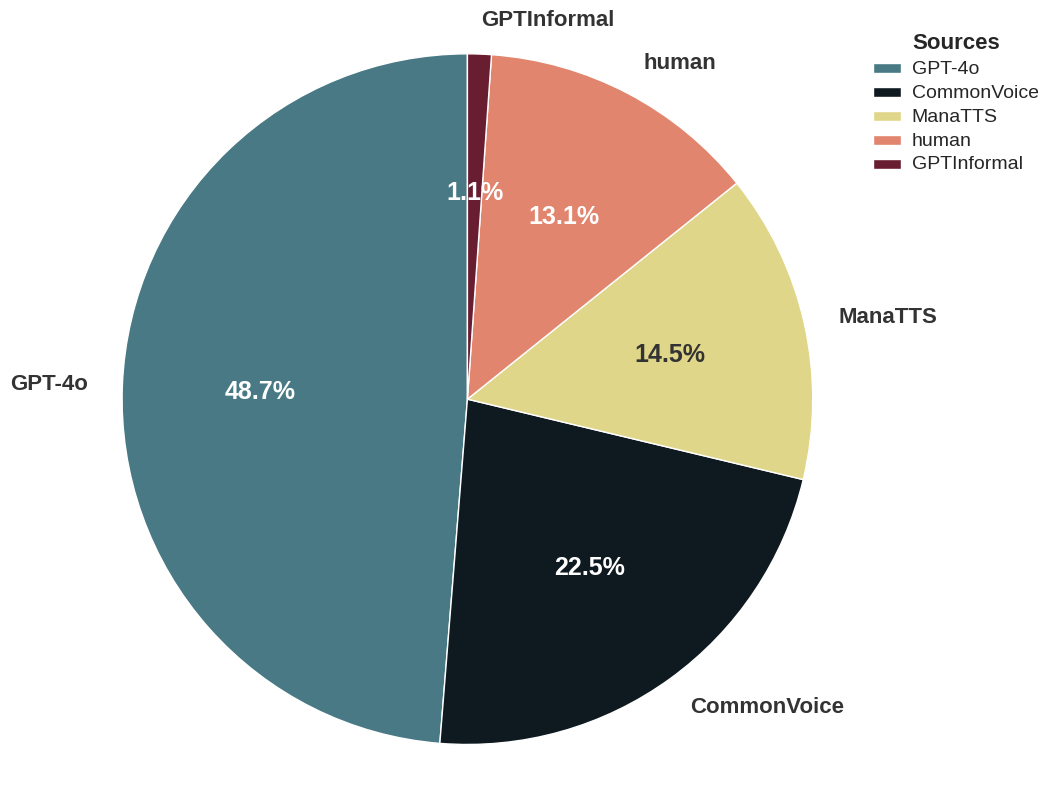
Distribution of data sources in HomoRich dataset |

The source for different parts of the HomoRich dataset |
|
Distribution of data sources in HomoRich dataset |
The source for different parts of the HomoRich dataset |
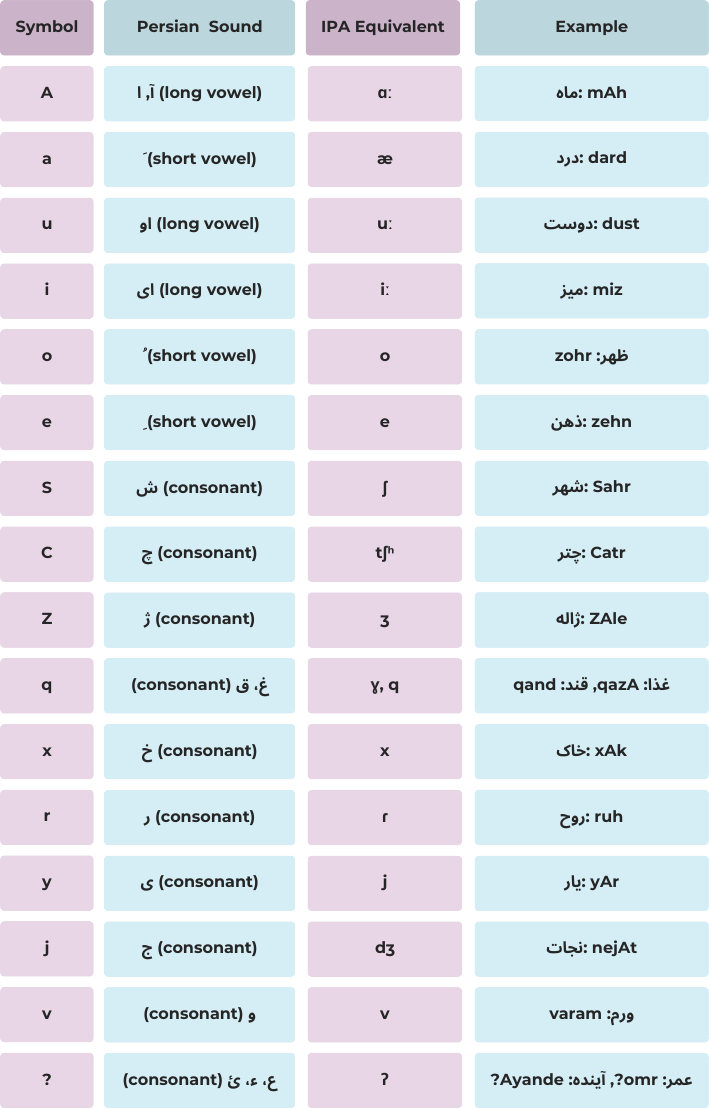
Repr. 1 |
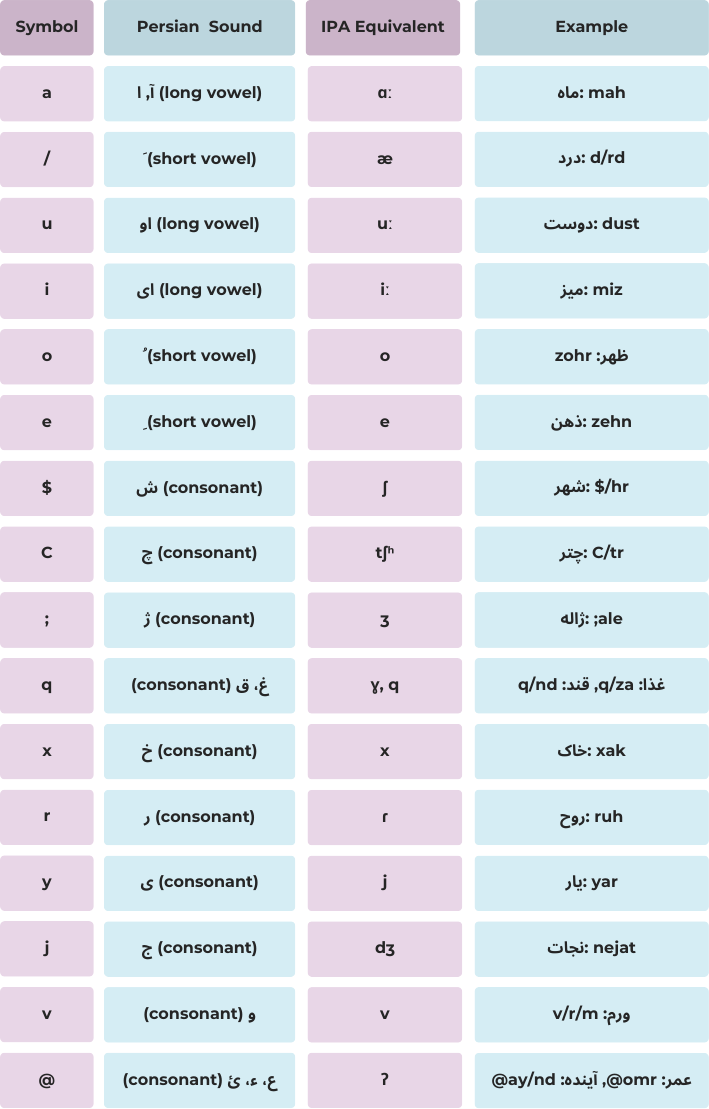
Repr. 2 |