
Browse Source
[1.29.15] Fix compiler warning, conversion from string constant to 'char *'.
espeakedit: Change compile_report file to include the phoneme name as well as phoneme table which uses each data file. git-svn-id: https://espeak.svn.sourceforge.net/svnroot/espeak/trunk@95 d46cf337-b52f-0410-862d-fd96e6ae7743master
30 changed files with 2125 additions and 842 deletions
+ 27
- 13
dictsource/dict_phonemes
View File
| @@ -68,26 +68,22 @@ Dictionary en_dict | |||
| 0 3 3: @ @- @2 @5 @L | |||
| a a2 A: A@ aa aI aI@ aU | |||
| aU@ E e@ eI I i I2 i: | |||
| i@ IR O O: o: O@ o@ OI | |||
| oU O~ U u: U@ V VR | |||
| aU@ E e@ eI I I2 i: i@ | |||
| IR O O: o: O@ o@ OI oU | |||
| O~ U u: U@ V VR | |||
| : ; b C d D dZ f | |||
| g g- h j k l L m | |||
| n N p Q r r- s S | |||
| t T t2 tS v w x z | |||
| Z | |||
| g h j k l m n N | |||
| p Q r r- s S t T | |||
| t2 tS v w x z Z | |||
| Dictionary eo_dict | |||
| @- a aI aU e eI eU i | |||
| o OI u uI | |||
| @- a aI aU e i o u | |||
| * b d dZ f g h j | |||
| k l m n p r R s | |||
| S t T tS ts v w x | |||
| z Z | |||
| * b d k l m n p | |||
| r R s t ts v z Z | |||
| Dictionary es_dict | |||
| @@ -346,3 +342,21 @@ I o r- u | |||
| k k^ l l^ m n n^ p | |||
| r R s S t tS ts v | |||
| x z Z | |||
| Dictionary zh_dict | |||
| Dictionary zhh_dict | |||
| &? 0 0? @ @? @r @u A | |||
| A? E E~ i i&? i. i0 i; | |||
| i? i@ i@? i[ iA iA? iE iE~ | |||
| io io? iu i~ o u u&? u? | |||
| u@ u@? uA uA? uE uE~ ui u~ | |||
| y y? y@ y@? ya y~ | |||
| c; f h k kh l m n | |||
| N p ph s s. t tc; tc; | |||
| th ts ts. ts. tsh v z. | |||
+ 5
- 2
dictsource/sv_list
View File
| @@ -16,10 +16,10 @@ d de: | |||
| e e: | |||
| f Ef | |||
| g ge: | |||
| h hO: | |||
| h ho: | |||
| i i: | |||
| j ji: | |||
| k kO: | |||
| k ko: | |||
| l El | |||
| m Em | |||
| n En | |||
| @@ -77,6 +77,9 @@ _0M3 bIlj'u:nER | |||
| _1M3 bIlj'u:n | |||
| _dpt p'8Nkt | |||
| (1 : a) f'Ws.ta | |||
| // abbreviations | |||
| //************** | |||
+ 1743
- 598
phsource/compile_report
File diff suppressed because it is too large
View File
+ 31
- 0
phsource/ph_greek_ancient
View File
| @@ -3,12 +3,43 @@ | |||
| // Ancient Greek - based on base2 | |||
| //==================================================== | |||
| phoneme : // Lengthen previous vowel by "length" | |||
| virtual | |||
| length 100 | |||
| endphoneme | |||
| phoneme y | |||
| vowel starttype (i) endtype (i) | |||
| length 160 | |||
| formants vowel/yy_4 | |||
| endphoneme | |||
| phoneme e | |||
| vowel starttype (e) endtype (e) | |||
| length 140 | |||
| formants vowel/e | |||
| endphoneme | |||
| phoneme E | |||
| vowel starttype (e) endtype (e) | |||
| length 150 | |||
| formants vowel/ee_1 | |||
| endphoneme | |||
| phoneme o | |||
| vowel starttype (o) endtype (o) | |||
| length 140 | |||
| formants vowel/o | |||
| endphoneme | |||
| phoneme O | |||
| vowel starttype (o) endtype (o) | |||
| length 150 | |||
| formants vowel/0 | |||
| endphoneme | |||
| phoneme EU | |||
| vowel starttype (e) endtype (u) | |||
| length 230 | |||
+ 7
- 0
phsource/phonemes
View File
| @@ -1236,6 +1236,13 @@ include ph_vi | |||
| phonemetable zhy base | |||
| include ph_zh_yue | |||
| phonemetable zh base | |||
| include ph_zh | |||
| phonemetable zhh zh | |||
| include ph_zh_huai | |||
| phonemetable sw base | |||
| include ph_swahili | |||
BIN
phsource/vdiph/vowelchart.png
View File
{kind=link}

BIN
phsource/vdiph2/vowelchart.png
View File
{kind=link}
BIN
phsource/vowel/vowelchart.png
View File
{kind=link}
+ 104
- 100
src/compiledata.cpp
View File
| @@ -80,13 +80,11 @@ extern int CompileDictionary(const char *dsource, const char *dict_name, FILE *l | |||
| static int markers_used[8]; | |||
| #define N_USED_BY 12 | |||
| typedef struct { | |||
| void *link; | |||
| int value; | |||
| short n_uses; | |||
| short n_used_by; | |||
| unsigned char used_by[N_USED_BY]; | |||
| int ph_mnemonic; | |||
| short ph_table; | |||
| char string[1]; | |||
| } REF_HASH_TAB; | |||
| @@ -906,12 +904,17 @@ int Compile::LoadDataFile(const char *path, int control) | |||
| FILE *f; | |||
| int id; | |||
| int ix; | |||
| int hash; | |||
| int addr = 0; | |||
| int type_code=' '; | |||
| REF_HASH_TAB *p, *p2; | |||
| char buf[sizeof(path_source)+120]; | |||
| if(strcmp(path,"NULL")==0) | |||
| return(0); | |||
| if(strcmp(path,"DFT")==0) | |||
| return(1); | |||
| count_references++; | |||
| hash = Hash8(path); | |||
| @@ -920,102 +923,80 @@ int Compile::LoadDataFile(const char *path, int control) | |||
| { | |||
| if(strcmp(path,p->string)==0) | |||
| { | |||
| int found = 0; | |||
| duplicate_references++; | |||
| p->n_uses++; | |||
| // add the current phoneme table to a list of users of this data file, if not already listed | |||
| for(ix=0; (ix < p->n_used_by) && (ix < N_USED_BY); ix++) | |||
| { | |||
| if(p->used_by[ix] == n_phoneme_tabs) | |||
| { | |||
| found = 1; | |||
| break; | |||
| } | |||
| } | |||
| if(found == 0) | |||
| { | |||
| if(ix < N_USED_BY) | |||
| { | |||
| p->used_by[ix] = n_phoneme_tabs; | |||
| } | |||
| p->n_used_by++; | |||
| } | |||
| return(p->value); // already loaded this data | |||
| addr = p->value; // already loaded this data | |||
| break; | |||
| } | |||
| p = (REF_HASH_TAB *)p->link; | |||
| } | |||
| sprintf(buf,"%s%s",path_source,path); | |||
| if(strcmp(path,"NULL")==0) | |||
| return(0); | |||
| if(strcmp(path,"DFT")==0) | |||
| return(1); | |||
| if((f = fopen(buf,"rb")) == NULL) | |||
| if(addr == 0) | |||
| { | |||
| sprintf(buf,"%s%s.wav",path_source,path); | |||
| sprintf(buf,"%s%s",path_source,path); | |||
| if((f = fopen(buf,"rb")) == NULL) | |||
| { | |||
| Error("Can't read file",path); | |||
| return(0); | |||
| sprintf(buf,"%s%s.wav",path_source,path); | |||
| if((f = fopen(buf,"rb")) == NULL) | |||
| { | |||
| Error("Can't read file",path); | |||
| return(0); | |||
| } | |||
| } | |||
| } | |||
| id = Read4Bytes(f); | |||
| // fread(&id,1,4,f); | |||
| rewind(f); | |||
| if(id == 0x43455053) | |||
| { | |||
| ix = LoadSpect(path, control); | |||
| type_code = 'S'; | |||
| } | |||
| else | |||
| if(id == 0x46464952) | |||
| { | |||
| ix = LoadWavefile(f,path); | |||
| type_code = 'W'; | |||
| } | |||
| else | |||
| if(id == 0x43544950) | |||
| { | |||
| ix = LoadEnvelope(f,path); | |||
| type_code = 'E'; | |||
| } | |||
| else | |||
| if(id == 0x45564E45) | |||
| { | |||
| ix = LoadEnvelope2(f,path); | |||
| type_code = 'E'; | |||
| } | |||
| else | |||
| { | |||
| Error("File not SPEC or RIFF",path); | |||
| ix = -1; | |||
| id = Read4Bytes(f); | |||
| rewind(f); | |||
| if(id == 0x43455053) | |||
| { | |||
| addr = LoadSpect(path, control); | |||
| type_code = 'S'; | |||
| } | |||
| else | |||
| if(id == 0x46464952) | |||
| { | |||
| addr = LoadWavefile(f,path); | |||
| type_code = 'W'; | |||
| } | |||
| else | |||
| if(id == 0x43544950) | |||
| { | |||
| addr = LoadEnvelope(f,path); | |||
| type_code = 'E'; | |||
| } | |||
| else | |||
| if(id == 0x45564E45) | |||
| { | |||
| addr = LoadEnvelope2(f,path); | |||
| type_code = 'E'; | |||
| } | |||
| else | |||
| { | |||
| Error("File not SPEC or RIFF",path); | |||
| addr = -1; | |||
| } | |||
| fclose(f); | |||
| if(addr > 0) | |||
| { | |||
| fprintf(f_phcontents,"%c 0x%.5x %s\n",type_code,addr & 0x7fffff,path); | |||
| } | |||
| } | |||
| fclose(f); | |||
| if(ix > 0) | |||
| // add this item to the hash table | |||
| if(addr > 0) | |||
| { | |||
| fprintf(f_phcontents,"%c 0x%.5x %s\n",type_code,ix & 0x7fffff,path); | |||
| p = ref_hash_tab[hash]; | |||
| p2 = (REF_HASH_TAB *)malloc(sizeof(REF_HASH_TAB)+strlen(path)+1); | |||
| p2->value = addr; | |||
| p2->ph_mnemonic = ph->mnemonic; // phoneme which uses this file | |||
| p2->ph_table = n_phoneme_tabs-1; | |||
| strcpy(p2->string,path); | |||
| p2->link = (char *)p; | |||
| ref_hash_tab[hash] = p2; | |||
| } | |||
| // add this item to the hash table | |||
| p = ref_hash_tab[hash]; | |||
| p2 = (REF_HASH_TAB *)malloc(sizeof(REF_HASH_TAB)+strlen(path)+1); | |||
| p2->value = ix; | |||
| p2->n_uses = 1; | |||
| p2->n_used_by = 1; | |||
| strcpy(p2->string,path); | |||
| p2->used_by[0] = n_phoneme_tabs; | |||
| p2->link = (char *)p; | |||
| ref_hash_tab[hash] = p2; | |||
| return(ix); | |||
| return(addr); | |||
| } // end of Compile::LoadDataFile | |||
| @@ -1892,12 +1873,21 @@ int Compile::LoadEnvelope2(FILE *f, const char *fname) | |||
| static int ref_sorter(char **a, char **b) | |||
| {//====================================== | |||
| int ix; | |||
| REF_HASH_TAB *p1 = (REF_HASH_TAB *)(*a); | |||
| REF_HASH_TAB *p2 = (REF_HASH_TAB *)(*b); | |||
| REF_HASH_TAB *p2 = (REF_HASH_TAB *)(*b); | |||
| ix = strcoll(p1->string,p2->string); | |||
| if(ix != 0) | |||
| return ix; | |||
| ix = p1->ph_table - p2->ph_table; | |||
| if(ix != 0) | |||
| return ix; | |||
| return(strcoll(p1->string,p2->string)); | |||
| } /* end of strcmp2 */ | |||
| return(p1->ph_mnemonic - p2->ph_mnemonic); | |||
| } /* end of ref_sorter */ | |||
| @@ -1909,10 +1899,13 @@ void Compile::Report(void) | |||
| REF_HASH_TAB *p; | |||
| REF_HASH_TAB **list; | |||
| FILE *f_report; | |||
| const char *data_path; | |||
| int prev_table; | |||
| int prev_mnemonic; | |||
| char fname[sizeof(path_source)+20]; | |||
| // make a list of all the references and sort it | |||
| list = (REF_HASH_TAB **)malloc(count_references * sizeof(REF_HASH_TAB *)); | |||
| list = (REF_HASH_TAB **)malloc((count_references)* sizeof(REF_HASH_TAB *)); | |||
| if(list == NULL) | |||
| return; | |||
| @@ -1932,6 +1925,7 @@ void Compile::Report(void) | |||
| } | |||
| fputc('\n',f_report); | |||
| fprintf(f_report,"Data file Used by\n"); | |||
| ix = 0; | |||
| for(hash=0; (hash < 256) && (ix < count_references); hash++) | |||
| { | |||
| @@ -1945,25 +1939,35 @@ void Compile::Report(void) | |||
| n = ix; | |||
| qsort((void *)list,n,sizeof(REF_HASH_TAB *),(int (*)(const void *,const void *))ref_sorter); | |||
| data_path = ""; | |||
| prev_mnemonic = 0; | |||
| prev_table = 0; | |||
| for(ix=0; ix<n; ix++) | |||
| { | |||
| int j, ph_tab_num; | |||
| int j = 0; | |||
| fprintf(f_report,"%3d %s",list[ix]->n_uses, list[ix]->string); | |||
| for(j = strlen(list[ix]->string); j < 14; j++) | |||
| if(strcmp(list[ix]->string, data_path) != 0) | |||
| { | |||
| fputc(' ',f_report); // pad filename with spaces | |||
| data_path = list[ix]->string; | |||
| j = strlen(data_path); | |||
| fprintf(f_report,"%s",data_path); | |||
| } | |||
| for(j=0; (j < list[ix]->n_used_by) && (j<N_USED_BY); j++) | |||
| else | |||
| { | |||
| ph_tab_num = list[ix]->used_by[j]; | |||
| fprintf(f_report," %s",phoneme_tab_list2[ph_tab_num-1].name); | |||
| if((list[ix]->ph_table == prev_table) && (list[ix]->ph_mnemonic == prev_mnemonic)) | |||
| continue; // same phoneme, don't list twice | |||
| } | |||
| if(j < list[ix]->n_used_by) | |||
| while(j < 14) | |||
| { | |||
| fprintf(f_report," ++"); | |||
| fputc(' ',f_report); // pad filename with spaces | |||
| j++; | |||
| } | |||
| fprintf(f_report," [%s] %s",WordToString(prev_mnemonic = list[ix]->ph_mnemonic), phoneme_tab_list2[prev_table = list[ix]->ph_table].name); | |||
| fputc('\n',f_report); | |||
| free(list[ix]); | |||
| } | |||
| free(list); | |||
| fclose(f_report); | |||
+ 16
- 14
src/compiledict.cpp
View File
| @@ -163,9 +163,9 @@ int compile_line(char *linebuf, char *dict_line, int *hash) | |||
| char *p; | |||
| char *word; | |||
| char *phonetic; | |||
| int ix; | |||
| unsigned int ix; | |||
| int step; | |||
| int n_flag_codes = 0; | |||
| unsigned int n_flag_codes = 0; | |||
| int flag_offset; | |||
| int length; | |||
| int multiple_words = 0; | |||
| @@ -181,10 +181,11 @@ int compile_line(char *linebuf, char *dict_line, int *hash) | |||
| unsigned char flag_codes[100]; | |||
| char encoded_ph[200]; | |||
| unsigned char bad_phoneme[4]; | |||
| static char nullstring[] = {0}; | |||
| comment = NULL; | |||
| text_not_phonemes = 0; | |||
| phonetic = word = ""; | |||
| phonetic = word = nullstring; | |||
| p = linebuf; | |||
| // while(isspace2(*p)) p++; | |||
| @@ -1219,7 +1220,7 @@ static int compile_dictrules(FILE *f_in, FILE *f_out, char *fname_temp) | |||
| int n_rules=0; | |||
| int count=0; | |||
| int different; | |||
| char *prev_rgroup_name; | |||
| const char *prev_rgroup_name; | |||
| unsigned int char_code; | |||
| int compile_mode=0; | |||
| char *buf; | |||
| @@ -1247,16 +1248,6 @@ static int compile_dictrules(FILE *f_in, FILE *f_out, char *fname_temp) | |||
| if(buf[0] == '\r') buf++; // ignore extra \r in \r\n | |||
| } | |||
| if((buf != NULL) && (memcmp(buf,".L",2)==0)) | |||
| { | |||
| if(compile_lettergroup(&buf[2], f_out) != 0) | |||
| { | |||
| fprintf(f_log,"%5d: Bad lettergroup\n",linenum); | |||
| error_count++; | |||
| } | |||
| continue; | |||
| } | |||
| if((buf == NULL) || (buf[0] == '.')) | |||
| { | |||
| // next .group or end of file, write out the previous group | |||
| @@ -1277,10 +1268,21 @@ static int compile_dictrules(FILE *f_in, FILE *f_out, char *fname_temp) | |||
| { | |||
| // end of the character replacements section | |||
| fwrite(&n_rules,1,4,f_out); // write a zero word to terminate the replacemenmt list | |||
| compile_mode = 0; | |||
| } | |||
| if(buf == NULL) break; // end of file | |||
| if(memcmp(buf,".L",2)==0) | |||
| { | |||
| if(compile_lettergroup(&buf[2], f_out) != 0) | |||
| { | |||
| fprintf(f_log,"%5d: Bad lettergroup\n",linenum); | |||
| error_count++; | |||
| } | |||
| continue; | |||
| } | |||
| if(memcmp(buf,".replace",8)==0) | |||
| { | |||
| compile_mode = 2; | |||
+ 36
- 19
src/dictionary.cpp
View File
| @@ -230,7 +230,7 @@ void Translator::InitGroups(void) | |||
| if(p[0] == RULE_REPLACEMENTS) | |||
| { | |||
| pw = (unsigned int *)(((int)p+4) & ~3); // advance to next word boundary | |||
| pw = (unsigned int *)(((long)p+4) & ~3); // advance to next word boundary | |||
| langopts.replace_chars = pw; | |||
| while(pw[0] != 0) | |||
| { | |||
| @@ -617,8 +617,8 @@ return(0); | |||
| int Translator::IsLetterGroup(char *word, int group) | |||
| {//================================================= | |||
| int Translator::IsLetterGroup(char *word, int group, int pre) | |||
| {//========================================================== | |||
| // match the word against a list of utf-8 strings | |||
| char *p; | |||
| char *w; | |||
| @@ -1484,7 +1484,7 @@ char *Translator::DecodeRule(const char *group, char *rule) | |||
| if(rb == RULE_ENDING) | |||
| { | |||
| static char *flag_chars = "ei vtfq t"; | |||
| static const char *flag_chars = "ei vtfq t"; | |||
| flags = ((rule[0] & 0x7f)<< 8) + (rule[1] & 0x7f); | |||
| suffix_char = 'S'; | |||
| if(flags & (SUFX_P >> 8)) | |||
| @@ -1802,9 +1802,9 @@ void Translator::MatchRule(char *word[], const char *group, char *rule, MatchRec | |||
| failed = 1; | |||
| break; | |||
| case RULE_LETTERGP2: // match against a list of utf-t strings | |||
| case RULE_LETTERGP2: // match against a list of utf-8 strings | |||
| letter_group = *rule++ - 'A'; | |||
| if((n_bytes = IsLetterGroup(post_ptr-1,letter_group)) >0) | |||
| if((n_bytes = IsLetterGroup(post_ptr-1,letter_group,0)) >0) | |||
| { | |||
| match.points += (20-distance_right); | |||
| post_ptr += (n_bytes-1); | |||
| @@ -1983,6 +1983,17 @@ void Translator::MatchRule(char *word[], const char *group, char *rule, MatchRec | |||
| failed = 1; | |||
| break; | |||
| case RULE_LETTERGP2: // match against a list of utf-8 strings | |||
| letter_group = *rule++ - 'A'; | |||
| if((n_bytes = IsLetterGroup(pre_ptr-letter_xbytes,letter_group,1)) >0) | |||
| { | |||
| match.points += (20-distance_right); | |||
| pre_ptr -= (n_bytes-1); | |||
| } | |||
| else | |||
| failed =1; | |||
| break; | |||
| case RULE_NOTVOWEL: | |||
| if(!IsLetter(letter_w,0)) | |||
| { | |||
| @@ -2345,7 +2356,7 @@ int Translator::TranslateRules(char *p_start, char *phonemes, int ph_size, char | |||
| } | |||
| } | |||
| } | |||
| if(match1.phonemes == NULL) | |||
| match1.phonemes = ""; | |||
| @@ -2567,10 +2578,10 @@ char *print_dflags(int flags) | |||
| int Translator::LookupDict2(char *word, char *word2, char *phonetic, unsigned int *flags, int end_flags) | |||
| //====================================================================================================== | |||
| const char *Translator::LookupDict2(const char *word, const char *word2, char *phonetic, unsigned int *flags, int end_flags) | |||
| //==================================================================================================================== | |||
| /* Find an entry in the word_dict file for a specified word. | |||
| Returns 1 if an entry is found | |||
| Returns NULL if no match, else returns 'word_end' | |||
| word zero terminated word to match | |||
| word2 pointer to next word(s) in the input text (terminated by space) | |||
| @@ -2590,8 +2601,8 @@ int Translator::LookupDict2(char *word, char *word2, char *phonetic, unsigned in | |||
| int condition_failed=0; | |||
| int n_chars; | |||
| int no_phonemes; | |||
| char *word_end; | |||
| char *word1; | |||
| const char *word_end; | |||
| const char *word1; | |||
| char word_buf[N_WORD_BYTES]; | |||
| word1 = word; | |||
| @@ -2801,7 +2812,7 @@ int Translator::LookupDict2(char *word, char *word2, char *phonetic, unsigned in | |||
| fprintf(f_trans,"Found: %s [%s] %s\n",word1,ph_decoded,print_dflags(flags1)); | |||
| } | |||
| } | |||
| return(1); | |||
| return(word_end); | |||
| } | |||
| return(0); | |||
| @@ -2818,12 +2829,13 @@ int Translator::LookupDictList(char **wordptr, char *ph_out, unsigned int *flags | |||
| */ | |||
| { | |||
| int length; | |||
| int found; | |||
| char *word1; | |||
| char *word2; | |||
| const char *found; | |||
| const char *word1; | |||
| const char *word2; | |||
| unsigned char c; | |||
| int nbytes; | |||
| int c2; | |||
| int len; | |||
| char word[N_WORD_BYTES]; | |||
| static char word_replacement[N_WORD_BYTES]; | |||
| @@ -2896,10 +2908,14 @@ int Translator::LookupDictList(char **wordptr, char *ph_out, unsigned int *flags | |||
| word_replacement[0] = 0; | |||
| word_replacement[1] = ' '; | |||
| strcpy(&word_replacement[2],ph_out); // replacement word, preceded by zerochar and space | |||
| word1 = *wordptr; | |||
| *wordptr = &word_replacement[2]; | |||
| if(option_phonemes == 2) | |||
| { | |||
| len = found - word1; | |||
| memcpy(word,word1,len); // include multiple matching words | |||
| fprintf(f_trans,"Replace: %s %s\n",word,*wordptr); | |||
| } | |||
| } | |||
| @@ -2917,10 +2933,11 @@ int Translator::LookupDictList(char **wordptr, char *ph_out, unsigned int *flags | |||
| int Translator::Lookup(char *word, char *ph_out) | |||
| {//============================================= | |||
| int Translator::Lookup(const char *word, char *ph_out) | |||
| {//=================================================== | |||
| unsigned int flags; | |||
| return(LookupDictList(&word,ph_out,&flags,0)); | |||
| char *word1 = (char *)word; | |||
| return(LookupDictList(&word1,ph_out,&flags,0)); | |||
| } | |||
+ 16
- 16
src/espeak_command.cpp
View File
| @@ -490,22 +490,22 @@ int delete_espeak_command( t_espeak_command* the_command) | |||
| case ET_VOICE_SPEC: | |||
| { | |||
| espeak_VOICE* data = &(the_command->u.my_voice_spec); | |||
| if (data->name) | |||
| { | |||
| free(data->name); | |||
| } | |||
| if (data->languages) | |||
| { | |||
| free(data->languages); | |||
| } | |||
| if (data->identifier) | |||
| { | |||
| free(data->identifier); | |||
| } | |||
| espeak_VOICE* data = &(the_command->u.my_voice_spec); | |||
| if (data->name) | |||
| { | |||
| free((void *)data->name); | |||
| } | |||
| if (data->languages) | |||
| { | |||
| free((void *)data->languages); | |||
| } | |||
| if (data->identifier) | |||
| { | |||
| free((void *)data->identifier); | |||
| } | |||
| } | |||
| break; | |||
+ 1
- 1
src/espeakedit.cpp
View File
| @@ -42,7 +42,7 @@ | |||
| #include "prosodydisplay.h" | |||
| static char *about_string = "espeakedit: %s\nAuthor: Jonathan Duddington (c) 2007\n\n" | |||
| static const char *about_string = "espeakedit: %s\nAuthor: Jonathan Duddington (c) 2007\n\n" | |||
| "Licensed under GNU General Public License version 3\n" | |||
| "http://espeak.sourceforge.net/"; | |||
+ 5
- 5
src/extras.cpp
View File
| @@ -308,7 +308,7 @@ void Lexicon_De() | |||
| char phonemes2[80]; | |||
| WORD_TAB winfo; | |||
| static char *vowels = "aeiouyAEIOUY29@"; | |||
| static const char *vowels = "aeiouyAEIOUY29@"; | |||
| wxString fname = wxFileSelector(_T("German Lexicon"),path_dir1,_T(""),_T(""),_T("*"),wxOPEN); | |||
| @@ -477,7 +477,7 @@ void Lexicon_Ru() | |||
| int input_length; | |||
| int sfx; | |||
| char *suffix; | |||
| const char *suffix; | |||
| int wlen; | |||
| int len; | |||
| int check_root; | |||
| @@ -495,7 +495,7 @@ void Lexicon_Ru() | |||
| static char vowels[] = {0xa3,0xc0,0xc1,0xc5,0xc9,0xcf,0xd1,0xd5,0xd9,0xdc,0}; | |||
| typedef struct { | |||
| char *suffix; | |||
| const char *suffix; | |||
| int syllables; | |||
| } SUFFIX; | |||
| @@ -1173,7 +1173,7 @@ int x; | |||
| #define TEXT "Hello world." | |||
| #define TEXT_SSML ("<speak>" TEXT "</speak>") | |||
| static void | |||
| speak(char *text) | |||
| speak(const char *text) | |||
| { | |||
| int result; | |||
| result = espeak_Synth(text, strlen(text) + 1, 0, POS_CHARACTER, 0, espeakSSML, NULL, NULL); | |||
| @@ -1216,7 +1216,7 @@ result = espeak_SetVoiceByProperties(&voice); | |||
| } | |||
| char* text1 = "Hello World2. <audio src=\"here\"> Some text</audio> This is the second sentence"; | |||
| const char* text1 = "Hello World2. <audio src=\"here\"> Some text</audio> This is the second sentence"; | |||
| void TestTest(int control) | |||
| {//======================= | |||
+ 71
- 17
src/intonation.cpp
View File
| @@ -811,10 +811,14 @@ void Translator::CalcPitches_Tone(int clause_tone) | |||
| PHONEME_LIST *p; | |||
| int ix; | |||
| int count_stressed=0; | |||
| int count_stressed2=0; | |||
| int final_stressed=0; | |||
| int tone_ph; | |||
| PHONEME_TAB *tph; | |||
| PHONEME_TAB *prev_tph; // forget across word boundary | |||
| PHONEME_TAB *prevw_tph; // remember across word boundary | |||
| PHONEME_TAB *prev2_tph; // 2 tones previous | |||
| PHONEME_LIST *prev_p; | |||
| int pitch_adjust = 13; // pitch gradient through the clause - inital value | |||
| int pitch_decrement = 3; // decrease by this for each stressed syllable | |||
| @@ -845,31 +849,81 @@ void Translator::CalcPitches_Tone(int clause_tone) | |||
| } | |||
| p = &phoneme_list[0]; | |||
| prev_p = p = &phoneme_list[0]; | |||
| prev_tph = prevw_tph = phoneme_tab[phonPAUSE]; | |||
| // perform tone sandhi | |||
| for(ix=0; ix<n_phoneme_list; ix++, p++) | |||
| { | |||
| if((p->newword) && ((option_tone1 & 1)==0)) | |||
| { | |||
| prev_tph = phoneme_tab[phonPAUSE]; // forget across word boundaries | |||
| } | |||
| if(p->type == phVOWEL) | |||
| { | |||
| tone_ph = p->tone_ph; | |||
| if(tone_ph == 0) | |||
| p->tone_ph = tone_ph = LookupPh("11"); // default tone 5 | |||
| tph = phoneme_tab[tone_ph]; | |||
| if(p->tone >= 2) | |||
| // Mandarin | |||
| if(translator_name == L('z','h')) | |||
| { | |||
| // a stressed syllable | |||
| if(p->tone >= 4) | |||
| if(prev_tph->mnemonic == 0x343132) // [214] | |||
| { | |||
| count_stressed2++; | |||
| if(count_stressed2 == count_stressed) | |||
| { | |||
| // the last stressed syllable | |||
| pitch_adjust = pitch_low; | |||
| } | |||
| if(tph->mnemonic == 0x343132) // [214] | |||
| prev_p->tone_ph = LookupPh("35"); | |||
| else | |||
| { | |||
| pitch_adjust -= pitch_decrement; | |||
| if(pitch_adjust <= pitch_low) | |||
| pitch_adjust = pitch_high; | |||
| } | |||
| prev_p->tone_ph = LookupPh("21"); | |||
| } | |||
| if((prev_tph->mnemonic == 0x3135) && (tph->mnemonic == 0x3135)) // [51] + [51] | |||
| { | |||
| prev_p->tone_ph = LookupPh("53"); | |||
| } | |||
| if(tph->mnemonic == 0x3131) // [11] Tone 5 | |||
| { | |||
| // tone 5, change its level depending on the previous tone (across word boundaries) | |||
| if(prevw_tph->mnemonic == 0x3535) | |||
| p->tone_ph = LookupPh("22"); | |||
| if(prevw_tph->mnemonic == 0x3533) | |||
| p->tone_ph = LookupPh("33"); | |||
| if(prevw_tph->mnemonic == 0x343132) | |||
| p->tone_ph = LookupPh("44"); | |||
| // tone 5 is unstressed (shorter) | |||
| p->tone = 1; // diminished stress | |||
| } | |||
| } | |||
| prev_p = p; | |||
| prev2_tph = prevw_tph; | |||
| prevw_tph = prev_tph = tph; | |||
| } | |||
| } | |||
| // convert tone numbers to pitch | |||
| p = &phoneme_list[0]; | |||
| for(ix=0; ix<n_phoneme_list; ix++, p++) | |||
| { | |||
| if(p->type == phVOWEL) | |||
| { | |||
| tone_ph = p->tone_ph; | |||
| if(p->tone >= 0) // TEST, consider all syllables as stressed | |||
| { | |||
| if(ix == final_stressed) | |||
| { | |||
| // the last stressed syllable | |||
| pitch_adjust = pitch_low; | |||
| } | |||
| else | |||
| { | |||
| pitch_adjust -= pitch_decrement; | |||
| if(pitch_adjust <= pitch_low) | |||
| pitch_adjust = pitch_high; | |||
| } | |||
| if(tone_ph ==0) | |||
+ 3
- 4
src/numbers.cpp
View File
| @@ -19,7 +19,6 @@ | |||
| #include "StdAfx.h" | |||
| #include <stdio.h> | |||
| #include <ctype.h> | |||
| #include <stdlib.h> | |||
| @@ -211,7 +210,7 @@ int Translator::TranslateRoman(char *word, char *ph_out) | |||
| unsigned int flags; | |||
| char number_chars[N_WORD_BYTES]; | |||
| static char *roman_numbers = "ixcmvld"; | |||
| static const char *roman_numbers = "ixcmvld"; | |||
| static int roman_values[] = {1,10,100,1000,5,50,500}; | |||
| acc = 0; | |||
| @@ -504,8 +503,8 @@ int Translator::LookupNum3(int value, char *ph_out, int suppress_null, int thous | |||
| static char *M_Variant(int value) | |||
| {//============================== | |||
| static const char *M_Variant(int value) | |||
| {//==================================== | |||
| // returns M, or perhaps MA for some cases | |||
| if(((value % 100)>20) || ((value % 100)<10)) // but not teens, 10 to 19 | |||
+ 9
- 13
src/readclause.cpp
View File
| @@ -38,7 +38,7 @@ | |||
| #define N_XML_BUF 256 | |||
| char *xmlbase = ""; // base URL from <speak> | |||
| const char *xmlbase = ""; // base URL from <speak> | |||
| int namedata_ix=0; | |||
| int n_namedata = 0; | |||
| @@ -454,23 +454,19 @@ static int GetC(void) | |||
| static void UngetC(int c) | |||
| {//====================== | |||
| ungot_char = c; | |||
| if((f_input != NULL) && feof(f_input)) | |||
| { | |||
| // ungetc(' ',f_input); | |||
| } | |||
| } | |||
| const char *Translator::LookupSpecial(char *string) | |||
| {//================================================ | |||
| const char *Translator::LookupSpecial(const char *string) | |||
| {//====================================================== | |||
| unsigned int flags; | |||
| char phonemes[55]; | |||
| char phonemes2[55]; | |||
| static char buf[60]; | |||
| char *string1 = (char *)string; | |||
| if(LookupDictList(&string,phonemes,&flags,0)) | |||
| if(LookupDictList(&string1,phonemes,&flags,0)) | |||
| { | |||
| SetWordStress(phonemes,flags,-1,0); | |||
| DecodePhonemes(phonemes,phonemes2); | |||
| @@ -706,13 +702,13 @@ MNEM_TAB ssmltags[] = { | |||
| static char *VoiceFromStack() | |||
| {//========================== | |||
| static const char *VoiceFromStack() | |||
| {//================================ | |||
| // Use the voice properties from the SSML stack to choose a voice, and switch | |||
| // to that voice if it's not the current voice | |||
| int ix; | |||
| SSML_STACK *sp; | |||
| char *v_id; | |||
| const char *v_id; | |||
| espeak_VOICE voice_select; | |||
| char voice_name[40]; | |||
| char language[40]; | |||
| @@ -1083,7 +1079,7 @@ static int GetVoiceAttributes(wchar_t *pw, int tag_type) | |||
| wchar_t *name; | |||
| wchar_t *age; | |||
| wchar_t *variant; | |||
| char *new_voice_id; | |||
| const char *new_voice_id; | |||
| static const MNEM_TAB mnem_gender[] = { | |||
| {"male", 1}, | |||
+ 2
- 0
src/speak_lib.cpp
View File
| @@ -365,7 +365,9 @@ static espeak_ERROR Synthesize(unsigned int unique_identifier, const void *text, | |||
| int length; | |||
| int finished = 0; | |||
| int count_buffers = 0; | |||
| #ifdef USE_ASYNC | |||
| uint32_t a_write_pos=0; | |||
| #endif | |||
| #ifdef DEBUG_ENABLED | |||
| if (text) | |||
+ 3
- 3
src/speak_lib.h
View File
| @@ -447,9 +447,9 @@ void espeak_CompileDictionary(const char *path, FILE *log); | |||
| // voice table | |||
| typedef struct { | |||
| char *name; // a given name for this voice. UTF8 string. | |||
| char *languages; // list of pairs of (byte) priority + (string) language (and dialect qualifier) | |||
| char *identifier; // the filename for this voice within espeak-data/voices | |||
| const char *name; // a given name for this voice. UTF8 string. | |||
| const char *languages; // list of pairs of (byte) priority + (string) language (and dialect qualifier) | |||
| const char *identifier; // the filename for this voice within espeak-data/voices | |||
| unsigned char gender; // 0=none 1=male, 2=female, | |||
| unsigned char age; // 0=not specified, or age in years | |||
| unsigned char variant; // only used when passed as a parameter to espeak_SetVoiceByProperties | |||
+ 1
- 1
src/synthdata.cpp
View File
| @@ -35,7 +35,7 @@ | |||
| #include "translate.h" | |||
| #include "wave.h" | |||
| const char *version_string = "1.29.12 29.Oct.07"; | |||
| const char *version_string = "1.29.15 01.Nov.07"; | |||
| const int version_phdata = 0x012901; | |||
| int option_device_number = -1; | |||
+ 4
- 2
src/synthesize.cpp
View File
| @@ -1541,6 +1541,10 @@ int SpeakNextClause(FILE *f_in, const void *text_in, int control) | |||
| // entries in the wavegen command queue | |||
| p_text = translator->TranslateClause(f_text,p_text,&clause_tone,&voice_change); | |||
| translator->CalcPitches(clause_tone); | |||
| translator->CalcLengths(); | |||
| translator->GetTranslatedPhonemeString(translator->phon_out,sizeof(translator->phon_out)); | |||
| if(option_phonemes > 0) | |||
| { | |||
| fprintf(f_trans,"%s\n",translator->phon_out); | |||
| @@ -1550,8 +1554,6 @@ int SpeakNextClause(FILE *f_in, const void *text_in, int control) | |||
| phoneme_callback(translator->phon_out); | |||
| } | |||
| translator->CalcPitches(clause_tone); | |||
| translator->CalcLengths(); | |||
| if(skipping_text) | |||
| { | |||
+ 6
- 6
src/tr_languages.cpp
View File
| @@ -535,7 +535,7 @@ SetLengthMods(tr,3); // all equal | |||
| { | |||
| static int stress_amps_sk[8] = {16,16, 20,20, 20,24, 24,22 }; | |||
| static int stress_lengths_sk[8] = {190,190, 210,210, 0,0, 210,210}; | |||
| static char *sk_voiced = "bdgjlmnrvwzaeiouy"; | |||
| static const char *sk_voiced = "bdgjlmnrvwzaeiouy"; | |||
| tr = new Translator(); | |||
| SetupTranslator(tr,stress_lengths_sk,stress_amps_sk); | |||
| @@ -647,18 +647,18 @@ SetLengthMods(tr,3); // all equal | |||
| break; | |||
| case L('z','h'): | |||
| case L_qa + 'a': // Test qaa | |||
| { | |||
| static int stress_lengths_qaa[8] = {200,200, 248,248, 248,0, 248,250}; | |||
| static int stress_amps_qaa[] = {16,16, 20,20, 24,24, 24,22 }; | |||
| static int stress_lengths_qaa[8] = {220,150, 230,230, 230,0, 230,250}; | |||
| static int stress_amps_qaa[] = {22,18, 22,22, 22,22, 22,22 }; | |||
| tr = new Translator(); | |||
| SetupTranslator(tr,stress_lengths_qaa,stress_amps_qaa); | |||
| tr->langopts.stress_rule = 0; | |||
| tr->langopts.stress_rule = 3; // stress on final syllable of a "word" | |||
| tr->langopts.stress_flags = 1; // don't automatically set diminished stress (may be set in the intonation module) | |||
| tr->langopts.vowel_pause = 0; | |||
| tr->langopts.intonation = 1; // Tone language, use CalcPitches_Tone() rather than CalcPitches() | |||
| tr->langopts.length_mods0 = tr->langopts.length_mods; // don't lengthen vowels in the last syllable | |||
| tr->langopts.tone_numbers = 9; | |||
| tr->langopts.tone_numbers = 9; // a number after letters indicates a tone number (eg. pinyin or jyutping) | |||
| tr->langopts.ideographs = 1; | |||
| tr->langopts.word_gap = 0x5; // length of a final vowel is less dependent on the next consonant, don't merge consonant with next word | |||
| } | |||
+ 9
- 4
src/translate.cpp
View File
| @@ -513,8 +513,8 @@ int utf8_out(unsigned int c, char *buf) | |||
| } // end of utf8_out | |||
| int utf8_in(int *c, char *buf, int backwards) | |||
| {//========================================== | |||
| int utf8_in(int *c, const char *buf, int backwards) | |||
| {//================================================ | |||
| int c1; | |||
| int n_bytes; | |||
| int ix; | |||
| @@ -1116,7 +1116,7 @@ int Translator::TranslateWord2(char *word, WORD_TAB *wtab, int pre_pause, int ne | |||
| int source_ix; | |||
| int len; | |||
| int sylimit; // max. number of syllables in a word to be combined with a preceding preposition | |||
| char *new_language; | |||
| const char *new_language; | |||
| unsigned char bad_phoneme[4]; | |||
| len = wtab->length; | |||
| @@ -1769,6 +1769,12 @@ void *Translator::TranslateClause(FILE *f_text, const void *vp_input, int *tone_ | |||
| prev_out2 = prev_out; | |||
| utf8_in(&prev_out,&sbuf[ix-1],1); // prev_out = sbuf[ix-1]; | |||
| if(langopts.tone_numbers && isdigit(prev_out) && IsAlpha(prev_out2)) | |||
| { | |||
| // tone numbers can be part of a word, consider them as alphabetic | |||
| prev_out = 'a'; | |||
| } | |||
| if(prev_in2 != 0) | |||
| { | |||
| prev_in = prev_in2; | |||
| @@ -2270,7 +2276,6 @@ if((c == '/') && (langopts.testing & 2) && isdigit(next_in) && IsAlpha(prev_out) | |||
| prev_clause_pause = clause_pause; | |||
| GetTranslatedPhonemeString(phon_out,sizeof(phon_out)); | |||
| *tone_out = tone; | |||
| new_sentence = 0; | |||
+ 7
- 6
src/translate.h
View File
| @@ -178,6 +178,7 @@ | |||
| // match 1 pre 2 post 0 - use common phoneme string | |||
| // match 1 pre 2 post 3 0 - empty phoneme string | |||
| typedef const char * constcharptr; | |||
| typedef struct { | |||
| int points; | |||
| @@ -351,6 +352,7 @@ public: | |||
| int LoadDictionary(const char *name, int no_error); | |||
| virtual void CalcLengths(); | |||
| virtual void CalcPitches(int clause_tone); | |||
| void GetTranslatedPhonemeString(char *phon_out, int n_phon_out); | |||
| LANGUAGE_OPTIONS langopts; | |||
| int translator_name; | |||
| @@ -385,7 +387,6 @@ private: | |||
| int TranslateWord2(char *word, WORD_TAB *wtab, int pre_pause, int next_pause); | |||
| int TranslateLetter(char *letter, char *phonemes, int control); | |||
| void SetSpellingStress(char *phonemes, int control); | |||
| void GetTranslatedPhonemeString(char *phon_out, int n_phon_out); | |||
| void WriteMnemonic(int *ix, int mnem); | |||
| void MakePhonemeList(int post_pause, int new_sentence); | |||
| int SubstitutePhonemes(PHONEME_LIST2 *plist_out); | |||
| @@ -393,8 +394,8 @@ private: | |||
| int ReadClause(FILE *f_in, char *buf, unsigned short *charix, int n_buf); | |||
| int AnnouncePunctuation(int c1, int c2, char *buf, int ix); | |||
| int LookupDict2(char *word, char *word2, char *phonetic, unsigned int *flags, int end_flags); | |||
| const char *LookupSpecial(char *string); | |||
| const char *LookupDict2(const char *word, const char *word2, char *phonetic, unsigned int *flags, int end_flags); | |||
| const char *LookupSpecial(const char *string); | |||
| const char *LookupCharName(int c); | |||
| int LookupNum2(int value, int control, char *ph_out); | |||
| int LookupNum3(int value, char *ph_out, int suppress_null, int thousandplex, int prev_thousands); | |||
| @@ -410,7 +411,7 @@ private: | |||
| void ApplySpecialAttribute(char *phonemes, int dict_flags); | |||
| int IsLetter(int letter, int group); | |||
| int IsLetterGroup(char *word, int group); | |||
| int IsLetterGroup(char *word, int group, int pre); | |||
| void CalcPitches_Tone(int clause_tone); | |||
| @@ -424,7 +425,7 @@ protected: | |||
| int IsVowel(int letter); | |||
| int LookupDictList(char **wordptr, char *ph_out, unsigned int *flags, int end_flags); | |||
| int Lookup(char *word, char *ph_out); | |||
| int Lookup(const char *word, char *ph_out); | |||
| // groups1 and groups2 are indexes into data_dictrules, set up by InitGroups() | |||
| @@ -521,7 +522,7 @@ void LoadConfig(void); | |||
| int PhonemeCode(unsigned int mnem); | |||
| void ChangeWordStress(Translator *tr, char *word, int new_stress); | |||
| int TransposeAlphabet(char *text, int offset, int min, int max); | |||
| int utf8_in(int *c, char *buf, int backwards); | |||
| int utf8_in(int *c, const char *buf, int backwards); | |||
| int utf8_out(unsigned int c, char *buf); | |||
| int lookupwchar(const unsigned short *list,int c); | |||
| int Eof(void); | |||
+ 3
- 2
src/transldlg.cpp
View File
| @@ -333,13 +333,14 @@ void TranslDlg::OnCommand(wxCommandEvent& event) | |||
| while((vp != NULL) && (n_ph_list < N_PH_LIST)) | |||
| { | |||
| vp = translator->TranslateClause(NULL,vp,&clause_tone,NULL); | |||
| translator->CalcPitches(clause_tone); | |||
| translator->CalcLengths(); | |||
| translator->GetTranslatedPhonemeString(translator->phon_out,sizeof(translator->phon_out)); | |||
| if(clause_count++ > 0) | |||
| strcat(phon_out," ||"); | |||
| strcat(phon_out,translator->phon_out); | |||
| t_phonetic->SetValue(wxString(translator->phon_out,wxConvLocal)); | |||
| translator->CalcPitches(clause_tone); | |||
| translator->CalcLengths(); | |||
| if((n_ph_list + n_phoneme_list) >= N_PH_LIST) | |||
| { | |||
+ 1
- 1
src/voice.h
View File
| @@ -67,7 +67,7 @@ extern USHORT voice_pcnt[N_PEAKS+1][3]; | |||
| extern voice_t *voice; | |||
| extern int tone_points[10]; | |||
| char *SelectVoice(espeak_VOICE *voice_select); | |||
| const char *SelectVoice(espeak_VOICE *voice_select); | |||
| voice_t *LoadVoice(const char *voice_name, int control); | |||
| voice_t *LoadVoiceVariant(const char *voice_name, int variant); | |||
| void DoVoiceChange(voice_t *v); | |||
+ 7
- 7
src/voices.cpp
View File
| @@ -482,7 +482,7 @@ voice_t *LoadVoice(const char *vname, int control) | |||
| char translator_name[40]; | |||
| char new_dictionary[40]; | |||
| char phonemes_name[40]; | |||
| char *language_type; | |||
| const char *language_type; | |||
| char buf[200]; | |||
| char path_voices[sizeof(path_home)+12]; | |||
| char langname[4]; | |||
| @@ -1005,7 +1005,7 @@ static int __cdecl VoiceScoreSorter(const void *p1, const void *p2) | |||
| static int ScoreVoice(espeak_VOICE *voice_spec, int spec_n_parts, int spec_lang_len, espeak_VOICE *voice) | |||
| {//====================================================================================================== | |||
| int ix; | |||
| char *p; | |||
| const char *p; | |||
| int c1, c2; | |||
| int language_priority; | |||
| int n_parts; | |||
| @@ -1146,7 +1146,7 @@ static int SetVoiceScores(espeak_VOICE *voice_select, espeak_VOICE **voices, int | |||
| int nv; // number of candidates | |||
| int n_parts=0; | |||
| int lang_len=0; | |||
| char *p; | |||
| const char *p; | |||
| espeak_VOICE *vp; | |||
| // count number of parts in the specified language | |||
| @@ -1194,7 +1194,7 @@ static espeak_VOICE *SelectVoiceByName(espeak_VOICE **voices, const char *name) | |||
| int match_fname = -1; | |||
| int match_fname2 = -1; | |||
| int match_name = -1; | |||
| char *id; | |||
| const char *id; | |||
| int last_part_len; | |||
| char last_part[41]; | |||
| @@ -1236,8 +1236,8 @@ static espeak_VOICE *SelectVoiceByName(espeak_VOICE **voices, const char *name) | |||
| char *SelectVoice(espeak_VOICE *voice_select) | |||
| {//========================================== | |||
| char const *SelectVoice(espeak_VOICE *voice_select) | |||
| {//================================================ | |||
| // Returns a path within espeak-voices, with a possible +variant suffix | |||
| // variant is an output-only parameter | |||
| int nv; // number of candidates | |||
| @@ -1525,7 +1525,7 @@ espeak_ERROR SetVoiceByName(const char *name) | |||
| espeak_ERROR SetVoiceByProperties(espeak_VOICE *voice_selector) | |||
| {//============================================================ | |||
| char *voice_id; | |||
| const char *voice_id; | |||
| voice_id = SelectVoice(voice_selector); | |||
+ 5
- 5
src/vowelchart.cpp
View File
| @@ -47,7 +47,7 @@ extern PHONEME_TAB_LIST phoneme_tab_list[N_PHONEME_TABS]; | |||
| // size of the vowelchart png | |||
| #define WIDTH 1200 | |||
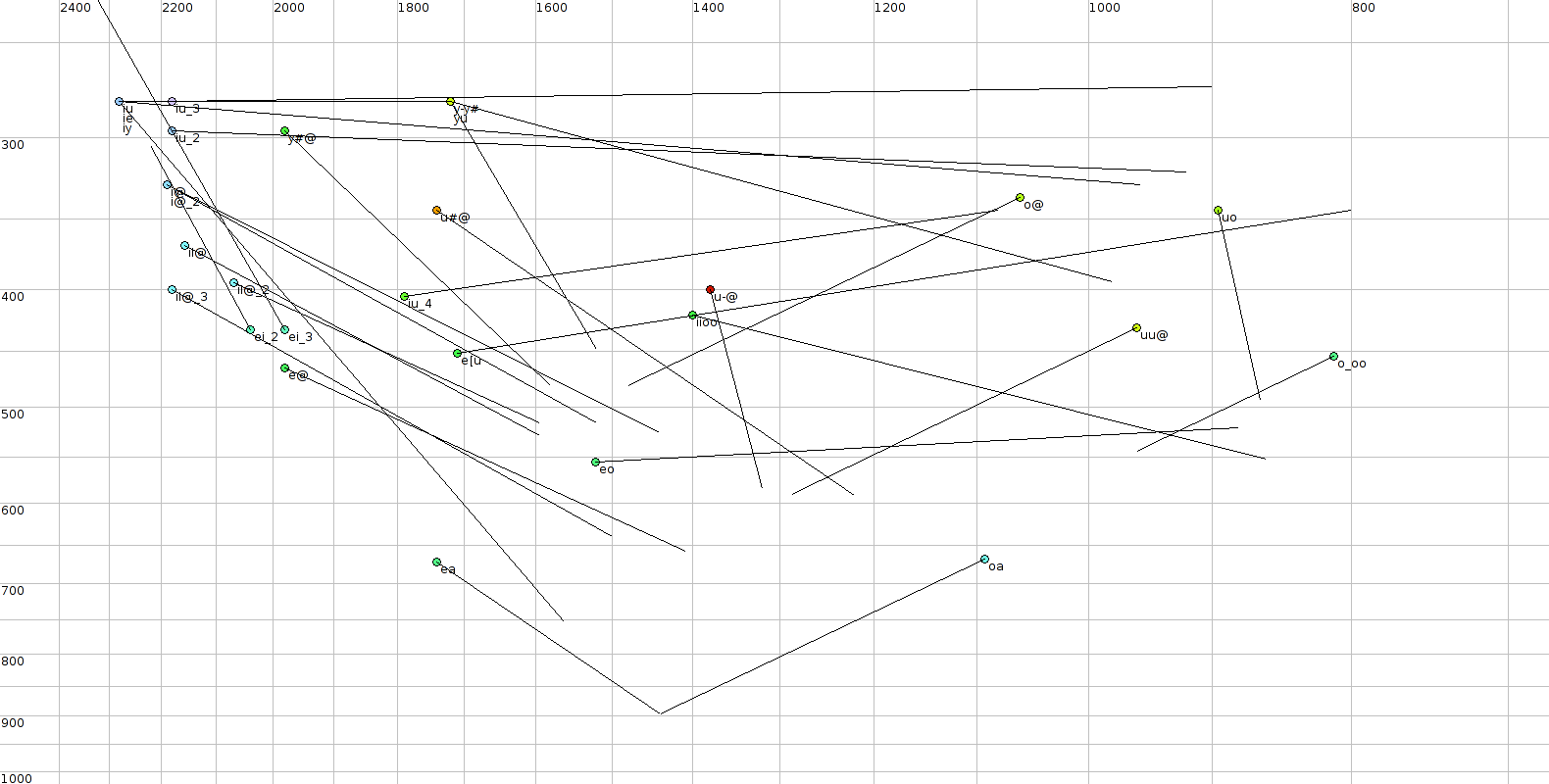
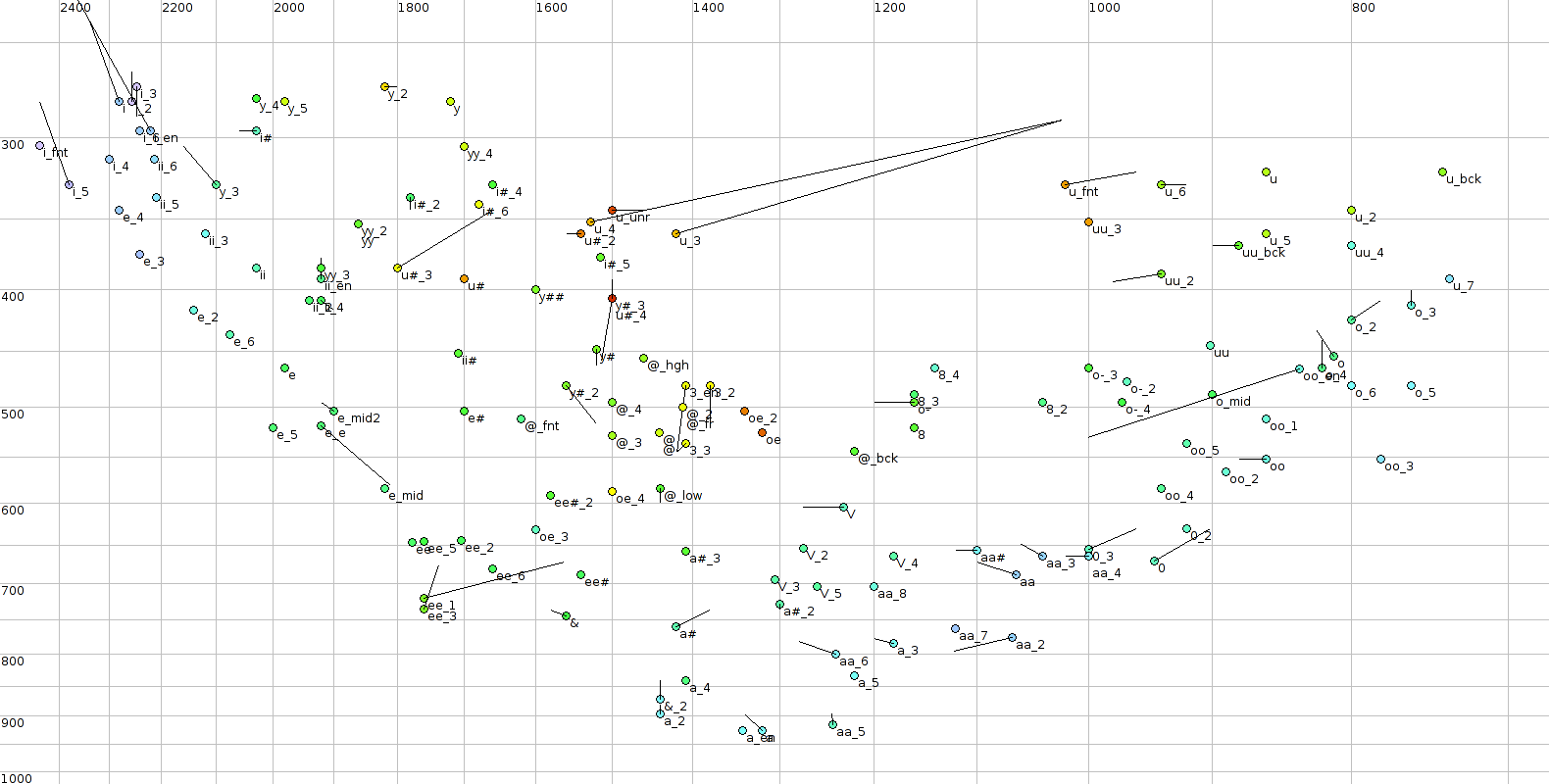
| #define WIDTH 1580 | |||
| #define HEIGHT 800 | |||
| @@ -131,8 +131,8 @@ static double log2a(double x) | |||
| static int VowelX(int f2) | |||
| {//====================== | |||
| return(WIDTH - int((log2a(f2) - 9.49)*WIDTH/1.8)); | |||
| // return(1024 - int((log2a(f2) - 9.50)*1020/1.8)); | |||
| return(WIDTH - int((log2a(f2) - 9.40)*WIDTH/1.9)); | |||
| // return(WIDTH - int((log2a(f2) - 9.49)*WIDTH/1.8)); | |||
| } | |||
| static int VowelY(int f1) | |||
| @@ -168,7 +168,7 @@ static void DrawVowel(wxDC *dc, wxString name, int f1, int f2, int f3, int g1, i | |||
| if(y < 0) y = 0; | |||
| if(y > (HEIGHT-4)) y= (HEIGHT-4); | |||
| if(x < 0) x = 0; | |||
| if(x > (WIDTH-8)) x = (WIDTH-8); | |||
| if(x > (WIDTH-12)) x = (WIDTH-12); | |||
| r = z; | |||
| g = 255; | |||
| @@ -351,7 +351,7 @@ void VowelChart(int control, char *fname) | |||
| if((ix % 100) == 0) | |||
| dc.DrawText(wxString::Format(_T("%d"),ix),1,y); | |||
| } | |||
| for(ix=800; ix<=2400; ix+=100) | |||
| for(ix=700; ix<=2400; ix+=100) | |||
| { | |||
| x = VowelX(ix); | |||
| dc.DrawLine(x,0,x,HEIGHT); | |||
+ 2
- 2
src/wave.cpp
View File
| @@ -634,7 +634,7 @@ void wave_init() | |||
| //> | |||
| //<wave_open | |||
| void* wave_open(char* the_api) | |||
| void* wave_open(const char* the_api) | |||
| { | |||
| ENTER("wave_open"); | |||
| static int once=0; | |||
| @@ -1022,7 +1022,7 @@ void *wave_test_get_write_buffer() | |||
| void wave_init() {} | |||
| void* wave_open(char* the_api) {return (void *)1;} | |||
| void* wave_open(const char* the_api) {return (void *)1;} | |||
| size_t wave_write(void* theHandler, char* theMono16BitsWaveBuffer, size_t theSize) {return theSize;} | |||
| int wave_close(void* theHandler) {return 0;} | |||
| int wave_is_busy(void* theHandler) {return 0;} | |||
+ 1
- 1
src/wave.h
View File
| @@ -9,7 +9,7 @@ extern int option_device_number; | |||
| extern void wave_init(); | |||
| // TBD: the arg could be "alsa", "oss",... | |||
| extern void* wave_open(char* the_api); | |||
| extern void* wave_open(const char* the_api); | |||
| extern size_t wave_write(void* theHandler, char* theMono16BitsWaveBuffer, size_t theSize); | |||
| extern int wave_close(void* theHandler); | |||
Loading…