
commit
6400586fcc
100 changed files with 27905 additions and 0 deletions
+ 6
- 0
.gitignore
View File
| @@ -0,0 +1,6 @@ | |||
| datasets/ | |||
| __pycache__ | |||
| .ipynb_checkpoints | |||
| wandb | |||
| lab/ | |||
+ 1201
- 0
01_ResidualPrompt/00_bert_ah.ipynb
File diff suppressed because it is too large
View File
+ 1539
- 0
01_ResidualPrompt/01_bert_custom.ipynb
File diff suppressed because it is too large
View File
+ 1444
- 0
01_ResidualPrompt/02_gpt_custom.ipynb
File diff suppressed because it is too large
View File
+ 12457
- 0
01_ResidualPrompt/03_gpt_hf_peft.ipynb
File diff suppressed because it is too large
View File
+ 1113
- 0
01_ResidualPrompt/04_T5_custom.ipynb
File diff suppressed because it is too large
View File
+ 115
- 0
01_ResidualPrompt/04_T5_custom.py
View File
| @@ -0,0 +1,115 @@ | |||
| from typing import Optional | |||
| import numpy as np | |||
| from tqdm import tqdm | |||
| import wandb | |||
| import torch | |||
| import torch.nn as nn | |||
| from transformers import T5TokenizerFast, T5ForConditionalGeneration | |||
| from _config import load_config | |||
| from _utils import print_system_info, silent_logs | |||
| from _datasets import AutoLoad, generate_dataloader | |||
| from _mydelta import T5Wrapper, auto_freeze, EmbeddingWrapper | |||
| from _trainer import train_loop, valid_loop, BestFinder | |||
| configs = load_config('./config.yaml') | |||
| RANDOM_SEED = configs.shared.random_seed | |||
| WANDB_PROJECT_NAME = configs.shared.project_name | |||
| DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") | |||
| USE_TQDM = configs.shared.use_tqdm | |||
| def run_experminent(config): | |||
| np.random.seed(RANDOM_SEED) | |||
| # ______________________LOAD MODEL_____________________________ | |||
| model = T5ForConditionalGeneration.from_pretrained(config.model_name) | |||
| tokenizer = T5TokenizerFast.from_pretrained(config.model_name, model_max_length=2048) | |||
| # ______________________MUTATE MODEL_____________________________ | |||
| if config.peft_params is not None: | |||
| peft_params = config.peft_params.to_dict() | |||
| slected_tokens = torch.from_numpy( | |||
| np.random.randint(0, tokenizer.vocab_size, size=(peft_params['n_tokens'],)) | |||
| ) | |||
| peft_class = { | |||
| 't5_encoder': T5Wrapper, | |||
| 'encoder_emb': EmbeddingWrapper | |||
| }[peft_params.pop('kind')] | |||
| delta_module = peft_class.mutate( | |||
| model=model, | |||
| slected_tokens=slected_tokens, | |||
| **peft_params | |||
| ) | |||
| elif config.best_finder.save: | |||
| raise NotImplementedError() | |||
| freeze_notes = auto_freeze(model, config.hot_modules) | |||
| # ______________________LOAD DATA_____________________________ | |||
| data_loader = AutoLoad(tokenizer) | |||
| dataset = data_loader.get_and_map(config.tasks[0]) | |||
| train_loader, valid_loader = generate_dataloader(tokenizer, dataset['train'], dataset['valid'], config) | |||
| # ______________________TRAIN_____________________________ | |||
| wandb.init( | |||
| name=config.wandb_name, | |||
| project=WANDB_PROJECT_NAME, | |||
| config=config.to_dict(), | |||
| notes=freeze_notes | |||
| ) | |||
| optimizer = torch.optim.AdamW(model.parameters(), lr=config.learning_rate) | |||
| best_finder = BestFinder(config.best_finder.higher_better) | |||
| model.to(DEVICE) | |||
| epochs_range = range(config.num_epochs) | |||
| if USE_TQDM: | |||
| epochs_range = tqdm(epochs_range, position=1, desc="EPOCHS", leave=False) | |||
| for epoch in epochs_range: | |||
| epoch_results = {} | |||
| epoch_results.update( | |||
| train_loop( | |||
| model=model, | |||
| loader=train_loader, | |||
| optimizer=optimizer, | |||
| use_tqdm=USE_TQDM | |||
| ) | |||
| ) | |||
| epoch_results.update( | |||
| valid_loop( | |||
| model=model, | |||
| loader=valid_loader, | |||
| use_tqdm=USE_TQDM | |||
| ) | |||
| ) | |||
| if config.best_finder.save: | |||
| if best_finder.is_better(epoch_results[config.best_finder.metric]): | |||
| torch.save(delta_module.peft_state_dict(), './best.pt') | |||
| wandb.log(epoch_results) | |||
| wandb.finish() | |||
| if __name__ == '__main__': | |||
| print_system_info() | |||
| silent_logs() | |||
| run_configs = configs.run_configs | |||
| if USE_TQDM: | |||
| run_configs = tqdm(run_configs, position=0, desc="Experiment") | |||
| for run_config in run_configs: | |||
| run_experminent(run_config) | |||
+ 111
- 0
01_ResidualPrompt/05_T5_custom_finetune.py
View File
| @@ -0,0 +1,111 @@ | |||
| from typing import Optional | |||
| import numpy as np | |||
| from tqdm import tqdm | |||
| import wandb | |||
| import torch | |||
| import torch.nn as nn | |||
| from transformers import T5TokenizerFast, T5ForConditionalGeneration | |||
| from _config import load_config | |||
| from _utils import print_system_info, silent_logs | |||
| from _datasets import AutoLoad, generate_dataloader | |||
| from _mydelta import T5Wrapper, auto_freeze, EmbeddingWrapper | |||
| from _trainer import train_loop, valid_loop | |||
| configs = load_config('./config.yaml') | |||
| RANDOM_SEED = configs.shared.random_seed | |||
| WANDB_PROJECT_NAME = configs.shared.project_name | |||
| DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") | |||
| USE_TQDM = configs.shared.use_tqdm | |||
| def run_experminent(config): | |||
| np.random.seed(RANDOM_SEED) | |||
| # ______________________LOAD MODEL_____________________________ | |||
| model = T5ForConditionalGeneration.from_pretrained(config.model_name) | |||
| tokenizer = T5TokenizerFast.from_pretrained(config.model_name, model_max_length=2048) | |||
| # ______________________MUTATE MODEL_____________________________ | |||
| if config.peft_params is not None: | |||
| peft_params = config.peft_params.to_dict() | |||
| slected_tokens = torch.from_numpy( | |||
| np.random.randint(0, tokenizer.vocab_size, size=(peft_params['n_tokens'],)) | |||
| ) | |||
| peft_class = { | |||
| 't5_encoder': T5Wrapper, | |||
| 'encoder_emb': EmbeddingWrapper | |||
| }[peft_params.pop('kind')] | |||
| delta_module = peft_class.mutate( | |||
| model=model, | |||
| slected_tokens=slected_tokens, | |||
| **peft_params | |||
| ) | |||
| loaded_weights = torch.load('./best.pt') | |||
| loaded_weights.pop('sadcl_learned_embedding') | |||
| delta_module.load_peft_state_dict(loaded_weights) | |||
| freeze_notes = auto_freeze(model, config.hot_modules) | |||
| # ______________________LOAD DATA_____________________________ | |||
| data_loader = AutoLoad(tokenizer) | |||
| dataset = data_loader.get_and_map(config.tasks[0]) | |||
| train_loader, valid_loader = generate_dataloader(tokenizer, dataset['train'], dataset['valid'], config) | |||
| # ______________________TRAIN_____________________________ | |||
| wandb.init( | |||
| name=config.wandb_name, | |||
| project=WANDB_PROJECT_NAME, | |||
| config=config.to_dict(), | |||
| notes=freeze_notes | |||
| ) | |||
| optimizer = torch.optim.AdamW(model.parameters(), lr=config.learning_rate) | |||
| model.to(DEVICE) | |||
| epochs_range = range(config.num_epochs) | |||
| if USE_TQDM: | |||
| epochs_range = tqdm(epochs_range, position=1, desc="EPOCHS", leave=False) | |||
| for epoch in epochs_range: | |||
| epoch_results = {} | |||
| epoch_results.update( | |||
| train_loop( | |||
| model=model, | |||
| loader=train_loader, | |||
| optimizer=optimizer, | |||
| use_tqdm=USE_TQDM | |||
| ) | |||
| ) | |||
| epoch_results.update( | |||
| valid_loop( | |||
| model=model, | |||
| loader=valid_loader, | |||
| use_tqdm=USE_TQDM | |||
| ) | |||
| ) | |||
| wandb.log(epoch_results) | |||
| wandb.finish() | |||
| if __name__ == '__main__': | |||
| print_system_info() | |||
| silent_logs() | |||
| run_configs = configs.run_configs | |||
| if USE_TQDM: | |||
| run_configs = tqdm(run_configs, position=0, desc="Experiment") | |||
| for run_config in run_configs: | |||
| run_experminent(run_config) | |||
+ 105
- 0
01_ResidualPrompt/config.yaml
View File
| @@ -0,0 +1,105 @@ | |||
| shared: | |||
| project_name: continual_prompt_pretrained_mlp | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| default: &default | |||
| model_name: google/t5-large-lm-adapt | |||
| wandb_name: null | |||
| train_batch_size: 32 | |||
| valid_batch_size: 32 | |||
| num_epochs: 100 | |||
| peft_params: null # no mutation | |||
| hot_modules: null # fine-tune all | |||
| balancify_train: false | |||
| best_finder: | |||
| save: true | |||
| metric: valid_f1-score-ma | |||
| higher_better: true | |||
| tasks: | |||
| - glue:cola | |||
| run_configs: | |||
| # - <<: *default | |||
| # wandb_name: large_5t_mlp128 | |||
| # learning_rate: 0.02 | |||
| # hot_modules: | |||
| # - sadcl_learned_embeddin | |||
| # train_batch_size: 24 | |||
| # valid_batch_size: 24 | |||
| # peft_params: | |||
| # kind: encoder_emb | |||
| # n_tokens: 5 | |||
| # mlp_emb: 128 | |||
| # - <<: *default | |||
| # wandb_name: large_10t_mlp128 | |||
| # learning_rate: 0.02 | |||
| # hot_modules: | |||
| # - sadcl_learned_embeddin | |||
| # train_batch_size: 24 | |||
| # valid_batch_size: 24 | |||
| # peft_params: | |||
| # kind: encoder_emb | |||
| # n_tokens: 10 | |||
| # mlp_emb: 128 | |||
| # - <<: *default | |||
| # wandb_name: large_5t_mlp128_not_freeze | |||
| # learning_rate: 0.02 | |||
| # hot_modules: | |||
| # - sadcl | |||
| # train_batch_size: 24 | |||
| # valid_batch_size: 24 | |||
| # peft_params: | |||
| # kind: encoder_emb | |||
| # n_tokens: 5 | |||
| # mlp_emb: 128 | |||
| # - <<: *default | |||
| # wandb_name: large_10t_mlp128_not_freeze | |||
| # learning_rate: 0.02 | |||
| # hot_modules: | |||
| # - sadcl | |||
| # train_batch_size: 24 | |||
| # valid_batch_size: 24 | |||
| # peft_params: | |||
| # kind: encoder_emb | |||
| # n_tokens: 10 | |||
| # mlp_emb: 128 | |||
| # - <<: *default | |||
| # wandb_name: large_5t_mlp128_not_freeze_lowlr | |||
| # learning_rate: 0.001 | |||
| # hot_modules: | |||
| # - sadcl | |||
| # train_batch_size: 24 | |||
| # valid_batch_size: 24 | |||
| # peft_params: | |||
| # kind: encoder_emb | |||
| # n_tokens: 5 | |||
| # mlp_emb: 128 | |||
| # - <<: *default | |||
| # wandb_name: large_10t_mlp128_not_freeze_lowlr | |||
| # learning_rate: 0.001 | |||
| # hot_modules: | |||
| # - sadcl | |||
| # train_batch_size: 24 | |||
| # valid_batch_size: 24 | |||
| # peft_params: | |||
| # kind: encoder_emb | |||
| # n_tokens: 10 | |||
| # mlp_emb: 128 | |||
| - <<: *default | |||
| wandb_name: large_100t_mlp128_lr.02 | |||
| learning_rate: 0.02 | |||
| hot_modules: | |||
| - sadcl_learned_embeddin | |||
| train_batch_size: 24 | |||
| valid_batch_size: 24 | |||
| peft_params: | |||
| kind: encoder_emb | |||
| n_tokens: 100 | |||
| mlp_emb: 128 | |||
+ 417
- 0
02_AutoEncoder/06_emb_ae.ipynb
View File
| @@ -0,0 +1,417 @@ | |||
| { | |||
| "cells": [ | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 6, | |||
| "id": "a50443d6-fe09-4905-b913-1be5f88c8c03", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import numpy as np\n", | |||
| "from tqdm import tqdm\n", | |||
| "from sklearn.model_selection import train_test_split\n", | |||
| "import torch\n", | |||
| "import torch.nn as nn\n", | |||
| "from transformers import T5Model" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 7, | |||
| "id": "4e677034-dc27-4939-8ea2-71fcbb2da57d", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "np_rng = np.random.default_rng(seed=42)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 8, | |||
| "id": "3d139e0a-b8e3-427b-a537-44bc0f14ba46", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "text/plain": [ | |||
| "array([[ 0.09141512, -0.31199523],\n", | |||
| " [ 0.22513536, 0.28216941],\n", | |||
| " [-0.58531056, -0.39065385],\n", | |||
| " [ 0.03835212, -0.09487278],\n", | |||
| " [-0.00504035, -0.25591318],\n", | |||
| " [ 0.26381939, 0.23333758],\n", | |||
| " [ 0.01980921, 0.33817236],\n", | |||
| " [ 0.1402528 , -0.25778774],\n", | |||
| " [ 0.11062524, -0.28766478],\n", | |||
| " [ 0.26353509, -0.01497777],\n", | |||
| " [-0.05545871, -0.20427886],\n", | |||
| " [ 0.3667624 , -0.04635884],\n", | |||
| " [-0.12849835, -0.10564007],\n", | |||
| " [ 0.15969276, 0.10963322],\n", | |||
| " [ 0.12381978, 0.1292463 ],\n", | |||
| " [ 0.64249428, -0.1219245 ],\n", | |||
| " [-0.15367282, -0.24413182],\n", | |||
| " [ 0.18479383, 0.33869169],\n", | |||
| " [-0.03418424, -0.25204694],\n", | |||
| " [-0.24734436, 0.19517784],\n", | |||
| " [ 0.22297625, 0.16294628],\n", | |||
| " [-0.19965291, 0.0696484 ],\n", | |||
| " [ 0.03500574, 0.06560658],\n", | |||
| " [ 0.26142863, 0.06707866],\n", | |||
| " [ 0.20367407, 0.02027372],\n", | |||
| " [ 0.08673582, 0.18938647],\n", | |||
| " [-0.43714675, -0.09590136],\n", | |||
| " [-0.1411118 , -0.19166335],\n", | |||
| " [-0.08254268, 0.44848239],\n", | |||
| " [-0.25974933, 0.29048351],\n", | |||
| " [-0.50486093, -0.10046551],\n", | |||
| " [ 0.04882592, 0.1758667 ]])" | |||
| ] | |||
| }, | |||
| "execution_count": 8, | |||
| "metadata": {}, | |||
| "output_type": "execute_result" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "np_rng.normal(loc=0, scale=0.3, size=(32, 2))" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 9, | |||
| "id": "544207bc-37fc-4376-9c63-bff44c72b32f", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "# BOTTLENECK_SIZE = 128\n", | |||
| "TRAIN_BATCH_SIZE = 8192\n", | |||
| "VALID_BATCH_SIZE = 8192\n", | |||
| "RANDOM_SEED = 42\n", | |||
| "\n", | |||
| "DEVICE = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\n" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 10, | |||
| "id": "37d2d256-a348-402b-999d-1a4edce360c5", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "def train_valid_test_split(total_range, random_seed=RANDOM_SEED):\n", | |||
| " train, testvalid = train_test_split(total_range, random_state=RANDOM_SEED, test_size=0.2)\n", | |||
| " test, valid = train_test_split(testvalid, random_state=RANDOM_SEED, test_size=0.5)\n", | |||
| " return train, valid, test\n", | |||
| "\n", | |||
| "def custom_dataloader(words_ids, batch_size, emb_dim, random_seed=RANDOM_SEED):\n", | |||
| " np_rng = np.random.default_rng(seed=random_seed)\n", | |||
| " while True:\n", | |||
| " word_ids = np_rng.choice(words_ids, size=(batch_size, 2))\n", | |||
| " additive_noise = np_rng.normal(loc=0, scale=0.1, size=(batch_size, emb_dim))\n", | |||
| " alpha = np_rng.uniform(size=(batch_size, 1))\n", | |||
| " yield torch.from_numpy(word_ids), torch.Tensor(additive_noise), torch.Tensor(alpha)\n", | |||
| " \n", | |||
| "class FakeEpoch:\n", | |||
| " def __init__(self, dataloader, each_epoch_size):\n", | |||
| " self.dataloader_iter = iter(dataloader)\n", | |||
| " self.each_epoch_size = each_epoch_size\n", | |||
| " \n", | |||
| " def __len__(self):\n", | |||
| " return self.each_epoch_size\n", | |||
| " \n", | |||
| " def __iter__(self):\n", | |||
| " for _ in range(self.each_epoch_size):\n", | |||
| " yield next(self.dataloader_iter)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 11, | |||
| "id": "644ae479-3f9a-426a-bd0b-4ec7694bc675", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "\n", | |||
| "def ez_freeze(module):\n", | |||
| " for param in module.parameters():\n", | |||
| " param.requires_grad = False\n", | |||
| " \n", | |||
| "def ez_mlp(linear_dims, last_layer_bias=False):\n", | |||
| " layers = []\n", | |||
| " pairs_count = len(linear_dims) - 1\n", | |||
| " for idx in range(pairs_count):\n", | |||
| " in_dim, out_dim = linear_dims[idx], linear_dims[idx + 1]\n", | |||
| " if idx == pairs_count - 1:\n", | |||
| " layers.append(nn.Linear(in_dim, out_dim, bias=last_layer_bias))\n", | |||
| " else:\n", | |||
| " layers.append(nn.Linear(in_dim, out_dim, bias=True))\n", | |||
| " layers.append(nn.ReLU())\n", | |||
| " return nn.Sequential(*layers)\n", | |||
| "\n", | |||
| "def auto_encoder_model(linear_dims):\n", | |||
| " return nn.Sequential(\n", | |||
| " ez_mlp(linear_dims, last_layer_bias=False),\n", | |||
| " nn.LayerNorm(linear_dims[-1]),\n", | |||
| " ez_mlp(list(reversed(linear_dims)), last_layer_bias=True)\n", | |||
| " )\n", | |||
| "\n", | |||
| "class AutoEncoderModel(nn.Module):\n", | |||
| " def __init__(self, pretrained_name, bottleneck_sizes):\n", | |||
| " super().__init__()\n", | |||
| " \n", | |||
| " self.bottleneck_size = bottleneck_sizes\n", | |||
| " \n", | |||
| " model = T5Model.from_pretrained(pretrained_name)\n", | |||
| " self.emb_layer = model.get_encoder().get_input_embeddings()\n", | |||
| " ez_freeze(self.emb_layer)\n", | |||
| " \n", | |||
| " self.auto_encoder = auto_encoder_model([\n", | |||
| " self.embedding_dim,\n", | |||
| " *bottleneck_sizes\n", | |||
| " ])\n", | |||
| " \n", | |||
| " self.loss_fn = nn.MSELoss()\n", | |||
| " \n", | |||
| " def forward(self, word_ids, additive_noise, alpha):\n", | |||
| " # word_ids.shape = (batch_size, 2)\n", | |||
| " # additive_noise.shape = (batch_size, embedding_dim)\n", | |||
| " # alpha.shape = (batch_size, 1)\n", | |||
| " \n", | |||
| " word_embs = self.emb_layer(word_ids)\n", | |||
| " # word_embs.shape = (batch_size, 2, embedding_dim)\n", | |||
| " \n", | |||
| " word_combs = word_embs[:, 0] * alpha + word_embs[:, 1] * (1 - alpha)\n", | |||
| " # word_combs.shape = (batch_size, embedding_dim)\n", | |||
| " \n", | |||
| " y_hat = self.auto_encoder(word_combs + additive_noise)\n", | |||
| " loss = self.loss_fn(word_combs, y_hat)\n", | |||
| " return loss, y_hat\n", | |||
| " \n", | |||
| " @property\n", | |||
| " def embedding_dim(self):\n", | |||
| " return self.emb_layer.embedding_dim\n", | |||
| " \n", | |||
| " @property\n", | |||
| " def num_embeddings(self):\n", | |||
| " return self.emb_layer.num_embeddings " | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 12, | |||
| "id": "aba28049-20bf-4ae6-9445-2f7c294686d8", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "model = AutoEncoderModel('google/t5-large-lm-adapt', bottleneck_sizes=[768, 768, 512, 512, 256, 256, 128, 128])" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 16, | |||
| "id": "cac6bc39-ba12-4052-bd5f-8834f57cfa15", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "text/plain": [ | |||
| "tensor(96.9082)" | |||
| ] | |||
| }, | |||
| "execution_count": 16, | |||
| "metadata": {}, | |||
| "output_type": "execute_result" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "(model.emb_layer.weight**2).mean()" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 6, | |||
| "id": "afe2efbf-e703-4c43-8f7b-a87d303ea89e", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "train_ds, valid_ds, test_ds = train_valid_test_split(range(model.num_embeddings))\n", | |||
| "train_loader = custom_dataloader(words_ids=train_ds, batch_size=TRAIN_BATCH_SIZE, emb_dim=model.embedding_dim)\n", | |||
| "valid_loader = custom_dataloader(words_ids=valid_ds, batch_size=VALID_BATCH_SIZE, emb_dim=model.embedding_dim)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 7, | |||
| "id": "c24ccc1c-4cbe-4373-871e-9090dceb69a1", | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [ | |||
| "train_loader = FakeEpoch(train_loader, 1000)\n", | |||
| "valid_loader = FakeEpoch(valid_loader, 100)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 8, | |||
| "id": "71936e43-d718-45ef-8115-7fc63999ebd9", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "def _prefix_dict_keys(prefix, input_dict):\n", | |||
| " return {f'{prefix}_{key}': val for key, val in input_dict.items()}\n", | |||
| "\n", | |||
| "def train_loop(model, loader, optimizer, use_tqdm=False):\n", | |||
| " model.train()\n", | |||
| "\n", | |||
| " batch_losses = []\n", | |||
| " \n", | |||
| " if use_tqdm:\n", | |||
| " loader = tqdm(loader, position=2, desc=\"Train Loop\", leave=False)\n", | |||
| " \n", | |||
| " for row in loader:\n", | |||
| " optimizer.zero_grad()\n", | |||
| " \n", | |||
| " out = model(*(item.to(DEVICE) for item in row))\n", | |||
| " loss = out[0]\n", | |||
| " \n", | |||
| " batch_loss_value = loss.item()\n", | |||
| " loss.backward()\n", | |||
| " optimizer.step()\n", | |||
| " \n", | |||
| " batch_losses.append(batch_loss_value)\n", | |||
| " \n", | |||
| " loss_value = np.mean(batch_losses)\n", | |||
| " return _prefix_dict_keys('train', {\n", | |||
| " 'loss': loss_value\n", | |||
| " })\n", | |||
| "\n", | |||
| "def valid_loop(model, loader, use_tqdm=False):\n", | |||
| " model.eval()\n", | |||
| "\n", | |||
| " batch_losses = []\n", | |||
| " \n", | |||
| " all_true = []\n", | |||
| " all_pred = []\n", | |||
| " \n", | |||
| " if use_tqdm:\n", | |||
| " loader = tqdm(loader, position=2, desc=\"Valid Loop\", leave=False)\n", | |||
| " \n", | |||
| " with torch.no_grad():\n", | |||
| " for row in loader:\n", | |||
| " out = model(*(item.to(DEVICE) for item in row))\n", | |||
| " loss = out[0]\n", | |||
| " \n", | |||
| " batch_loss_value = loss.item()\n", | |||
| "\n", | |||
| " batch_losses.append(batch_loss_value)\n", | |||
| "\n", | |||
| " loss_value = np.mean(batch_losses)\n", | |||
| " \n", | |||
| " return_value = {\n", | |||
| " 'loss': loss_value,\n", | |||
| " }\n", | |||
| " \n", | |||
| " return _prefix_dict_keys('valid', return_value)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 9, | |||
| "id": "082b5384-827f-48b3-aa8e-40483668bbc0", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "ename": "KeyboardInterrupt", | |||
| "evalue": "", | |||
| "output_type": "error", | |||
| "traceback": [ | |||
| "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m", | |||
| "\u001b[0;31mKeyboardInterrupt\u001b[0m Traceback (most recent call last)", | |||
| "Cell \u001b[0;32mIn[9], line 8\u001b[0m\n\u001b[1;32m 4\u001b[0m \u001b[38;5;28;01mfor\u001b[39;00m epoch \u001b[38;5;129;01min\u001b[39;00m \u001b[38;5;28mrange\u001b[39m(\u001b[38;5;241m1000\u001b[39m):\n\u001b[1;32m 5\u001b[0m epoch_results \u001b[38;5;241m=\u001b[39m {}\n\u001b[1;32m 7\u001b[0m epoch_results\u001b[38;5;241m.\u001b[39mupdate(\n\u001b[0;32m----> 8\u001b[0m \u001b[43mtrain_loop\u001b[49m\u001b[43m(\u001b[49m\n\u001b[1;32m 9\u001b[0m \u001b[43m \u001b[49m\u001b[43mmodel\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mmodel\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 10\u001b[0m \u001b[43m \u001b[49m\u001b[43mloader\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43mtrain_loader\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 11\u001b[0m \u001b[43m \u001b[49m\u001b[43moptimizer\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43moptimizer\u001b[49m\u001b[43m,\u001b[49m\n\u001b[1;32m 12\u001b[0m \u001b[43m \u001b[49m\u001b[43muse_tqdm\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[38;5;28;43;01mFalse\u001b[39;49;00m\n\u001b[1;32m 13\u001b[0m \u001b[43m \u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 14\u001b[0m )\n\u001b[1;32m 16\u001b[0m epoch_results\u001b[38;5;241m.\u001b[39mupdate(\n\u001b[1;32m 17\u001b[0m valid_loop(\n\u001b[1;32m 18\u001b[0m model\u001b[38;5;241m=\u001b[39mmodel,\n\u001b[0;32m (...)\u001b[0m\n\u001b[1;32m 21\u001b[0m )\n\u001b[1;32m 22\u001b[0m )\n\u001b[1;32m 23\u001b[0m \u001b[38;5;28mprint\u001b[39m(epoch_results)\n", | |||
| "Cell \u001b[0;32mIn[8], line 12\u001b[0m, in \u001b[0;36mtrain_loop\u001b[0;34m(model, loader, optimizer, use_tqdm)\u001b[0m\n\u001b[1;32m 9\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m use_tqdm:\n\u001b[1;32m 10\u001b[0m loader \u001b[38;5;241m=\u001b[39m tqdm(loader, position\u001b[38;5;241m=\u001b[39m\u001b[38;5;241m2\u001b[39m, desc\u001b[38;5;241m=\u001b[39m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mTrain Loop\u001b[39m\u001b[38;5;124m\"\u001b[39m, leave\u001b[38;5;241m=\u001b[39m\u001b[38;5;28;01mFalse\u001b[39;00m)\n\u001b[0;32m---> 12\u001b[0m \u001b[38;5;28;01mfor\u001b[39;00m row \u001b[38;5;129;01min\u001b[39;00m loader:\n\u001b[1;32m 13\u001b[0m optimizer\u001b[38;5;241m.\u001b[39mzero_grad()\n\u001b[1;32m 15\u001b[0m out \u001b[38;5;241m=\u001b[39m model(\u001b[38;5;241m*\u001b[39m(item\u001b[38;5;241m.\u001b[39mto(DEVICE) \u001b[38;5;28;01mfor\u001b[39;00m item \u001b[38;5;129;01min\u001b[39;00m row))\n", | |||
| "Cell \u001b[0;32mIn[3], line 24\u001b[0m, in \u001b[0;36mFakeEpoch.__iter__\u001b[0;34m(self)\u001b[0m\n\u001b[1;32m 22\u001b[0m \u001b[38;5;28;01mdef\u001b[39;00m \u001b[38;5;21m__iter__\u001b[39m(\u001b[38;5;28mself\u001b[39m):\n\u001b[1;32m 23\u001b[0m \u001b[38;5;28;01mfor\u001b[39;00m _ \u001b[38;5;129;01min\u001b[39;00m \u001b[38;5;28mrange\u001b[39m(\u001b[38;5;28mself\u001b[39m\u001b[38;5;241m.\u001b[39meach_epoch_size):\n\u001b[0;32m---> 24\u001b[0m \u001b[38;5;28;01myield\u001b[39;00m \u001b[38;5;28;43mnext\u001b[39;49m\u001b[43m(\u001b[49m\u001b[38;5;28;43mself\u001b[39;49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mdataloader_iter\u001b[49m\u001b[43m)\u001b[49m\n", | |||
| "Cell \u001b[0;32mIn[3], line 10\u001b[0m, in \u001b[0;36mcustom_dataloader\u001b[0;34m(words_ids, batch_size, emb_dim, random_seed)\u001b[0m\n\u001b[1;32m 8\u001b[0m \u001b[38;5;28;01mwhile\u001b[39;00m \u001b[38;5;28;01mTrue\u001b[39;00m:\n\u001b[1;32m 9\u001b[0m word_ids \u001b[38;5;241m=\u001b[39m np_rng\u001b[38;5;241m.\u001b[39mchoice(words_ids, size\u001b[38;5;241m=\u001b[39m(batch_size, \u001b[38;5;241m2\u001b[39m))\n\u001b[0;32m---> 10\u001b[0m additive_noise \u001b[38;5;241m=\u001b[39m \u001b[43mnp_rng\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mnormal\u001b[49m\u001b[43m(\u001b[49m\u001b[43mloc\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[38;5;241;43m0\u001b[39;49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mscale\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[38;5;241;43m0.1\u001b[39;49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43msize\u001b[49m\u001b[38;5;241;43m=\u001b[39;49m\u001b[43m(\u001b[49m\u001b[43mbatch_size\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43memb_dim\u001b[49m\u001b[43m)\u001b[49m\u001b[43m)\u001b[49m\n\u001b[1;32m 11\u001b[0m alpha \u001b[38;5;241m=\u001b[39m np_rng\u001b[38;5;241m.\u001b[39muniform(size\u001b[38;5;241m=\u001b[39m(batch_size, \u001b[38;5;241m1\u001b[39m))\n\u001b[1;32m 12\u001b[0m \u001b[38;5;28;01myield\u001b[39;00m torch\u001b[38;5;241m.\u001b[39mfrom_numpy(word_ids), torch\u001b[38;5;241m.\u001b[39mTensor(additive_noise), torch\u001b[38;5;241m.\u001b[39mTensor(alpha)\n", | |||
| "\u001b[0;31mKeyboardInterrupt\u001b[0m: " | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "model.to(DEVICE)\n", | |||
| "optimizer = torch.optim.AdamW(model.parameters(), lr=0.001)\n", | |||
| "\n", | |||
| "for epoch in range(1000):\n", | |||
| " epoch_results = {}\n", | |||
| "\n", | |||
| " epoch_results.update(\n", | |||
| " train_loop(\n", | |||
| " model=model,\n", | |||
| " loader=train_loader,\n", | |||
| " optimizer=optimizer,\n", | |||
| " use_tqdm=False\n", | |||
| " )\n", | |||
| " )\n", | |||
| "\n", | |||
| " epoch_results.update(\n", | |||
| " valid_loop(\n", | |||
| " model=model,\n", | |||
| " loader=valid_loader,\n", | |||
| " use_tqdm=False\n", | |||
| " )\n", | |||
| " )\n", | |||
| " print(epoch_results)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": null, | |||
| "id": "53425637-6146-41d2-b59e-4617ae1f8521", | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [] | |||
| } | |||
| ], | |||
| "metadata": { | |||
| "kernelspec": { | |||
| "display_name": "Python [conda env:deep]", | |||
| "language": "python", | |||
| "name": "conda-env-deep-py" | |||
| }, | |||
| "language_info": { | |||
| "codemirror_mode": { | |||
| "name": "ipython", | |||
| "version": 3 | |||
| }, | |||
| "file_extension": ".py", | |||
| "mimetype": "text/x-python", | |||
| "name": "python", | |||
| "nbconvert_exporter": "python", | |||
| "pygments_lexer": "ipython3", | |||
| "version": "3.10.11" | |||
| } | |||
| }, | |||
| "nbformat": 4, | |||
| "nbformat_minor": 5 | |||
| } | |||
+ 244
- 0
02_AutoEncoder/06_emb_ae.py
View File
| @@ -0,0 +1,244 @@ | |||
| #!/usr/bin/env python | |||
| # coding: utf-8 | |||
| # In[1]: | |||
| import numpy as np | |||
| from tqdm import tqdm | |||
| from sklearn.model_selection import train_test_split | |||
| import torch | |||
| import torch.nn as nn | |||
| from transformers import T5Model | |||
| # In[2]: | |||
| # BOTTLENECK_SIZE = 128 | |||
| TRAIN_BATCH_SIZE = 64 | |||
| VALID_BATCH_SIZE = 64 | |||
| NOISE_SCALE = 0.5 | |||
| RANDOM_SEED = 42 | |||
| SEED_SHIFT = 0 | |||
| DROP_OUT = 0.5 | |||
| DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") | |||
| # In[3]: | |||
| def train_valid_test_split(total_range, random_seed=RANDOM_SEED): | |||
| train, testvalid = train_test_split(total_range, random_state=random_seed, test_size=0.2) | |||
| test, valid = train_test_split(testvalid, random_state=random_seed, test_size=0.5) | |||
| return train, valid, test | |||
| def custom_dataloader(words_ids, batch_size, emb_dim, random_seed=RANDOM_SEED+SEED_SHIFT): | |||
| np_rng = np.random.default_rng(seed=random_seed) | |||
| while True: | |||
| word_ids = np_rng.choice(words_ids, size=(batch_size, 2)) | |||
| additive_noise = np_rng.normal(loc=0, scale=NOISE_SCALE, size=(batch_size, emb_dim)) | |||
| alpha = np_rng.uniform(size=(batch_size, 1)) | |||
| yield torch.from_numpy(word_ids), torch.Tensor(additive_noise), torch.Tensor(alpha) | |||
| class FakeEpoch: | |||
| def __init__(self, dataloader, each_epoch_size): | |||
| self.dataloader_iter = iter(dataloader) | |||
| self.each_epoch_size = each_epoch_size | |||
| def __len__(self): | |||
| return self.each_epoch_size | |||
| def __iter__(self): | |||
| for _ in range(self.each_epoch_size): | |||
| yield next(self.dataloader_iter) | |||
| # In[4]: | |||
| def ez_freeze(module): | |||
| for param in module.parameters(): | |||
| param.requires_grad = False | |||
| def ez_mlp(linear_dims, last_layer_bias=False, drop_out=None): | |||
| layers = [] | |||
| pairs_count = len(linear_dims) - 1 | |||
| for idx in range(pairs_count): | |||
| in_dim, out_dim = linear_dims[idx], linear_dims[idx + 1] | |||
| if idx == pairs_count - 1: | |||
| layers.append(nn.Linear(in_dim, out_dim, bias=True)) | |||
| else: | |||
| layers.append(nn.Linear(in_dim, out_dim, bias=True)) | |||
| layers.append(nn.ReLU()) | |||
| if drop_out is not None: | |||
| layers.append(nn.Dropout(drop_out)) | |||
| return nn.Sequential(*layers) | |||
| def auto_encoder_model(linear_dims): | |||
| return nn.Sequential( | |||
| ez_mlp(linear_dims, last_layer_bias=False, drop_out=DROP_OUT), | |||
| nn.ReLU(), | |||
| nn.Dropout(0.5), | |||
| # nn.LayerNorm(linear_dims[-1]), | |||
| ez_mlp(list(reversed(linear_dims)), last_layer_bias=True) | |||
| ) | |||
| class AutoEncoderModel(nn.Module): | |||
| def __init__(self, pretrained_name, bottleneck_sizes): | |||
| super().__init__() | |||
| self.bottleneck_size = bottleneck_sizes | |||
| model = T5Model.from_pretrained(pretrained_name) | |||
| self.emb_layer = model.get_encoder().get_input_embeddings() | |||
| ez_freeze(self.emb_layer) | |||
| self.auto_encoder = auto_encoder_model([ | |||
| self.embedding_dim, | |||
| *bottleneck_sizes | |||
| ]) | |||
| self.loss_fn = nn.MSELoss() | |||
| def forward(self, word_ids, additive_noise, alpha): | |||
| # word_ids.shape = (batch_size, 2) | |||
| # additive_noise.shape = (batch_size, embedding_dim) | |||
| # alpha.shape = (batch_size, 1) | |||
| word_embs = self.emb_layer(word_ids) | |||
| # word_embs.shape = (batch_size, 2, embedding_dim) | |||
| word_combs = word_embs[:, 0] * alpha + word_embs[:, 1] * (1 - alpha) | |||
| # word_combs.shape = (batch_size, embedding_dim) | |||
| y_hat = self.auto_encoder(word_combs + additive_noise) | |||
| loss = self.loss_fn(word_combs, y_hat) | |||
| return loss, y_hat | |||
| @property | |||
| def embedding_dim(self): | |||
| return self.emb_layer.embedding_dim | |||
| @property | |||
| def num_embeddings(self): | |||
| return self.emb_layer.num_embeddings | |||
| # In[5]: | |||
| model = AutoEncoderModel('google/t5-large-lm-adapt', bottleneck_sizes=[4096]) | |||
| print(model) | |||
| # In[6]: | |||
| train_ds, valid_ds, test_ds = train_valid_test_split(range(model.num_embeddings)) | |||
| train_loader = custom_dataloader(words_ids=train_ds, batch_size=TRAIN_BATCH_SIZE, emb_dim=model.embedding_dim) | |||
| valid_loader = custom_dataloader(words_ids=valid_ds, batch_size=VALID_BATCH_SIZE, emb_dim=model.embedding_dim) | |||
| # In[7]: | |||
| train_loader = FakeEpoch(train_loader, 2000) | |||
| valid_loader = FakeEpoch(valid_loader, 100) | |||
| # In[8]: | |||
| def _prefix_dict_keys(prefix, input_dict): | |||
| return {f'{prefix}_{key}': val for key, val in input_dict.items()} | |||
| def train_loop(model, loader, optimizer, use_tqdm=False): | |||
| model.train() | |||
| batch_losses = [] | |||
| if use_tqdm: | |||
| loader = tqdm(loader, position=2, desc="Train Loop", leave=False) | |||
| for row in loader: | |||
| optimizer.zero_grad() | |||
| out = model(*(item.to(DEVICE) for item in row)) | |||
| loss = out[0] | |||
| batch_loss_value = loss.item() | |||
| loss.backward() | |||
| optimizer.step() | |||
| batch_losses.append(batch_loss_value) | |||
| loss_value = np.mean(batch_losses) | |||
| return _prefix_dict_keys('train', { | |||
| 'loss': loss_value | |||
| }) | |||
| def valid_loop(model, loader, use_tqdm=False): | |||
| model.eval() | |||
| batch_losses = [] | |||
| if use_tqdm: | |||
| loader = tqdm(loader, position=2, desc="Valid Loop", leave=False) | |||
| with torch.no_grad(): | |||
| for row in loader: | |||
| out = model(*(item.to(DEVICE) for item in row)) | |||
| loss = out[0] | |||
| batch_loss_value = loss.item() | |||
| batch_losses.append(batch_loss_value) | |||
| loss_value = np.mean(batch_losses) | |||
| return_value = { | |||
| 'loss': loss_value, | |||
| } | |||
| return _prefix_dict_keys('valid', return_value) | |||
| # In[9]: | |||
| model.to(DEVICE) | |||
| # model.load_state_dict(torch.load('./ae_file/snap_72.pt')) | |||
| optimizer = torch.optim.AdamW(model.parameters(), lr=0.0001) # was 0.001 | |||
| for epoch in tqdm(range(1000), position=1): | |||
| epoch_results = {} | |||
| epoch_results.update( | |||
| train_loop( | |||
| model=model, | |||
| loader=train_loader, | |||
| optimizer=optimizer, | |||
| use_tqdm=True | |||
| ) | |||
| ) | |||
| epoch_results.update( | |||
| valid_loop( | |||
| model=model, | |||
| loader=valid_loader, | |||
| use_tqdm=True | |||
| ) | |||
| ) | |||
| torch.save(model.state_dict(), f'/disks/ssd/ae_file4/snap_{epoch}.pt') | |||
| print(epoch_results) | |||
| # In[ ]: | |||
+ 254
- 0
02_AutoEncoder/06_emb_ae_res_mlp.py
View File
| @@ -0,0 +1,254 @@ | |||
| #!/usr/bin/env python | |||
| # coding: utf-8 | |||
| # In[1]: | |||
| import numpy as np | |||
| from tqdm import tqdm | |||
| from sklearn.model_selection import train_test_split | |||
| import torch | |||
| import torch.nn as nn | |||
| from transformers import T5Model | |||
| # In[2]: | |||
| # BOTTLENECK_SIZE = 128 | |||
| TRAIN_BATCH_SIZE = 8192 | |||
| VALID_BATCH_SIZE = 8192 | |||
| NOISE_SCALE = 1 | |||
| RANDOM_SEED = 42 | |||
| SEED_SHIFT = 0 | |||
| DROP_OUT = 0.2 | |||
| DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") | |||
| # In[3]: | |||
| def train_valid_test_split(total_range, random_seed=RANDOM_SEED): | |||
| train, testvalid = train_test_split(total_range, random_state=random_seed, test_size=0.2) | |||
| test, valid = train_test_split(testvalid, random_state=random_seed, test_size=0.5) | |||
| return train, valid, test | |||
| def custom_dataloader(words_ids, batch_size, emb_dim, random_seed=RANDOM_SEED+SEED_SHIFT): | |||
| np_rng = np.random.default_rng(seed=random_seed) | |||
| while True: | |||
| word_ids = np_rng.choice(words_ids, size=(batch_size, 2)) | |||
| additive_noise = np_rng.normal(loc=0, scale=NOISE_SCALE, size=(batch_size, emb_dim)) | |||
| alpha = np_rng.uniform(size=(batch_size, 1)) | |||
| yield torch.from_numpy(word_ids), torch.Tensor(additive_noise), torch.Tensor(alpha) | |||
| class FakeEpoch: | |||
| def __init__(self, dataloader, each_epoch_size): | |||
| self.dataloader_iter = iter(dataloader) | |||
| self.each_epoch_size = each_epoch_size | |||
| def __len__(self): | |||
| return self.each_epoch_size | |||
| def __iter__(self): | |||
| for _ in range(self.each_epoch_size): | |||
| yield next(self.dataloader_iter) | |||
| # In[4]: | |||
| def ez_freeze(module): | |||
| for param in module.parameters(): | |||
| param.requires_grad = False | |||
| class ResLinear(nn.Module): | |||
| def __init__(self, in_dim, out_dim): | |||
| super().__init__() | |||
| self.linear1 = nn.Linear(in_dim, out_dim) | |||
| self.linear2 = nn.Linear(out_dim, out_dim) | |||
| def forward(self, x): | |||
| out1 = nn.functional.relu(self.linear1(x)) | |||
| out2 = nn.functional.relu(self.linear2(out1)) | |||
| return out1 + out2 | |||
| def ez_mlp(linear_dims, last_layer_bias=False, drop_out=None): | |||
| layers = [] | |||
| pairs_count = len(linear_dims) - 1 | |||
| for idx in range(pairs_count): | |||
| in_dim, out_dim = linear_dims[idx], linear_dims[idx + 1] | |||
| if idx == pairs_count - 1: | |||
| layers.append(nn.Linear(in_dim, out_dim, bias=last_layer_bias)) | |||
| else: | |||
| layers.append(ResLinear(in_dim, out_dim)) | |||
| if drop_out is not None: | |||
| layers.append(nn.Dropout(drop_out)) | |||
| return nn.Sequential(*layers) | |||
| def auto_encoder_model(linear_dims): | |||
| return nn.Sequential( | |||
| ez_mlp(linear_dims, last_layer_bias=False, drop_out=DROP_OUT), | |||
| nn.LayerNorm(linear_dims[-1]), | |||
| ez_mlp(list(reversed(linear_dims)), last_layer_bias=True) | |||
| ) | |||
| class AutoEncoderModel(nn.Module): | |||
| def __init__(self, pretrained_name, bottleneck_sizes): | |||
| super().__init__() | |||
| self.bottleneck_size = bottleneck_sizes | |||
| model = T5Model.from_pretrained(pretrained_name) | |||
| self.emb_layer = model.get_encoder().get_input_embeddings() | |||
| ez_freeze(self.emb_layer) | |||
| self.auto_encoder = auto_encoder_model([ | |||
| self.embedding_dim, | |||
| *bottleneck_sizes | |||
| ]) | |||
| self.loss_fn = nn.MSELoss() | |||
| def forward(self, word_ids, additive_noise, alpha): | |||
| # word_ids.shape = (batch_size, 2) | |||
| # additive_noise.shape = (batch_size, embedding_dim) | |||
| # alpha.shape = (batch_size, 1) | |||
| word_embs = self.emb_layer(word_ids) | |||
| # word_embs.shape = (batch_size, 2, embedding_dim) | |||
| word_combs = word_embs[:, 0] * alpha + word_embs[:, 1] * (1 - alpha) | |||
| # word_combs.shape = (batch_size, embedding_dim) | |||
| y_hat = self.auto_encoder(word_combs + additive_noise) | |||
| loss = self.loss_fn(word_combs, y_hat) | |||
| return loss, y_hat | |||
| @property | |||
| def embedding_dim(self): | |||
| return self.emb_layer.embedding_dim | |||
| @property | |||
| def num_embeddings(self): | |||
| return self.emb_layer.num_embeddings | |||
| # In[5]: | |||
| model = AutoEncoderModel('google/t5-large-lm-adapt', bottleneck_sizes=[768, 512, 256, 128]) | |||
| print(model) | |||
| # In[6]: | |||
| train_ds, valid_ds, test_ds = train_valid_test_split(range(model.num_embeddings)) | |||
| train_loader = custom_dataloader(words_ids=train_ds, batch_size=TRAIN_BATCH_SIZE, emb_dim=model.embedding_dim) | |||
| valid_loader = custom_dataloader(words_ids=valid_ds, batch_size=VALID_BATCH_SIZE, emb_dim=model.embedding_dim) | |||
| # In[7]: | |||
| train_loader = FakeEpoch(train_loader, 1000) | |||
| valid_loader = FakeEpoch(valid_loader, 100) | |||
| # In[8]: | |||
| def _prefix_dict_keys(prefix, input_dict): | |||
| return {f'{prefix}_{key}': val for key, val in input_dict.items()} | |||
| def train_loop(model, loader, optimizer, use_tqdm=False): | |||
| model.train() | |||
| batch_losses = [] | |||
| if use_tqdm: | |||
| loader = tqdm(loader, position=2, desc="Train Loop", leave=False) | |||
| for row in loader: | |||
| optimizer.zero_grad() | |||
| out = model(*(item.to(DEVICE) for item in row)) | |||
| loss = out[0] | |||
| batch_loss_value = loss.item() | |||
| loss.backward() | |||
| optimizer.step() | |||
| batch_losses.append(batch_loss_value) | |||
| loss_value = np.mean(batch_losses) | |||
| return _prefix_dict_keys('train', { | |||
| 'loss': loss_value | |||
| }) | |||
| def valid_loop(model, loader, use_tqdm=False): | |||
| model.eval() | |||
| batch_losses = [] | |||
| all_true = [] | |||
| all_pred = [] | |||
| if use_tqdm: | |||
| loader = tqdm(loader, position=2, desc="Valid Loop", leave=False) | |||
| with torch.no_grad(): | |||
| for row in loader: | |||
| out = model(*(item.to(DEVICE) for item in row)) | |||
| loss = out[0] | |||
| batch_loss_value = loss.item() | |||
| batch_losses.append(batch_loss_value) | |||
| loss_value = np.mean(batch_losses) | |||
| return_value = { | |||
| 'loss': loss_value, | |||
| } | |||
| return _prefix_dict_keys('valid', return_value) | |||
| # In[9]: | |||
| model.to(DEVICE) | |||
| # model.load_state_dict(torch.load('./ae_file/snap_72.pt')) | |||
| optimizer = torch.optim.AdamW(model.parameters(), lr=0.001) # was 0.001 | |||
| for epoch in tqdm(range(1000), position=1): | |||
| epoch_results = {} | |||
| epoch_results.update( | |||
| train_loop( | |||
| model=model, | |||
| loader=train_loader, | |||
| optimizer=optimizer, | |||
| use_tqdm=True | |||
| ) | |||
| ) | |||
| epoch_results.update( | |||
| valid_loop( | |||
| model=model, | |||
| loader=valid_loader, | |||
| use_tqdm=True | |||
| ) | |||
| ) | |||
| torch.save(model.state_dict(), f'./ae_file4_res_mlp/snap_{epoch}.pt') | |||
| print(epoch_results) | |||
| # In[ ]: | |||
+ 88
- 0
02_AutoEncoder/07_emb_sp.ipynb
View File
| @@ -0,0 +1,88 @@ | |||
| { | |||
| "cells": [ | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 1, | |||
| "id": "4c6f353f-83e2-4780-9124-bf7f30e2a77d", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "from typing import Optional\n", | |||
| "\n", | |||
| "import numpy as np\n", | |||
| "from tqdm import tqdm\n", | |||
| "\n", | |||
| "import wandb\n", | |||
| "import torch\n", | |||
| "import torch.nn as nn\n", | |||
| "from transformers import T5TokenizerFast, T5ForConditionalGeneration\n", | |||
| "\n", | |||
| "from _config import load_config\n", | |||
| "from _utils import print_system_info, silent_logs\n", | |||
| "from _datasets import AutoLoad, generate_dataloader\n", | |||
| "from _mydelta import T5Wrapper, auto_freeze, EmbeddingWrapper\n", | |||
| "from _trainer import train_loop, valid_loop, BestFinder\n", | |||
| "\n", | |||
| "# configs = load_config('./config.yaml')\n", | |||
| "\n", | |||
| "# RANDOM_SEED = configs.shared.random_seed\n", | |||
| "# WANDB_PROJECT_NAME = configs.shared.project_name\n", | |||
| "# DEVICE = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\n", | |||
| "# USE_TQDM = configs.shared.use_tqdm\n", | |||
| "\n" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 2, | |||
| "id": "ead0c663-c9e4-4625-8f3b-11e53ca59920", | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [ | |||
| "model = T5ForConditionalGeneration.from_pretrained('google/t5-large-lm-adapt')\n", | |||
| "tokenizer = T5TokenizerFast.from_pretrained('google/t5-large-lm-adapt', model_max_length=2048)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": null, | |||
| "id": "e348f601-c713-49af-86e4-a40382c5a36f", | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [ | |||
| "num_tokens = 100" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": null, | |||
| "id": "6d9a6602-f90d-440a-b11e-ddda2d36d2f7", | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [] | |||
| } | |||
| ], | |||
| "metadata": { | |||
| "kernelspec": { | |||
| "display_name": "Python [conda env:deep]", | |||
| "language": "python", | |||
| "name": "conda-env-deep-py" | |||
| }, | |||
| "language_info": { | |||
| "codemirror_mode": { | |||
| "name": "ipython", | |||
| "version": 3 | |||
| }, | |||
| "file_extension": ".py", | |||
| "mimetype": "text/x-python", | |||
| "name": "python", | |||
| "nbconvert_exporter": "python", | |||
| "pygments_lexer": "ipython3", | |||
| "version": "3.10.11" | |||
| } | |||
| }, | |||
| "nbformat": 4, | |||
| "nbformat_minor": 5 | |||
| } | |||
+ 0
- 0
03_CombPrompts/config.yaml
View File
+ 27
- 0
03_CombPrompts/train.py
View File
| @@ -0,0 +1,27 @@ | |||
| from tqdm import tqdm | |||
| import torch | |||
| import os | |||
| import sys | |||
| sys.path.insert(1, os.path.join(sys.path[0], '..')) | |||
| from _config import load_config | |||
| from _utils import print_system_info, sp_encode | |||
| from train_single import run_experminent | |||
| if __name__ == '__main__': | |||
| print_system_info() | |||
| configs = load_config(sys.argv[1]) | |||
| run_configs = tqdm(configs.run_configs, position=0, desc="Experiment") | |||
| for run_config in run_configs: | |||
| tasks = tqdm(run_config.tasks, position=1, desc="Task:", leave=False) | |||
| for task_name in tasks: | |||
| tasks.set_description(f'Task: {task_name}') | |||
| torch.cuda.empty_cache() | |||
| run_experminent(run_config, task_name) | |||
+ 47
- 0
03_CombPrompts/train_single.py
View File
| @@ -0,0 +1,47 @@ | |||
| import numpy as np | |||
| import torch | |||
| import os | |||
| import sys | |||
| sys.path.insert(1, os.path.join(sys.path[0], '..')) | |||
| from _utils import silent_logs, sp_decode | |||
| from _datasets import AutoLoad | |||
| from _trainer import auto_train | |||
| from _mydelta import auto_mutate | |||
| from _models import auto_model | |||
| from _config import Config | |||
| DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") | |||
| def run_experminent(config, task_name): | |||
| silent_logs() | |||
| np.random.seed(config.random_seed) | |||
| # ______________________LOAD MODEL_____________________________ | |||
| model, tokenizer = auto_model(config.model_name, AutoLoad.get_task_output(task_name)) | |||
| # ______________________MUTATE MODEL_____________________________ | |||
| n_prefix_token = 0 | |||
| if config.peft_params is not None: | |||
| n_prefix_token = config.peft_params.n_tokens | |||
| delta_module = auto_mutate( | |||
| model=model, | |||
| tokenizer=tokenizer, | |||
| peft_params=config.peft_params.to_dict(), | |||
| remove_dropout=config.remove_dropout | |||
| ) | |||
| # ______________________LOAD DATA_____________________________ | |||
| autoload = AutoLoad(tokenizer, n_prefix_token=n_prefix_token) | |||
| # ______________________TRAIN_____________________________ | |||
| dataset = autoload.get_and_map(task_name) | |||
| auto_train(model, tokenizer, dataset, config, device=DEVICE) | |||
| if __name__ == '__main__': | |||
| config_json = sp_decode(sys.argv[1]) | |||
| config = Config(config_json, '') | |||
| task_name = sp_decode(sys.argv[2]) | |||
| run_experminent(config, task_name) | |||
+ 62
- 0
04_LowerDimPrompt/config.yaml
View File
| @@ -0,0 +1,62 @@ | |||
| shared: | |||
| project_name: lowdim_prompts | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| default: &default | |||
| model_name: google/t5-large-lm-adapt | |||
| wandb_name: null | |||
| train_batch_size: 32 | |||
| valid_batch_size: 32 | |||
| num_epochs: 200 | |||
| peft_params: null # no mutation | |||
| hot_modules: null # fine-tune all | |||
| balancify_train: false | |||
| best_finder: | |||
| save: true | |||
| metric: valid_f1-score-ma | |||
| higher_better: true | |||
| tasks: | |||
| - glue:cola | |||
| run_configs: | |||
| # - <<: *default | |||
| # wandb_name: n_tokens100_n_comb_tokens512 | |||
| # learning_rate: 0.01 | |||
| # hot_modules: | |||
| # - sadcl | |||
| # peft_params: | |||
| # kind: comb_prompt | |||
| # n_tokens: 100 | |||
| # n_comb_tokens: 512 | |||
| # - <<: *default | |||
| # wandb_name: n_tokens100_n_comb_tokens2048 | |||
| # learning_rate: 0.01 | |||
| # hot_modules: | |||
| # - sadcl | |||
| # peft_params: | |||
| # kind: comb_prompt | |||
| # n_tokens: 100 | |||
| # n_comb_tokens: 2048 | |||
| - <<: *default | |||
| wandb_name: large_n_tokens100_64_256 | |||
| learning_rate: 0.01 | |||
| hot_modules: | |||
| - sadcl | |||
| peft_params: | |||
| kind: lowdim_prompt | |||
| n_tokens: 100 | |||
| dims: | |||
| - 64 | |||
| - 256 | |||
| - <<: *default | |||
| wandb_name: large_n_tokens100_256_512 | |||
| learning_rate: 0.01 | |||
| hot_modules: | |||
| - sadcl | |||
| peft_params: | |||
| kind: lowdim_prompt | |||
| n_tokens: 100 | |||
| dims: | |||
| - 256 | |||
| - 512 | |||
+ 116
- 0
04_LowerDimPrompt/train.py
View File
| @@ -0,0 +1,116 @@ | |||
| from typing import Optional | |||
| import numpy as np | |||
| from tqdm import tqdm | |||
| import wandb | |||
| import torch | |||
| import torch.nn as nn | |||
| from transformers import T5TokenizerFast, T5ForConditionalGeneration | |||
| import os | |||
| import sys | |||
| sys.path.insert(1, os.path.join(sys.path[0], '..')) | |||
| from _config import load_config | |||
| from _utils import print_system_info, silent_logs | |||
| from _datasets import AutoLoad, generate_dataloader | |||
| from _mydelta import auto_freeze, LowdimEmbeddingWrapper | |||
| from _trainer import train_loop, valid_loop, BestFinder | |||
| configs = load_config('./config.yaml') | |||
| RANDOM_SEED = configs.shared.random_seed | |||
| WANDB_PROJECT_NAME = configs.shared.project_name | |||
| DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") | |||
| USE_TQDM = configs.shared.use_tqdm | |||
| def run_experminent(config): | |||
| np.random.seed(RANDOM_SEED) | |||
| # ______________________LOAD MODEL_____________________________ | |||
| model = T5ForConditionalGeneration.from_pretrained(config.model_name) | |||
| tokenizer = T5TokenizerFast.from_pretrained(config.model_name, model_max_length=2048) | |||
| # ______________________MUTATE MODEL_____________________________ | |||
| if config.peft_params is not None: | |||
| peft_params = config.peft_params.to_dict() | |||
| peft_class = { | |||
| 'lowdim_prompt': LowdimEmbeddingWrapper | |||
| }[peft_params.pop('kind')] | |||
| delta_module = peft_class.mutate( | |||
| model=model, | |||
| **peft_params | |||
| ) | |||
| elif config.best_finder.save: | |||
| raise NotImplementedError() | |||
| freeze_notes = auto_freeze(model, config.hot_modules) | |||
| # ______________________LOAD DATA_____________________________ | |||
| data_loader = AutoLoad(tokenizer) | |||
| dataset = data_loader.get_and_map(config.tasks[0]) | |||
| train_loader, valid_loader = generate_dataloader(tokenizer, dataset['train'], dataset['valid'], config) | |||
| # ______________________TRAIN_____________________________ | |||
| print(delta_module) | |||
| wandb.init( | |||
| name=config.wandb_name, | |||
| project=WANDB_PROJECT_NAME, | |||
| config=config.to_dict(), | |||
| notes=freeze_notes | |||
| ) | |||
| optimizer = torch.optim.AdamW(model.parameters(), lr=config.learning_rate) | |||
| best_finder = BestFinder(config.best_finder.higher_better) | |||
| model.to(DEVICE) | |||
| epochs_range = range(config.num_epochs) | |||
| if USE_TQDM: | |||
| epochs_range = tqdm(epochs_range, position=1, desc="EPOCHS", leave=False) | |||
| for epoch in epochs_range: | |||
| epoch_results = {} | |||
| epoch_results.update( | |||
| train_loop( | |||
| model=model, | |||
| loader=train_loader, | |||
| optimizer=optimizer, | |||
| use_tqdm=USE_TQDM | |||
| ) | |||
| ) | |||
| epoch_results.update( | |||
| valid_loop( | |||
| model=model, | |||
| loader=valid_loader, | |||
| use_tqdm=USE_TQDM | |||
| ) | |||
| ) | |||
| if config.best_finder.save: | |||
| if best_finder.is_better(epoch_results[config.best_finder.metric]): | |||
| torch.save(delta_module.peft_state_dict(), './best.pt') | |||
| wandb.log(epoch_results) | |||
| wandb.finish() | |||
| if __name__ == '__main__': | |||
| print_system_info() | |||
| silent_logs() | |||
| run_configs = configs.run_configs | |||
| if USE_TQDM: | |||
| run_configs = tqdm(run_configs, position=0, desc="Experiment") | |||
| for run_config in run_configs: | |||
| run_experminent(run_config) | |||
+ 146
- 0
06_PCAEmb/Untitled.ipynb
File diff suppressed because it is too large
View File
+ 1109
- 0
07_AnalyzeCombPrompts/Untitled.ipynb
File diff suppressed because it is too large
View File
+ 219
- 0
08_ICLR/attempt.ipynb
View File
| @@ -0,0 +1,219 @@ | |||
| { | |||
| "cells": [ | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 1, | |||
| "id": "e6ecf439-a0db-42e0-a6b9-f512198b0e0e", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import torch" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 4, | |||
| "id": "4bcc7c7e-711a-4cd9-b901-d6ff76938a75", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "best_path = '/home/msadraei/trained_final/iclr_resp_t5_small_glue-cola/10_attempt/best.pt'\n", | |||
| "first_path = '/home/msadraei/trained_final/iclr_resp_t5_small_glue-cola/10_attempt/first.pt'" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 5, | |||
| "id": "eaa4a300-1e6c-46f0-8f0d-16e9c71c2388", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "best = torch.load(best_path)\n", | |||
| "first = torch.load(first_path)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 8, | |||
| "id": "c5e0b6bb-3bde-4526-8a6a-5dac0a3b3cc3", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "sadcl_p_target\n", | |||
| "tensor(42.7208, device='cuda:0')\n", | |||
| "pretrained_tasks\n", | |||
| "tensor(0., device='cuda:0')\n", | |||
| "sadcl_attention_score.g_network.0.weight\n", | |||
| "tensor(157.3032, device='cuda:0')\n", | |||
| "sadcl_attention_score.g_network.2.weight\n", | |||
| "tensor(154.6590, device='cuda:0')\n", | |||
| "sadcl_attention_score.g_network.3.weight\n", | |||
| "tensor(18.1127, device='cuda:0')\n", | |||
| "sadcl_attention_score.g_network.3.bias\n", | |||
| "tensor(19.0149, device='cuda:0')\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "for key in best.keys():\n", | |||
| " print(key)\n", | |||
| " v1 = first[key]\n", | |||
| " v2 = best[key]\n", | |||
| " print(torch.norm(v1 - v2))" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 13, | |||
| "id": "42815cf2-b8bf-4219-a3fd-ebbe92fb5c32", | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [ | |||
| "base_path = '/home/msadraei/trained_final/forward_transfer_test_t5_base_superglue-rte/10_combine_128_4tasks_new_impl_tie_50/100'\n", | |||
| "last_path = f'{base_path}/last.pt'\n", | |||
| "best_path = f'{base_path}/best.pt'\n", | |||
| "first_path = f'{base_path}/first.pt'" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 14, | |||
| "id": "880cb651-ddea-4564-93ab-c5f52e1f02dd", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import torch\n", | |||
| "last = torch.load(last_path)\n", | |||
| "best = torch.load(best_path)\n", | |||
| "first = torch.load(first_path)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 15, | |||
| "id": "ee4b3287-203f-49b0-8b89-6070f9ff4062", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import numpy as np\n", | |||
| "def pretrained_coeff(state_dict):\n", | |||
| " return np.stack([\n", | |||
| " val.cpu().numpy()\n", | |||
| " for key, val in state_dict.items()\n", | |||
| " if 'sadcl_coeff_pretrained' in key\n", | |||
| " ])" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 16, | |||
| "id": "26518ecd-8cc1-4543-acaf-56637295bbe8", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "last_coeff = pretrained_coeff(best)\n", | |||
| "best_coeff = pretrained_coeff(best)\n", | |||
| "first_coeff = pretrained_coeff(first)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 17, | |||
| "id": "5a850a65-724a-483d-abb3-b7de6118db31", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "text/plain": [ | |||
| "array([[0.43, 0.42, 0.42, 0.42],\n", | |||
| " [0.43, 0.42, 0.42, 0.42],\n", | |||
| " [0.43, 0.42, 0.42, 0.42],\n", | |||
| " [0.43, 0.42, 0.42, 0.42],\n", | |||
| " [0.43, 0.42, 0.42, 0.42],\n", | |||
| " [0.43, 0.42, 0.42, 0.42],\n", | |||
| " [0.43, 0.42, 0.42, 0.42],\n", | |||
| " [0.43, 0.42, 0.42, 0.42],\n", | |||
| " [0.43, 0.42, 0.42, 0.42],\n", | |||
| " [0.43, 0.42, 0.42, 0.42]], dtype=float32)" | |||
| ] | |||
| }, | |||
| "execution_count": 17, | |||
| "metadata": {}, | |||
| "output_type": "execute_result" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "np.round(last_coeff/ 100 , 2)\n" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 65, | |||
| "id": "7182b595-5bb3-4c06-88dc-1f50ed774500", | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "text/plain": [ | |||
| "tensor(34.9105)" | |||
| ] | |||
| }, | |||
| "execution_count": 65, | |||
| "metadata": {}, | |||
| "output_type": "execute_result" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "torch.linalg.vector_norm(torch.Tensor(best_coeff[0]), ord=1)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": null, | |||
| "id": "9e2a2080-9450-4df2-b20e-4619e3f92c1b", | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [] | |||
| } | |||
| ], | |||
| "metadata": { | |||
| "kernelspec": { | |||
| "display_name": "Python [conda env:deep]", | |||
| "language": "python", | |||
| "name": "conda-env-deep-py" | |||
| }, | |||
| "language_info": { | |||
| "codemirror_mode": { | |||
| "name": "ipython", | |||
| "version": 3 | |||
| }, | |||
| "file_extension": ".py", | |||
| "mimetype": "text/x-python", | |||
| "name": "python", | |||
| "nbconvert_exporter": "python", | |||
| "pygments_lexer": "ipython3", | |||
| "version": "3.10.13" | |||
| } | |||
| }, | |||
| "nbformat": 4, | |||
| "nbformat_minor": 5 | |||
| } | |||
+ 538
- 0
08_ICLR/explore_ds.ipynb
View File
| @@ -0,0 +1,538 @@ | |||
| { | |||
| "cells": [ | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 1, | |||
| "id": "3526e83a-baa5-4278-81ce-e142e0a6d208", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import sys\n", | |||
| "from pathlib import Path\n", | |||
| "sys.path.append(Path('./').absolute().parent.__str__())\n", | |||
| "from _datasets import AutoLoad" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 48, | |||
| "id": "5a0264f8-4b67-44e2-8aa9-468ae8b249b5", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "(12, 15)\n", | |||
| "{'a': 'b'}\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "class Test():\n", | |||
| " def __new__(cls, *args, **kwargs):\n", | |||
| " print(args)\n", | |||
| " print(kwargs)\n", | |||
| "Test(12, 15, a='b')" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 10, | |||
| "id": "f0d8ead2-cfa6-4044-8e7a-6b7146bea9cd", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "from transformers import T5TokenizerFast\n", | |||
| "\n", | |||
| "tokenizer = T5TokenizerFast.from_pretrained('google/t5-small-lm-adapt')\n", | |||
| "tokenizer._is_seq2seq = True\n", | |||
| "loader = AutoLoad(tokenizer=tokenizer)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 19, | |||
| "id": "07c556fd-780d-4aee-a5e9-ad81a474d94b", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "text/plain": [ | |||
| "['sentence1', 'sentence2']" | |||
| ] | |||
| }, | |||
| "execution_count": 19, | |||
| "metadata": {}, | |||
| "output_type": "execute_result" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "loader.glue_helper.get_task_input('stsb')" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 11, | |||
| "id": "04feb162-ef3f-42a8-ab00-23d3faea5209", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "application/vnd.jupyter.widget-view+json": { | |||
| "model_id": "8165afbb7bcb474e80b9538b0c0c39da", | |||
| "version_major": 2, | |||
| "version_minor": 0 | |||
| }, | |||
| "text/plain": [ | |||
| "Map: 0%| | 0/5749 [00:00<?, ? examples/s]" | |||
| ] | |||
| }, | |||
| "metadata": {}, | |||
| "output_type": "display_data" | |||
| }, | |||
| { | |||
| "data": { | |||
| "application/vnd.jupyter.widget-view+json": { | |||
| "model_id": "95318c2e7b684eabb280fd34d014f1d3", | |||
| "version_major": 2, | |||
| "version_minor": 0 | |||
| }, | |||
| "text/plain": [ | |||
| "Map: 0%| | 0/1500 [00:00<?, ? examples/s]" | |||
| ] | |||
| }, | |||
| "metadata": {}, | |||
| "output_type": "display_data" | |||
| }, | |||
| { | |||
| "data": { | |||
| "application/vnd.jupyter.widget-view+json": { | |||
| "model_id": "0e47b3895f4d4f77920c8d82579ec683", | |||
| "version_major": 2, | |||
| "version_minor": 0 | |||
| }, | |||
| "text/plain": [ | |||
| "Map: 0%| | 0/1500 [00:00<?, ? examples/s]" | |||
| ] | |||
| }, | |||
| "metadata": {}, | |||
| "output_type": "display_data" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "ds = loader.get_and_map('glue:stsb')" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 43, | |||
| "id": "9dcf1e0c-e703-4e30-9dab-bfc54cde7d3f", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "application/vnd.jupyter.widget-view+json": { | |||
| "model_id": "e703362287be445fa8f3949c592b1c26", | |||
| "version_major": 2, | |||
| "version_minor": 0 | |||
| }, | |||
| "text/plain": [ | |||
| "Downloading data: 0%| | 0.00/51.8M [00:00<?, ?B/s]" | |||
| ] | |||
| }, | |||
| "metadata": {}, | |||
| "output_type": "display_data" | |||
| }, | |||
| { | |||
| "data": { | |||
| "application/vnd.jupyter.widget-view+json": { | |||
| "model_id": "2d231baabf80401eacf8c400a811c5ac", | |||
| "version_major": 2, | |||
| "version_minor": 0 | |||
| }, | |||
| "text/plain": [ | |||
| "Generating train split: 0%| | 0/100730 [00:00<?, ? examples/s]" | |||
| ] | |||
| }, | |||
| "metadata": {}, | |||
| "output_type": "display_data" | |||
| }, | |||
| { | |||
| "data": { | |||
| "application/vnd.jupyter.widget-view+json": { | |||
| "model_id": "6c699b3fdf1e468e9ef8a442651d1f7c", | |||
| "version_major": 2, | |||
| "version_minor": 0 | |||
| }, | |||
| "text/plain": [ | |||
| "Generating validation split: 0%| | 0/10000 [00:00<?, ? examples/s]" | |||
| ] | |||
| }, | |||
| "metadata": {}, | |||
| "output_type": "display_data" | |||
| }, | |||
| { | |||
| "data": { | |||
| "application/vnd.jupyter.widget-view+json": { | |||
| "model_id": "91acd57830124beeb29c9869f3b67788", | |||
| "version_major": 2, | |||
| "version_minor": 0 | |||
| }, | |||
| "text/plain": [ | |||
| "Generating test split: 0%| | 0/10000 [00:00<?, ? examples/s]" | |||
| ] | |||
| }, | |||
| "metadata": {}, | |||
| "output_type": "display_data" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "from datasets import load_dataset\n", | |||
| "\n", | |||
| "ds = load_dataset('super_glue', 'record')" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 46, | |||
| "id": "c4d652d7-8237-4e5a-85e5-faf39a88eea5", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "text/plain": [ | |||
| "{'passage': \"For everyone who has ever thought about shooting their boss - metaphorically, o fcourse - this one is for you. An employee of a Texas armored car company got to do just that this week to 'demonstrate that they take client safety seriously'. And to further that demonstration, the CEO was sitting alone inside the Mercedes-Benz as 12 rounds from an AK-47 rained down upon the SUV. The company, Texas Armoring Corporation, has supplied protected vehicles to the Pope, celebrities like rapper T.I. and actor Steven Segal and oil executives in West Africa, according to My San Antonio. Texas Armoring Corp. & Jason Forston.\\n@highlight\\nTexas Armoring Corporation created a video to show the effectiveness of their armored\\n@highlight\\nCEO R. Trent Kimball sat in the drivers seat of a Mercedes-Benz SUV\\n@highlight\\nTotal of 12 rounds fired at the windscreen\\n@highlight\\nCompany known for working with celebrities, oil barons and even the Pope\",\n", | |||
| " 'query': \"'When it comes to assuring our clients' safety, we take product testing extremely seriously,' @placeholder says in a video taken of the display.\",\n", | |||
| " 'entities': ['Steven Segal',\n", | |||
| " 'Texas Armoring Corp.',\n", | |||
| " 'Trent Kimball',\n", | |||
| " 'Texas Armoring Corporation',\n", | |||
| " 'Texas',\n", | |||
| " 'AK-47',\n", | |||
| " 'Pope',\n", | |||
| " 'Mercedes-Benz',\n", | |||
| " 'San Antonio',\n", | |||
| " 'West Africa',\n", | |||
| " 'rapper T.I.',\n", | |||
| " 'Jason Forston'],\n", | |||
| " 'entity_spans': {'text': ['Texas',\n", | |||
| " 'Mercedes-Benz',\n", | |||
| " 'AK-47',\n", | |||
| " 'Texas Armoring Corporation',\n", | |||
| " 'Pope',\n", | |||
| " 'rapper T.I.',\n", | |||
| " 'Steven Segal',\n", | |||
| " 'West Africa',\n", | |||
| " 'San Antonio',\n", | |||
| " 'Texas Armoring Corp.',\n", | |||
| " 'Jason Forston',\n", | |||
| " 'Texas Armoring Corporation',\n", | |||
| " 'Trent Kimball',\n", | |||
| " 'Mercedes-Benz',\n", | |||
| " 'Pope'],\n", | |||
| " 'start': [128,\n", | |||
| " 313,\n", | |||
| " 348,\n", | |||
| " 393,\n", | |||
| " 460,\n", | |||
| " 483,\n", | |||
| " 505,\n", | |||
| " 540,\n", | |||
| " 569,\n", | |||
| " 582,\n", | |||
| " 605,\n", | |||
| " 631,\n", | |||
| " 735,\n", | |||
| " 778,\n", | |||
| " 929],\n", | |||
| " 'end': [133,\n", | |||
| " 326,\n", | |||
| " 353,\n", | |||
| " 419,\n", | |||
| " 464,\n", | |||
| " 494,\n", | |||
| " 517,\n", | |||
| " 551,\n", | |||
| " 580,\n", | |||
| " 602,\n", | |||
| " 618,\n", | |||
| " 657,\n", | |||
| " 748,\n", | |||
| " 791,\n", | |||
| " 933]},\n", | |||
| " 'answers': ['Trent Kimball'],\n", | |||
| " 'idx': {'passage': 4, 'query': 10}}" | |||
| ] | |||
| }, | |||
| "execution_count": 46, | |||
| "metadata": {}, | |||
| "output_type": "execute_result" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "ds['train'][10]" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 31, | |||
| "id": "c77ab84e-1cd2-4038-9354-b7f2668bc99d", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "from evaluate import load" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 38, | |||
| "id": "dc4b8326-43c7-4941-aae5-3cbea1f793cb", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "text/plain": [ | |||
| "{'exact_match': 0.0, 'f1_m': 0.0, 'f1_a': 0.0}" | |||
| ] | |||
| }, | |||
| "execution_count": 38, | |||
| "metadata": {}, | |||
| "output_type": "execute_result" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "metric = load('super_glue', 'multirc')\n", | |||
| "metric.compute(\n", | |||
| " predictions=[{'prediction': 0, 'idx':{'paragraph': 0, 'question': 0, 'answer': 2}}],\n", | |||
| " references=[1]\n", | |||
| ") " | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 39, | |||
| "id": "13da4dac-ae6f-4a36-a6ed-ebf077eef625", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "text/plain": [ | |||
| "EvaluationModule(name: \"super_glue\", module_type: \"metric\", features: {'predictions': {'idx': {'answer': Value(dtype='int64', id=None), 'paragraph': Value(dtype='int64', id=None), 'question': Value(dtype='int64', id=None)}, 'prediction': Value(dtype='int64', id=None)}, 'references': Value(dtype='int64', id=None)}, usage: \"\"\"\n", | |||
| "Compute SuperGLUE evaluation metric associated to each SuperGLUE dataset.\n", | |||
| "Args:\n", | |||
| " predictions: list of predictions to score. Depending on the SuperGlUE subset:\n", | |||
| " - for 'record': list of question-answer dictionaries with the following keys:\n", | |||
| " - 'idx': index of the question as specified by the dataset\n", | |||
| " - 'prediction_text': the predicted answer text\n", | |||
| " - for 'multirc': list of question-answer dictionaries with the following keys:\n", | |||
| " - 'idx': index of the question-answer pair as specified by the dataset\n", | |||
| " - 'prediction': the predicted answer label\n", | |||
| " - otherwise: list of predicted labels\n", | |||
| " references: list of reference labels. Depending on the SuperGLUE subset:\n", | |||
| " - for 'record': list of question-answers dictionaries with the following keys:\n", | |||
| " - 'idx': index of the question as specified by the dataset\n", | |||
| " - 'answers': list of possible answers\n", | |||
| " - otherwise: list of reference labels\n", | |||
| "Returns: depending on the SuperGLUE subset:\n", | |||
| " - for 'record':\n", | |||
| " - 'exact_match': Exact match between answer and gold answer\n", | |||
| " - 'f1': F1 score\n", | |||
| " - for 'multirc':\n", | |||
| " - 'exact_match': Exact match between answer and gold answer\n", | |||
| " - 'f1_m': Per-question macro-F1 score\n", | |||
| " - 'f1_a': Average F1 score over all answers\n", | |||
| " - for 'axb':\n", | |||
| " 'matthews_correlation': Matthew Correlation\n", | |||
| " - for 'cb':\n", | |||
| " - 'accuracy': Accuracy\n", | |||
| " - 'f1': F1 score\n", | |||
| " - for all others:\n", | |||
| " - 'accuracy': Accuracy\n", | |||
| "Examples:\n", | |||
| "\n", | |||
| " >>> super_glue_metric = evaluate.load('super_glue', 'copa') # any of [\"copa\", \"rte\", \"wic\", \"wsc\", \"wsc.fixed\", \"boolq\", \"axg\"]\n", | |||
| " >>> predictions = [0, 1]\n", | |||
| " >>> references = [0, 1]\n", | |||
| " >>> results = super_glue_metric.compute(predictions=predictions, references=references)\n", | |||
| " >>> print(results)\n", | |||
| " {'accuracy': 1.0}\n", | |||
| "\n", | |||
| " >>> super_glue_metric = evaluate.load('super_glue', 'cb')\n", | |||
| " >>> predictions = [0, 1]\n", | |||
| " >>> references = [0, 1]\n", | |||
| " >>> results = super_glue_metric.compute(predictions=predictions, references=references)\n", | |||
| " >>> print(results)\n", | |||
| " {'accuracy': 1.0, 'f1': 1.0}\n", | |||
| "\n", | |||
| " >>> super_glue_metric = evaluate.load('super_glue', 'record')\n", | |||
| " >>> predictions = [{'idx': {'passage': 0, 'query': 0}, 'prediction_text': 'answer'}]\n", | |||
| " >>> references = [{'idx': {'passage': 0, 'query': 0}, 'answers': ['answer', 'another_answer']}]\n", | |||
| " >>> results = super_glue_metric.compute(predictions=predictions, references=references)\n", | |||
| " >>> print(results)\n", | |||
| " {'exact_match': 1.0, 'f1': 1.0}\n", | |||
| "\n", | |||
| " >>> super_glue_metric = evaluate.load('super_glue', 'multirc')\n", | |||
| " >>> predictions = [{'idx': {'answer': 0, 'paragraph': 0, 'question': 0}, 'prediction': 0}, {'idx': {'answer': 1, 'paragraph': 2, 'question': 3}, 'prediction': 1}]\n", | |||
| " >>> references = [0, 1]\n", | |||
| " >>> results = super_glue_metric.compute(predictions=predictions, references=references)\n", | |||
| " >>> print(results)\n", | |||
| " {'exact_match': 1.0, 'f1_m': 1.0, 'f1_a': 1.0}\n", | |||
| "\n", | |||
| " >>> super_glue_metric = evaluate.load('super_glue', 'axb')\n", | |||
| " >>> references = [0, 1]\n", | |||
| " >>> predictions = [0, 1]\n", | |||
| " >>> results = super_glue_metric.compute(predictions=predictions, references=references)\n", | |||
| " >>> print(results)\n", | |||
| " {'matthews_correlation': 1.0}\n", | |||
| "\"\"\", stored examples: 0)" | |||
| ] | |||
| }, | |||
| "execution_count": 39, | |||
| "metadata": {}, | |||
| "output_type": "execute_result" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "metric" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 29, | |||
| "id": "020f35a1-09ec-4ef3-94f4-28144778a3ab", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n", | |||
| "0.1\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "from transformers import T5ForConditionalGeneration\n", | |||
| "import torch\n", | |||
| "\n", | |||
| "model = T5ForConditionalGeneration.from_pretrained('google/t5-small-lm-adapt')\n", | |||
| "\n", | |||
| "def mutate_remove_dropout(model):\n", | |||
| " for module in model.modules():\n", | |||
| " if isinstance(module, torch.nn.Dropout):\n", | |||
| " module._backup_p = module.p\n", | |||
| " module.p = 0\n", | |||
| " print(module._backup_p)\n", | |||
| "mutate_remove_dropout(model)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": null, | |||
| "id": "146e1eb3-f6a6-41d2-ab84-13b62de8983a", | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [] | |||
| } | |||
| ], | |||
| "metadata": { | |||
| "kernelspec": { | |||
| "display_name": "Python [conda env:deep]", | |||
| "language": "python", | |||
| "name": "conda-env-deep-py" | |||
| }, | |||
| "language_info": { | |||
| "codemirror_mode": { | |||
| "name": "ipython", | |||
| "version": 3 | |||
| }, | |||
| "file_extension": ".py", | |||
| "mimetype": "text/x-python", | |||
| "name": "python", | |||
| "nbconvert_exporter": "python", | |||
| "pygments_lexer": "ipython3", | |||
| "version": "3.10.13" | |||
| } | |||
| }, | |||
| "nbformat": 4, | |||
| "nbformat_minor": 5 | |||
| } | |||
+ 1
- 0
09_Cluster/.virtual_documents/Untitled.ipynb
View File
| @@ -0,0 +1 @@ | |||
| import nu | |||
+ 42
- 0
09_Cluster/config1.yaml
View File
| @@ -0,0 +1,42 @@ | |||
| default: &default | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| base_save_path: /disks/ssd/trained_final/dummy_test | |||
| model_name: google/t5-base-lm-adapt | |||
| project_name_prefix: dummy_test_new_power | |||
| experiment_name_suffix: null | |||
| train_batch_size: 8 | |||
| valid_batch_size: 8 | |||
| remove_dropout: true | |||
| learning_rate: 0.01 | |||
| weight_decay: 0.01 | |||
| num_epochs: 80 | |||
| peft_params: null # no mutation | |||
| hot_modules: | |||
| - sadcl | |||
| best_finder: | |||
| save: True | |||
| metric: valid_mean | |||
| higher_better: true | |||
| tasks: | |||
| - superglue:boolq | |||
| pp: &pp | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_small_glue-mnli/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_small_glue-sst2/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_small_glue-qqp/10_combine_128 | |||
| run_configs: | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 128 | |||
| # - <<: *default | |||
| # learning_rate: 0.3 | |||
| # peft_params: | |||
| # kind: residual | |||
| # n_tokens: 10 | |||
| # mlp_size: 128 | |||
+ 74
- 0
09_Cluster/config2.yaml
View File
| @@ -0,0 +1,74 @@ | |||
| default: &default | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| base_save_path: /home/msadraei/trained_final | |||
| model_name: google/t5-base-lm-adapt | |||
| project_name_prefix: iclr_attempt_lmt5 | |||
| experiment_name_suffix: null | |||
| train_batch_size: 32 | |||
| valid_batch_size: 32 | |||
| remove_dropout: true | |||
| learning_rate: 0.01 | |||
| weight_decay: 0.01 | |||
| num_epochs: 40 | |||
| peft_params: null # no mutation | |||
| hot_modules: | |||
| - sadcl | |||
| best_finder: | |||
| save: True | |||
| metric: valid_mean | |||
| higher_better: true | |||
| tasks: | |||
| # - superglue:rte | |||
| # - superglue:cb | |||
| # - superglue:wic | |||
| # - superglue:copa | |||
| # - glue:cola | |||
| # - glue:mrpc | |||
| # - superglue:boolq | |||
| # - glue:stsb | |||
| - superglue:multirc | |||
| pp: &pp | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_base_glue-mnli/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_base_glue-sst2/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_base_glue-qqp/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_base_glue-qnli/10_combine_128 | |||
| run_configs: | |||
| - <<: *default | |||
| learning_rate: 0.3 | |||
| weight_decay: 0.00001 | |||
| peft_params: | |||
| kind: attempt | |||
| n_tokens: 10 | |||
| g_bottleneck: 100 | |||
| pretrained_paths: *pp | |||
| # - <<: *default_large | |||
| # learning_rate: 0.3 | |||
| # weight_decay: 0.00001 | |||
| # peft_params: | |||
| # kind: attempt | |||
| # n_tokens: 10 | |||
| # g_bottleneck: 100 | |||
| # pretrained_paths: *pp | |||
| # - <<: *default | |||
| # learning_rate: 0.3 | |||
| # remove_dropout: false | |||
| # experiment_name_suffix: dropout | |||
| # weight_decay: 0.00001 | |||
| # peft_params: | |||
| # kind: attempt | |||
| # n_tokens: 10 | |||
| # g_bottleneck: 100 | |||
| # pretrained_paths: *pp | |||
| # - <<: *default_large | |||
| # learning_rate: 0.3 | |||
| # remove_dropout: false | |||
| # experiment_name_suffix: dropout | |||
| # weight_decay: 0.00001 | |||
| # peft_params: | |||
| # kind: attempt | |||
| # n_tokens: 10 | |||
| # g_bottleneck: 100 | |||
| # pretrained_paths: *pp | |||
+ 53
- 0
09_Cluster/config3.yaml
View File
| @@ -0,0 +1,53 @@ | |||
| default: &default | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| base_save_path: /home/msadraei/trained_final | |||
| model_name: t5-small | |||
| project_name_prefix: iclr_orig_t5 | |||
| experiment_name_suffix: null | |||
| train_batch_size: 24 | |||
| valid_batch_size: 24 | |||
| remove_dropout: true | |||
| learning_rate: 0.01 | |||
| weight_decay: 0.01 | |||
| num_epochs: 80 | |||
| peft_params: null # no mutation | |||
| hot_modules: | |||
| - sadcl | |||
| best_finder: | |||
| save: True | |||
| metric: valid_mean | |||
| higher_better: true | |||
| tasks: | |||
| - superglue:rte | |||
| - superglue:cb | |||
| - superglue:wic | |||
| - superglue:copa | |||
| - glue:cola | |||
| - glue:mrpc | |||
| - superglue:boolq | |||
| - glue:qqp | |||
| - glue:qnli | |||
| - glue:mnli | |||
| - glue:sst2 | |||
| - glue:stsb | |||
| pp: &pp | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_small_glue-mnli/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_small_glue-sst2/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_small_glue-qqp/10_combine_128 | |||
| run_configs: | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 128 | |||
| # - <<: *default | |||
| # learning_rate: 0.3 | |||
| # peft_params: | |||
| # kind: residual | |||
| # n_tokens: 10 | |||
| # mlp_size: 128 | |||
+ 74
- 0
09_Cluster/config4.yaml
View File
| @@ -0,0 +1,74 @@ | |||
| default: &default | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| base_save_path: /home/msadraei/trained_final | |||
| model_name: google/t5-base-lm-adapt | |||
| project_name_prefix: iclr_attempt_lmt5 | |||
| experiment_name_suffix: null | |||
| train_batch_size: 24 | |||
| valid_batch_size: 24 | |||
| remove_dropout: true | |||
| learning_rate: 0.01 | |||
| weight_decay: 0.01 | |||
| num_epochs: 80 | |||
| peft_params: null # no mutation | |||
| hot_modules: | |||
| - sadcl | |||
| best_finder: | |||
| save: True | |||
| metric: valid_mean | |||
| higher_better: true | |||
| tasks: | |||
| # - superglue:rte | |||
| # - superglue:cb | |||
| # - superglue:wic | |||
| # - superglue:copa | |||
| # - glue:cola | |||
| # - glue:mrpc | |||
| # - superglue:boolq | |||
| # - glue:stsb | |||
| - superglue:multirc | |||
| pp: &pp | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_base_glue-mnli/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_base_glue-sst2/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_base_glue-qqp/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_base_glue-qnli/10_combine_128 | |||
| run_configs: | |||
| # - <<: *default | |||
| # learning_rate: 0.3 | |||
| # weight_decay: 0.00001 | |||
| # peft_params: | |||
| # kind: attempt | |||
| # n_tokens: 10 | |||
| # g_bottleneck: 100 | |||
| # pretrained_paths: *pp | |||
| # - <<: *default_large | |||
| # learning_rate: 0.3 | |||
| # weight_decay: 0.00001 | |||
| # peft_params: | |||
| # kind: attempt | |||
| # n_tokens: 10 | |||
| # g_bottleneck: 100 | |||
| # pretrained_paths: *pp | |||
| - <<: *default | |||
| learning_rate: 0.3 | |||
| remove_dropout: false | |||
| experiment_name_suffix: dropout | |||
| weight_decay: 0.00001 | |||
| peft_params: | |||
| kind: attempt | |||
| n_tokens: 10 | |||
| g_bottleneck: 100 | |||
| pretrained_paths: *pp | |||
| # - <<: *default_large | |||
| # learning_rate: 0.3 | |||
| # remove_dropout: false | |||
| # experiment_name_suffix: dropout | |||
| # weight_decay: 0.00001 | |||
| # peft_params: | |||
| # kind: attempt | |||
| # n_tokens: 10 | |||
| # g_bottleneck: 100 | |||
| # pretrained_paths: *pp | |||
+ 39
- 0
09_Cluster/config5.yaml
View File
| @@ -0,0 +1,39 @@ | |||
| default: &default | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| base_save_path: /home/msadraei/trained_final | |||
| model_name: google/t5-base-lm-adapt | |||
| project_name_prefix: iclr_softmax_effect | |||
| experiment_name_suffix: null | |||
| train_batch_size: 24 | |||
| valid_batch_size: 24 | |||
| remove_dropout: true | |||
| learning_rate: 0.01 | |||
| weight_decay: 0.01 | |||
| num_epochs: 20 | |||
| peft_params: null # no mutation | |||
| hot_modules: | |||
| - sadcl | |||
| best_finder: | |||
| save: True | |||
| metric: valid_mean | |||
| higher_better: true | |||
| tasks: | |||
| - glue:qqp | |||
| - glue:qnli | |||
| - glue:mnli | |||
| - glue:sst2 | |||
| run_configs: | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 128 | |||
| softmax: true | |||
| # - <<: *default | |||
| # learning_rate: 0.3 | |||
| # peft_params: | |||
| # kind: residual | |||
| # n_tokens: 10 | |||
| # mlp_size: 128 | |||
+ 48
- 0
09_Cluster/config6.yaml
View File
| @@ -0,0 +1,48 @@ | |||
| default: &default | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| base_save_path: /home/msadraei/trained_final | |||
| model_name: google/t5-small-lm-adapt | |||
| project_name_prefix: iclr_softmax_effect | |||
| experiment_name_suffix: null | |||
| train_batch_size: 32 | |||
| valid_batch_size: 32 | |||
| remove_dropout: true | |||
| learning_rate: 0.01 | |||
| weight_decay: 0.01 | |||
| num_epochs: 20 | |||
| peft_params: null # no mutation | |||
| hot_modules: | |||
| - sadcl | |||
| best_finder: | |||
| save: True | |||
| metric: valid_mean | |||
| higher_better: true | |||
| tasks: | |||
| # - superglue:rte | |||
| # - superglue:cb | |||
| # - superglue:wic | |||
| # - superglue:copa | |||
| # - glue:cola | |||
| # - glue:mrpc | |||
| # - superglue:boolq | |||
| # - glue:stsb | |||
| # - glue:qqp | |||
| # - glue:qnli | |||
| # - glue:mnli | |||
| # - glue:sst2 | |||
| - superglue:multirc | |||
| run_configs: | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 128 | |||
| softmax: true | |||
| # - <<: *default | |||
| # learning_rate: 0.3 | |||
| # peft_params: | |||
| # kind: residual | |||
| # n_tokens: 10 | |||
| # mlp_size: 128 | |||
+ 54
- 0
09_Cluster/config7.yaml
View File
| @@ -0,0 +1,54 @@ | |||
| default: &default | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| base_save_path: /home/msadraei/trained_final | |||
| model_name: t5-base | |||
| project_name_prefix: iclr_orig_t5 | |||
| experiment_name_suffix: null | |||
| train_batch_size: 24 | |||
| valid_batch_size: 24 | |||
| remove_dropout: true | |||
| learning_rate: 0.01 | |||
| weight_decay: 0.01 | |||
| num_epochs: 80 | |||
| peft_params: null # no mutation | |||
| hot_modules: | |||
| - sadcl | |||
| best_finder: | |||
| save: True | |||
| metric: valid_mean | |||
| higher_better: true | |||
| tasks: | |||
| # - superglue:rte | |||
| # - superglue:cb | |||
| # - superglue:wic | |||
| # - superglue:copa | |||
| # - glue:cola | |||
| # - glue:mrpc | |||
| # - superglue:boolq | |||
| # - glue:qqp | |||
| # - glue:qnli | |||
| # - glue:mnli | |||
| # - glue:sst2 | |||
| # - glue:stsb | |||
| - superglue:multirc | |||
| pp: &pp | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_small_glue-mnli/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_small_glue-sst2/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_small_glue-qqp/10_combine_128 | |||
| run_configs: | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 128 | |||
| # - <<: *default | |||
| # learning_rate: 0.3 | |||
| # peft_params: | |||
| # kind: residual | |||
| # n_tokens: 10 | |||
| # mlp_size: 128 | |||
+ 74
- 0
09_Cluster/config8.yaml
View File
| @@ -0,0 +1,74 @@ | |||
| default: &default | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| base_save_path: /home/msadraei/trained_final | |||
| model_name: google/t5-small-lm-adapt | |||
| project_name_prefix: iclr_attempt_lmt5 | |||
| experiment_name_suffix: null | |||
| train_batch_size: 32 | |||
| valid_batch_size: 32 | |||
| remove_dropout: true | |||
| learning_rate: 0.01 | |||
| weight_decay: 0.01 | |||
| num_epochs: 40 | |||
| peft_params: null # no mutation | |||
| hot_modules: | |||
| - sadcl | |||
| best_finder: | |||
| save: True | |||
| metric: valid_mean | |||
| higher_better: true | |||
| tasks: | |||
| # - superglue:rte | |||
| # - superglue:cb | |||
| # - superglue:wic | |||
| # - superglue:copa | |||
| # - glue:cola | |||
| # - glue:mrpc | |||
| # - superglue:boolq | |||
| # - glue:stsb | |||
| - superglue:multirc | |||
| pp: &pp | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_small_glue-mnli/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_small_glue-sst2/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_small_glue-qqp/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_small_glue-qnli/10_combine_128 | |||
| run_configs: | |||
| - <<: *default | |||
| learning_rate: 0.3 | |||
| weight_decay: 0.00001 | |||
| peft_params: | |||
| kind: attempt | |||
| n_tokens: 10 | |||
| g_bottleneck: 100 | |||
| pretrained_paths: *pp | |||
| # - <<: *default_large | |||
| # learning_rate: 0.3 | |||
| # weight_decay: 0.00001 | |||
| # peft_params: | |||
| # kind: attempt | |||
| # n_tokens: 10 | |||
| # g_bottleneck: 100 | |||
| # pretrained_paths: *pp | |||
| # - <<: *default | |||
| # learning_rate: 0.3 | |||
| # remove_dropout: false | |||
| # experiment_name_suffix: dropout | |||
| # weight_decay: 0.00001 | |||
| # peft_params: | |||
| # kind: attempt | |||
| # n_tokens: 10 | |||
| # g_bottleneck: 100 | |||
| # pretrained_paths: *pp | |||
| # - <<: *default_large | |||
| # learning_rate: 0.3 | |||
| # remove_dropout: false | |||
| # experiment_name_suffix: dropout | |||
| # weight_decay: 0.00001 | |||
| # peft_params: | |||
| # kind: attempt | |||
| # n_tokens: 10 | |||
| # g_bottleneck: 100 | |||
| # pretrained_paths: *pp | |||
+ 74
- 0
09_Cluster/config9.yaml
View File
| @@ -0,0 +1,74 @@ | |||
| default: &default | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| base_save_path: /home/msadraei/trained_final | |||
| model_name: google/t5-small-lm-adapt | |||
| project_name_prefix: iclr_attempt_lmt5 | |||
| experiment_name_suffix: null | |||
| train_batch_size: 32 | |||
| valid_batch_size: 32 | |||
| remove_dropout: true | |||
| learning_rate: 0.01 | |||
| weight_decay: 0.01 | |||
| num_epochs: 40 | |||
| peft_params: null # no mutation | |||
| hot_modules: | |||
| - sadcl | |||
| best_finder: | |||
| save: True | |||
| metric: valid_mean | |||
| higher_better: true | |||
| tasks: | |||
| # - superglue:rte | |||
| # - superglue:cb | |||
| # - superglue:wic | |||
| # - superglue:copa | |||
| # - glue:cola | |||
| # - glue:mrpc | |||
| # - superglue:boolq | |||
| # - glue:stsb | |||
| - superglue:multirc | |||
| pp: &pp | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_small_glue-mnli/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_small_glue-sst2/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_small_glue-qqp/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_small_glue-qnli/10_combine_128 | |||
| run_configs: | |||
| # - <<: *default | |||
| # learning_rate: 0.3 | |||
| # weight_decay: 0.00001 | |||
| # peft_params: | |||
| # kind: attempt | |||
| # n_tokens: 10 | |||
| # g_bottleneck: 100 | |||
| # pretrained_paths: *pp | |||
| # - <<: *default_large | |||
| # learning_rate: 0.3 | |||
| # weight_decay: 0.00001 | |||
| # peft_params: | |||
| # kind: attempt | |||
| # n_tokens: 10 | |||
| # g_bottleneck: 100 | |||
| # pretrained_paths: *pp | |||
| - <<: *default | |||
| learning_rate: 0.3 | |||
| remove_dropout: false | |||
| experiment_name_suffix: dropout | |||
| weight_decay: 0.00001 | |||
| peft_params: | |||
| kind: attempt | |||
| n_tokens: 10 | |||
| g_bottleneck: 100 | |||
| pretrained_paths: *pp | |||
| # - <<: *default_large | |||
| # learning_rate: 0.3 | |||
| # remove_dropout: false | |||
| # experiment_name_suffix: dropout | |||
| # weight_decay: 0.00001 | |||
| # peft_params: | |||
| # kind: attempt | |||
| # n_tokens: 10 | |||
| # g_bottleneck: 100 | |||
| # pretrained_paths: *pp | |||
+ 19
- 0
09_Cluster/gpu_run2.sh
View File
| @@ -0,0 +1,19 @@ | |||
| #!/bin/bash | |||
| #SBATCH --job-name=gputest # Name of job | |||
| #SBATCH --output=out/%x_%j.out # stdout | |||
| #SBATCH --error=out/%x_%j.err # stderr | |||
| #SBATCH --partition=gpu # partition to use (check with sinfo) | |||
| #SBATCH --gres=gpu:v100:1 | |||
| #SBATCH --nodes=1 # Number of nodes | |||
| #SBATCH --ntasks=1 # Number of tasks | Alternative: --ntasks-per-node | |||
| #SBATCH --threads-per-core=1 # Ensure we only get one logical CPU per core | |||
| #SBATCH --cpus-per-task=1 # Number of cores per task | |||
| #SBATCH --mem=16G # Memory per node | Alternative: --mem-per-cpu | |||
| #SBATCH --time=24:00:00 # wall time limit (HH:MM:SS) | |||
| #SBATCH --mail-type=ALL | |||
| #SBATCH [email protected] | |||
| #SBATCH --clusters=bioinf | |||
| export SAD_PYTHON=/home/msadraei/miniconda3/envs/deep/bin/python | |||
| export SAD_PRJ_PATH=/home/msadraei/developer/Thesis/09_Cluster | |||
| $SAD_PYTHON $SAD_PRJ_PATH/train.py $SAD_PRJ_PATH/config2.yaml | |||
+ 69
- 0
09_Cluster/run_hyperparam_effect/config1.yaml
View File
| @@ -0,0 +1,69 @@ | |||
| default: &default | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| base_save_path: /home/msadraei/trained_final | |||
| model_name: google/t5-base-lm-adapt | |||
| project_name_prefix: hzi_cluster_comp_run | |||
| experiment_name_suffix: null | |||
| train_batch_size: 32 | |||
| valid_batch_size: 32 | |||
| remove_dropout: true | |||
| learning_rate: 0.01 | |||
| weight_decay: 0.01 | |||
| num_epochs: 80 | |||
| peft_params: null # no mutation | |||
| hot_modules: | |||
| - sadcl | |||
| - classifier | |||
| best_finder: | |||
| save: True | |||
| metric: valid_mean | |||
| higher_better: true | |||
| tasks: | |||
| - glue:mrpc | |||
| - glue:cola | |||
| run_configs: | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 4 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 8 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 16 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 32 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 64 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 128 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 256 | |||
+ 69
- 0
09_Cluster/run_hyperparam_effect/config2.yaml
View File
| @@ -0,0 +1,69 @@ | |||
| default: &default | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| base_save_path: /home/msadraei/trained_final | |||
| model_name: google/t5-base-lm-adapt | |||
| project_name_prefix: hzi_cluster_comp_run | |||
| experiment_name_suffix: null | |||
| train_batch_size: 32 | |||
| valid_batch_size: 32 | |||
| remove_dropout: true | |||
| learning_rate: 0.01 | |||
| weight_decay: 0.01 | |||
| num_epochs: 80 | |||
| peft_params: null # no mutation | |||
| hot_modules: | |||
| - sadcl | |||
| - classifier | |||
| best_finder: | |||
| save: True | |||
| metric: valid_mean | |||
| higher_better: true | |||
| tasks: | |||
| - superglue:rte | |||
| - superglue:cb | |||
| run_configs: | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 4 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 8 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 16 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 32 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 64 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 128 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 256 | |||
+ 69
- 0
09_Cluster/run_hyperparam_effect/config3.yaml
View File
| @@ -0,0 +1,69 @@ | |||
| default: &default | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| base_save_path: /home/msadraei/trained_final | |||
| model_name: google/t5-base-lm-adapt | |||
| project_name_prefix: hzi_cluster_comp_run | |||
| experiment_name_suffix: null | |||
| train_batch_size: 32 | |||
| valid_batch_size: 32 | |||
| remove_dropout: true | |||
| learning_rate: 0.01 | |||
| weight_decay: 0.01 | |||
| num_epochs: 80 | |||
| peft_params: null # no mutation | |||
| hot_modules: | |||
| - sadcl | |||
| - classifier | |||
| best_finder: | |||
| save: True | |||
| metric: valid_mean | |||
| higher_better: true | |||
| tasks: | |||
| - superglue:copa | |||
| - superglue:wic | |||
| run_configs: | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 4 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 8 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 16 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 32 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 64 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 128 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 256 | |||
+ 38
- 0
09_Cluster/run_hyperparam_effect/config4.yaml
View File
| @@ -0,0 +1,38 @@ | |||
| default: &default | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| base_save_path: /home/msadraei/trained_final | |||
| model_name: google/t5-base-lm-adapt | |||
| project_name_prefix: hzi_cluster_comp_run | |||
| experiment_name_suffix: null | |||
| train_batch_size: 24 | |||
| valid_batch_size: 24 | |||
| remove_dropout: true | |||
| learning_rate: 0.01 | |||
| weight_decay: 0.01 | |||
| num_epochs: 80 | |||
| peft_params: null # no mutation | |||
| hot_modules: | |||
| - sadcl | |||
| - classifier | |||
| best_finder: | |||
| save: True | |||
| metric: valid_mean | |||
| higher_better: true | |||
| tasks: | |||
| - superglue:boolq | |||
| run_configs: | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 8 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 16 | |||
+ 33
- 0
09_Cluster/run_hyperparam_effect/config4_prim.yaml
View File
| @@ -0,0 +1,33 @@ | |||
| default: &default | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| base_save_path: /home/msadraei/trained_final | |||
| model_name: google/t5-base-lm-adapt | |||
| project_name_prefix: hzi_cluster_comp_run | |||
| experiment_name_suffix: null | |||
| train_batch_size: 24 | |||
| valid_batch_size: 24 | |||
| remove_dropout: true | |||
| learning_rate: 0.01 | |||
| weight_decay: 0.01 | |||
| num_epochs: 80 | |||
| peft_params: null # no mutation | |||
| hot_modules: | |||
| - sadcl | |||
| - classifier | |||
| best_finder: | |||
| save: True | |||
| metric: valid_mean | |||
| higher_better: true | |||
| tasks: | |||
| - superglue:boolq | |||
| run_configs: | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 64 | |||
+ 38
- 0
09_Cluster/run_hyperparam_effect/config4_zegond.yaml
View File
| @@ -0,0 +1,38 @@ | |||
| default: &default | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| base_save_path: /home/msadraei/trained_final | |||
| model_name: google/t5-base-lm-adapt | |||
| project_name_prefix: hzi_cluster_comp_run | |||
| experiment_name_suffix: null | |||
| train_batch_size: 24 | |||
| valid_batch_size: 24 | |||
| remove_dropout: true | |||
| learning_rate: 0.01 | |||
| weight_decay: 0.01 | |||
| num_epochs: 80 | |||
| peft_params: null # no mutation | |||
| hot_modules: | |||
| - sadcl | |||
| - classifier | |||
| best_finder: | |||
| save: True | |||
| metric: valid_mean | |||
| higher_better: true | |||
| tasks: | |||
| - superglue:boolq | |||
| run_configs: | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 128 | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 10 | |||
| n_comb_tokens: 256 | |||
+ 19
- 0
09_Cluster/run_hyperparam_effect/gpu_run1.sh
View File
| @@ -0,0 +1,19 @@ | |||
| #!/bin/bash | |||
| #SBATCH --job-name=gputest # Name of job | |||
| #SBATCH --output=out/%x_%j.out # stdout | |||
| #SBATCH --error=out/%x_%j.err # stderr | |||
| #SBATCH --partition=gpu # partition to use (check with sinfo) | |||
| #SBATCH --gres=gpu:v100:1 | |||
| #SBATCH --nodes=1 # Number of nodes | |||
| #SBATCH --ntasks=1 # Number of tasks | Alternative: --ntasks-per-node | |||
| #SBATCH --threads-per-core=1 # Ensure we only get one logical CPU per core | |||
| #SBATCH --cpus-per-task=1 # Number of cores per task | |||
| #SBATCH --mem=16G # Memory per node | Alternative: --mem-per-cpu | |||
| #SBATCH --time=24:00:00 # wall time limit (HH:MM:SS) | |||
| #SBATCH --mail-type=ALL | |||
| #SBATCH [email protected] | |||
| #SBATCH --clusters=bioinf | |||
| export SAD_PYTHON=/home/msadraei/miniconda3/envs/deep/bin/python | |||
| export SAD_PRJ_PATH=/home/msadraei/developer/Thesis/09_Cluster | |||
| $SAD_PYTHON $SAD_PRJ_PATH/train.py $SAD_PRJ_PATH/config1.yaml | |||
+ 19
- 0
09_Cluster/run_hyperparam_effect/gpu_run2.sh
View File
| @@ -0,0 +1,19 @@ | |||
| #!/bin/bash | |||
| #SBATCH --job-name=gputest # Name of job | |||
| #SBATCH --output=out/%x_%j.out # stdout | |||
| #SBATCH --error=out/%x_%j.err # stderr | |||
| #SBATCH --partition=gpu # partition to use (check with sinfo) | |||
| #SBATCH --gres=gpu:a100:1 | |||
| #SBATCH --nodes=1 # Number of nodes | |||
| #SBATCH --ntasks=1 # Number of tasks | Alternative: --ntasks-per-node | |||
| #SBATCH --threads-per-core=1 # Ensure we only get one logical CPU per core | |||
| #SBATCH --cpus-per-task=1 # Number of cores per task | |||
| #SBATCH --mem=16G # Memory per node | Alternative: --mem-per-cpu | |||
| #SBATCH --time=36:00:00 # wall time limit (HH:MM:SS) | |||
| #SBATCH --mail-type=ALL | |||
| #SBATCH [email protected] | |||
| #SBATCH --clusters=bioinf | |||
| export SAD_PYTHON=/home/msadraei/miniconda3/envs/deep/bin/python | |||
| export SAD_PRJ_PATH=/home/msadraei/developer/Thesis/09_Cluster | |||
| $SAD_PYTHON $SAD_PRJ_PATH/train.py $SAD_PRJ_PATH/config2.yaml | |||
+ 27
- 0
09_Cluster/train.py
View File
| @@ -0,0 +1,27 @@ | |||
| from tqdm import tqdm | |||
| import torch | |||
| import os | |||
| import sys | |||
| sys.path.insert(1, os.path.join(sys.path[0], '..')) | |||
| from _config import load_config | |||
| from _utils import print_system_info, sp_encode | |||
| from train_single import run_experminent | |||
| if __name__ == '__main__': | |||
| print_system_info() | |||
| configs = load_config(sys.argv[1]) | |||
| run_configs = tqdm(configs.run_configs, position=0, desc="Experiment") | |||
| for run_config in run_configs: | |||
| tasks = tqdm(run_config.tasks, position=1, desc="Task:", leave=False) | |||
| for task_name in tasks: | |||
| tasks.set_description(f'Task: {task_name}') | |||
| torch.cuda.empty_cache() | |||
| run_experminent(run_config, task_name) | |||
+ 47
- 0
09_Cluster/train_single.py
View File
| @@ -0,0 +1,47 @@ | |||
| import numpy as np | |||
| import torch | |||
| import os | |||
| import sys | |||
| sys.path.insert(1, os.path.join(sys.path[0], '..')) | |||
| from _utils import silent_logs, sp_decode | |||
| from _datasets import AutoLoad | |||
| from _trainer import auto_train | |||
| from _mydelta import auto_mutate | |||
| from _models import auto_model | |||
| from _config import Config | |||
| DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") | |||
| def run_experminent(config, task_name): | |||
| silent_logs() | |||
| np.random.seed(config.random_seed) | |||
| torch.manual_seed(config.random_seed) | |||
| # ______________________LOAD MODEL_____________________________ | |||
| model, tokenizer = auto_model(config.model_name, AutoLoad.get_task_output(task_name)) | |||
| # ______________________MUTATE MODEL_____________________________ | |||
| n_prefix_token = 0 | |||
| if config.peft_params is not None: | |||
| n_prefix_token = config.peft_params.n_tokens | |||
| delta_module = auto_mutate( | |||
| model=model, | |||
| tokenizer=tokenizer, | |||
| peft_params=config.peft_params.to_dict(), | |||
| remove_dropout=config.remove_dropout | |||
| ) | |||
| # ______________________LOAD DATA_____________________________ | |||
| autoload = AutoLoad(tokenizer, n_prefix_token=n_prefix_token) | |||
| # ______________________TRAIN_____________________________ | |||
| dataset = autoload.get_and_map(task_name) | |||
| auto_train(model, tokenizer, dataset, config, device=DEVICE) | |||
| if __name__ == '__main__': | |||
| config_json = sp_decode(sys.argv[1]) | |||
| config = Config(config_json, '') | |||
| task_name = sp_decode(sys.argv[2]) | |||
| run_experminent(config, task_name) | |||
+ 867
- 0
11_wandb_api/Untitled.ipynb
File diff suppressed because it is too large
View File
+ 998
- 0
11_wandb_api/Untitled_bac.ipynb
File diff suppressed because it is too large
View File
BIN
11_wandb_api/curve.png
View File
{kind=link}
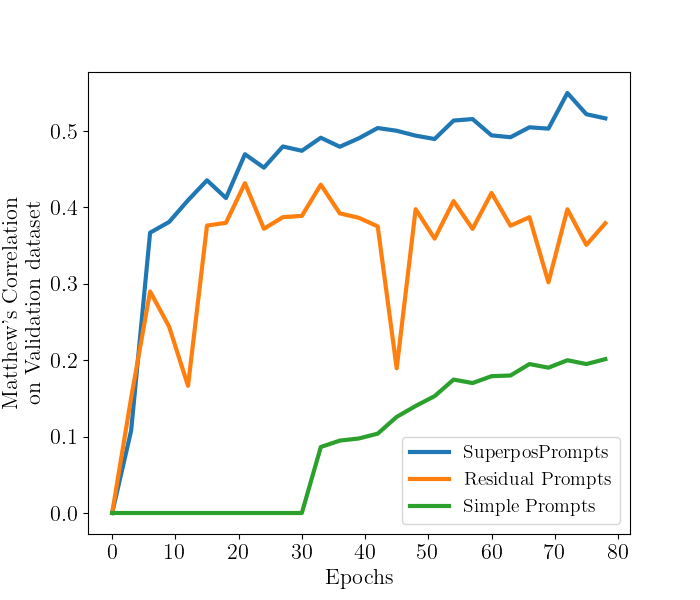
+ 205
- 0
11_wandb_api/orig_t5.ipynb
View File
| @@ -0,0 +1,205 @@ | |||
| { | |||
| "cells": [ | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 1, | |||
| "id": "cbff7109-365e-42c9-82b1-8e0fa8173d8d", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import pandas as pd \n", | |||
| "import numpy as np\n", | |||
| "from latex_table import generate_table, generate_rows\n", | |||
| "import matplotlib.pyplot as plt\n", | |||
| "from matplotlib.ticker import FormatStrFormatter\n", | |||
| "\n", | |||
| "class WandBWrapper:\n", | |||
| " def __init__(self, prefix=''):\n", | |||
| " import wandb\n", | |||
| " self.api = wandb.Api()\n", | |||
| " self.prefix = prefix\n", | |||
| " \n", | |||
| " def get_runs(self, name):\n", | |||
| " return self.api.runs(f\"{self.prefix}{name}\")\n", | |||
| " \n", | |||
| " def _preprocess_config(self, run):\n", | |||
| " return {\n", | |||
| " k: v for k,v in run.config.items()\n", | |||
| " if not k.startswith('_')\n", | |||
| " }\n", | |||
| " \n", | |||
| " def _best_in_history(self, run, key):\n", | |||
| " out = run.history()[key].astype('float').fillna(0).max()\n", | |||
| " return max(out, 0)\n", | |||
| " \n", | |||
| " def get_full_history(self, runs, tasks, model_size=''):\n", | |||
| " task_names = [model_size + '_' + task_name for task_name in tasks]\n", | |||
| " return {\n", | |||
| " task_name: pd.DataFrame({\n", | |||
| " run.name: run.history()['valid_mean']\n", | |||
| " for run in self.get_runs(task_name)\n", | |||
| " if run.name in runs\n", | |||
| " })[runs]\n", | |||
| " for task_name in task_names\n", | |||
| " }\n", | |||
| " \n", | |||
| " def get_runs_best(self, name, run_name_filter=None):\n", | |||
| " runs = self.get_runs(name)\n", | |||
| " return {\n", | |||
| " run.name: self._best_in_history(run, 'valid_mean')\n", | |||
| " for run in runs\n", | |||
| " if run_name_filter is None or run.name in run_name_filter\n", | |||
| " }\n", | |||
| " \n", | |||
| " def get_runs_tasks_df(self, runs, tasks, model_size=''):\n", | |||
| " task_names = [model_size + '_' + task_name for task_name in tasks]\n", | |||
| " results = {task_name: self.get_runs_best(task_name, runs) for task_name in task_names}\n", | |||
| " return pd.DataFrame(results).T[runs].T" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 4, | |||
| "id": "2e3239bf-7044-4ffd-93f3-39272dbd82ff", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "tasks = [\n", | |||
| " # 'glue-wnli',\n", | |||
| " # 'glue-rte',\n", | |||
| " 'glue-qqp', # new datasets\n", | |||
| " # 'glue-qnli', # new datasets\n", | |||
| " # 'glue-mnli', # new datasets\n", | |||
| " # 'glue-sst2', # new datasets\n", | |||
| " # 'glue-stsb', # new datasets\n", | |||
| " 'glue-mrpc',\n", | |||
| " 'glue-cola',\n", | |||
| " # 'superglue-multirc', # new datasets\n", | |||
| " 'superglue-rte',\n", | |||
| " 'superglue-cb',\n", | |||
| " # 'superglue-copa', # not in attempt\n", | |||
| " 'superglue-wic',\n", | |||
| " 'superglue-boolq',\n", | |||
| "]\n", | |||
| "\n", | |||
| "runs = [\n", | |||
| " '10_combine_128',\n", | |||
| "]\n", | |||
| "\n", | |||
| "df = WandBWrapper(\"mohalisad/iclr_orig_t5_t5_\").get_runs_tasks_df(\n", | |||
| " runs=runs,\n", | |||
| " tasks=tasks,\n", | |||
| " model_size='base'\n", | |||
| ")" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 5, | |||
| "id": "050389ec-ce24-431f-b1cb-e21f4c942c20", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "text/html": [ | |||
| "<div>\n", | |||
| "<style scoped>\n", | |||
| " .dataframe tbody tr th:only-of-type {\n", | |||
| " vertical-align: middle;\n", | |||
| " }\n", | |||
| "\n", | |||
| " .dataframe tbody tr th {\n", | |||
| " vertical-align: top;\n", | |||
| " }\n", | |||
| "\n", | |||
| " .dataframe thead th {\n", | |||
| " text-align: right;\n", | |||
| " }\n", | |||
| "</style>\n", | |||
| "<table border=\"1\" class=\"dataframe\">\n", | |||
| " <thead>\n", | |||
| " <tr style=\"text-align: right;\">\n", | |||
| " <th></th>\n", | |||
| " <th>base_glue-qqp</th>\n", | |||
| " <th>base_glue-mrpc</th>\n", | |||
| " <th>base_glue-cola</th>\n", | |||
| " <th>base_superglue-rte</th>\n", | |||
| " <th>base_superglue-cb</th>\n", | |||
| " <th>base_superglue-copa</th>\n", | |||
| " <th>base_superglue-wic</th>\n", | |||
| " <th>base_superglue-boolq</th>\n", | |||
| " </tr>\n", | |||
| " </thead>\n", | |||
| " <tbody>\n", | |||
| " <tr>\n", | |||
| " <th>10_combine_128</th>\n", | |||
| " <td>0.892432</td>\n", | |||
| " <td>0.909251</td>\n", | |||
| " <td>0.596682</td>\n", | |||
| " <td>0.801444</td>\n", | |||
| " <td>0.968944</td>\n", | |||
| " <td>0.66</td>\n", | |||
| " <td>0.675549</td>\n", | |||
| " <td>0.813456</td>\n", | |||
| " </tr>\n", | |||
| " </tbody>\n", | |||
| "</table>\n", | |||
| "</div>" | |||
| ], | |||
| "text/plain": [ | |||
| " base_glue-qqp base_glue-mrpc base_glue-cola \\\n", | |||
| "10_combine_128 0.892432 0.909251 0.596682 \n", | |||
| "\n", | |||
| " base_superglue-rte base_superglue-cb base_superglue-copa \\\n", | |||
| "10_combine_128 0.801444 0.968944 0.66 \n", | |||
| "\n", | |||
| " base_superglue-wic base_superglue-boolq \n", | |||
| "10_combine_128 0.675549 0.813456 " | |||
| ] | |||
| }, | |||
| "execution_count": 5, | |||
| "metadata": {}, | |||
| "output_type": "execute_result" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "df" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": null, | |||
| "id": "36774895-c1e4-4d26-bfc7-69e4003d2bbb", | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [] | |||
| } | |||
| ], | |||
| "metadata": { | |||
| "kernelspec": { | |||
| "display_name": "Python [conda env:deep]", | |||
| "language": "python", | |||
| "name": "conda-env-deep-py" | |||
| }, | |||
| "language_info": { | |||
| "codemirror_mode": { | |||
| "name": "ipython", | |||
| "version": 3 | |||
| }, | |||
| "file_extension": ".py", | |||
| "mimetype": "text/x-python", | |||
| "name": "python", | |||
| "nbconvert_exporter": "python", | |||
| "pygments_lexer": "ipython3", | |||
| "version": "3.10.13" | |||
| } | |||
| }, | |||
| "nbformat": 4, | |||
| "nbformat_minor": 5 | |||
| } | |||
+ 12
- 0
11_wandb_api/project.csv
View File
| @@ -0,0 +1,12 @@ | |||
| ,summary,config,name | |||
| 0,"{'_step': 79, '_wandb': {'runtime': 837}, '_runtime': 834.6212244033813, '_timestamp': 1695328162.5200074, 'train_loss': 0.14249593541026115, 'valid_mean': 0.5492957746478874, 'valid_accuracy': 0.5492957746478874}","{'tasks': ['glue:wnli', 'glue:rte', 'glue:mrpc'], 'use_tqdm': True, 'model_name': 'google/t5-base-lm-adapt', 'num_epochs': 80, 'best_finder': {'save': True, 'metric': 'valid_mean', 'higher_better': True}, 'hot_modules': None, 'peft_params': None, 'random_seed': 42, 'weight_decay': 0.01, 'learning_rate': 1e-05, 'base_save_path': '/home/msadraei/trained_final', 'remove_dropout': True, 'train_batch_size': 32, 'valid_batch_size': 32, 'project_name_prefix': 'hzi_cluster', 'experiment_name_suffix': None}",full | |||
| 1,"{'_step': 79, '_wandb': {'runtime': 372}, '_runtime': 373.980761051178, '_timestamp': 1695319551.4411, 'train_loss': 0.15845297500491143, 'valid_mean': 0.5633802816901409, 'valid_accuracy': 0.5633802816901409}","{'tasks': ['glue:wnli', 'glue:rte', 'glue:mrpc'], 'use_tqdm': True, 'model_name': 'google/t5-base-lm-adapt', 'num_epochs': 80, 'best_finder': {'save': True, 'metric': 'valid_mean', 'higher_better': True}, 'hot_modules': ['sadcl', 'classifier'], 'peft_params': {'kind': 'combine', 'n_tokens': 10, 'radnom_init': True, 'n_comb_tokens': 8}, 'random_seed': 42, 'weight_decay': 0.01, 'learning_rate': 0.01, 'base_save_path': '/home/msadraei/trained_final', 'remove_dropout': True, 'train_batch_size': 32, 'valid_batch_size': 32, 'project_name_prefix': 'hzi_cluster', 'experiment_name_suffix': 'random'}",10_combine_8_random | |||
| 2,"{'_timestamp': 1695314124.8870673, 'train_loss': 0.1371849663555622, 'valid_mean': 0.43661971830985913, 'valid_accuracy': 0.43661971830985913, '_step': 79, '_wandb': {'runtime': 372}, '_runtime': 373.63361120224}","{'tasks': ['glue:wnli', 'glue:rte', 'glue:mrpc'], 'use_tqdm': True, 'model_name': 'google/t5-base-lm-adapt', 'num_epochs': 80, 'best_finder': {'save': True, 'metric': 'valid_mean', 'higher_better': True}, 'hot_modules': ['sadcl', 'classifier'], 'peft_params': {'kind': 'combine', 'n_tokens': 10, 'radnom_init': True, 'n_comb_tokens': 128}, 'random_seed': 42, 'weight_decay': 0.01, 'learning_rate': 0.01, 'base_save_path': '/home/msadraei/trained_final', 'remove_dropout': True, 'train_batch_size': 32, 'valid_batch_size': 32, 'project_name_prefix': 'hzi_cluster', 'experiment_name_suffix': 'random'}",10_combine_128_random | |||
| 3,"{'valid_mean': 0.5633802816901409, 'valid_accuracy': 0.5633802816901409, '_step': 79, '_wandb': {'runtime': 389}, '_runtime': 389.9232409000397, '_timestamp': 1695309065.9015949, 'train_loss': 0.17796048820018767}","{'tasks': ['glue:wnli', 'glue:rte', 'glue:mrpc'], 'use_tqdm': True, 'model_name': 'google/t5-base-lm-adapt', 'num_epochs': 80, 'best_finder': {'save': True, 'metric': 'valid_mean', 'higher_better': True}, 'hot_modules': ['sadcl', 'classifier'], 'peft_params': {'kind': 'residual', 'mlp_size': 128, 'n_tokens': 10}, 'random_seed': 42, 'weight_decay': 0.01, 'learning_rate': 0.3, 'base_save_path': '/home/msadraei/trained_final', 'remove_dropout': False, 'train_batch_size': 32, 'valid_batch_size': 32, 'project_name_prefix': 'hzi_cluster', 'experiment_name_suffix': 'dropout'}",10_residual_128_dropout | |||
| 4,"{'train_loss': 0.749963104724884, 'valid_mean': 0.43661971830985913, 'valid_accuracy': 0.43661971830985913, '_step': 79, '_wandb': {'runtime': 479}, '_runtime': 480.0062892436981, '_timestamp': 1695303861.035812}","{'tasks': ['glue:wnli', 'glue:rte', 'glue:mrpc'], 'use_tqdm': True, 'model_name': 'google/t5-base-lm-adapt', 'num_epochs': 80, 'best_finder': {'save': True, 'metric': 'valid_mean', 'higher_better': True}, 'hot_modules': ['sadcl', 'classifier'], 'peft_params': {'kind': 'simple', 'n_tokens': 10}, 'random_seed': 42, 'weight_decay': 0.01, 'learning_rate': 0.01, 'base_save_path': '/home/msadraei/trained_final', 'remove_dropout': False, 'train_batch_size': 32, 'valid_batch_size': 32, 'project_name_prefix': 'hzi_cluster', 'experiment_name_suffix': 'dropout'}",10_simple_dropout | |||
| 5,"{'_step': 79, '_wandb': {'runtime': 413}, '_runtime': 414.14359283447266, '_timestamp': 1695298720.0363448, 'train_loss': 0.1991661325097084, 'valid_mean': 0.5633802816901409, 'valid_accuracy': 0.5633802816901409}","{'tasks': ['glue:wnli', 'glue:rte', 'glue:mrpc'], 'use_tqdm': True, 'model_name': 'google/t5-base-lm-adapt', 'num_epochs': 80, 'best_finder': {'save': True, 'metric': 'valid_mean', 'higher_better': True}, 'hot_modules': ['sadcl', 'classifier'], 'peft_params': {'kind': 'combine', 'n_tokens': 10, 'n_comb_tokens': 8}, 'random_seed': 42, 'weight_decay': 0.01, 'learning_rate': 0.01, 'base_save_path': '/home/msadraei/trained_final', 'remove_dropout': False, 'train_batch_size': 32, 'valid_batch_size': 32, 'project_name_prefix': 'hzi_cluster', 'experiment_name_suffix': 'dropout'}",10_combine_8_dropout | |||
| 6,"{'valid_accuracy': 0.5633802816901409, '_step': 79, '_wandb': {'runtime': 384}, '_runtime': 384.9592313766479, '_timestamp': 1695293638.5694425, 'train_loss': 0.1572120986878872, 'valid_mean': 0.5633802816901409}","{'tasks': ['glue:wnli', 'glue:rte', 'glue:mrpc'], 'use_tqdm': True, 'model_name': 'google/t5-base-lm-adapt', 'num_epochs': 80, 'best_finder': {'save': True, 'metric': 'valid_mean', 'higher_better': True}, 'hot_modules': ['sadcl', 'classifier'], 'peft_params': {'kind': 'combine', 'n_tokens': 10, 'n_comb_tokens': 128}, 'random_seed': 42, 'weight_decay': 0.01, 'learning_rate': 0.01, 'base_save_path': '/home/msadraei/trained_final', 'remove_dropout': False, 'train_batch_size': 32, 'valid_batch_size': 32, 'project_name_prefix': 'hzi_cluster', 'experiment_name_suffix': 'dropout'}",10_combine_128_dropout | |||
| 7,"{'_step': 79, '_wandb': {'runtime': 376}, '_runtime': 377.5810399055481, '_timestamp': 1695288599.143306, 'train_loss': 0.13466075621545315, 'valid_mean': 0.43661971830985913, 'valid_accuracy': 0.43661971830985913}","{'tasks': ['glue:wnli', 'glue:rte', 'glue:mrpc'], 'use_tqdm': True, 'model_name': 'google/t5-base-lm-adapt', 'num_epochs': 80, 'best_finder': {'save': True, 'metric': 'valid_mean', 'higher_better': True}, 'hot_modules': ['sadcl', 'classifier'], 'peft_params': {'kind': 'residual', 'mlp_size': 128, 'n_tokens': 10}, 'random_seed': 42, 'weight_decay': 0.01, 'learning_rate': 0.3, 'base_save_path': '/home/msadraei/trained_final', 'remove_dropout': True, 'train_batch_size': 32, 'valid_batch_size': 32, 'project_name_prefix': 'hzi_cluster', 'experiment_name_suffix': None}",10_residual_128 | |||
| 8,"{'_step': 79, '_wandb': {'runtime': 468}, '_runtime': 469.2816665172577, '_timestamp': 1695283548.0529184, 'train_loss': 0.19754927083849907, 'valid_mean': 0.5633802816901409, 'valid_accuracy': 0.5633802816901409}","{'tasks': ['glue:wnli', 'glue:rte', 'glue:mrpc'], 'use_tqdm': True, 'model_name': 'google/t5-base-lm-adapt', 'num_epochs': 80, 'best_finder': {'save': True, 'metric': 'valid_mean', 'higher_better': True}, 'hot_modules': ['sadcl', 'classifier'], 'peft_params': {'kind': 'simple', 'n_tokens': 10}, 'random_seed': 42, 'weight_decay': 0.01, 'learning_rate': 0.01, 'base_save_path': '/home/msadraei/trained_final', 'remove_dropout': True, 'train_batch_size': 32, 'valid_batch_size': 32, 'project_name_prefix': 'hzi_cluster', 'experiment_name_suffix': None}",10_simple | |||
| 9,"{'valid_mean': 0.43661971830985913, 'valid_accuracy': 0.43661971830985913, '_step': 79, '_wandb': {'runtime': 381}, '_runtime': 381.929176568985, '_timestamp': 1695278516.4769197, 'train_loss': 0.1441124401986599}","{'tasks': ['glue:wnli', 'glue:rte', 'glue:mrpc'], 'use_tqdm': True, 'model_name': 'google/t5-base-lm-adapt', 'num_epochs': 80, 'best_finder': {'save': True, 'metric': 'valid_mean', 'higher_better': True}, 'hot_modules': ['sadcl', 'classifier'], 'peft_params': {'kind': 'combine', 'n_tokens': 10, 'n_comb_tokens': 8}, 'random_seed': 42, 'weight_decay': 0.01, 'learning_rate': 0.01, 'base_save_path': '/home/msadraei/trained_final', 'remove_dropout': True, 'train_batch_size': 32, 'valid_batch_size': 32, 'project_name_prefix': 'hzi_cluster', 'experiment_name_suffix': None}",10_combine_8 | |||
| 10,"{'_step': 79, '_wandb': {'runtime': 371}, '_runtime': 371.98936891555786, '_timestamp': 1695273540.236157, 'train_loss': 0.1341699216514826, 'valid_mean': 0.4225352112676056, 'valid_accuracy': 0.4225352112676056}","{'tasks': ['glue:wnli', 'glue:rte', 'glue:mrpc'], 'use_tqdm': True, 'model_name': 'google/t5-base-lm-adapt', 'num_epochs': 80, 'best_finder': {'save': True, 'metric': 'valid_mean', 'higher_better': True}, 'hot_modules': ['sadcl', 'classifier'], 'peft_params': {'kind': 'combine', 'n_tokens': 10, 'n_comb_tokens': 128}, 'random_seed': 42, 'weight_decay': 0.01, 'learning_rate': 0.01, 'base_save_path': '/home/msadraei/trained_final', 'remove_dropout': True, 'train_batch_size': 32, 'valid_batch_size': 32, 'project_name_prefix': 'hzi_cluster', 'experiment_name_suffix': None}",10_combine_128 | |||
+ 273
- 0
11_wandb_api/softmax.ipynb
View File
| @@ -0,0 +1,273 @@ | |||
| { | |||
| "cells": [ | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 1, | |||
| "id": "54a7edcf-605f-40f1-9e89-d62067f55dd3", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import pandas as pd \n", | |||
| "import numpy as np\n", | |||
| "from latex_table import generate_table, generate_rows\n", | |||
| "import matplotlib.pyplot as plt\n", | |||
| "from matplotlib.ticker import FormatStrFormatter\n", | |||
| "\n", | |||
| "class WandBWrapper:\n", | |||
| " def __init__(self, prefix=''):\n", | |||
| " import wandb\n", | |||
| " self.api = wandb.Api()\n", | |||
| " self.prefix = prefix\n", | |||
| " \n", | |||
| " def get_runs(self, name):\n", | |||
| " return self.api.runs(f\"{self.prefix}{name}\")\n", | |||
| " \n", | |||
| " def _preprocess_config(self, run):\n", | |||
| " return {\n", | |||
| " k: v for k,v in run.config.items()\n", | |||
| " if not k.startswith('_')\n", | |||
| " }\n", | |||
| " \n", | |||
| " def _best_in_history(self, run, key):\n", | |||
| " out = run.history()[key].astype('float').fillna(0).max()\n", | |||
| " return max(out, 0)\n", | |||
| " \n", | |||
| " def get_full_history(self, runs, tasks, model_size=''):\n", | |||
| " task_names = [model_size + '_' + task_name for task_name in tasks]\n", | |||
| " return {\n", | |||
| " task_name: pd.DataFrame({\n", | |||
| " run.name: run.history()['valid_mean']\n", | |||
| " for run in self.get_runs(task_name)\n", | |||
| " if run.name in runs\n", | |||
| " })[runs]\n", | |||
| " for task_name in task_names\n", | |||
| " }\n", | |||
| " \n", | |||
| " def get_runs_best(self, name, run_name_filter=None):\n", | |||
| " runs = self.get_runs(name)\n", | |||
| " return {\n", | |||
| " run.name: self._best_in_history(run, 'valid_mean')\n", | |||
| " for run in runs\n", | |||
| " if run_name_filter is None or run.name in run_name_filter\n", | |||
| " }\n", | |||
| " \n", | |||
| " def get_runs_tasks_df(self, runs, tasks, model_size=''):\n", | |||
| " task_names = [model_size + '_' + task_name for task_name in tasks]\n", | |||
| " results = {task_name: self.get_runs_best(task_name, runs) for task_name in task_names}\n", | |||
| " return pd.DataFrame(results).T[runs].T" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 2, | |||
| "id": "1d044235-2d14-4e4b-ad87-2077c9cd89a4", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "tasks = [\n", | |||
| " # 'glue-wnli',\n", | |||
| " # 'glue-rte',\n", | |||
| " 'glue-qqp', # new datasets\n", | |||
| " 'glue-qnli', # new datasets\n", | |||
| " 'glue-mnli', # new datasets\n", | |||
| " 'glue-sst2', # new datasets\n", | |||
| " 'glue-stsb', # new datasets\n", | |||
| " 'glue-mrpc',\n", | |||
| " 'glue-cola',\n", | |||
| " 'superglue-multirc', # new datasets\n", | |||
| " 'superglue-rte',\n", | |||
| " 'superglue-cb',\n", | |||
| " 'superglue-copa',\n", | |||
| " 'superglue-wic',\n", | |||
| " 'superglue-boolq',\n", | |||
| "]\n", | |||
| "\n", | |||
| "runs = [\n", | |||
| " '10_combine_128',\n", | |||
| "] \n", | |||
| "\n", | |||
| "# small_df_softmax = WandBWrapper(\"mohalisad/iclr_softmax_effect_t5_\").get_runs_tasks_df(\n", | |||
| "# runs=runs,\n", | |||
| "# tasks=tasks,\n", | |||
| "# model_size='small'\n", | |||
| "# )\n", | |||
| "small_df_no_softmax = WandBWrapper(\"mohalisad/hzi_cluster_t5_\").get_runs_tasks_df(\n", | |||
| " runs=runs,\n", | |||
| " tasks=tasks,\n", | |||
| " model_size='small'\n", | |||
| ")\n" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 7, | |||
| "id": "7300ed8f-4477-4e4c-b818-c265c3f02aae", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "small_df = pd.concat([small_df_no_softmax, small_df_no_softmax], ignore_index=True)\n", | |||
| "small_df['name'] = ['softmax', 'no_softmax']\n", | |||
| "small_df.set_index('name', inplace=True)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 10, | |||
| "id": "fe96e491-24ce-4cb8-a25e-0db9cb98435d", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import numpy as np\n", | |||
| "\n", | |||
| "def _tblr_args():\n", | |||
| " return r\"\"\"column{2-16} = {c},\n", | |||
| " cell{1}{3} = {r=3}{b},\n", | |||
| " cell{1}{4} = {c=7}{c},\n", | |||
| " cell{1}{11} = {c=6}{},\n", | |||
| " vline{3, 4,11,17} = {1-3}{},\n", | |||
| " hline{2} = {3-15}{},\n", | |||
| " row{4, 7} = {c},\n", | |||
| " cell{4, 7}{1} = {c=16}{},\n", | |||
| " hline{6, 9} = {-}{},\n", | |||
| " hline{4, 7, 10} = {-}{2px},,\"\"\"\n", | |||
| "\n", | |||
| "def _head_rows():\n", | |||
| " return [\n", | |||
| " r\" & \\rot{\\eztb{Softmax}} & \\rot{\\eztb{Dropout}} & GLUE &&&&&&& SuperGLUE &&&&&&\",\n", | |||
| " r\"Task→ &&& QQP & QNLI & MNLI & SST-2 & STS-B & MRPC & CoLA & MultiRC & RTE & CB & COPA & WiC & BoolQ & Avg.\",\n", | |||
| " r\"Method↓ &&& F1/Acc. & Acc. & Acc. & Acc. & PCC/$\\rho$ & F1/Acc. & MCC & F1a/EM & Acc. & F1/Acc. & Acc. & Acc. & Acc. & -\"\n", | |||
| " ]\n", | |||
| "\n", | |||
| "def _section_row(name):\n", | |||
| " return name + \"&&&&&&& &&&&&&&&&\"\n", | |||
| "\n", | |||
| "def _convert_number(n):\n", | |||
| " if n == 0:\n", | |||
| " return '0.0 $\\\\dag$'\n", | |||
| " return f\"{100 * n:.1f}\"\n", | |||
| "\n", | |||
| "def _normal_row(name, is_softmax, is_dropout, numbers, bold_mask=None):\n", | |||
| " numbers_str = [_convert_number(n) for n in numbers]\n", | |||
| " if bold_mask is not None:\n", | |||
| " for idx, bold_state in enumerate(bold_mask):\n", | |||
| " if bold_state:\n", | |||
| " numbers_str[idx] = \"\\\\textbf{\" + numbers_str[idx] + \"}\"\n", | |||
| " \n", | |||
| " soft_mark = \"\\\\cmark\" if is_softmax else \"\\\\xmark\"\n", | |||
| " drop_mark = \"\\\\cmark\" if is_dropout else \"\\\\xmark\"\n", | |||
| " return \" & \".join([name, soft_mark, drop_mark, *numbers_str])\n", | |||
| " \n", | |||
| "def generate_rows(names, softmaxes, dropouts, numbers):\n", | |||
| " mean = numbers.mean(axis=1, keepdims=True)\n", | |||
| " numbers = np.concatenate((numbers, mean), axis=1)\n", | |||
| " pefts = numbers\n", | |||
| " pefts_best = pefts.max(axis=0)\n", | |||
| " \n", | |||
| " rows = [\n", | |||
| " _normal_row(name, is_softmax, drop, peft_row, peft_row == pefts_best)\n", | |||
| " for (name, is_softmax, drop, peft_row) in zip(names, softmaxes, dropouts, pefts)\n", | |||
| " ]\n", | |||
| " return rows\n", | |||
| " \n", | |||
| "def generate_table(rows1_key, rows1, rows2_key, rows2):\n", | |||
| " end_line = '\\\\\\\\\\n'\n", | |||
| " rows = [\n", | |||
| " *_head_rows(),\n", | |||
| " _section_row(rows1_key),\n", | |||
| " *rows1,\n", | |||
| " _section_row(rows2_key),\n", | |||
| " *rows2,\n", | |||
| " ]\n", | |||
| " return r\"\"\"\\begin{tblr}{\n", | |||
| " %s\n", | |||
| "}\n", | |||
| "%s\n", | |||
| "\\end{tblr}\n", | |||
| "\"\"\" % (_tblr_args(), end_line.join(rows + [\"\"]))" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 11, | |||
| "id": "ac11ea00-a9af-4454-982f-2aed9b552e5e", | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "\\begin{tblr}{\n", | |||
| " column{2-16} = {c},\n", | |||
| " cell{1}{3} = {r=3}{b},\n", | |||
| " cell{1}{4} = {c=7}{c},\n", | |||
| " cell{1}{11} = {c=6}{},\n", | |||
| " vline{3, 4,11,17} = {1-3}{},\n", | |||
| " hline{2} = {3-15}{},\n", | |||
| " row{4, 7} = {c},\n", | |||
| " cell{4, 7}{1} = {c=16}{},\n", | |||
| " hline{6, 9} = {-}{},\n", | |||
| " hline{4, 7, 10} = {-}{2px},,\n", | |||
| "}\n", | |||
| " & \\rot{\\eztb{Softmax}} & \\rot{\\eztb{Dropout}} & GLUE &&&&&&& SuperGLUE &&&&&&\\\\\n", | |||
| "Task→ &&& QQP & QNLI & MNLI & SST-2 & STS-B & MRPC & CoLA & MultiRC & RTE & CB & COPA & WiC & BoolQ & Avg.\\\\\n", | |||
| "Method↓ &&& F1/Acc. & Acc. & Acc. & Acc. & PCC/$\\rho$ & F1/Acc. & MCC & F1a/EM & Acc. & F1/Acc. & Acc. & Acc. & Acc. & -\\\\\n", | |||
| "T5v1.1 Small LM-Adapted&&&&&&& &&&&&&&&&\\\\\n", | |||
| "SuperPos PT & \\cmark & \\xmark & \\textbf{81.2} & \\textbf{85.3} & \\textbf{71.7} & \\textbf{89.8} & \\textbf{84.0} & \\textbf{87.9} & \\textbf{38.9} & \\textbf{41.6} & \\textbf{64.6} & \\textbf{75.2} & \\textbf{58.0} & \\textbf{65.7} & \\textbf{68.9} & \\textbf{70.2}\\\\\n", | |||
| "SuperPos PT & \\xmark & \\xmark & \\textbf{81.2} & \\textbf{85.3} & \\textbf{71.7} & \\textbf{89.8} & \\textbf{84.0} & \\textbf{87.9} & \\textbf{38.9} & \\textbf{41.6} & \\textbf{64.6} & \\textbf{75.2} & \\textbf{58.0} & \\textbf{65.7} & \\textbf{68.9} & \\textbf{70.2}\\\\\n", | |||
| "T5v1.1 Base LM-Adapted&&&&&&& &&&&&&&&&\\\\\n", | |||
| "SuperPos PT & \\cmark & \\xmark & \\textbf{81.2} & \\textbf{85.3} & \\textbf{71.7} & \\textbf{89.8} & \\textbf{84.0} & \\textbf{87.9} & \\textbf{38.9} & \\textbf{41.6} & \\textbf{64.6} & \\textbf{75.2} & \\textbf{58.0} & \\textbf{65.7} & \\textbf{68.9} & \\textbf{70.2}\\\\\n", | |||
| "SuperPos PT & \\xmark & \\xmark & \\textbf{81.2} & \\textbf{85.3} & \\textbf{71.7} & \\textbf{89.8} & \\textbf{84.0} & \\textbf{87.9} & \\textbf{38.9} & \\textbf{41.6} & \\textbf{64.6} & \\textbf{75.2} & \\textbf{58.0} & \\textbf{65.7} & \\textbf{68.9} & \\textbf{70.2}\\\\\n", | |||
| "\n", | |||
| "\\end{tblr}\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "dropouts = [False, False]\n", | |||
| "softmaxes = [True, False]\n", | |||
| "names = ['SuperPos PT'] * 2\n", | |||
| "# base_rows = generate_rows(names, dropouts, base_df.to_numpy())\n", | |||
| "small_rows = generate_rows(names, softmaxes, dropouts, small_df.to_numpy())\n", | |||
| "print(generate_table('T5v1.1 Small LM-Adapted', small_rows, 'T5v1.1 Base LM-Adapted', small_rows))" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": null, | |||
| "id": "e138dc33-5b68-4b27-95e9-39c76f4cbc37", | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [] | |||
| } | |||
| ], | |||
| "metadata": { | |||
| "kernelspec": { | |||
| "display_name": "Python [conda env:flash]", | |||
| "language": "python", | |||
| "name": "conda-env-flash-py" | |||
| }, | |||
| "language_info": { | |||
| "codemirror_mode": { | |||
| "name": "ipython", | |||
| "version": 3 | |||
| }, | |||
| "file_extension": ".py", | |||
| "mimetype": "text/x-python", | |||
| "name": "python", | |||
| "nbconvert_exporter": "python", | |||
| "pygments_lexer": "ipython3", | |||
| "version": "3.10.13" | |||
| } | |||
| }, | |||
| "nbformat": 4, | |||
| "nbformat_minor": 5 | |||
| } | |||
+ 451
- 0
13_additional_table/openai/Untitled.ipynb
View File
| @@ -0,0 +1,451 @@ | |||
| { | |||
| "cells": [ | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 1, | |||
| "id": "55d641c5-ae0e-42af-afba-65dab055734e", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "OPENAI_TOKEN = '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'" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 2, | |||
| "id": "86ec3895-06b0-4601-a08f-756d286653b3", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "from langchain.chat_models import ChatOpenAI\n", | |||
| "from langchain.schema.messages import HumanMessage, SystemMessage\n", | |||
| "\n", | |||
| "chat = ChatOpenAI(openai_api_key=OPENAI_TOKEN, temperature=0)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 3, | |||
| "id": "2e75b407-27a6-4651-b240-0b370424d837", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import sys\n", | |||
| "sys.path.append('/home/msadraei/developer/Thesis')" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 5, | |||
| "id": "79a19f7f-0c9d-44a5-8089-d89f3e8ac43a", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "from _datasets.glue_helper import SuperGLUEHelper, GLUEHelper" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 6, | |||
| "id": "f57eace5-57d2-4d0c-908d-20c0f5844f8e", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "glue_helper = GLUEHelper()\n", | |||
| "superglue_helper = SuperGLUEHelper()" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 9, | |||
| "id": "80bc73c9-c8f5-42cb-a024-2b825c0b1bea", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "text/plain": [ | |||
| "{'paragraph': 'While this process moved along, diplomacy continued its rounds. Direct pressure on the Taliban had proved unsuccessful. As one NSC staff note put it, \"Under the Taliban, Afghanistan is not so much a state sponsor of terrorism as it is a state sponsored by terrorists.\" In early 2000, the United States began a high-level effort to persuade Pakistan to use its influence over the Taliban. In January 2000, Assistant Secretary of State Karl Inderfurth and the State Department\\'s counterterrorism coordinator, Michael Sheehan, met with General Musharraf in Islamabad, dangling before him the possibility of a presidential visit in March as a reward for Pakistani cooperation. Such a visit was coveted by Musharraf, partly as a sign of his government\\'s legitimacy. He told the two envoys that he would meet with Mullah Omar and press him on Bin Laden. They left, however, reporting to Washington that Pakistan was unlikely in fact to do anything,\" given what it sees as the benefits of Taliban control of Afghanistan.\" President Clinton was scheduled to travel to India. The State Department felt that he should not visit India without also visiting Pakistan. The Secret Service and the CIA, however, warned in the strongest terms that visiting Pakistan would risk the President\\'s life. Counterterrorism officials also argued that Pakistan had not done enough to merit a presidential visit. But President Clinton insisted on including Pakistan in the itinerary for his trip to South Asia. His one-day stopover on March 25, 2000, was the first time a U.S. president had been there since 1969. At his meeting with Musharraf and others, President Clinton concentrated on tensions between Pakistan and India and the dangers of nuclear proliferation, but also discussed Bin Laden. President Clinton told us that when he pulled Musharraf aside for a brief, one-on-one meeting, he pleaded with the general for help regarding Bin Laden.\" I offered him the moon when I went to see him, in terms of better relations with the United States, if he\\'d help us get Bin Laden and deal with another issue or two.\" The U.S. effort continued. ',\n", | |||
| " 'question': 'What did the high-level effort to persuade Pakistan include?',\n", | |||
| " 'answer': 'Children, Gerd, or Dorian Popa',\n", | |||
| " 'idx': {'paragraph': 0, 'question': 0, 'answer': 0},\n", | |||
| " 'label': 0}" | |||
| ] | |||
| }, | |||
| "execution_count": 9, | |||
| "metadata": {}, | |||
| "output_type": "execute_result" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "superglue_helper.datasets['multirc']['train'][0]" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 13, | |||
| "id": "392f5304-00e8-41ec-aab5-0bd34e6bb3e7", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import json\n", | |||
| "import numpy as np\n", | |||
| "from evaluate import load\n", | |||
| "\n", | |||
| "prompt_template = 'input = {input}\\noutput = {output}'\n", | |||
| "\n", | |||
| "def prepare_wic(input_dict_row):\n", | |||
| " word = input_dict_row['word']\n", | |||
| " sent1 = input_dict_row['sentence1']\n", | |||
| " sent2 = input_dict_row['sentence2']\n", | |||
| " slice1 = slice(input_dict_row['start1'], input_dict_row['end1'])\n", | |||
| " slice2 = slice(input_dict_row['start2'], input_dict_row['end2'])\n", | |||
| "\n", | |||
| " anotate_word = lambda _sent, _slice: _sent[:_slice.start] + \" ** \" + _sent[_slice] + \" ** \" + _sent[_slice.stop:]\n", | |||
| " input_dict_row['sentence1'] = anotate_word(sent1, slice1)\n", | |||
| " input_dict_row['sentence2'] = anotate_word(sent2, slice2)\n", | |||
| "\n", | |||
| " return {\n", | |||
| " 'sentence1': input_dict_row['sentence1'],\n", | |||
| " 'sentence2': input_dict_row['sentence2']\n", | |||
| " }\n", | |||
| "\n", | |||
| "def make_chatgpt_ready(ds_helper, task_name):\n", | |||
| " ds = ds_helper.datasets[task_name]\n", | |||
| " if task_name == 'wic':\n", | |||
| " ds = {\n", | |||
| " split: [\n", | |||
| " {\n", | |||
| " **prepare_wic(row),\n", | |||
| " 'label': row['label'],\n", | |||
| " 'idx': 0\n", | |||
| " } for row in ds[split]\n", | |||
| " ]\n", | |||
| " for split in ['train', 'validation']\n", | |||
| " }\n", | |||
| " if task_name not in ['wic', 'boolq', 'cb', 'copa', 'cola', 'mrpc', 'rte', 'sst2', 'multirc']:\n", | |||
| " np.random.seed(42)\n", | |||
| " validation_samples = np.random.choice(range(len(ds['validation'])), replace=False, size=2000).tolist()\n", | |||
| " ds = {\n", | |||
| " 'train': ds['train'],\n", | |||
| " 'validation': [ds['validation'][idx] for idx in validation_samples]\n", | |||
| " }\n", | |||
| " task_out = ds_helper.get_task_output(task_name)\n", | |||
| " \n", | |||
| " all_labels = [row['label'] for row in ds['validation']]\n", | |||
| " if task_name == 'multirc':\n", | |||
| " all_idx = ds['validation']['idx']\n", | |||
| " def compute_metric(y_pred):\n", | |||
| " glue_metric = load(ds_helper.base_name, task_name)\n", | |||
| " y_pred = [\n", | |||
| " task_out.str2int(json.loads(item)['label'])\n", | |||
| " for item in y_pred\n", | |||
| " ]\n", | |||
| " assert len(all_idx) == len(y_pred)\n", | |||
| " y_pred = [\n", | |||
| " {\n", | |||
| " 'prediction': y_pred_item,\n", | |||
| " 'idx': idx\n", | |||
| " } for (y_pred_item, idx) in zip(y_pred, all_idx)\n", | |||
| " ]\n", | |||
| " return glue_metric.compute(predictions=y_pred, references=all_labels)\n", | |||
| " else:\n", | |||
| " def compute_metric(y_pred):\n", | |||
| " glue_metric = load(ds_helper.base_name, task_name)\n", | |||
| " all_preds = [\n", | |||
| " task_out.str2int(json.loads(item)['label'])\n", | |||
| " for item in y_pred\n", | |||
| " ]\n", | |||
| " return glue_metric.compute(predictions=all_preds, references=all_labels)\n", | |||
| " \n", | |||
| " few_exmples = {}\n", | |||
| " for row in ds['train']:\n", | |||
| " if row['label'] not in few_exmples:\n", | |||
| " label = row.pop('label')\n", | |||
| " row.pop('idx')\n", | |||
| " few_exmples[label] = row\n", | |||
| " \n", | |||
| " class_names = json.dumps(task_out.names)\n", | |||
| " pre_prompt_parts = [f'class_names = {class_names}']\n", | |||
| " for label_id, example in few_exmples.items():\n", | |||
| " pre_prompt_parts.append(\n", | |||
| " prompt_template.format(\n", | |||
| " input = json.dumps(example),\n", | |||
| " output = json.dumps({'label': task_out.int2str(label_id)})\n", | |||
| " )\n", | |||
| " )\n", | |||
| " \n", | |||
| " prompt_str = []\n", | |||
| " for row in ds['validation']:\n", | |||
| " row.pop('label')\n", | |||
| " row.pop('idx')\n", | |||
| " prompt_parts = pre_prompt_parts + [\n", | |||
| " prompt_template.format(\n", | |||
| " input = json.dumps(row),\n", | |||
| " output = ''\n", | |||
| " )\n", | |||
| " ]\n", | |||
| " prompt_str.append('\\n'.join(prompt_parts))\n", | |||
| " \n", | |||
| " return prompt_str, compute_metric" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 14, | |||
| "id": "9304b06b-1c8c-4654-b074-c442f3aa3ed4", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "def make_chatgpt_ready_stsb(ds_helper, task_name):\n", | |||
| " ds = ds_helper.datasets[task_name]\n", | |||
| " task_out = ds_helper.get_task_output(task_name)\n", | |||
| " \n", | |||
| " all_labels = [row['label'] for row in ds['validation']]\n", | |||
| " def compute_metric(y_pred):\n", | |||
| " glue_metric = load(ds_helper.base_name, task_name)\n", | |||
| " all_preds = [\n", | |||
| " task_out.str2int(json.loads(item)['label'])\n", | |||
| " for item in y_pred\n", | |||
| " ]\n", | |||
| " return glue_metric.compute(predictions=all_preds, references=all_labels)\n", | |||
| " \n", | |||
| " few_exmples = {}\n", | |||
| " for row in ds['train']:\n", | |||
| " row['label'] = task_out.int2str(row['label'])\n", | |||
| " if row['label'] not in few_exmples:\n", | |||
| " label = row.pop('label')\n", | |||
| " row.pop('idx')\n", | |||
| " few_exmples[label] = row\n", | |||
| " \n", | |||
| " class_names = list(sorted(few_exmples.keys()))\n", | |||
| " pre_prompt_parts = [f'class_names = {class_names}']\n", | |||
| " for label_id, example in few_exmples.items():\n", | |||
| " pre_prompt_parts.append(\n", | |||
| " prompt_template.format(\n", | |||
| " input = json.dumps(example),\n", | |||
| " output = json.dumps({'label': label_id})\n", | |||
| " )\n", | |||
| " )\n", | |||
| " \n", | |||
| " prompt_str = []\n", | |||
| " for row in ds['validation']:\n", | |||
| " row.pop('label')\n", | |||
| " row.pop('idx')\n", | |||
| " prompt_parts = pre_prompt_parts + [\n", | |||
| " prompt_template.format(\n", | |||
| " input = json.dumps(row),\n", | |||
| " output = ''\n", | |||
| " )\n", | |||
| " ]\n", | |||
| " prompt_str.append('\\n'.join(prompt_parts))\n", | |||
| " \n", | |||
| " return prompt_str, compute_metric" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 19, | |||
| "id": "afe4b96f-2948-4544-9397-121a10319bf6", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "task_name = 'multirc'\n", | |||
| "prompts, compute_metric = make_chatgpt_ready(superglue_helper, task_name)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": null, | |||
| "id": "6cec4a27-bcfc-4699-9555-9d2cefcdfcaa", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "from tqdm import tqdm\n", | |||
| "\n", | |||
| "# all_results = []\n", | |||
| "for prompt in tqdm(prompts):\n", | |||
| " messages = [\n", | |||
| " SystemMessage(content=\"You are going to be used as a model for natural language understanding task. Read the json input and output carefully and according to the few-shot examples, classify the input. Your output label must be a member of 'class_names'. Your task is according to the paragraph the answer of question is True of False.\"),\n", | |||
| " HumanMessage(content=prompt)\n", | |||
| " ]\n", | |||
| " all_results.append(chat.invoke(messages).content)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 30, | |||
| "id": "57acf17a-8aa1-4f7a-90b3-dd69460d81df", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "name": "stderr", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 504/504 [08:28<00:00, 1.01s/it]\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "for prompt in tqdm(prompts[len(all_results):]):\n", | |||
| " messages = [\n", | |||
| " SystemMessage(content=\"You are going to be used as a model for natural language understanding task. Read the json input and output carefully and according to the few-shot examples, classify the input. Your output label must be a member of 'class_names'. Your task is according to the paragraph the answer of question is True of False.\"),\n", | |||
| " HumanMessage(content=prompt)\n", | |||
| " ]\n", | |||
| " all_results.append(chat.invoke(messages).content)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 118, | |||
| "id": "8e2ea4da-4710-42fa-befc-0c93fd8e5df0", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "# def conv_res(inp):\n", | |||
| "# if 'label' in inp:\n", | |||
| "# return inp\n", | |||
| "# return json.dumps({'label': inp})\n", | |||
| "\n", | |||
| "# all_results_conv = [conv_res(x) for x in all_results]" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 31, | |||
| "id": "15f18e92-80ca-4b7c-87e6-20d694e8cca1", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "text/plain": [ | |||
| "{'exact_match': 0.3410283315844701,\n", | |||
| " 'f1_m': 0.728404774590195,\n", | |||
| " 'f1_a': 0.7791361043194783}" | |||
| ] | |||
| }, | |||
| "execution_count": 31, | |||
| "metadata": {}, | |||
| "output_type": "execute_result" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "result = compute_metric(all_results)\n", | |||
| "result" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 33, | |||
| "id": "1041840c-4590-4034-8e64-cbdc215a11a8", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "text/plain": [ | |||
| "0.555" | |||
| ] | |||
| }, | |||
| "execution_count": 33, | |||
| "metadata": {}, | |||
| "output_type": "execute_result" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "(0.77 + 0.34) / 2" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 32, | |||
| "id": "6171134d-45ba-4bc8-991c-8fbd1cb7d370", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "with open(f'./{task_name}.json', 'w') as f:\n", | |||
| " json.dump(result, f)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 54, | |||
| "id": "2fca5a91-dbba-4768-9b9f-82f56619f2fb", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "text/plain": [ | |||
| "'class_names = [\"False\", \"True\"]\\ninput = {\"sentence1\": \"Do you want to come over to my ** place ** later?\", \"sentence2\": \"A political system with no ** place ** for the less prominent groups.\"}\\noutput = {\"label\": \"False\"}\\ninput = {\"sentence1\": \"The general ordered the colonel to ** hold ** his position at all costs.\", \"sentence2\": \" ** Hold ** the taxi.\"}\\noutput = {\"label\": \"True\"}\\ninput = {\"sentence1\": \"An emerging professional ** class ** .\", \"sentence2\": \"Apologizing for losing your temper, even though you were badly provoked, showed real ** class ** .\"}\\noutput = '" | |||
| ] | |||
| }, | |||
| "execution_count": 54, | |||
| "metadata": {}, | |||
| "output_type": "execute_result" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "prompts[0]" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": null, | |||
| "id": "229572a2-20ac-43d6-b370-7812deef23cd", | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [] | |||
| } | |||
| ], | |||
| "metadata": { | |||
| "kernelspec": { | |||
| "display_name": "Python [conda env:openai]", | |||
| "language": "python", | |||
| "name": "conda-env-openai-py" | |||
| }, | |||
| "language_info": { | |||
| "codemirror_mode": { | |||
| "name": "ipython", | |||
| "version": 3 | |||
| }, | |||
| "file_extension": ".py", | |||
| "mimetype": "text/x-python", | |||
| "name": "python", | |||
| "nbconvert_exporter": "python", | |||
| "pygments_lexer": "ipython3", | |||
| "version": "3.10.13" | |||
| } | |||
| }, | |||
| "nbformat": 4, | |||
| "nbformat_minor": 5 | |||
| } | |||
+ 1
- 0
13_additional_table/openai/boolq.json
View File
| @@ -0,0 +1 @@ | |||
| {"accuracy": 0.6963302752293578} | |||
+ 1
- 0
13_additional_table/openai/cb.json
View File
| @@ -0,0 +1 @@ | |||
| {"accuracy": 0.625, "f1": 0.5564102564102564} | |||
+ 1
- 0
13_additional_table/openai/cola.json
View File
| @@ -0,0 +1 @@ | |||
| {"matthews_correlation": 0.4606224140235148} | |||
+ 1
- 0
13_additional_table/openai/copa.json
View File
| @@ -0,0 +1 @@ | |||
| {"accuracy": 0.95} | |||
+ 1
- 0
13_additional_table/openai/mnli_matched.json
View File
| @@ -0,0 +1 @@ | |||
| {"accuracy": 0.576} | |||
+ 1
- 0
13_additional_table/openai/mnli_mismatched.json
View File
| @@ -0,0 +1 @@ | |||
| {"accuracy": 0.593} | |||
+ 1
- 0
13_additional_table/openai/mrpc.json
View File
| @@ -0,0 +1 @@ | |||
| {"accuracy": 0.7696078431372549, "f1": 0.8464052287581698} | |||
+ 1
- 0
13_additional_table/openai/multirc.json
View File
| @@ -0,0 +1 @@ | |||
| {"exact_match": 0.3410283315844701, "f1_m": 0.728404774590195, "f1_a": 0.7791361043194783} | |||
+ 1
- 0
13_additional_table/openai/qnli.json
View File
| @@ -0,0 +1 @@ | |||
| {"accuracy": 0.709} | |||
+ 1
- 0
13_additional_table/openai/qqp.json
View File
| @@ -0,0 +1 @@ | |||
| {"accuracy": 0.7925, "f1": 0.7632629777524244} | |||
+ 1
- 0
13_additional_table/openai/rte.json
View File
| @@ -0,0 +1 @@ | |||
| {"accuracy": 0.7075812274368231} | |||
+ 1
- 0
13_additional_table/openai/sst2.json
View File
| @@ -0,0 +1 @@ | |||
| {"accuracy": 0.9403669724770642} | |||
+ 1
- 0
13_additional_table/openai/stsb.json
View File
| @@ -0,0 +1 @@ | |||
| {"pearson": 0.3462796541200245, "spearmanr": 0.34129866842299095} | |||
+ 1
- 0
13_additional_table/openai/wic.json
View File
| @@ -0,0 +1 @@ | |||
| {"accuracy": 0.5877742946708464} | |||
+ 568
- 0
13_additional_table/table2.ipynb
View File
| @@ -0,0 +1,568 @@ | |||
| { | |||
| "cells": [ | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 1, | |||
| "id": "135746cc-454c-41a2-977c-cf633899f002", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import pandas as pd \n", | |||
| "import numpy as np\n", | |||
| "import matplotlib.pyplot as plt\n", | |||
| "from matplotlib.ticker import FormatStrFormatter\n", | |||
| "\n", | |||
| "class WandBWrapper:\n", | |||
| " def __init__(self, prefix=''):\n", | |||
| " import wandb\n", | |||
| " self.api = wandb.Api()\n", | |||
| " self.prefix = prefix\n", | |||
| " \n", | |||
| " def get_runs(self, name):\n", | |||
| " return self.api.runs(f\"{self.prefix}{name}\")\n", | |||
| " \n", | |||
| " def _preprocess_config(self, run):\n", | |||
| " return {\n", | |||
| " k: v for k,v in run.config.items()\n", | |||
| " if not k.startswith('_')\n", | |||
| " }\n", | |||
| " \n", | |||
| " def sort_valid_columns(self, cols):\n", | |||
| " priority = {\n", | |||
| " 'matthews_correlation': 0,\n", | |||
| " 'f1': 1,\n", | |||
| " 'f1_a':1,\n", | |||
| " 'accuracy': 2,\n", | |||
| " 'exact_match': 3,\n", | |||
| " 'pearson': 5,\n", | |||
| " 'spearmanr': 6\n", | |||
| " }\n", | |||
| " \n", | |||
| " for col in cols: # mnli dirty fix\n", | |||
| " if 'matched_accuracy' in col:\n", | |||
| " return ['valid_mean']\n", | |||
| " \n", | |||
| " cols = [col for col in cols if 'f1_m' not in col]\n", | |||
| " \n", | |||
| " stripper = lambda x: x[x.find('_') + 1:]\n", | |||
| " return list(sorted(cols, key=lambda x: priority[stripper(x)]))\n", | |||
| " \n", | |||
| " def _best_in_history(self, run, key):\n", | |||
| " history = run.history()\n", | |||
| " all_valid_columns = [col for col in history.columns if 'valid' in col and 'mean' not in col]\n", | |||
| " best_row_idx = history[key].astype('float').fillna(0).argmax()\n", | |||
| " all_valid_columns = self.sort_valid_columns(all_valid_columns)\n", | |||
| " return [max(float(history[key][best_row_idx]), 0) for key in all_valid_columns]\n", | |||
| " \n", | |||
| " def get_full_history(self, runs, tasks, model_size=''):\n", | |||
| " task_names = [model_size + '_' + task_name for task_name in tasks]\n", | |||
| " return {\n", | |||
| " task_name: pd.DataFrame({\n", | |||
| " run.name: run.history()['valid_mean']\n", | |||
| " for run in self.get_runs(task_name)\n", | |||
| " if run.name in runs\n", | |||
| " })[runs]\n", | |||
| " for task_name in task_names\n", | |||
| " }\n", | |||
| " \n", | |||
| " def get_runs_best(self, name, run_name_filter=None):\n", | |||
| " runs = self.get_runs(name)\n", | |||
| " return {\n", | |||
| " run.name: self._best_in_history(run, 'valid_mean')\n", | |||
| " for run in runs\n", | |||
| " if run_name_filter is None or run.name in run_name_filter\n", | |||
| " }\n", | |||
| " \n", | |||
| " def get_runs_tasks_df(self, runs, tasks, model_size=''):\n", | |||
| " task_names = [model_size + '_' + task_name for task_name in tasks]\n", | |||
| " results = {task_name: self.get_runs_best(task_name, runs) for task_name in task_names}\n", | |||
| " return pd.DataFrame(results).T[runs].T" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 2, | |||
| "id": "a4ddeace-44eb-4a2d-b215-b3d9af067204", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "attempt = {\n", | |||
| " 'qqp': ['-', 0.903], # F1/acc\n", | |||
| " 'qnli': [0.930],\n", | |||
| " 'mnli': [0.843],\n", | |||
| " 'sst2': [0.932],\n", | |||
| " 'stsb': [0.897, '-'], # Pearson / rho\n", | |||
| " 'mrpc': ['-', 0.857], # F1/acc\n", | |||
| " 'cola': [0.574],\n", | |||
| " 'multirc': [0.744, \"-\"], # F1a / EM\n", | |||
| " 'rte': [0.734],\n", | |||
| " 'cb': [\"-\", 0.786], # F1/acc\n", | |||
| " 'copa': '-',\n", | |||
| " 'wic': [0.668],\n", | |||
| " 'boolq': [0.788],\n", | |||
| "}\n", | |||
| "residual = {\n", | |||
| " 'qqp': \"-\",\n", | |||
| " 'qnli': \"-\",\n", | |||
| " 'mnli': \"-\",\n", | |||
| " 'sst2': \"-\",\n", | |||
| " 'stsb': \"-\",\n", | |||
| " 'mrpc': \"-\",\n", | |||
| " 'cola': \"-\",\n", | |||
| " 'multirc': [0.593],\n", | |||
| " 'rte': [0.704],\n", | |||
| " 'cb': [0.792],\n", | |||
| " 'copa': [0.583],\n", | |||
| " 'wic': [0.668],\n", | |||
| " 'boolq': [0.779],\n", | |||
| "}" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 3, | |||
| "id": "28243b98-8fa8-4fc0-a348-b905c126bdd7", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import json\n", | |||
| "import numpy as np\n", | |||
| "from pathlib import Path \n", | |||
| "\n", | |||
| "def load_gpt_score(base_path, task_name):\n", | |||
| " base_path = Path(base_path)\n", | |||
| " if task_name == 'mnli':\n", | |||
| " matched = json.loads((base_path / f'{task_name}_matched.json').read_text())\n", | |||
| " mismatched = json.loads((base_path / f'{task_name}_mismatched.json').read_text())\n", | |||
| " return [np.mean([*matched.values(), *mismatched.values()])]\n", | |||
| " \n", | |||
| " performance = json.loads((base_path / f'{task_name}.json').read_text())\n", | |||
| " \n", | |||
| " key_priority = {\n", | |||
| " 'matthews_correlation': 0,\n", | |||
| " 'f1': 1,\n", | |||
| " 'f1_a':1,\n", | |||
| " 'accuracy': 2,\n", | |||
| " 'exact_match': 3,\n", | |||
| " 'pearson': 5,\n", | |||
| " 'spearmanr': 6\n", | |||
| " }\n", | |||
| " \n", | |||
| " performance_keys = list(performance.keys())\n", | |||
| " if 'f1_m' in performance_keys:\n", | |||
| " performance_keys.pop(performance_keys.index('f1_m'))\n", | |||
| " performance_keys.sort(key=lambda x: key_priority[x])\n", | |||
| " \n", | |||
| " return [float(performance[key]) for key in performance_keys]\n", | |||
| "\n", | |||
| "tasks = [\n", | |||
| " 'qqp', # new datasets\n", | |||
| " 'qnli', # new datasets\n", | |||
| " 'mnli', # new datasets\n", | |||
| " 'sst2', # new datasets\n", | |||
| " 'stsb', # new datasets\n", | |||
| " 'mrpc',\n", | |||
| " 'cola',\n", | |||
| " 'multirc', # new datasets\n", | |||
| " 'rte',\n", | |||
| " 'cb',\n", | |||
| " 'copa',\n", | |||
| " 'wic',\n", | |||
| " 'boolq',\n", | |||
| "]\n", | |||
| "\n", | |||
| "gpt_performances = {task: load_gpt_score('openai', task) for task in tasks}" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 4, | |||
| "id": "5ac2b609-3fb8-4206-a20b-36b2282f3372", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "tasks = {\n", | |||
| " # 'glue-wnli',\n", | |||
| " # 'glue-rte',\n", | |||
| " 'glue-qqp': 'qqp', # new datasets\n", | |||
| " 'glue-qnli': 'qnli', # new datasets\n", | |||
| " 'glue-mnli': 'mnli', # new datasets\n", | |||
| " 'glue-sst2': 'sst2', # new datasets\n", | |||
| " 'glue-stsb': 'stsb', # new datasets\n", | |||
| " 'glue-mrpc': 'mrpc',\n", | |||
| " 'glue-cola': 'cola',\n", | |||
| " 'superglue-multirc': 'multirc', # new datasets\n", | |||
| " 'superglue-rte': 'rte',\n", | |||
| " 'superglue-cb': 'cb',\n", | |||
| " 'superglue-copa': 'copa',\n", | |||
| " 'superglue-wic': 'wic',\n", | |||
| " 'superglue-boolq': 'boolq',\n", | |||
| "}\n", | |||
| "\n", | |||
| "runs = [\n", | |||
| " '10_combine_128',\n", | |||
| "] \n", | |||
| "\n", | |||
| "base_lmt5_df = WandBWrapper(\"mohalisad/hzi_cluster_t5_\").get_runs_tasks_df(\n", | |||
| " runs=runs, tasks=tasks.keys(), model_size='base'\n", | |||
| ")\n", | |||
| "base_lmt5_df['base_superglue-cb']['10_combine_128'] = [0.7826, 0.8214]\n", | |||
| "small_lmt5_df = WandBWrapper(\"mohalisad/hzi_cluster_t5_\").get_runs_tasks_df(\n", | |||
| " runs=runs,\n", | |||
| " tasks=tasks.keys(),\n", | |||
| " model_size='small'\n", | |||
| ")\n", | |||
| "small_lmt5_softmax_df = WandBWrapper(\"mohalisad/iclr_softmax_effect_t5_\").get_runs_tasks_df(\n", | |||
| " runs=runs,\n", | |||
| " tasks=tasks.keys(),\n", | |||
| " model_size='small'\n", | |||
| ")\n", | |||
| "base_origt5_df = WandBWrapper(\"iclr_orig_t5_t5_\").get_runs_tasks_df(\n", | |||
| " runs=runs, tasks=tasks, model_size='base'\n", | |||
| ")" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 5, | |||
| "id": "b4e6da93-1cad-4310-9e54-f6a5f0c87a58", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "base_lmt5_df.columns = tasks.values()\n", | |||
| "small_lmt5_df.columns = tasks.values()\n", | |||
| "small_lmt5_softmax_df.columns = tasks.values()\n", | |||
| "base_origt5_df.columns = tasks.values()\n", | |||
| "\n", | |||
| "attempt_df = pd.Series(attempt).to_frame().T\n", | |||
| "residual_df = pd.Series(residual).to_frame().T\n", | |||
| "gpt_df = pd.Series(gpt_performances).to_frame().T" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 6, | |||
| "id": "a58a4bbc-7b62-4c5a-b69c-27252598232b", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "def my_concat(**kwargs):\n", | |||
| " merged_df = pd.concat(\n", | |||
| " list(kwargs.values()),\n", | |||
| " ignore_index=True\n", | |||
| " )\n", | |||
| " merged_df['name'] = list(kwargs.keys())\n", | |||
| " merged_df.set_index('name', inplace=True)\n", | |||
| " return merged_df\n", | |||
| "\n", | |||
| "comp_orig_df = my_concat(\n", | |||
| " superpos=base_origt5_df,\n", | |||
| " attempt=attempt_df,\n", | |||
| " residual=residual_df\n", | |||
| ")\n", | |||
| "comp_softmax_df = my_concat(\n", | |||
| " superpos=small_lmt5_df,\n", | |||
| " superpos_softmax=small_lmt5_softmax_df,\n", | |||
| ")\n", | |||
| "comb_base_df = my_concat(\n", | |||
| " superpos=base_lmt5_df\n", | |||
| ")\n", | |||
| "comp_gpt_df = my_concat(\n", | |||
| " gpt=gpt_df\n", | |||
| ")" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 14, | |||
| "id": "b7cbb0bd-0dbe-4f98-9f28-9e1f60d43b1c", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import numpy as np\n", | |||
| "import itertools\n", | |||
| "\n", | |||
| "def _tblr_args(rows_count_seq):\n", | |||
| " top_rows = list(np.cumsum([4, *rows_count_seq]))\n", | |||
| " top_rows_str = ', '.join(map(str, top_rows[:-1]))\n", | |||
| " bold_line = ', '.join(map(str, top_rows))\n", | |||
| " return r\"\"\"column{2-18} = {c},\n", | |||
| " cell{1}{2, 3, 4} = {r=3}{b},\n", | |||
| " cell{1}{5} = {c=7}{c},\n", | |||
| " cell{1}{12} = {c=6}{},\n", | |||
| " vline{2, 3, 4, 5,12,18} = {1-3}{},\n", | |||
| " hline{2} = {4-17}{},\n", | |||
| " row{%s} = {c},\n", | |||
| " cell{%s}{1} = {c=18}{},\n", | |||
| " hline{%s} = {-}{2px},,\"\"\" % (top_rows_str, top_rows_str, bold_line)\n", | |||
| "\n", | |||
| "def _head_rows():\n", | |||
| " return [\n", | |||
| " r\"&\\rot{\\eztb{\\# Prompts}} & \\rot{\\eztb{Softmax}} & \\rot{\\eztb{Dropout}} & GLUE &&&&&&& SuperGLUE &&&&&&\",\n", | |||
| " r\"Task→ &&&& QQP & QNLI & MNLI & SST-2 & STS-B & MRPC & CoLA & MultiRC & RTE & CB & COPA & WiC & BoolQ & Avg.\",\n", | |||
| " r\"Method↓ &&&& F1/Acc. & Acc. & Acc. & Acc. & PCC/$\\rho$ & F1/Acc. & MCC & F1a/EM & Acc. & F1/Acc. & Acc. & Acc. & Acc. & -\"\n", | |||
| " ]\n", | |||
| "\n", | |||
| "def _section_row(name):\n", | |||
| " return name\n", | |||
| "\n", | |||
| "def to_pure_number(item):\n", | |||
| " if isinstance(item, list):\n", | |||
| " item = [x for x in item if x != '-']\n", | |||
| " if len(item) == 0:\n", | |||
| " return '-'\n", | |||
| " return sum(item) / len(item)\n", | |||
| " return item\n", | |||
| "\n", | |||
| "def to_pure_numbers(numbers):\n", | |||
| " return np.array([\n", | |||
| " to_pure_number(list_item)\n", | |||
| " for list_item in numbers\n", | |||
| " ])\n", | |||
| "\n", | |||
| "def _convert_single_number(single_number):\n", | |||
| " if single_number == '-':\n", | |||
| " return '-'\n", | |||
| " if isinstance(single_number, str):\n", | |||
| " print(single_number)\n", | |||
| " return f\"{100 * single_number:.1f}\"\n", | |||
| "\n", | |||
| "def _convert_number(n):\n", | |||
| " if not isinstance(n, list):\n", | |||
| " n = [n]\n", | |||
| " number_str = \"/\".join([_convert_single_number(n_item) for n_item in n])\n", | |||
| " if to_pure_number(n) == 0:\n", | |||
| " return f'{number_str} $\\\\dag$'\n", | |||
| " return number_str\n", | |||
| "\n", | |||
| "def _get_mark(mark_bool):\n", | |||
| " if mark_bool is None:\n", | |||
| " return \"\"\n", | |||
| " return \"\\\\cmark\" if mark_bool else \"\\\\xmark\"\n", | |||
| "\n", | |||
| "def _normal_row(name, prompt_count, is_softmax, is_dropout, numbers, bold_mask=None):\n", | |||
| " numbers_str = [_convert_number(n) for n in numbers]\n", | |||
| " if bold_mask is not None:\n", | |||
| " for idx, bold_state in enumerate(bold_mask):\n", | |||
| " if bold_state:\n", | |||
| " numbers_str[idx] = \"\\\\textbf{\" + numbers_str[idx] + \"}\"\n", | |||
| " \n", | |||
| " prompt_count = str(prompt_count) if prompt_count is not None else \"\"\n", | |||
| " return \" & \".join([name, prompt_count, _get_mark(is_softmax), _get_mark(is_dropout), *numbers_str])\n", | |||
| "\n", | |||
| "def _compute_mean(numbers):\n", | |||
| " return np.array([[\n", | |||
| " '-'\n", | |||
| " if '-' in list(row)\n", | |||
| " else to_pure_numbers(row).mean()\n", | |||
| " for row in numbers\n", | |||
| " ]], dtype=object).T\n", | |||
| "\n", | |||
| "def generate_rows(names, prompt_counts, softmaxes, dropouts, numbers, first_row_bold=False):\n", | |||
| " mean = _compute_mean(numbers)\n", | |||
| " numbers = np.concatenate((numbers, mean), axis=1)\n", | |||
| " \n", | |||
| " if first_row_bold:\n", | |||
| " mask = np.zeros_like(numbers)\n", | |||
| " mask[0, :] = 1\n", | |||
| " mask = mask.astype(bool)\n", | |||
| " args_zip = zip(names, prompt_counts, softmaxes, dropouts, numbers, mask)\n", | |||
| " else:\n", | |||
| " args_zip = zip(names, prompt_counts, softmaxes, dropouts, numbers)\n", | |||
| " \n", | |||
| " rows = [\n", | |||
| " _normal_row(*args)\n", | |||
| " for args in args_zip\n", | |||
| " ]\n", | |||
| " return rows\n", | |||
| " \n", | |||
| "def generate_table(input_dict):\n", | |||
| " all_rows = [(_section_row(key), *val) for (key, val) in input_dict.items()]\n", | |||
| " rows_count_seq = [len(row) for row in all_rows]\n", | |||
| " all_rows_flatten = itertools.chain.from_iterable(all_rows)\n", | |||
| " end_line = '\\\\\\\\\\n'\n", | |||
| " rows = [\n", | |||
| " *_head_rows(),\n", | |||
| " *all_rows_flatten\n", | |||
| " ]\n", | |||
| " return r\"\"\"\\begin{tblr}{\n", | |||
| " %s\n", | |||
| "}\n", | |||
| "%s\n", | |||
| "\\end{tblr}\n", | |||
| "\"\"\" % (_tblr_args(rows_count_seq), end_line.join(rows + [\"\"]))" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 15, | |||
| "id": "f760915e-5c07-4aed-b0b8-1d46a5002bd0", | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "\\begin{tblr}{\n", | |||
| " column{2-18} = {c},\n", | |||
| " cell{1}{2, 3, 4} = {r=3}{b},\n", | |||
| " cell{1}{5} = {c=7}{c},\n", | |||
| " cell{1}{12} = {c=6}{},\n", | |||
| " vline{2, 3, 4, 5,12,18} = {1-3}{},\n", | |||
| " hline{2} = {4-17}{},\n", | |||
| " row{4, 8, 11, 13} = {c},\n", | |||
| " cell{4, 8, 11, 13}{1} = {c=18}{},\n", | |||
| " hline{4, 8, 11, 13, 15} = {-}{2px},,\n", | |||
| "}\n", | |||
| "&\\rot{\\eztb{\\# Prompts}} & \\rot{\\eztb{Softmax}} & \\rot{\\eztb{Dropout}} & GLUE &&&&&&& SuperGLUE &&&&&&\\\\\n", | |||
| "Task→ &&&& QQP & QNLI & MNLI & SST-2 & STS-B & MRPC & CoLA & MultiRC & RTE & CB & COPA & WiC & BoolQ & Avg.\\\\\n", | |||
| "Method↓ &&&& F1/Acc. & Acc. & Acc. & Acc. & PCC/$\\rho$ & F1/Acc. & MCC & F1a/EM & Acc. & F1/Acc. & Acc. & Acc. & Acc. & -\\\\\n", | |||
| "T5 Base\\\\\n", | |||
| "SuperPos PT & 10 & \\xmark & \\xmark & \\textbf{87.8/90.8} & \\textbf{93.5} & \\textbf{86.0} & \\textbf{94.4} & \\textbf{90.2/90.1} & \\textbf{92.4/89.5} & \\textbf{59.7} & \\textbf{77.7/40.9} & \\textbf{80.1} & \\textbf{97.4/96.4} & \\textbf{66.0} & \\textbf{67.6} & \\textbf{81.3} & \\textbf{81.2}\\\\\n", | |||
| "ATTEMPT $\\star$ & 100 & \\cmark & \\cmark & -/90.3 & 93.0 & 84.3 & 93.2 & 89.7/- & -/85.7 & 57.4 & 74.4/- & 73.4 & -/78.6 & - & 66.8 & 78.8 & -\\\\\n", | |||
| "Residual PT $\\star$ & 10 & \\xmark & \\cmark & - & - & - & - & - & - & - & 59.3 & 70.4 & 79.2 & 58.3 & 66.8 & 77.9 & -\\\\\n", | |||
| "T5v1.1 Small LM-Adapted\\\\\n", | |||
| "SuperPos PT & 10 & \\xmark & \\xmark & \\textbf{79.1/83.3} & \\textbf{85.3} & \\textbf{71.7} & \\textbf{89.8} & \\textbf{84.0/84.0} & \\textbf{89.9/85.8} & \\textbf{38.9} & \\textbf{66.6/16.7} & \\textbf{64.6} & \\textbf{73.6/76.8} & \\textbf{58.0} & \\textbf{65.7} & \\textbf{68.9} & \\textbf{70.2}\\\\\n", | |||
| "SuperPos PT & 10 & \\cmark & \\xmark & 69.6/75.2 & 76.0 & 42.7 & 82.9 & 45.5/43.3 & 82.4/73.0 & 4.6 & 47.5/0.9 & 52.0 & 49.9/71.4 & 57.0 & 56.4 & 62.3 & 54.9\\\\\n", | |||
| "T5v1.1 Base LM-Adapted\\\\\n", | |||
| "SuperPos PT & 10 & \\xmark & \\xmark & 81.9/86.3 & 89.8 & 81.0 & 94.2 & 88.6/88.5 & 89.7/85.5 & 56.5 & 72.9/24.9 & 70.4 & 78.3/82.1 & 62.0 & 67.6 & 74.0 & 75.8\\\\\n", | |||
| "GPT-3.5-Turbo\\\\\n", | |||
| "1 Shot & & & & 76.3/79.2 & 70.9 & 58.5 & 94.0 & 34.6/34.1 & 84.6/77.0 & 46.1 & 77.9/34.1 & 70.8 & 55.6/62.5 & 95.0 & 58.8 & 69.6 & 67.1\\\\\n", | |||
| "\n", | |||
| "\\end{tblr}\n", | |||
| "\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "comp_orig_rows = generate_rows(\n", | |||
| " names=['SuperPos PT', 'ATTEMPT $\\star$', 'Residual PT $\\star$'],\n", | |||
| " prompt_counts=[10, 100, 10],\n", | |||
| " softmaxes=[False, True, False],\n", | |||
| " dropouts=[False, True, True],\n", | |||
| " numbers=comp_orig_df.to_numpy(),\n", | |||
| " first_row_bold=True\n", | |||
| ")\n", | |||
| "comp_softmax_rows = generate_rows(\n", | |||
| " names=['SuperPos PT', 'SuperPos PT'],\n", | |||
| " prompt_counts=[10, 10],\n", | |||
| " softmaxes=[False, True],\n", | |||
| " dropouts=[False, False],\n", | |||
| " numbers=comp_softmax_df.to_numpy(),\n", | |||
| " first_row_bold=True\n", | |||
| ")\n", | |||
| "comb_base_rows = generate_rows(\n", | |||
| " names=['SuperPos PT'],\n", | |||
| " prompt_counts=[10],\n", | |||
| " softmaxes=[False],\n", | |||
| " dropouts=[False],\n", | |||
| " numbers=comb_base_df.to_numpy()\n", | |||
| ")\n", | |||
| "comp_gpt_rows = generate_rows(\n", | |||
| " names=['1 Shot'],\n", | |||
| " prompt_counts=[None],\n", | |||
| " softmaxes=[None],\n", | |||
| " dropouts=[None],\n", | |||
| " numbers=comp_gpt_df.to_numpy()\n", | |||
| ")\n", | |||
| "\n", | |||
| "\n", | |||
| "print(generate_table({\n", | |||
| " 'T5 Base': comp_orig_rows,\n", | |||
| " 'T5v1.1 Small LM-Adapted': comp_softmax_rows,\n", | |||
| " 'T5v1.1 Base LM-Adapted': comb_base_rows,\n", | |||
| " 'GPT-3.5-Turbo': comp_gpt_rows\n", | |||
| "}))" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 9, | |||
| "id": "624c8219-2f9f-4321-9bb4-e5c9f4c8a2d8", | |||
| "metadata": {}, | |||
| "outputs": [ | |||
| { | |||
| "ename": "NameError", | |||
| "evalue": "name 'base_df' is not defined", | |||
| "output_type": "error", | |||
| "traceback": [ | |||
| "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m", | |||
| "\u001b[0;31mNameError\u001b[0m Traceback (most recent call last)", | |||
| "Cell \u001b[0;32mIn[9], line 1\u001b[0m\n\u001b[0;32m----> 1\u001b[0m \u001b[43mbase_df\u001b[49m\u001b[38;5;241m.\u001b[39mto_numpy()\n", | |||
| "\u001b[0;31mNameError\u001b[0m: name 'base_df' is not defined" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "base_df.to_numpy()" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": null, | |||
| "id": "c9559566-d8fb-4310-ad31-fb204877609f", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import pandas as pd" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": null, | |||
| "id": "98ad4c6b-7de1-483a-993e-f4f3332a65c6", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "pd.DataFrame({'a': [1, 2., '-'], 'b': [0, 5, 1]}).to_numpy()[0].mean()" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": null, | |||
| "id": "a68c7196-462b-407f-b84a-98265296b612", | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [] | |||
| } | |||
| ], | |||
| "metadata": { | |||
| "kernelspec": { | |||
| "display_name": "Python [conda env:deep]", | |||
| "language": "python", | |||
| "name": "conda-env-deep-py" | |||
| }, | |||
| "language_info": { | |||
| "codemirror_mode": { | |||
| "name": "ipython", | |||
| "version": 3 | |||
| }, | |||
| "file_extension": ".py", | |||
| "mimetype": "text/x-python", | |||
| "name": "python", | |||
| "nbconvert_exporter": "python", | |||
| "pygments_lexer": "ipython3", | |||
| "version": "3.10.13" | |||
| } | |||
| }, | |||
| "nbformat": 4, | |||
| "nbformat_minor": 5 | |||
| } | |||
+ 81
- 0
14_thesis_run/config1.yaml
View File
| @@ -0,0 +1,81 @@ | |||
| default: &default | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| base_save_path: /disks/ssd/trained_final/sing_thesis | |||
| model_name: google/t5-small-lm-adapt | |||
| project_name_prefix: sing_thesis | |||
| experiment_name_suffix: null | |||
| train_batch_size: 24 | |||
| valid_batch_size: 24 | |||
| remove_dropout: true | |||
| learning_rate: 0.01 | |||
| weight_decay: 0.01 | |||
| num_epochs: 20 | |||
| peft_params: null # no mutation | |||
| hot_modules: | |||
| - sadcl | |||
| best_finder: | |||
| save: True | |||
| metric: valid_mean | |||
| higher_better: true | |||
| tasks: | |||
| - glue:qqp | |||
| - glue:mnli | |||
| - glue:qnli | |||
| pp: &pp | |||
| # - /disks/ssd/hzi_trained/hzi_cluster_t5_small_glue-mnli/10_combine_128 | |||
| # - /disks/ssd/hzi_trained/hzi_cluster_t5_small_glue-qqp/10_combine_128 | |||
| # - /disks/ssd/trained_final/cont_thesis/cont_thesis_t5_base_glue-mrpc/10_combine_128 | |||
| # - /disks/ssd/trained_final/cont_thesis/cont_thesis_t5_base_glue-cola/10_combine_128_simple | |||
| # - /disks/ssd/trained_final/cont_thesis/cont_thesis_t5_base_glue-stsb/10_combine_128_simple | |||
| # - /disks/ssd/trained_final/cont_thesis/cont_thesis_t5_base_glue-sst2/10_combine_128_simple | |||
| # - /disks/ssd/trained_final/cont_thesis/cont_thesis_t5_base_superglue-rte/10_combine_128_simple | |||
| # - /disks/ssd/trained_final/cont_thesis/cont_thesis_t5_base_superglue-cb/10_combine_128_simple | |||
| # - /disks/ssd/trained_final/cont_thesis/cont_thesis_t5_base_superglue-copa/10_combine_128_simple | |||
| run_configs: | |||
| - <<: *default | |||
| peft_params: | |||
| kind: combine | |||
| n_tokens: 50 | |||
| n_comb_tokens: 128 | |||
| # pretrained_paths: *pp | |||
| use_pretrained_mode: simple | |||
| # - <<: *default | |||
| # peft_params: | |||
| # kind: combine | |||
| # n_tokens: 10 | |||
| # n_comb_tokens: 128 | |||
| # pretrained_paths: *pp | |||
| # use_pretrained_mode: gumbal | |||
| # - <<: *default | |||
| # peft_params: | |||
| # kind: combine | |||
| # n_tokens: 10 | |||
| # n_comb_tokens: 128 | |||
| # pretrained_paths: *pp | |||
| # use_pretrained_mode: softmax | |||
| # tempreture: 0.2 | |||
| # - <<: *default | |||
| # peft_params: | |||
| # kind: combine | |||
| # n_tokens: 10 | |||
| # n_comb_tokens: 128 | |||
| # pretrained_paths: *pp | |||
| # use_pretrained_mode: softmax | |||
| # tempreture: 1. | |||
| # - <<: *default | |||
| # peft_params: | |||
| # kind: combine | |||
| # n_tokens: 10 | |||
| # n_comb_tokens: 128 | |||
| # pretrained_paths: *pp | |||
| # use_pretrained_mode: softmax | |||
| # tempreture: 5. | |||
| # - <<: *default | |||
| # peft_params: | |||
| # kind: combine | |||
| # n_tokens: 10 | |||
| # n_comb_tokens: 128 | |||
+ 57
- 0
14_thesis_run/train.py
View File
| @@ -0,0 +1,57 @@ | |||
| from tqdm import tqdm | |||
| import numpy as np | |||
| import torch | |||
| import os | |||
| import sys | |||
| sys.path.insert(1, os.path.join(sys.path[0], '..')) | |||
| from _datasets import AutoLoad | |||
| from _trainer import auto_train | |||
| from _mydelta import auto_mutate | |||
| from _models import auto_model | |||
| from _config import Config, load_config | |||
| from _utils import print_system_info, silent_logs | |||
| DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") | |||
| def run_experminent(config, task_name): | |||
| np.random.seed(config.random_seed) | |||
| torch.manual_seed(config.random_seed) | |||
| # ______________________LOAD MODEL_____________________________ | |||
| model, tokenizer = auto_model(config.model_name, AutoLoad.get_task_output(task_name)) | |||
| # ______________________MUTATE MODEL_____________________________ | |||
| n_prefix_token = 0 | |||
| if config.peft_params is not None: | |||
| n_prefix_token = config.peft_params.n_tokens | |||
| delta_module = auto_mutate( | |||
| model=model, | |||
| tokenizer=tokenizer, | |||
| peft_params=config.peft_params.to_dict(), | |||
| remove_dropout=config.remove_dropout | |||
| ) | |||
| # ______________________LOAD DATA_____________________________ | |||
| autoload = AutoLoad(tokenizer, n_prefix_token=n_prefix_token) | |||
| # ______________________TRAIN_____________________________ | |||
| dataset = autoload.get_and_map(task_name) | |||
| auto_train(model, tokenizer, dataset, config, device=DEVICE) | |||
| if __name__ == '__main__': | |||
| print_system_info() | |||
| silent_logs() | |||
| configs = load_config(sys.argv[1]) | |||
| run_configs = tqdm(configs.run_configs, position=0, desc="Experiment") | |||
| for run_config in run_configs: | |||
| tasks = tqdm(run_config.tasks, position=1, desc="Task:", leave=False) | |||
| for task_name in tasks: | |||
| tasks.set_description(f'Task: {task_name}') | |||
| torch.cuda.empty_cache() | |||
| run_experminent(run_config, task_name) | |||
+ 64
- 0
14_thesis_run/train_cont.py
View File
| @@ -0,0 +1,64 @@ | |||
| from tqdm import tqdm | |||
| import numpy as np | |||
| import torch | |||
| import os | |||
| import sys | |||
| sys.path.insert(1, os.path.join(sys.path[0], '..')) | |||
| from _datasets import AutoLoad | |||
| from _trainer import auto_train | |||
| from _mydelta import auto_mutate | |||
| from _models import auto_model | |||
| from _config import Config, load_config | |||
| from _utils import print_system_info, silent_logs | |||
| DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") | |||
| def run_experminent(config, task_name): | |||
| silent_logs() | |||
| np.random.seed(config.random_seed) | |||
| torch.manual_seed(config.random_seed) | |||
| # ______________________LOAD MODEL_____________________________ | |||
| model, tokenizer = auto_model(config.model_name, AutoLoad.get_task_output(task_name)) | |||
| # ______________________MUTATE MODEL_____________________________ | |||
| n_prefix_token = 0 | |||
| if config.peft_params is not None: | |||
| n_prefix_token = config.peft_params.n_tokens | |||
| delta_module = auto_mutate( | |||
| model=model, | |||
| tokenizer=tokenizer, | |||
| peft_params=config.peft_params.to_dict(), | |||
| remove_dropout=config.remove_dropout | |||
| ) | |||
| # ______________________LOAD DATA_____________________________ | |||
| autoload = AutoLoad(tokenizer, n_prefix_token=n_prefix_token) | |||
| # ______________________TRAIN_____________________________ | |||
| dataset = autoload.get_and_map(task_name) | |||
| return auto_train(model, tokenizer, dataset, config, device=DEVICE) | |||
| if __name__ == '__main__': | |||
| print_system_info() | |||
| configs = load_config(sys.argv[1]) | |||
| run_configs = tqdm(configs.run_configs, position=0, desc="Experiment") | |||
| for run_config in run_configs: | |||
| tasks = tqdm(run_config.tasks, position=1, desc="Task:", leave=False) | |||
| tasks_path = [] | |||
| for task_name in tasks: | |||
| tasks.set_description(f'Task: {task_name}') | |||
| torch.cuda.empty_cache() | |||
| run_config.peft_params._write_mode = True | |||
| orig_paths = run_config.peft_params.get('pretrained_paths', []) | |||
| run_config.peft_params.pretrained_paths = list(orig_paths) + tasks_path | |||
| delattr(run_config.peft_params, '_write_mode') | |||
| saved_path = run_experminent(run_config, task_name) | |||
| tasks_path.append(saved_path) | |||
+ 80
- 0
README.md
View File
| @@ -0,0 +1,80 @@ | |||
| # Project README | |||
| This project is based on `Python 3.10`. To get started, you can create an environment using conda with the following command: | |||
| ```bash | |||
| conda create -n superpos python=3.10 | |||
| ``` | |||
| After setting up the environment, install all the required packages with: | |||
| ```bash | |||
| pip install -r requirements.txt | |||
| ``` | |||
| ## Project Structure | |||
| The entry point of this project is located in the `./09_Cluster` directory. The most important files in this directory are the `config.yaml` files. Below is an example of a configuration file: | |||
| ```yaml | |||
| default: &default | |||
| use_tqdm: true | |||
| random_seed: 42 | |||
| base_save_path: /home/msadraei/trained_final | |||
| model_name: google/t5-base-lm-adapt | |||
| project_name_prefix: iclr_attempt_lmt5 | |||
| experiment_name_suffix: null | |||
| train_batch_size: 32 | |||
| valid_batch_size: 32 | |||
| remove_dropout: true | |||
| learning_rate: 0.01 | |||
| weight_decay: 0.01 | |||
| num_epochs: 40 | |||
| peft_params: null # no mutation | |||
| hot_modules: | |||
| - sadcl | |||
| best_finder: | |||
| save: true | |||
| metric: valid_mean | |||
| higher_better: true | |||
| tasks: | |||
| - glue:cola | |||
| - glue:mrpc | |||
| - glue:stsb | |||
| - superglue:rte | |||
| - superglue:cb | |||
| - superglue:wic | |||
| - superglue:copa | |||
| - superglue:boolq | |||
| - superglue:multirc | |||
| pp: &pp | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_base_glue-mnli/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_base_glue-sst2/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_base_glue-qqp/10_combine_128 | |||
| - /home/msadraei/trained_final/hzi_cluster_t5_base_glue-qnli/10_combine_128 | |||
| run_configs: | |||
| - <<: *default | |||
| learning_rate: 0.3 | |||
| weight_decay: 0.00001 | |||
| peft_params: | |||
| kind: attempt | |||
| n_tokens: 10 | |||
| g_bottleneck: 100 | |||
| pretrained_paths: *pp | |||
| ``` | |||
| ## PEFT Support | |||
| This project supports different kinds of Parameter-Efficient Fine-Tuning (PEFT) methods. The valid values for PEFT types are `'combine'`, `'residual'`, `'simple'`, `'spot'`, and `'attempt'`. Each run configuration will be executed over each dataset in the list of tasks. | |||
| ## Running the Project | |||
| To run a configuration, use the following command: | |||
| ```bash | |||
| python train.py config.yaml | |||
| ``` | |||
| This will start the training process based on the settings defined in `config.yaml`. | |||
+ 191
- 0
Untitled.ipynb
View File
| @@ -0,0 +1,191 @@ | |||
| { | |||
| "cells": [ | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 1, | |||
| "id": "93e252d5-c7d2-48bd-9d21-70bb5694a026", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "from _mydelta.multi_prompt import MultiPrompt" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 2, | |||
| "id": "c9cd7bc9-cd12-4e77-9176-d71c614a6094", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "from pathlib import Path\n", | |||
| "path = Path('/disks/ssd/trained_final/cont_thesis/cont_thesis_t5_small_glue-cola/10_combine_128_simple')\n", | |||
| "best_out = MultiPrompt.get_saved_final_emb(\n", | |||
| " config_path=path / 'config.json',\n", | |||
| " weights_path=path / 'best.pt'\n", | |||
| ")" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 3, | |||
| "id": "853f0084-5b12-40e0-a6ea-da6cd96bcd88", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "text/plain": [ | |||
| "torch.Size([10, 512])" | |||
| ] | |||
| }, | |||
| "execution_count": 3, | |||
| "metadata": {}, | |||
| "output_type": "execute_result" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "best_out.shape" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 4, | |||
| "id": "0807f193-4cb5-4d84-9210-3581e2e49c51", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "import torch\n", | |||
| "\n", | |||
| "sd = torch.load(path / 'best.pt')" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 7, | |||
| "id": "73685dcd-d842-4265-b1db-760124840212", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "text/plain": [ | |||
| "tensor([0.3015], device='cuda:0')" | |||
| ] | |||
| }, | |||
| "execution_count": 7, | |||
| "metadata": {}, | |||
| "output_type": "execute_result" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "sd['prompts.2.sadcl_coeff_pretrained']" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 16, | |||
| "id": "dffe272c-97d5-41de-ac31-fd2702163670", | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [ | |||
| "from accelerate import Accelerator\n", | |||
| "import accelerate.utils.other as auo\n", | |||
| "import accelerate.logging as al" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 25, | |||
| "id": "8d184d14-a9b7-41ae-b5f8-cf977b7009fd", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [], | |||
| "source": [ | |||
| "# Accelerator()\n", | |||
| "\n", | |||
| "al" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 28, | |||
| "id": "972a0e50-43aa-44eb-8c10-3e86fba0819d", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "data": { | |||
| "text/plain": [ | |||
| "50" | |||
| ] | |||
| }, | |||
| "execution_count": 28, | |||
| "metadata": {}, | |||
| "output_type": "execute_result" | |||
| } | |||
| ], | |||
| "source": [ | |||
| "auo.logger.getEffectiveLevel()" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": 18, | |||
| "id": "7a247b50-57a0-43cd-9a8d-18d58ea1fd27", | |||
| "metadata": { | |||
| "tags": [] | |||
| }, | |||
| "outputs": [ | |||
| { | |||
| "name": "stdout", | |||
| "output_type": "stream", | |||
| "text": [ | |||
| "__main__\n" | |||
| ] | |||
| } | |||
| ], | |||
| "source": [ | |||
| "print(__name__)" | |||
| ] | |||
| }, | |||
| { | |||
| "cell_type": "code", | |||
| "execution_count": null, | |||
| "id": "6abe432e-bb4b-4610-899d-e7759512181c", | |||
| "metadata": {}, | |||
| "outputs": [], | |||
| "source": [] | |||
| } | |||
| ], | |||
| "metadata": { | |||
| "kernelspec": { | |||
| "display_name": "Python [conda env:deep]", | |||
| "language": "python", | |||
| "name": "conda-env-deep-py" | |||
| }, | |||
| "language_info": { | |||
| "codemirror_mode": { | |||
| "name": "ipython", | |||
| "version": 3 | |||
| }, | |||
| "file_extension": ".py", | |||
| "mimetype": "text/x-python", | |||
| "name": "python", | |||
| "nbconvert_exporter": "python", | |||
| "pygments_lexer": "ipython3", | |||
| "version": "3.10.13" | |||
| } | |||
| }, | |||
| "nbformat": 4, | |||
| "nbformat_minor": 5 | |||
| } | |||
+ 103
- 0
_config.py
View File
| @@ -0,0 +1,103 @@ | |||
| import json | |||
| from os import PathLike | |||
| from pathlib import Path | |||
| from typing import Any, Union, Optional, Literal | |||
| import yaml | |||
| class Config(object): | |||
| def __init__(self, data: dict, base_path: str): | |||
| self._write_mode = True | |||
| self._base_path = base_path | |||
| for key, val in data.items(): | |||
| if isinstance(val, (list, tuple)): | |||
| generator = (self.__parse_value(item) for item in val) | |||
| setattr(self, key, tuple(generator)) | |||
| else: | |||
| setattr(self, key, self.__parse_value(val)) | |||
| delattr(self, '_base_path') | |||
| delattr(self, '_write_mode') | |||
| def __parse_value(self, value: Any): | |||
| if isinstance(value, dict): | |||
| return self.__class__(value, self._base_path) | |||
| if isinstance(value, str): | |||
| if value.startswith('path:'): | |||
| value = value[len('path:'):] | |||
| value = str((Path(self._base_path) / value).absolute()) | |||
| return value | |||
| def __setattr__(self, key, value): | |||
| if key == '_write_mode' or hasattr(self, '_write_mode'): | |||
| super().__setattr__(key, value) | |||
| else: | |||
| raise Exception('Set config') | |||
| def __delattr__(self, item): | |||
| if item == '_write_mode' or hasattr(self, '_write_mode'): | |||
| super().__delattr__(item) | |||
| else: | |||
| raise Exception('Del config') | |||
| def __contains__(self, name): | |||
| return name in self.__dict__ | |||
| def __getitem__(self, name): | |||
| return self.__dict__[name] | |||
| def __repr__(self): | |||
| return repr(self.to_dict()) | |||
| @staticmethod | |||
| def __item_to_dict(val): | |||
| if isinstance(val, Config): | |||
| return val.to_dict() | |||
| if isinstance(val, (list, tuple)): | |||
| generator = (Config.__item_to_dict(item) for item in val) | |||
| return list(generator) | |||
| return val | |||
| def merge(self, other_conf): | |||
| return Config( | |||
| data={**self.to_dict(), **other_conf.to_dict()}, | |||
| base_path='' | |||
| ) | |||
| def get(self, key, default=None): | |||
| return self.__dict__.get(key, default) | |||
| def to_dict(self) -> dict: | |||
| """ | |||
| Convert object to dict recursively! | |||
| :return: Dictionary output | |||
| """ | |||
| return { | |||
| key: Config.__item_to_dict(val) for key, val in self.__dict__.items() | |||
| } | |||
| def load_config(config_file_path: Union[str, PathLike], base_path: Optional[Union[str, PathLike]] = None, | |||
| file_type: Literal['json', 'JSON', 'yml', 'YML', 'yaml', 'YAML', None] = None) -> Config: | |||
| """ | |||
| Load configs from a YAML or JSON file. | |||
| :param config_file_path: File path as a string or pathlike object | |||
| :param base_path: Base path for `path:` strings, default value is parent of `config_file_path` | |||
| :param file_type: What is the format of the file. If none it will look at the file extension | |||
| :return: A config object | |||
| """ | |||
| if base_path is None: | |||
| base_path = str(Path(config_file_path).resolve().parent) | |||
| if file_type is None: | |||
| file_type = Path(config_file_path).suffix | |||
| file_type = file_type[1:] # remove extra first dot! | |||
| content = Path(config_file_path).read_text(encoding='utf-8') | |||
| load_content = { | |||
| 'json': json.loads, | |||
| 'yaml': yaml.safe_load, | |||
| 'yml': yaml.safe_load | |||
| }[file_type.lower()] | |||
| return Config(load_content(content), base_path) | |||
+ 3
- 0
_datasets/__init__.py
View File
| @@ -0,0 +1,3 @@ | |||
| from .glue_helper import GLUEHelper | |||
| from .autoload import AutoLoad | |||
| from .dataloader import generate_dataloader, generate_output_preprocess | |||
+ 144
- 0
_datasets/autoload.py
View File
| @@ -0,0 +1,144 @@ | |||
| from datasets import DatasetDict | |||
| from .glue_helper import GLUEHelper, SuperGLUEHelper | |||
| class AutoLoad: | |||
| def __init__(self, tokenizer, n_prefix_token=0, lazy_load=True): | |||
| self.tokenizer = tokenizer | |||
| self.n_prefix_token = n_prefix_token | |||
| # self.lowercase = lowercase | |||
| self.post_tokenizer_map = { | |||
| 'input_ids': 0, | |||
| 'attention_mask': 1, | |||
| 'token_type_ids': 0 | |||
| } | |||
| load_names = [] if lazy_load else None | |||
| self.glue_helper = GLUEHelper(load_names) | |||
| self.superglue_helper = SuperGLUEHelper(load_names) | |||
| @property | |||
| def _is_bert(self): | |||
| return 'bert' in self.tokenizer.name_or_path.lower() | |||
| def __output_type(self): | |||
| return_value = [ | |||
| 'input_ids', 'attention_mask', 'labels' | |||
| ] | |||
| if self._is_bert: | |||
| return return_value + ['token_type_ids'] | |||
| return return_value | |||
| def _add_prefix(self, tokenizer_out): | |||
| if self.n_prefix_token == 0: | |||
| return tokenizer_out | |||
| for special_key, pad_val in self.post_tokenizer_map.items(): | |||
| if special_key in tokenizer_out: | |||
| for batch_item in tokenizer_out[special_key]: | |||
| batch_item[:0] = ([pad_val] * self.n_prefix_token) | |||
| return tokenizer_out | |||
| def map_dataset(self, dataset, input_info, output_info, task_name): | |||
| def preprocess(input_dict_row): | |||
| return_value = {} | |||
| if task_name == 'wic': | |||
| word = input_dict_row['word'] | |||
| sent1 = input_dict_row['sentence1'] | |||
| sent2 = input_dict_row['sentence2'] | |||
| slice1 = slice(input_dict_row['start1'], input_dict_row['end1']) | |||
| slice2 = slice(input_dict_row['start2'], input_dict_row['end2']) | |||
| anotate_word = lambda _sent, _slice: _sent[:_slice.start] + "** " + _sent[_slice] + " **" + _sent[_slice.stop:] | |||
| input_dict_row['sentence1'] = anotate_word(sent1, slice1) | |||
| input_dict_row['sentence2'] = anotate_word(sent2, slice2) | |||
| return_value['sentence1'] = input_dict_row['sentence1'] | |||
| return_value['sentence2'] = input_dict_row['sentence2'] | |||
| if len(input_info) == 1: | |||
| return_value['merged'] = input_dict_row[input_info[0]] | |||
| else: | |||
| return_value['merged'] = "".join(f"{key}: {input_dict_row[key]} " for key in input_info) | |||
| return return_value | |||
| def create_input(input_dict_rows): | |||
| if self._is_bert: | |||
| if len(input_info) < 3: | |||
| generator = (input_dict_rows[input_name] for input_name in input_info) | |||
| else: | |||
| generator = [input_dict_rows['merged']] | |||
| tokenizer_out = self.tokenizer( | |||
| *generator, | |||
| truncation=True, | |||
| max_length=self.tokenizer.model_max_length - self.n_prefix_token | |||
| ) | |||
| else: # t5 or bart multi tokens | |||
| tokenizer_out = self.tokenizer(input_dict_rows['merged']) | |||
| return self._add_prefix(tokenizer_out) | |||
| def create_output(input_dict): | |||
| if self.tokenizer._is_seq2seq: | |||
| tokens = self.tokenizer(output_info.int2str(input_dict['label'])) | |||
| return tokens.input_ids | |||
| else: | |||
| return input_dict['label'] | |||
| def map_function(input_dict): | |||
| return { | |||
| **create_input(input_dict), | |||
| 'labels': create_output(input_dict) | |||
| } | |||
| dataset = dataset.map(preprocess) # pass all as one batch | |||
| dataset = dataset.map(map_function, batched=True) # pass all as one batch | |||
| dataset.set_format(type='torch', columns=self.__output_type()) | |||
| return dataset | |||
| def get_glue(self, category, task_name): | |||
| glue_agent = { | |||
| 'glue': self.glue_helper, | |||
| 'superglue': self.superglue_helper | |||
| }[category] | |||
| dataset = glue_agent.get_dataset(task_name) | |||
| train_ds = dataset[glue_agent.get_task_train_key(task_name)] | |||
| valid_ds_keys = glue_agent.get_task_validation_key(task_name) | |||
| valid_ds_dict = DatasetDict({ | |||
| key: dataset[key] | |||
| for key in valid_ds_keys | |||
| }) | |||
| kwargs = { | |||
| 'input_info': glue_agent.get_task_input(task_name), | |||
| 'output_info': glue_agent.get_task_output(task_name), | |||
| 'task_name': task_name | |||
| } | |||
| return { | |||
| 'name': f'{category}-{task_name}', | |||
| 'train': self.map_dataset(train_ds, **kwargs), | |||
| 'valid_dict': self.map_dataset(valid_ds_dict, **kwargs), | |||
| 'compute_metrics': glue_agent.generate_compute_metrics(task_name, text2text=self.tokenizer._is_seq2seq) | |||
| } | |||
| def get_and_map(self, task_name): | |||
| category, ds_name = task_name.split(':') | |||
| if category in ['glue', 'superglue']: | |||
| return self.get_glue(category, ds_name) | |||
| raise Exception("not implented") | |||
| @staticmethod | |||
| def get_task_output(full_task_name): | |||
| category, task_name = full_task_name.split(':') | |||
| if category in ['glue', 'superglue']: | |||
| selected_helper = { | |||
| 'glue': GLUEHelper, | |||
| 'superglue': SuperGLUEHelper | |||
| }[category] | |||
| return selected_helper.get_task_output(task_name) | |||
+ 44
- 0
_datasets/dataloader.py
View File
| @@ -0,0 +1,44 @@ | |||
| import torch | |||
| from transformers import DataCollatorForSeq2Seq, DataCollatorWithPadding | |||
| def generate_dataloader(tokenizer, ds_train, ds_valid_dict, train_bs, valid_bs): | |||
| if tokenizer._is_seq2seq: | |||
| col_fn = DataCollatorForSeq2Seq( | |||
| tokenizer, return_tensors='pt', padding='longest' | |||
| ) | |||
| else: | |||
| col_fn = DataCollatorWithPadding( | |||
| tokenizer, return_tensors='pt', padding='longest' | |||
| ) | |||
| train_loader = torch.utils.data.DataLoader( | |||
| ds_train, | |||
| batch_size=train_bs, | |||
| collate_fn=col_fn, | |||
| shuffle=True | |||
| ) | |||
| valid_loader = { | |||
| key: torch.utils.data.DataLoader( | |||
| val, | |||
| batch_size=valid_bs, | |||
| collate_fn=col_fn, | |||
| # shuffle=True | |||
| ) | |||
| for key, val in ds_valid_dict.items() | |||
| } | |||
| return train_loader, valid_loader | |||
| def generate_output_preprocess(tokenizer): | |||
| if tokenizer._is_seq2seq: | |||
| def preprocess(all_input_ids): | |||
| return_value = [] | |||
| for input_ids in all_input_ids: | |||
| if -100 in input_ids: | |||
| input_ids = input_ids[:input_ids.index(-100)] | |||
| return_value.append(tokenizer.decode(input_ids, skip_special_tokens=True)) | |||
| return return_value | |||
| return preprocess | |||
| else: | |||
| return lambda x: x # identity function | |||
+ 190
- 0
_datasets/glue_helper.py
View File
| @@ -0,0 +1,190 @@ | |||
| from datasets import load_dataset | |||
| from evaluate import load | |||
| import numpy as np | |||
| from _utils import prefix_dict_keys | |||
| from .my_label import MyClassLabel, MyRegresionLabel | |||
| class GLUEHelperBase: | |||
| def __init__(self, base_name, load_names): | |||
| self.base_name = base_name | |||
| self.datasets = {} | |||
| for name in load_names: | |||
| self.__load_dataset(name) | |||
| def __load_dataset(self, name): | |||
| self.datasets[name] = load_dataset(self.base_name, name) | |||
| @property | |||
| def keys(self): | |||
| return list(self.datasets.keys()) | |||
| def get_task_input(self, task_name): | |||
| return_value = list(self.datasets[task_name]['train'].column_names) | |||
| return_value.remove('label') | |||
| return_value.remove('idx') | |||
| return return_value | |||
| def get_task_train_key(self, task_name): | |||
| return 'train' | |||
| def get_task_validation_key(self, task_name): | |||
| return 'validation', | |||
| def get_dataset(self, task_name): | |||
| if task_name not in self.datasets: | |||
| self.__load_dataset(task_name) | |||
| return self.datasets[task_name] | |||
| def generate_compute_metrics(self, task_name, text2text: bool): | |||
| task_output = self.get_task_output(task_name) | |||
| glue_metric = load(self.base_name, task_name) | |||
| def compute_metrics(y_pred, y_true): | |||
| if text2text: | |||
| y_pred = task_output.str2int(y_pred) | |||
| y_true = task_output.str2int(y_true) | |||
| if None in y_pred: | |||
| y_pred = [0, 1] | |||
| y_true = [1, 0] | |||
| glue_metrics = glue_metric.compute(predictions=y_pred, references=y_true) | |||
| glue_metrics['mean'] = np.mean(list(glue_metrics.values())) | |||
| return glue_metrics | |||
| return compute_metrics | |||
| class GLUEHelper(GLUEHelperBase): | |||
| def __init__(self, load_names=None): | |||
| if load_names is None: | |||
| load_names = self.__class__.get_task_names() | |||
| super().__init__('glue', load_names) | |||
| @property | |||
| def keys(self): | |||
| return list(self.datasets.keys()) | |||
| @staticmethod | |||
| def get_task_names(): | |||
| return [ | |||
| 'cola', 'sst2', 'mrpc', 'qqp', | |||
| 'stsb', | |||
| 'mnli', # different validation matched/mismatched | |||
| 'qnli', 'rte', 'wnli', | |||
| # 'ax' not have a train section | |||
| ] | |||
| @staticmethod | |||
| def get_task_output(task_name): | |||
| if task_name == 'stsb': | |||
| return MyRegresionLabel() | |||
| names = { | |||
| 'cola': ['unacceptable', 'acceptable'], | |||
| 'sst2': ['negative', 'positive'], | |||
| 'mrpc': ['not_equivalent', 'equivalent'], | |||
| 'qqp': ['not_duplicate', 'duplicate'], | |||
| 'mnli': ['entailment', 'neutral', 'contradiction'], | |||
| 'qnli': ['entailment', 'not_entailment'], | |||
| 'rte': ['entailment', 'not_entailment'], | |||
| 'wnli': ['not_entailment', 'entailment'] | |||
| }[task_name] | |||
| return MyClassLabel(names) | |||
| def get_task_validation_key(self, task_name): | |||
| if task_name == 'mnli': | |||
| return 'validation_matched', 'validation_mismatched' | |||
| return 'validation', | |||
| class SuperGLUEHelper(GLUEHelperBase): | |||
| def __init__(self, load_names=None): | |||
| if load_names is None: | |||
| load_names = self.__class__.get_task_names() | |||
| super().__init__('super_glue', load_names) | |||
| def get_task_input(self, task_name): | |||
| map_dict = { | |||
| "wic": ("sentence1", "sentence2"), | |||
| "wsc.fixed": ("span1_text", "span1_index", "span2_text", "span2_index", "text"), | |||
| "multirc": ("question", "answer", "paragraph"), | |||
| "copa": ('choice1', 'choice2', 'premise', 'question'), | |||
| "boolq": ("question", "passage") # save question from truncing | |||
| } | |||
| if task_name in map_dict: | |||
| return map_dict[task_name] | |||
| return super().get_task_input(task_name) | |||
| @staticmethod | |||
| def get_task_output(task_name): | |||
| names = { | |||
| 'boolq': ['False', 'True'], | |||
| 'cb': ['entailment', 'contradiction', 'neutral'], | |||
| 'copa': ['choice1', 'choice2'], | |||
| 'multirc': ['False', 'True'], | |||
| 'rte': ['entailment', 'not_entailment'], | |||
| 'wic': ['False', 'True'], | |||
| 'wsc.fixed': ['False', 'True'] | |||
| }[task_name] | |||
| return MyClassLabel(names) | |||
| @staticmethod | |||
| def get_task_names(): | |||
| return [ | |||
| 'boolq', 'cb', 'copa', 'multirc', | |||
| # 'record', an span problem | |||
| 'rte', 'wic', 'wsc.fixed', | |||
| # 'axb', 'axg' no training | |||
| ] | |||
| def generate_compute_metrics(self, task_name, text2text: bool): | |||
| if task_name in ['multirc', 'record']: | |||
| task_output = self.get_task_output(task_name) | |||
| glue_metric = load(self.base_name, task_name) | |||
| all_idx = self.datasets[task_name]['validation']['idx'] | |||
| if task_name == 'multirc': | |||
| def compute_metrics(y_pred, y_true): | |||
| y_pred = task_output.str2int(y_pred) | |||
| assert len(all_idx) == len(y_pred) | |||
| if None in y_pred: | |||
| glue_metrics = {'exact_match': 0.0, 'f1_m': 0.0, 'f1_a': 0.0} | |||
| else: | |||
| y_pred = [ | |||
| { | |||
| 'prediction': y_pred_item, | |||
| 'idx': idx | |||
| } for (y_pred_item, idx) in zip(y_pred, all_idx) | |||
| ] | |||
| y_true = task_output.str2int(y_true) | |||
| glue_metrics = glue_metric.compute(predictions=y_pred, references=y_true) | |||
| glue_metrics['mean'] = np.mean([glue_metrics['exact_match'], glue_metrics['f1_a']]) | |||
| return glue_metrics | |||
| elif task_name == 'record': | |||
| def compute_metrics(y_pred, y_true): | |||
| assert len(all_idx) == len(y_pred) | |||
| if None in y_pred: | |||
| glue_metrics = {'exact_match': 0.0, 'f1': 0.0} | |||
| else: | |||
| y_pred = [ | |||
| { | |||
| 'prediction': y_pred_item, | |||
| 'idx': idx | |||
| } for (y_pred_item, idx) in zip(y_pred, all_idx) | |||
| ] | |||
| glue_metrics = glue_metric.compute(predictions=y_pred, references=y_true) | |||
| glue_metrics['mean'] = np.mean(list(glue_metrics.values())) | |||
| return glue_metrics | |||
| return compute_metrics | |||
| else: | |||
| return super().generate_compute_metrics(task_name, text2text) | |||
+ 49
- 0
_datasets/my_label.py
View File
| @@ -0,0 +1,49 @@ | |||
| import abc | |||
| class MyBaseLabel(abc.ABC): | |||
| @abc.abstractmethod | |||
| def _int2str_item(self, int_inp): | |||
| pass | |||
| @abc.abstractmethod | |||
| def _str2int_item(self, str_inp): | |||
| pass | |||
| def int2str(self, _input): | |||
| if isinstance(_input, list): | |||
| return [self._int2str_item(item) for item in _input] | |||
| return self._int2str_item(_input) | |||
| def str2int(self, _input): | |||
| if isinstance(_input, list): | |||
| return [self._str2int_item(item) for item in _input] | |||
| return self._str2int_item(_input) | |||
| class MyDummyLabel(MyBaseLabel): | |||
| def _int2str_item(self, int_inp): | |||
| return int_inp | |||
| def _str2int_item(self, str_inp): | |||
| return str_inp | |||
| class MyClassLabel(MyBaseLabel): | |||
| def __init__(self, names): | |||
| self.names = names | |||
| def _int2str_item(self, int_inp): | |||
| return self.names[int_inp] | |||
| def _str2int_item(self, str_inp): | |||
| if str_inp not in self.names: | |||
| return None | |||
| return self.names.index(str_inp) | |||
| class MyRegresionLabel(MyBaseLabel): | |||
| def _int2str_item(self, int_inp): | |||
| return "%.1f" % round(int_inp, 1) | |||
| def _str2int_item(self, str_inp): | |||
| try: | |||
| return float(str_inp) | |||
| except ValueError as ex: | |||
| return None | |||
+ 3
- 0
_models/__init__.py
View File
| @@ -0,0 +1,3 @@ | |||
| # from .adapterhub import BertAdapterModelWrapper | |||
| # from .tokenizerman import TokenizerMan | |||
| from .auto_model import auto_model | |||
+ 16
- 0
_models/_base_peft.py
View File
| @@ -0,0 +1,16 @@ | |||
| from abc import abstractmethod, ABC | |||
| from os import PathLike | |||
| from typing import Dict, Union, Optional, Iterable | |||
| class base_peft(ABC): | |||
| def __init__(self, base_model_name: Union[str, PathLike[str]], mask_token_id: int): | |||
| self.base_model_name = base_model_name | |||
| self.mask_token_id = mask_token_id | |||
| def save_peft(self, peft_name: str): | |||
| pass | |||
| @abstractmethod | |||
| def finetune_peft(self, peft_name: str, train_dataset, validation_dataset): | |||
| pass | |||
+ 158
- 0
_models/adapterhub.py
View File
| @@ -0,0 +1,158 @@ | |||
| from os import PathLike | |||
| from pathlib import Path | |||
| from typing import Dict, Union, Optional, Iterable | |||
| import numpy as np | |||
| import torch | |||
| from torch import Tensor | |||
| from torch.utils.data import Dataset | |||
| from sklearn.metrics import classification_report | |||
| from transformers import TrainingArguments, BertAdapterModel, EvalPrediction, AdapterTrainer | |||
| from transformers.adapters import Fuse | |||
| class BertAdapterModelWrapper: | |||
| def __init__(self, base_model_name: Union[str, PathLike[str]], mask_token_id: int = -100): | |||
| self.model = BertAdapterModel.from_pretrained(str(base_model_name)) | |||
| self.mask_token_id = mask_token_id | |||
| @property | |||
| def enabled_fusion(self) -> bool: | |||
| return len(self.model.config.adapters.fusions) != 0 | |||
| @property | |||
| def active_head_configs(self) -> dict: | |||
| if self.model.active_head is None: | |||
| return {} | |||
| return self.model.config.prediction_heads[self.model.active_head] | |||
| @property | |||
| def __fuse_all_adapters(self) -> Fuse: | |||
| adapters = list(self.model.config.adapters) | |||
| return Fuse(*adapters) | |||
| def load_adapters(self, adapter_path: str, adapter_names: Iterable[str], with_heads: bool = True) -> None: | |||
| for name in adapter_names: | |||
| path = Path(adapter_path) / name | |||
| self.model.load_adapter(str(path), with_head=with_heads) | |||
| def add_classification_adapter(self, adapter_name: str, num_labels: int) -> None: | |||
| if self.enabled_fusion: | |||
| raise Exception("Model has a fusion layer and you cannot add adapters to it!!!") | |||
| self.model.add_adapter(adapter_name) | |||
| self.model.add_classification_head( | |||
| adapter_name, | |||
| num_labels=num_labels | |||
| ) | |||
| def remove_heads_and_add_fusion(self, head_name: str, num_labels: int) -> None: | |||
| self.model.add_adapter_fusion(self.__fuse_all_adapters) | |||
| self.model.set_active_adapters(self.__fuse_all_adapters) | |||
| for head in list(self.model.heads.keys()): | |||
| self.model.delete_head(head) | |||
| self.model.add_tagging_head( | |||
| head_name, | |||
| num_labels=num_labels | |||
| ) | |||
| def __compute_metrics(self, pred: EvalPrediction) -> Dict[str, float]: | |||
| true_labels = pred.label_ids.ravel() | |||
| pred_labels = pred.predictions.argmax(-1).ravel() | |||
| report = classification_report(true_labels, pred_labels, output_dict=True) | |||
| return { | |||
| 'accuracy': report['accuracy'], | |||
| 'f1-score-1': report['1']['f1-score'], | |||
| 'f1-score-ma': report['macro avg']['f1-score'] | |||
| } | |||
| def __finetune( | |||
| self, | |||
| train_dataset: Dataset, | |||
| eval_dataset: Dataset, | |||
| col_fn, | |||
| training_args: Optional[dict] | |||
| ) -> None: | |||
| if training_args is None: | |||
| training_args = {} | |||
| training_args = TrainingArguments( | |||
| evaluation_strategy="epoch", | |||
| save_strategy="epoch", | |||
| # The next 2 lines are important to ensure the dataset labels are properly passed to the model | |||
| remove_unused_columns=False, | |||
| **training_args | |||
| ) | |||
| trainer = AdapterTrainer( | |||
| model=self.model, | |||
| args=training_args, | |||
| train_dataset=train_dataset, | |||
| eval_dataset=eval_dataset, | |||
| data_collator=col_fn, | |||
| compute_metrics=self.__compute_metrics | |||
| ) | |||
| trainer.train() | |||
| def finetune_adapter( | |||
| self, adapter_name: str, | |||
| train_dataset: Dataset, | |||
| eval_dataset: Dataset, | |||
| col_fn, | |||
| training_args=None | |||
| ): | |||
| self.model.train_adapter(adapter_name) # freeze other adapters and unfreeze selected adapter | |||
| self.__finetune(train_dataset, eval_dataset, col_fn, training_args) | |||
| def finetune_fusion( | |||
| self, | |||
| head_name: str, | |||
| train_dataset: Dataset, | |||
| eval_dataset: Dataset, | |||
| col_fn, | |||
| training_args=None | |||
| ): | |||
| if not self.enabled_fusion: | |||
| raise Exception("You must have a fusion layer to do that!") | |||
| self.model.train_adapter_fusion(self.__fuse_all_adapters) | |||
| self.model.active_head = head_name | |||
| self.__finetune(train_dataset, eval_dataset, col_fn, training_args) | |||
| def evaluate_adapter( | |||
| self, | |||
| adapter_name: str, | |||
| eval_dataset: Dataset, | |||
| col_fn, | |||
| eval_batch_size: int = 32 | |||
| ) -> Dict[str, float]: | |||
| self.model.set_active_adapters(adapter_name) | |||
| training_args = TrainingArguments( | |||
| output_dir='.', | |||
| remove_unused_columns=False, | |||
| label_names=['labels'], | |||
| per_device_eval_batch_size=eval_batch_size | |||
| ) | |||
| trainer = AdapterTrainer( | |||
| model=self.model, | |||
| args=training_args, | |||
| data_collator=col_fn, | |||
| compute_metrics=self.__compute_metrics | |||
| ) | |||
| return trainer.evaluate(eval_dataset) | |||
| def inference_adapter(self, adapter_name: str, input_ids, attention_mask) -> Tensor: | |||
| self.model.eval() | |||
| self.model.set_active_adapters(adapter_name) | |||
| with torch.no_grad(): | |||
| model_output = self.model( | |||
| input_ids=input_ids, | |||
| attention_mask=attention_mask | |||
| ) | |||
| return torch.softmax(model_output.logits, dim=2) | |||
+ 32
- 0
_models/auto_model.py
View File
| @@ -0,0 +1,32 @@ | |||
| from transformers import ( | |||
| T5TokenizerFast, | |||
| BertTokenizerFast, | |||
| BartTokenizerFast, | |||
| T5ForConditionalGeneration, | |||
| BertForSequenceClassification, | |||
| BartForConditionalGeneration, | |||
| BartForSequenceClassification | |||
| ) | |||
| def auto_model(model_name, output_info): | |||
| if 't5' in model_name.lower(): | |||
| model = T5ForConditionalGeneration.from_pretrained(model_name) | |||
| tokenizer = T5TokenizerFast.from_pretrained(model_name, model_max_length=2048) | |||
| model._is_seq2seq = True | |||
| tokenizer._is_seq2seq = True | |||
| elif 'bart' in model_name.lower(): | |||
| model = BartForConditionalGeneration.from_pretrained(model_name) | |||
| tokenizer = BartTokenizerFast.from_pretrained(model_name, model_max_length=1024) | |||
| model._is_seq2seq = True | |||
| tokenizer._is_seq2seq = True | |||
| elif 'bert' in model_name.lower(): | |||
| class_count = len(output_info.names) | |||
| model = BertForSequenceClassification.from_pretrained(model_name, num_labels=class_count) | |||
| tokenizer = BertTokenizerFast.from_pretrained(model_name, trunction=True) | |||
| model._is_seq2seq = False | |||
| tokenizer._is_seq2seq = False | |||
| else: | |||
| raise NotImplementedError() | |||
| return model, tokenizer | |||
+ 61
- 0
_models/opendelta.py
View File
| @@ -0,0 +1,61 @@ | |||
| from os import PathLike | |||
| from pathlib import Path | |||
| from typing import Dict, Union, Optional, Iterable | |||
| import numpy as np | |||
| import torch | |||
| from torch import Tensor | |||
| from torch.utils.data import Dataset | |||
| from sklearn.metrics import classification_report | |||
| from transformers import TrainingArguments, BertForSequenceClassification, EvalPrediction, Trainer | |||
| from opendelta import AdapterModel | |||
| class OpenDeltaModelWrapper: | |||
| def __init__(self, base_model_name: Union[str, PathLike[str]], mask_token_id: int = -100): | |||
| self.model = BertForSequenceClassification.from_pretrained(str(base_model_name)) | |||
| self.mask_token_id = mask_token_id | |||
| def load_adapters(self, adapter_path: str, adapter_names: Iterable[str], with_heads: bool = True) -> None: | |||
| # TODO | |||
| pass | |||
| def add_classification_adapter(self, adapter_name: str, bottleneck_dim: int) -> None: | |||
| # TODO | |||
| self.delta_model = AdapterModel(base_model, bottleneck_dim=48) | |||
| # leave the delta tuning modules and the newly initialized classification head tunable. | |||
| def __compute_metrics(self, pred: EvalPrediction) -> Dict[str, float]: | |||
| true_labels = pred.label_ids.ravel() | |||
| pred_labels = pred.predictions.argmax(-1).ravel() | |||
| report = classification_report(true_labels, pred_labels, output_dict=True) | |||
| return { | |||
| 'accuracy': report['accuracy'], | |||
| 'f1-score-1': report['1']['f1-score'], | |||
| 'f1-score-ma': report['macro avg']['f1-score'] | |||
| } | |||
| def finetune_adapter( | |||
| self, adapter_name: str, | |||
| train_dataset: Dataset, | |||
| eval_dataset: Dataset, | |||
| col_fn, | |||
| training_args=None | |||
| ): | |||
| self.delta_model.freeze_module(exclude=["deltas", "classifier"]) # freeze other adapters and unfreeze selected adapter | |||
| self.__finetune(train_dataset, eval_dataset, col_fn, training_args) | |||
| def evaluate_adapter( | |||
| self, | |||
| adapter_name: str, | |||
| eval_dataset: Dataset, | |||
| col_fn, | |||
| eval_batch_size: int = 32 | |||
| ) -> Dict[str, float]: | |||
| # TODO | |||
| pass | |||
| def inference_adapter(self, adapter_name: str, input_ids, attention_mask) -> Tensor: | |||
| # TODO | |||
| pass | |||
+ 14
- 0
_models/tokenizerman.py
View File
| @@ -0,0 +1,14 @@ | |||
| from transformers import BertTokenizerFast, DataCollatorWithPadding | |||
| class TokenizerMan: | |||
| def __init__(self, tokenizer_kind: str, pretrained_name: str): | |||
| if tokenizer_kind == 'bert': | |||
| self.tokenizer = BertTokenizerFast.from_pretrained(pretrained_name) | |||
| else: | |||
| raise Exception('Not implemented!') | |||
| def get_col_fn(self): | |||
| return DataCollatorWithPadding( | |||
| self.tokenizer, return_tensors='pt', padding='longest' | |||
| ) | |||
+ 3
- 0
_mydelta/__init__.py
View File
| @@ -0,0 +1,3 @@ | |||
| from .auto_freeze import auto_freeze | |||
| from .auto_mutate import auto_mutate | |||
| from .emb_wrapper import EmbeddingWrapper | |||
+ 44
- 0
_mydelta/adapter.py
View File
| @@ -0,0 +1,44 @@ | |||
| import torch | |||
| import torch.nn as nn | |||
| from transformers.models.t5.modeling_t5 import T5LayerFF | |||
| class AdapterLayer(nn.Module): | |||
| def __init__( | |||
| self, | |||
| emb_dim: int, | |||
| bottleneck_size: int | |||
| ): | |||
| super().__init__() | |||
| self.sadcl_adapter = nn.Sequential( | |||
| nn.Linear(emb_dim, bottleneck_size), | |||
| nn.ReLU(), | |||
| nn.Linear(bottleneck_size, emb_dim) | |||
| ) | |||
| def forward(self, x: torch.Tensor): | |||
| return x + self.sharif_llm_adapter(x) | |||
| class FeedForwardAdapterWrapper(nn.Module): | |||
| def __init__( | |||
| self, | |||
| original_module: T5LayerFF, | |||
| bottleneck_size: int | |||
| ): | |||
| super().__init__() | |||
| assert isinstance(original_module, T5LayerFF) | |||
| self.original_module = original_module | |||
| emb_dim = original_module.DenseReluDense.wi.in_features | |||
| self.adapter = AdapterLayer(emb_dim, bottleneck_size) | |||
| def forward(self, x: torch.Tensor): | |||
| output = self.original_module(x) | |||
| output = self.adapter(output) | |||
| return output | |||
+ 91
- 0
_mydelta/attempt.py
View File
| @@ -0,0 +1,91 @@ | |||
| import json | |||
| from pathlib import Path | |||
| from typing import Optional, List | |||
| import numpy as np | |||
| import torch | |||
| import torch.nn as nn | |||
| from .single_prompt import SingleCombPrompt, SingleResidualPrompt, SingleSimplePrompt | |||
| class AttemptAttention(nn.Module): | |||
| def __init__(self, emb_dim, g_bottleneck, temperature): | |||
| super().__init__() | |||
| self.g_network = nn.Sequential( | |||
| nn.Linear(emb_dim, g_bottleneck, bias=False), | |||
| nn.SiLU(), | |||
| nn.Linear(g_bottleneck, emb_dim, bias=False), | |||
| nn.LayerNorm(emb_dim) | |||
| ) | |||
| self.temperature = temperature | |||
| def forward(self, x_hat, p_hats): | |||
| # x_hat.shape == batch_size, emb_dim | |||
| # p_hats.shape == (pretrained_tasks + 1), emb_dim | |||
| batch_size = x_hat.shape[0] | |||
| p_hats_batched = p_hats.repeat(batch_size, 1, 1) | |||
| # p_hats_batched.shape == batch_size, (pretrained_tasks + 1), emb_dim | |||
| h_out = self.g_network(x_hat) | |||
| powers = torch.bmm(p_hats_batched, h_out[:, :, None]) / self.temperature | |||
| # powers.shape == batch_size, (pretrained_tasks + 1), 1 | |||
| attention_weights = torch.softmax(powers[:, :, 0], dim=1) | |||
| # attention_weights.shape == batch_size, (pretrained_tasks + 1) | |||
| return attention_weights | |||
| class Attempt(nn.Module): | |||
| def __init__(self, selected_embs, pretrained, g_bottleneck, kind): | |||
| # selected_embs.shape == n_tokens, emb_dim | |||
| # pretrained.shape == pretrained_tasks, n_tokens, emb_dim | |||
| super().__init__() | |||
| assert selected_embs.shape == pretrained.shape[1:] | |||
| self._constructed_configs = { | |||
| 'kind': kind, | |||
| 'selected_embs.shape': selected_embs.shape, | |||
| 'pretrained.shape': pretrained.shape, | |||
| 'g_bottleneck': g_bottleneck | |||
| } | |||
| self.sadcl_p_target = nn.parameter.Parameter( | |||
| selected_embs.detach().clone() | |||
| ) | |||
| self.pretrained_tasks = nn.parameter.Parameter( | |||
| pretrained.detach().clone() | |||
| ) | |||
| self.sadcl_attention_score = AttemptAttention( | |||
| emb_dim=selected_embs.shape[1], | |||
| g_bottleneck=g_bottleneck, | |||
| temperature=selected_embs.shape[1] * 2.71828 # e number | |||
| ) | |||
| def forward(self, x_inp, prompt_mask): | |||
| # x_inp.shape == batch_size, seq_len, emb_dim | |||
| # prompt_mask.shape == batch_size, seq_len ------- 1 when token is prompt o.w. 0 | |||
| prompt_mask = torch.zeros_like(prompt_mask, dtype=torch.float).masked_fill_(prompt_mask, float('-Inf')) | |||
| x_inp = x_inp + prompt_mask[:, :, None] | |||
| x_hat = x_inp.max(axis=1).values | |||
| # x_hat.shape == batch_size, emb_dim | |||
| all_prompts = torch.cat(( | |||
| self.pretrained_tasks, | |||
| self.sadcl_p_target[None, :, :] | |||
| ),dim=0) | |||
| # all_prompts.shape == (pretrained_tasks + 1), n_tokens, emb_dim | |||
| p_hats = all_prompts.max(axis=1).values | |||
| # p_hats.shape == (pretrained_tasks + 1), emb_dim | |||
| attention_weights = self.sadcl_attention_score(x_hat=x_hat, p_hats=p_hats) | |||
| # attention_weights.shape == batch_size, (pretrained_tasks + 1) | |||
| all_prompts_weighted = all_prompts[None, :, :, :] * attention_weights[:, :, None, None] | |||
| # all_prompts_weighted.shape == batch_size, (pretrained_tasks + 1), n_tokens, emb_dim | |||
| prompts = all_prompts_weighted.sum(axis=1) | |||
| # prompts.shape == batch_size, n_tokens, emb_dim | |||
| return prompts | |||
+ 21
- 0
_mydelta/auto_freeze.py
View File
| @@ -0,0 +1,21 @@ | |||
| from typing import List | |||
| def _is_it_hot(param_name: str, hot_modules: List[str]): | |||
| for module_name in hot_modules: | |||
| if module_name in param_name: # str contains | |||
| return True | |||
| return False | |||
| def auto_freeze(model, hot_modules: List[str]) -> str: | |||
| if hot_modules is None: | |||
| return "No freezing!!!" | |||
| return_value = "Hot params are:" | |||
| for param_name, weights in model.named_parameters(): | |||
| weights.requires_grad = _is_it_hot(param_name, hot_modules) | |||
| if weights.requires_grad: | |||
| return_value += '\n' + param_name | |||
| return return_value | |||
+ 38
- 0
_mydelta/auto_mutate.py
View File
| @@ -0,0 +1,38 @@ | |||
| from .emb_wrapper import EmbeddingWrapper | |||
| from .mutate_forward import mutate_remove_dropout | |||
| def _mutate_comb_prompt(emb_layer, **kwargs): | |||
| return EmbeddingWrapper(emb_layer=emb_layer, **kwargs) | |||
| def auto_mutate(model, tokenizer, peft_params, remove_dropout: bool): | |||
| if model._is_seq2seq: | |||
| delta_module = _mutate_comb_prompt(model.get_encoder().get_input_embeddings(), **peft_params) | |||
| model.get_encoder().set_input_embeddings(delta_module) | |||
| else: | |||
| delta_module = _mutate_comb_prompt(model.get_input_embeddings(), **peft_params) | |||
| model.set_input_embeddings(delta_module) | |||
| # mutate_forward(model, peft_params.get('n_tokens'), just_place_holder=False) | |||
| if remove_dropout: | |||
| mutate_remove_dropout(model) | |||
| model._delta_module = delta_module | |||
| return delta_module | |||
| # temp = MultiCombPrompt( | |||
| # n_tokens=config.peft_params.n_tokens, | |||
| # selected_embs=torch.zeros(128, 768), | |||
| # shared_diff=False | |||
| # ) | |||
| # state_dict = torch.load('/disks/ssd/trained_extensive_test_l2.01_for_real/base_10_128/best.pt') | |||
| # state_dict = {key.replace('comb_prompts.comb_prompts', 'comb_prompts'): val for (key, val) in state_dict.items()} | |||
| # temp.load_state_dict(state_dict) | |||
| # embs = temp() | |||
| # print(embs.shape) | |||
| # for idx, module in enumerate(delta_module.soft_prompts.comb_prompts.comb_prompts): | |||
| # module.sadcl_coeff.data[0] = 1 | |||
| # module.pretrained_embs.data[0] = embs[idx] | |||
+ 111
- 0
_mydelta/emb_wrapper.py
View File
| @@ -0,0 +1,111 @@ | |||
| from pathlib import Path | |||
| from typing import Optional, List | |||
| import torch | |||
| import torch.nn as nn | |||
| import numpy as np | |||
| from .multi_prompt import MultiPrompt | |||
| from .attempt import Attempt | |||
| def _prompts_joiner(prompts, input_embedding): | |||
| batch_size = input_embedding.size(0) | |||
| if len(prompts.shape) == 3: | |||
| prompts_batched = prompts | |||
| else: | |||
| prompts_batched = prompts.repeat(batch_size, 1, 1) # (batch_size, n_tokens, emb_dim) | |||
| n_tokens = prompts_batched.size(1) | |||
| return torch.cat([prompts_batched, input_embedding[:, n_tokens:]], dim=1) | |||
| class EmbeddingWrapper(nn.Module): | |||
| def __init__( | |||
| self, | |||
| emb_layer: nn.Embedding, | |||
| n_tokens: int, | |||
| n_comb_tokens: Optional[int] = None, | |||
| radnom_init: bool = False, | |||
| pretrained_paths: Optional[List[str]] = None, | |||
| pad_token_id: int = 0, # todo! | |||
| **kwargs | |||
| ): | |||
| super().__init__() | |||
| self.emb_layer = emb_layer | |||
| self.kind = kwargs['kind'] | |||
| self.pad_token_id = pad_token_id | |||
| if self.kind == 'combine': | |||
| slected_tokens_size = (n_comb_tokens,) | |||
| elif self.kind in ['residual', 'simple', 'spot', 'attempt']: | |||
| slected_tokens_size = (n_tokens,) | |||
| else: | |||
| raise NotImplementedError() | |||
| selected_embs=self._generate_embs(slected_tokens_size, radnom_init) | |||
| pretrained=self._generate_pretrained(pretrained_paths) | |||
| if self.kind in ['combine', 'residual', 'simple', 'spot']: | |||
| self.soft_prompts = MultiPrompt( | |||
| n_tokens=n_tokens, | |||
| selected_embs=selected_embs, | |||
| pretrained=pretrained, | |||
| **kwargs | |||
| ) | |||
| elif self.kind == 'attempt': | |||
| self.soft_prompts = Attempt( | |||
| selected_embs=selected_embs, | |||
| pretrained=pretrained, | |||
| **kwargs | |||
| ) | |||
| else: | |||
| raise NotImplementedError() | |||
| def _generate_pretrained(self, pretrained_paths): | |||
| if pretrained_paths is None or len(pretrained_paths) == 0: | |||
| return None | |||
| pretrained = torch.stack([ | |||
| MultiPrompt.get_saved_final_emb( | |||
| config_path=Path(path) / 'config.json', | |||
| weights_path=Path(path) / 'best.pt' | |||
| ) for path in pretrained_paths | |||
| ], dim=0) | |||
| return pretrained | |||
| def _generate_embs(self, size, radnom_init): | |||
| if radnom_init: | |||
| size = size + (self.emb_layer.embedding_dim,) | |||
| mean = self.emb_layer.weight.ravel().detach().numpy().mean() | |||
| std_dev = self.emb_layer.weight.ravel().detach().numpy().std() | |||
| return torch.FloatTensor(*size).normal_(mean=mean, std=std_dev) | |||
| # return torch.FloatTensor(*size).uniform_(-1, 1) | |||
| else: | |||
| slected_tokens = torch.from_numpy( | |||
| np.random.choice( | |||
| self.emb_layer.num_embeddings, | |||
| size=size, | |||
| replace=False | |||
| ) | |||
| ) | |||
| return self.emb_layer(slected_tokens) | |||
| def forward(self, tokens): | |||
| input_embedding = self.emb_layer(tokens) | |||
| if self.kind == 'attempt': | |||
| prompts = self.soft_prompts( | |||
| x_inp=input_embedding, | |||
| prompt_mask=(tokens == self.pad_token_id) | |||
| ) | |||
| else: | |||
| prompts = self.soft_prompts() | |||
| return _prompts_joiner(prompts, input_embedding) | |||
| def peft_state_dict(self): | |||
| return self.soft_prompts.state_dict() | |||
| def peft_config(self): | |||
| return self.soft_prompts._constructed_configs | |||
| def load_peft(self, config, state_dict): | |||
| self.soft_prompts = MultiPrompt.from_config(config) | |||
| self.soft_prompts.load_state_dict(state_dict) | |||
+ 15
- 0
_mydelta/gumbal_switch.py
View File
| @@ -0,0 +1,15 @@ | |||
| import torch | |||
| import torch.nn as nn | |||
| class GumbalSwitch(nn.Module): | |||
| def __init__(self, switch_count): | |||
| super().__init__() | |||
| self.switch_weight = nn.parameter.Parameter(torch.ones((switch_count, 2))) | |||
| def forward(self): | |||
| if self.training: | |||
| return_value = nn.functional.gumbel_softmax(self.switch_weight, hard=True, dim=-1) | |||
| else: | |||
| argmax = torch.argmax(self.switch_weight, dim=-1) | |||
| return_value = nn.functional.one_hot(argmax, num_classes=2).float() | |||
| return return_value[:, 0] | |||
+ 92
- 0
_mydelta/multi_prompt.py
View File
| @@ -0,0 +1,92 @@ | |||
| import json | |||
| from pathlib import Path | |||
| from typing import Optional, List | |||
| import numpy as np | |||
| import torch | |||
| import torch.nn as nn | |||
| from _trainer.loss_hooks import add_to_loss_hooks | |||
| from .single_prompt import SingleCombPrompt, SingleResidualPrompt, SingleSimplePrompt, SingleSuperSimplePrompt | |||
| class MultiPrompt(nn.Module): | |||
| def __init__(self, n_tokens, selected_embs, kind: str, shared_weights: bool = False, pretrained: Optional[torch.Tensor] = None, **kwargs): | |||
| ####### Kind in [simple, super_simple, residual] | |||
| # selected_embs.shape == n_tokens, emb_dim | |||
| # pretrained.shape == 1, n_tokens, emb_dim | |||
| ####### Kind == combine | |||
| # selected_embs.shape == super_pos_m, emb_dim for combine | |||
| # pretrained.shape == pretrained_task_count, n_tokens, emb_dim | |||
| super().__init__() | |||
| self._constructed_configs = { | |||
| 'n_tokens': n_tokens, | |||
| 'selected_embs.shape': selected_embs.shape, | |||
| 'kind': kind, | |||
| 'shared_weights': shared_weights, | |||
| **kwargs | |||
| } | |||
| self.n_tokens = n_tokens | |||
| self.emb_dim = selected_embs.size(1) | |||
| prompt_constructor = { | |||
| 'simple': lambda idx, selected_embs: SingleSimplePrompt(selected_embs[idx], **kwargs), | |||
| 'spot': lambda idx, selected_embs: SingleSuperSimplePrompt(selected_embs[idx], **kwargs), | |||
| 'residual': lambda idx, selected_embs: SingleResidualPrompt(selected_embs[idx], **kwargs), | |||
| 'combine': lambda ـ, selected_embs: SingleCombPrompt(selected_embs, **kwargs), | |||
| }[kind] | |||
| self.prompts = nn.ModuleList([ | |||
| prompt_constructor(idx, selected_embs) for idx in range(n_tokens) | |||
| ]) | |||
| if shared_weights: | |||
| if kind == 'combine': | |||
| for module in self.prompts: | |||
| module.sadcl_embs_diff = self.prompts[0].sadcl_embs_diff | |||
| elif kind == 'residual': | |||
| for module in self.prompts: | |||
| module.sadcl_mlp = self.prompts[0].sadcl_mlp | |||
| else: | |||
| raise NotImplementedError() | |||
| if pretrained is not None: | |||
| self._constructed_configs['pretrained.shape'] = pretrained.shape | |||
| assert pretrained.shape[1:] == (self.n_tokens, self.emb_dim) | |||
| for idx, module in enumerate(self.prompts): | |||
| self.prompts[idx].use_pretrained_tokens(pretrained[:, idx, :]) | |||
| if kind == 'combine': | |||
| for prompt in self.prompts[1:]: | |||
| prompt.sadcl_coeff_pretrained = self.prompts[0].sadcl_coeff_pretrained | |||
| # l1 loss | |||
| # add_to_loss_hooks(self.prompts[0].loss_hook_coeff_pretrained) | |||
| @classmethod | |||
| def from_config(cls, config): | |||
| selected_embs = torch.zeros(*config.pop('selected_embs.shape')) | |||
| pretrained = None | |||
| if 'pretrained.shape' in config: | |||
| pretrained = torch.zeros(*config.pop('pretrained.shape')) | |||
| return cls(selected_embs=selected_embs, pretrained=pretrained, **config) | |||
| @classmethod | |||
| def get_saved_final_emb(cls, config_path, weights_path): | |||
| with open(config_path, 'r') as f: | |||
| config = json.load(f) | |||
| temp_multi_prompt = cls.from_config(config['peft_config']) | |||
| temp_multi_prompt.load_state_dict(torch.load(weights_path, map_location='cpu')) | |||
| with torch.no_grad(): | |||
| embs = temp_multi_prompt().detach() | |||
| # embs.shape == n_tokens, emb_dim | |||
| return embs | |||
| def forward(self): | |||
| out = torch.stack([ | |||
| prompt() for prompt in self.prompts | |||
| ], dim=0) | |||
| assert out.shape == (self.n_tokens, self.emb_dim) | |||
| return out | |||
+ 7
- 0
_mydelta/mutate_forward.py
View File
| @@ -0,0 +1,7 @@ | |||
| import torch | |||
| def mutate_remove_dropout(model): | |||
| for module in model.modules(): | |||
| if isinstance(module, torch.nn.Dropout): | |||
| module._backup_p = module.p | |||
| module.p = 0 | |||
+ 134
- 0
_mydelta/single_prompt.py
View File
| @@ -0,0 +1,134 @@ | |||
| import torch | |||
| import torch.nn as nn | |||
| from .gumbal_switch import GumbalSwitch | |||
| class SingleSuperSimplePrompt(nn.Module): | |||
| def __init__(self, pretrained_emb): | |||
| super().__init__() | |||
| self.sadcl_prompt = nn.parameter.Parameter( | |||
| pretrained_emb.detach().clone() | |||
| ) | |||
| def forward(self): | |||
| return self.sadcl_prompt | |||
| def use_pretrained_tokens(self, new_tokens): | |||
| assert new_tokens.shape[0] == 1 | |||
| assert new_tokens.shape[1] == self.sadcl_prompt.data.shape[0] | |||
| self.sadcl_prompt.data = new_tokens[0].detach().clone() | |||
| class SingleSimplePrompt(nn.Module): | |||
| def __init__(self, pretrained_emb): | |||
| super().__init__() | |||
| self.pretrained_emb = nn.parameter.Parameter( | |||
| pretrained_emb.detach().clone() | |||
| ) | |||
| self.sadcl_emb_diff = nn.parameter.Parameter( | |||
| torch.zeros_like(pretrained_emb) | |||
| ) | |||
| def forward(self): | |||
| return self.pretrained_emb + self.sadcl_emb_diff | |||
| class SingleResidualPrompt(nn.Module): | |||
| def __init__(self, pretrained_emb, mlp_size): | |||
| super().__init__() | |||
| self.pretrained_emb = nn.parameter.Parameter( | |||
| pretrained_emb.detach().clone() | |||
| ) | |||
| self.sadcl_emb_diff = nn.parameter.Parameter( | |||
| torch.zeros_like(pretrained_emb) | |||
| ) | |||
| self.sadcl_mlp = nn.Sequential( | |||
| nn.Linear(pretrained_emb.size(0), mlp_size), | |||
| nn.ReLU(), | |||
| nn.Linear(mlp_size, pretrained_emb.size(0)), | |||
| nn.LayerNorm(pretrained_emb.size(0)) | |||
| ) | |||
| def forward(self): | |||
| input_prompt = self.pretrained_emb + self.sadcl_emb_diff | |||
| return input_prompt + self.sadcl_mlp(input_prompt) | |||
| class SingleCombPrompt(nn.Module): | |||
| def __init__(self, pretrained_embs, softmax=False, use_pretrained_mode='simple', tempreture=1.0): | |||
| super().__init__() | |||
| self.sadcl_coeff = nn.parameter.Parameter( | |||
| torch.FloatTensor(pretrained_embs.size(0)).uniform_(-0.5, 0.5) # maybe another init | |||
| ) | |||
| self.pretrained_embs = nn.parameter.Parameter( | |||
| pretrained_embs.detach().clone() | |||
| ) | |||
| self.sadcl_embs_diff = nn.parameter.Parameter( | |||
| torch.zeros_like(pretrained_embs) | |||
| ) | |||
| self.use_pretrained = False | |||
| self.softmax = softmax | |||
| assert use_pretrained_mode in ['simple', 'gumbal', 'softmax'] | |||
| self.use_pretrained_mode = use_pretrained_mode | |||
| self.tempreture = tempreture | |||
| def use_pretrained_tokens(self, new_tokens): | |||
| assert new_tokens.shape[1] == self.pretrained_embs.data.shape[1] | |||
| self.use_pretrained = True | |||
| self.pretrained_tokens = nn.parameter.Parameter( | |||
| new_tokens.detach().clone() | |||
| ) | |||
| if self.use_pretrained_mode == 'simple': | |||
| self.sadcl_coeff_pretrained = nn.parameter.Parameter( | |||
| torch.full(size=(new_tokens.size(0),), fill_value=0.5) | |||
| ) | |||
| elif self.use_pretrained_mode == 'gumbal': | |||
| self.sadcl_coeff_pretrained = GumbalSwitch(new_tokens.shape[0]) | |||
| elif self.use_pretrained_mode == 'softmax': | |||
| self.sadcl_coeff_pretrained = nn.parameter.Parameter( | |||
| torch.full(size=(new_tokens.size(0),), fill_value=1.) | |||
| ) | |||
| def get_pretrained_coeff(self): | |||
| assert self.use_pretrained | |||
| if self.use_pretrained_mode == 'simple': | |||
| return self.sadcl_coeff_pretrained | |||
| elif self.use_pretrained_mode == 'gumbal': | |||
| return self.sadcl_coeff_pretrained() | |||
| elif self.use_pretrained_mode == 'softmax': | |||
| return torch.softmax(self.sadcl_coeff_pretrained / self.tempreture, dim=0) | |||
| def forward(self): | |||
| coeff = self.sadcl_coeff | |||
| mat = (self.pretrained_embs + self.sadcl_embs_diff) | |||
| if self.use_pretrained: | |||
| coeff = torch.cat( | |||
| ( | |||
| coeff, | |||
| self.get_pretrained_coeff() | |||
| ), dim=0 | |||
| ) | |||
| mat = torch.cat( | |||
| (mat, self.pretrained_tokens), dim=0 | |||
| ) | |||
| if self.softmax: | |||
| assert (not self.use_pretrained), 'This feature is not compatible with use_pretrained' | |||
| coeff = torch.nn.functional.softmax(coeff, dim=0) | |||
| return coeff @ mat | |||
+ 1
- 0
_trainer/__init__.py
View File
| @@ -0,0 +1 @@ | |||
| from .auto_train import auto_train | |||
+ 43
- 0
_trainer/auto_save.py
View File
| @@ -0,0 +1,43 @@ | |||
| import torch | |||
| import json | |||
| from pathlib import Path | |||
| CONFIG_FILE_NAME = 'config.json' | |||
| class AutoSave: | |||
| def __init__(self, model, path): | |||
| self.path = Path(path) | |||
| self.path.mkdir(exist_ok=True, parents=True) | |||
| self.model_name = model.name_or_path | |||
| if hasattr(model, '_delta_module'): | |||
| self.delta_module = model._delta_module | |||
| else: | |||
| self.model = model | |||
| self._save_config() | |||
| def _save_config(self): | |||
| config = { | |||
| 'model_name': self.model_name, | |||
| } | |||
| if self.has_delta: | |||
| config['peft_config'] = self.delta_module.peft_config() | |||
| with open(self.path / CONFIG_FILE_NAME, 'w') as f: | |||
| json.dump(config, f) | |||
| @property | |||
| def has_delta(self): | |||
| return hasattr(self, 'delta_module') | |||
| def save(self, name): | |||
| if self.has_delta: | |||
| state_dict = self.delta_module.peft_state_dict() | |||
| else: | |||
| state_dict = self.model.state_dict() | |||
| torch.save(state_dict, self.path / f'{name}.pt') | |||
| def load(self, name): | |||
| with open(self.path / CONFIG_FILE_NAME, 'r') as f: | |||
| config = json.load(f) | |||
| state_dict = torch.load(self.path / f'{name}.pt') | |||
| self.delta_module.load_peft(config=config['peft_config'], state_dict=state_dict) | |||
+ 125
- 0
_trainer/auto_train.py
View File
| @@ -0,0 +1,125 @@ | |||
| from pathlib import Path | |||
| import torch | |||
| import wandb | |||
| from accelerate import Accelerator | |||
| from tqdm import tqdm | |||
| from .auto_save import AutoSave | |||
| from .run_loops import train_loop, valid_loop | |||
| from .best_finder import BestFinder | |||
| from _datasets import generate_dataloader, generate_output_preprocess | |||
| from _mydelta import auto_freeze | |||
| def _extract_name(model_name, candidates): | |||
| for candid in candidates: | |||
| if candid in model_name: | |||
| return candid | |||
| return 'none' | |||
| def get_project_name(config, model_name, dataset_name): | |||
| name_stack = [] | |||
| model_name = model_name.lower() | |||
| if config.project_name_prefix is not None: | |||
| name_stack.append(config.project_name_prefix) | |||
| name_stack.append(_extract_name(model_name, ['t5', 'bert', 'bart'])) | |||
| name_stack.append(_extract_name(model_name, ['small', 'base', 'large'])) | |||
| name_stack.append(dataset_name) | |||
| return '_'.join(name_stack) | |||
| def get_experiment_name(config): | |||
| if config.peft_params is None: | |||
| return 'full' | |||
| name_stack = [config.peft_params.n_tokens, config.peft_params.kind] | |||
| if config.peft_params.kind == 'combine': | |||
| name_stack.append(config.peft_params.n_comb_tokens) | |||
| if len(config.peft_params.get('pretrained_paths', [])) > 0: | |||
| name_stack.append(config.peft_params.use_pretrained_mode) | |||
| if config.peft_params.use_pretrained_mode == 'softmax': | |||
| name_stack.append(config.peft_params.tempreture) | |||
| elif config.peft_params.kind == 'residual': | |||
| name_stack.append(config.peft_params.mlp_size) | |||
| if config.experiment_name_suffix is not None: | |||
| name_stack.append(config.experiment_name_suffix) | |||
| return '_'.join([str(x) for x in name_stack]) | |||
| def auto_train(model, tokenizer, dataset, config, device): | |||
| best_finder = BestFinder(config.best_finder.higher_better) | |||
| project_name = get_project_name(config=config, model_name=model.name_or_path, dataset_name=dataset['name']) | |||
| experiment_name = get_experiment_name(config) | |||
| save_path = Path(config.base_save_path) / project_name / experiment_name | |||
| saver = AutoSave( | |||
| model=model, | |||
| path=Path(config.base_save_path) / project_name / experiment_name | |||
| ) | |||
| train_loader, valid_loader_dict = generate_dataloader( | |||
| tokenizer, | |||
| dataset['train'], | |||
| dataset['valid_dict'], | |||
| train_bs=config.train_batch_size, | |||
| valid_bs=config.valid_batch_size | |||
| ) | |||
| output_preprocess = generate_output_preprocess(tokenizer) | |||
| freeze_notes = auto_freeze(model, config.hot_modules) | |||
| optimizer = torch.optim.AdamW(model.parameters(), lr=config.learning_rate, weight_decay=config.weight_decay) | |||
| accelerator = Accelerator(log_with="wandb") # gradient_accumulation_steps=8 | |||
| model, optimizer, train_loader = accelerator.prepare( | |||
| model, optimizer, train_loader | |||
| ) | |||
| accelerator.init_trackers( | |||
| project_name=project_name, | |||
| config=config.to_dict(), | |||
| init_kwargs={"wandb": {"name": experiment_name, "notes": freeze_notes}} | |||
| ) | |||
| saver.save('first') | |||
| epochs_range = range(config.num_epochs) | |||
| if config.use_tqdm: | |||
| epochs_range = tqdm(epochs_range, position=2, desc="EPOCHS", leave=False) | |||
| for epoch in epochs_range: | |||
| epoch_results = {} | |||
| epoch_results.update( | |||
| train_loop( | |||
| model=model, | |||
| loader=train_loader, | |||
| optimizer=optimizer, | |||
| accelerator=accelerator, | |||
| use_tqdm=config.use_tqdm | |||
| ) | |||
| ) | |||
| epoch_results.update( | |||
| valid_loop( | |||
| model=model, | |||
| loader_dict=valid_loader_dict, | |||
| use_tqdm=config.use_tqdm, | |||
| compute_metrics=dataset['compute_metrics'], | |||
| output_preprocess=output_preprocess | |||
| ) | |||
| ) | |||
| accelerator.log(epoch_results) | |||
| if best_finder.is_better(epoch_results[config.best_finder.metric]): | |||
| saver.save('best') | |||
| saver.save('last') | |||
| accelerator.end_training() | |||
| return str(save_path) | |||
+ 19
- 0
_trainer/best_finder.py
View File
| @@ -0,0 +1,19 @@ | |||
| class BestFinder: | |||
| def __init__(self, higher_better=True): | |||
| self.best_value = None | |||
| self.higher_better = higher_better | |||
| def _compare(self, new_value): | |||
| if self.best_value is None: | |||
| return True | |||
| if self.higher_better: | |||
| return new_value > self.best_value | |||
| else: | |||
| return new_value < self.best_value | |||
| def is_better(self, new_value): | |||
| compare_reuslt = self._compare(new_value) | |||
| if compare_reuslt: | |||
| self.best_value = new_value | |||
| return compare_reuslt | |||
+ 8
- 0
_trainer/loss_hooks.py
View File
| @@ -0,0 +1,8 @@ | |||
| loss_hooks = [] | |||
| def add_to_loss_hooks(fn): | |||
| loss_hooks.append(fn) | |||
| def get_hooks(): | |||
| return loss_hooks | |||
+ 78
- 0
_trainer/run_loops.py
View File
| @@ -0,0 +1,78 @@ | |||
| import numpy as np | |||
| import torch | |||
| from tqdm import tqdm | |||
| from _utils import prefix_dict_keys | |||
| from .loss_hooks import get_hooks | |||
| def train_loop(model, loader, optimizer, accelerator, use_tqdm=False, loss_hook_alpha=0.001, gradient_clipping=1.0): | |||
| model.train() | |||
| batch_losses = [] | |||
| if use_tqdm: | |||
| loader = tqdm(loader, position=3, desc="Train Loop", leave=False) | |||
| for row in loader: | |||
| optimizer.zero_grad() | |||
| out = model(**row.to(model.device)) | |||
| loss = out.loss | |||
| for loss_hook in get_hooks(): | |||
| loss += loss_hook_alpha * loss_hook() | |||
| batch_loss_value = loss.item() | |||
| accelerator.backward(loss) | |||
| if accelerator.sync_gradients: | |||
| accelerator.clip_grad_norm_(model.parameters(), 1.0) | |||
| optimizer.step() | |||
| batch_losses.append(batch_loss_value) | |||
| loss_value = np.mean(batch_losses) | |||
| return prefix_dict_keys('train', { | |||
| 'loss': loss_value | |||
| }) | |||
| def _predict(model, row): | |||
| if model._is_seq2seq: | |||
| return model.generate( | |||
| **row, | |||
| max_length=50 | |||
| ) | |||
| else: | |||
| return model( | |||
| **row | |||
| ).logits.argmax(-1) | |||
| def valid_loop(model, loader_dict, compute_metrics, output_preprocess, use_tqdm=False): | |||
| model.eval() | |||
| return_value = {} | |||
| all_means = [] | |||
| for key, loader in loader_dict.items(): | |||
| all_true = [] | |||
| all_pred = [] | |||
| if use_tqdm: | |||
| loader = tqdm(loader, position=3, desc="Valid Loop", leave=False) | |||
| with torch.no_grad(): | |||
| for row in loader: | |||
| row.to(model.device) | |||
| pred = _predict(model, row) | |||
| all_true += row.labels.detach().cpu().tolist() | |||
| all_pred += pred.detach().cpu().tolist() | |||
| all_true = output_preprocess(all_true) | |||
| all_pred = output_preprocess(all_pred) | |||
| metrics = compute_metrics(y_true=all_true, y_pred=all_pred) | |||
| all_means.append(metrics['mean']) | |||
| return_value.update(prefix_dict_keys(key, metrics)) | |||
| return_value['valid_mean'] = np.mean(all_means) | |||
| return return_value | |||
+ 59
- 0
_utils.py
View File
| @@ -0,0 +1,59 @@ | |||
| def prefix_dict_keys(prefix, input_dict): | |||
| return {f'{prefix}_{key}': val for key, val in input_dict.items()} | |||
| def print_system_info(): | |||
| from platform import python_version | |||
| print(f"Python version is: {python_version()}") | |||
| try: | |||
| import sklearn | |||
| print(f"Scikit-learn version is: {sklearn.__version__}") | |||
| except: | |||
| print("Scikit-learn not found!!!") | |||
| try: | |||
| import torch | |||
| print(f"Torch version is: {torch.__version__}") | |||
| if torch.cuda.is_available() and torch.cuda.device_count() >= 0: | |||
| print(f"Nvidia device is: {torch.cuda.get_device_name(0)}") | |||
| else: | |||
| print("Torch is using CPU") | |||
| except: | |||
| print("Torch not found!!!") | |||
| return | |||
| try: | |||
| import transformers | |||
| print(f"Transformers version is: {transformers.__version__}") | |||
| try: | |||
| print(f"Adapterhub version is: {transformers.adapters.__version__}") | |||
| except: | |||
| print("Adapterhub not found!!!") | |||
| except: | |||
| print("Transformers not found!!!") | |||
| def silent_logs(): | |||
| import os | |||
| os.environ["WANDB_SILENT"] = "true" | |||
| # os.environ["TRANSFORMERS_VERBOSITY"] = "fatal" | |||
| os.environ["TRANSFORMERS_NO_ADVISORY_WARNINGS"] = "1" | |||
| os.environ["ACCELERATE_LOG_LEVEL"] = "CRITICAL" | |||
| import transformers | |||
| from transformers.utils import logging | |||
| logging.set_verbosity(transformers.logging.FATAL) | |||
| from datasets.utils.logging import disable_progress_bar, set_verbosity_error | |||
| disable_progress_bar() | |||
| set_verbosity_error() | |||
| import accelerate.utils.other as accelerate_other | |||
| accelerate_other.logger.setLevel(50) | |||
| def sp_encode(data): | |||
| import json | |||
| import base64 | |||
| return base64.b32encode(json.dumps(data).encode()) | |||
| def sp_decode(encoded_data): | |||
| import json | |||
| import base64 | |||
| return json.loads(base64.b32decode(encoded_data).decode()) | |||
+ 0
- 0
requirements.txt
View File
Some files were not shown because too many files changed in this diff
Loading…