the dimensionality of embeddings for sparse features and | |||||
| data.'' \emph{CoRR}, vol. abs/1901.02103, 2019. [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/journals/corr/corr1901.html#abs-1901-02103} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{Ginart_MixedDimEmb} | |||||
| \BIBentryALTinterwordspacing | |||||
| A.~Ginart, M.~Naumov, D.~Mudigere, J.~Yang, and J.~Zou, ``Mixed dimension | |||||
| embeddings with application to memory-efficient recommendation systems.'' | |||||
| \emph{CoRR}, vol. abs/1909.11810, 2019. [Online]. Available: | |||||
| \url{http://dblp.uni-trier.de/db/journals/corr/corr1909.html#abs-1909-11810} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{he2017neural} | |||||
| \BIBentryALTinterwordspacing | |||||
| X.~He, L.~Liao, H.~Zhang, L.~Nie, X.~Hu, and T.-S. Chua, ``Neural collaborative | |||||
| filtering,'' in \emph{Proceedings of the 26th International Conference on | |||||
| World Wide Web}, ser. WWW ’17.\hskip 1em plus 0.5em minus 0.4em\relax | |||||
| Republic and Canton of Geneva, CHE: International World Wide Web Conferences | |||||
| Steering Committee, 2017, p. 173–182. [Online]. Available: | |||||
| \url{https://doi.org/10.1145/3038912.3052569} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \bibitem{maas2013leakyrelu} | |||||
| A.~L. Maas, A.~Y. Hannun, and A.~Y. Ng, ``Rectifier nonlinearities improve | |||||
| neural network acoustic models,'' in \emph{Proc. icml}, vol.~30, no.~1.\hskip | |||||
| 1em plus 0.5em minus 0.4em\relax Citeseer, 2013, p.~3. | |||||
| \bibitem{t-sne} | |||||
| \BIBentryALTinterwordspacing | |||||
| L.~van~der Maaten and G.~Hinton, ``Visualizing data using {t-SNE},'' | |||||
| \emph{Journal of Machine Learning Research}, vol.~9, pp. 2579--2605, 2008. | |||||
| [Online]. Available: \url{http://www.jmlr.org/papers/v9/vandermaaten08a.html} | |||||
| \BIBentrySTDinterwordspacing | |||||
| \end{thebibliography} |
+ 100
- 0
Thesis/thesis.blg
View File
| This is BibTeX, Version 0.99d (TeX Live 2017/W32TeX) | |||||
| Capacity: max_strings=100000, hash_size=100000, hash_prime=85009 | |||||
| The top-level auxiliary file: thesis.aux | |||||
| A level-1 auxiliary file: cover_fa.aux | |||||
| A level-1 auxiliary file: confirm.aux | |||||
| A level-1 auxiliary file: chap1.aux | |||||
| A level-1 auxiliary file: chap2.aux | |||||
| A level-1 auxiliary file: chap3.aux | |||||
| A level-1 auxiliary file: chap4.aux | |||||
| A level-1 auxiliary file: chap5.aux | |||||
| A level-1 auxiliary file: references.aux | |||||
| The style file: IEEEtran.bst | |||||
| A level-1 auxiliary file: cover_en.aux | |||||
| Reallocated singl_function (elt_size=4) to 100 items from 50. | |||||
| Reallocated singl_function (elt_size=4) to 100 items from 50. | |||||
| Reallocated singl_function (elt_size=4) to 100 items from 50. | |||||
| Reallocated wiz_functions (elt_size=4) to 6000 items from 3000. | |||||
| Reallocated singl_function (elt_size=4) to 100 items from 50. | |||||
| Database file #1: IEEEabrv.bib | |||||
| Database file #2: references.bib | |||||
| A bad cross reference---entry "qin2019revenue" | |||||
| refers to entry "conf/smc/2017", which doesn't exist | |||||
| A bad cross reference---entry "reference/ml/LingS17" | |||||
| refers to entry "reference/ml/2017", which doesn't exist | |||||
| A bad cross reference---entry "Graepel_2010" | |||||
| refers to entry "conf/icml/2010", which doesn't exist | |||||
| A bad cross reference---entry "Juan_fieldawarefm1" | |||||
| refers to entry "conf/recsys/2016", which doesn't exist | |||||
| A bad cross reference---entry "Pan_sparsefm" | |||||
| refers to entry "conf/icdm/2016", which doesn't exist | |||||
| A bad cross reference---entry "Chen_deepctr" | |||||
| refers to entry "conf/mm/2016", which doesn't exist | |||||
| A bad cross reference---entry "Nair_relu" | |||||
| refers to entry "conf/icml/2010", which doesn't exist | |||||
| A bad cross reference---entry "Guo_deepfm1" | |||||
| refers to entry "conf/ijcai/2017", which doesn't exist | |||||
| A bad cross reference---entry "Cheng_wideanddeep" | |||||
| refers to entry "conf/recsys/2016dlrs", which doesn't exist | |||||
| A bad cross reference---entry "Ballard_autoencoder" | |||||
| refers to entry "conf/aaai/1987", which doesn't exist | |||||
| Warning--I didn't find a database entry for "conf/icml/2010" | |||||
| Warning--I didn't find a database entry for "conf/recsys/2016" | |||||
| Warning--I didn't find a database entry for "conf/icdm/2016" | |||||
| Warning--I didn't find a database entry for "conf/mm/2016" | |||||
| Warning--I didn't find a database entry for "conf/ijcai/2017" | |||||
| Warning--I didn't find a database entry for "conf/recsys/2016dlrs" | |||||
| Warning--I didn't find a database entry for "conf/aaai/1987" | |||||
| Warning--I didn't find a database entry for "conf/smc/2017" | |||||
| Warning--I didn't find a database entry for "reference/ml/2017" | |||||
| -- IEEEtran.bst version 1.14 (2015/08/26) by Michael Shell. | |||||
| -- http://www.michaelshell.org/tex/ieeetran/bibtex/ | |||||
| -- See the "IEEEtran_bst_HOWTO.pdf" manual for usage information. | |||||
| Name 1 in "Freudenthaler, C., Schmidt-Thieme, L., and Rendle, S" has a comma at the end for entry Freudenthaler2011BayesianFM | |||||
| while executing---line 2403 of file IEEEtran.bst | |||||
| Too many commas in name 1 of "Freudenthaler, C., Schmidt-Thieme, L., and Rendle, S" for entry Freudenthaler2011BayesianFM | |||||
| while executing---line 2403 of file IEEEtran.bst | |||||
| Done. | |||||
| You've used 38 entries, | |||||
| 4087 wiz_defined-function locations, | |||||
| 1485 strings with 24219 characters, | |||||
| and the built_in function-call counts, 32317 in all, are: | |||||
| = -- 2540 | |||||
| > -- 937 | |||||
| < -- 219 | |||||
| + -- 503 | |||||
| - -- 193 | |||||
| * -- 1649 | |||||
| := -- 4910 | |||||
| add.period$ -- 90 | |||||
| call.type$ -- 38 | |||||
| change.case$ -- 59 | |||||
| chr.to.int$ -- 513 | |||||
| cite$ -- 38 | |||||
| duplicate$ -- 2249 | |||||
| empty$ -- 2575 | |||||
| format.name$ -- 223 | |||||
| if$ -- 7486 | |||||
| int.to.chr$ -- 0 | |||||
| int.to.str$ -- 38 | |||||
| missing$ -- 438 | |||||
| newline$ -- 199 | |||||
| num.names$ -- 58 | |||||
| pop$ -- 1057 | |||||
| preamble$ -- 1 | |||||
| purify$ -- 0 | |||||
| quote$ -- 2 | |||||
| skip$ -- 2459 | |||||
| stack$ -- 0 | |||||
| substring$ -- 1287 | |||||
| swap$ -- 1830 | |||||
| text.length$ -- 48 | |||||
| text.prefix$ -- 0 | |||||
| top$ -- 5 | |||||
| type$ -- 38 | |||||
| warning$ -- 0 | |||||
| while$ -- 118 | |||||
| width$ -- 40 | |||||
| write$ -- 477 | |||||
| (There were 12 error messages) |
+ 0
- 0
Thesis/thesis.en.glo
View File
Some files were not shown because too many files changed in this diff
Loading…