
commit
d2705c3a33
24 changed files with 5967 additions and 0 deletions
BIN
.DS_Store
View File
+ 1
- 0
Docs/Docs.txt
View File
| the docs file repo saves here |
BIN
Docs/ffpip.jpg
View File
{kind=link}
+ 531
- 0
Inference_individually.py
View File
| from pathlib import Path | |||||
| import numpy as np | |||||
| import matplotlib.pyplot as plt | |||||
| from utils import sample_prompt | |||||
| from collections import defaultdict | |||||
| import torchvision.transforms as transforms | |||||
| import torch | |||||
| from torch import nn | |||||
| import torch.nn.functional as F | |||||
| from segment_anything.utils.transforms import ResizeLongestSide | |||||
| import albumentations as A | |||||
| from albumentations.pytorch import ToTensorV2 | |||||
| from einops import rearrange | |||||
| import random | |||||
| from tqdm import tqdm | |||||
| from time import sleep | |||||
| from data import * | |||||
| from time import time | |||||
| from PIL import Image | |||||
| from sklearn.model_selection import KFold | |||||
| from shutil import copyfile | |||||
| from args import get_arguments | |||||
| # import wandb_handler | |||||
| args = get_arguments() | |||||
| def save_img(img, dir): | |||||
| img = img.clone().cpu().numpy() + 100 | |||||
| if len(img.shape) == 3: | |||||
| img = rearrange(img, "c h w -> h w c") | |||||
| img_min = np.amin(img, axis=(0, 1), keepdims=True) | |||||
| img = img - img_min | |||||
| img_max = np.amax(img, axis=(0, 1), keepdims=True) | |||||
| img = (img / img_max * 255).astype(np.uint8) | |||||
| img = Image.fromarray(img) | |||||
| else: | |||||
| img_min = img.min() | |||||
| img = img - img_min | |||||
| img_max = img.max() | |||||
| if img_max != 0: | |||||
| img = img / img_max * 255 | |||||
| img = Image.fromarray(img).convert("L") | |||||
| img.save(dir) | |||||
| class loss_fn(torch.nn.Module): | |||||
| def __init__(self, alpha=0.7, gamma=2.0, epsilon=1e-5): | |||||
| super(loss_fn, self).__init__() | |||||
| self.alpha = alpha | |||||
| self.gamma = gamma | |||||
| self.epsilon = epsilon | |||||
| def dice_loss(self, logits, gt, eps=1): | |||||
| probs = torch.sigmoid(logits) | |||||
| probs = probs.view(-1) | |||||
| gt = gt.view(-1) | |||||
| intersection = (probs * gt).sum() | |||||
| dice_coeff = (2.0 * intersection + eps) / (probs.sum() + gt.sum() + eps) | |||||
| loss = 1 - dice_coeff | |||||
| return loss | |||||
| def focal_loss(self, logits, gt, gamma=2): | |||||
| logits = logits.reshape(-1, 1) | |||||
| gt = gt.reshape(-1, 1) | |||||
| logits = torch.cat((1 - logits, logits), dim=1) | |||||
| probs = torch.sigmoid(logits) | |||||
| pt = probs.gather(1, gt.long()) | |||||
| modulating_factor = (1 - pt) ** gamma | |||||
| focal_loss = -modulating_factor * torch.log(pt + 1e-12) | |||||
| loss = focal_loss.mean() | |||||
| return loss # Store as a Python number to save memory | |||||
| def forward(self, logits, target): | |||||
| logits = logits.squeeze(1) | |||||
| target = target.squeeze(1) | |||||
| # Dice Loss | |||||
| # prob = F.softmax(logits, dim=1)[:, 1, ...] | |||||
| dice_loss = self.dice_loss(logits, target) | |||||
| # Focal Loss | |||||
| focal_loss = self.focal_loss(logits, target.squeeze(-1)) | |||||
| alpha = 20.0 | |||||
| # Combined Loss | |||||
| combined_loss = alpha * focal_loss + dice_loss | |||||
| return combined_loss | |||||
| def img_enhance(img2, coef=0.2): | |||||
| img_mean = np.mean(img2) | |||||
| img_max = np.max(img2) | |||||
| val = (img_max - img_mean) * coef + img_mean | |||||
| img2[img2 < img_mean * 0.7] = img_mean * 0.7 | |||||
| img2[img2 > val] = val | |||||
| return img2 | |||||
| def dice_coefficient(logits, gt): | |||||
| eps=1 | |||||
| binary_mask = logits>0 | |||||
| intersection = (binary_mask * gt).sum(dim=(-2,-1)) | |||||
| dice_scores = (2.0 * intersection + eps) / (binary_mask.sum(dim=(-2,-1)) + gt.sum(dim=(-2,-1)) + eps) | |||||
| return dice_scores.mean() | |||||
| def calculate_recall(pred, target): | |||||
| smooth = 1 | |||||
| batch_size = pred.shape[0] | |||||
| recall_scores = [] | |||||
| binary_mask = pred>0 | |||||
| for i in range(batch_size): | |||||
| true_positive = ((binary_mask[i] == 1) & (target[i] == 1)).sum().item() | |||||
| false_negative = ((binary_mask[i] == 0) & (target[i] == 1)).sum().item() | |||||
| recall = (true_positive + smooth) / ((true_positive + false_negative) + smooth) | |||||
| recall_scores.append(recall) | |||||
| return sum(recall_scores) / len(recall_scores) | |||||
| def calculate_precision(pred, target): | |||||
| smooth = 1 | |||||
| batch_size = pred.shape[0] | |||||
| precision_scores = [] | |||||
| binary_mask = pred>0 | |||||
| for i in range(batch_size): | |||||
| true_positive = ((binary_mask[i] == 1) & (target[i] == 1)).sum().item() | |||||
| false_positive = ((binary_mask[i] == 1) & (target[i] == 0)).sum().item() | |||||
| precision = (true_positive + smooth) / ((true_positive + false_positive) + smooth) | |||||
| precision_scores.append(precision) | |||||
| return sum(precision_scores) / len(precision_scores) | |||||
| def calculate_jaccard(pred, target): | |||||
| smooth = 1 | |||||
| batch_size = pred.shape[0] | |||||
| jaccard_scores = [] | |||||
| binary_mask = pred>0 | |||||
| for i in range(batch_size): | |||||
| true_positive = ((binary_mask[i] == 1) & (target[i] == 1)).sum().item() | |||||
| false_positive = ((binary_mask[i] == 1) & (target[i] == 0)).sum().item() | |||||
| false_negative = ((binary_mask[i] == 0) & (target[i] == 1)).sum().item() | |||||
| jaccard = (true_positive + smooth) / (true_positive + false_positive + false_negative + smooth) | |||||
| jaccard_scores.append(jaccard) | |||||
| return sum(jaccard_scores) / len(jaccard_scores) | |||||
| def calculate_specificity(pred, target): | |||||
| smooth = 1 | |||||
| batch_size = pred.shape[0] | |||||
| specificity_scores = [] | |||||
| binary_mask = pred>0 | |||||
| for i in range(batch_size): | |||||
| true_negative = ((binary_mask[i] == 0) & (target[i] == 0)).sum().item() | |||||
| false_positive = ((binary_mask[i] == 1) & (target[i] == 0)).sum().item() | |||||
| specificity = (true_negative + smooth) / (true_negative + false_positive + smooth) | |||||
| specificity_scores.append(specificity) | |||||
| return sum(specificity_scores) / len(specificity_scores) | |||||
| def what_the_f(low_res_masks,label): | |||||
| low_res_label = F.interpolate(label, low_res_masks.shape[-2:]) | |||||
| dice = dice_coefficient( | |||||
| low_res_masks, low_res_label | |||||
| ) | |||||
| recall=calculate_recall(low_res_masks, low_res_label) | |||||
| precision =calculate_precision(low_res_masks, low_res_label) | |||||
| jaccard = calculate_jaccard(low_res_masks, low_res_label) | |||||
| return dice , precision , recall , jaccard | |||||
| accumaltive_batch_size = 8 | |||||
| batch_size = 1 | |||||
| num_workers = 2 | |||||
| slice_per_image = 1 | |||||
| num_epochs = 40 | |||||
| sample_size = 3660 | |||||
| # sample_size = 43300 | |||||
| # image_size=sam_model.image_encoder.img_size | |||||
| image_size = 1024 | |||||
| exp_id = 0 | |||||
| found = 0 | |||||
| layer_n = 4 | |||||
| L = layer_n | |||||
| a = np.full(L, layer_n) | |||||
| params = {"M": 255, "a": a, "p": 0.35} | |||||
| model_type = "vit_h" | |||||
| checkpoint = "checkpoints/sam_vit_h_4b8939.pth" | |||||
| device = "cuda:0" | |||||
| from segment_anything import SamPredictor, sam_model_registry | |||||
| ##################################main model####################################### | |||||
| class panc_sam(nn.Module): | |||||
| def __init__(self, *args, **kwargs) -> None: | |||||
| super().__init__(*args, **kwargs) | |||||
| #Promptless | |||||
| sam = torch.load(args.pointbasemodel).sam | |||||
| self.prompt_encoder = sam.prompt_encoder | |||||
| self.mask_decoder = sam.mask_decoder | |||||
| for param in self.prompt_encoder.parameters(): | |||||
| param.requires_grad = False | |||||
| for param in self.mask_decoder.parameters(): | |||||
| param.requires_grad = False | |||||
| #with Prompt | |||||
| sam = torch.load( | |||||
| args.promptprovider | |||||
| ).sam | |||||
| self.image_encoder = sam.image_encoder | |||||
| self.prompt_encoder2 = sam.prompt_encoder | |||||
| self.mask_decoder2 = sam.mask_decoder | |||||
| for param in self.image_encoder.parameters(): | |||||
| param.requires_grad = False | |||||
| for param in self.prompt_encoder2.parameters(): | |||||
| param.requires_grad = False | |||||
| def forward(self, input_images,box=None): | |||||
| # input_images = torch.stack([x["image"] for x in batched_input], dim=0) | |||||
| # raise ValueError(input_images.shape) | |||||
| with torch.no_grad(): | |||||
| image_embeddings = self.image_encoder(input_images).detach() | |||||
| outputs_prompt = [] | |||||
| outputs = [] | |||||
| for curr_embedding in image_embeddings: | |||||
| with torch.no_grad(): | |||||
| sparse_embeddings, dense_embeddings = self.prompt_encoder( | |||||
| points=None, | |||||
| boxes=None, | |||||
| masks=None, | |||||
| ) | |||||
| low_res_masks, _ = self.mask_decoder( | |||||
| image_embeddings=curr_embedding, | |||||
| image_pe=self.prompt_encoder.get_dense_pe().detach(), | |||||
| sparse_prompt_embeddings=sparse_embeddings.detach(), | |||||
| dense_prompt_embeddings=dense_embeddings.detach(), | |||||
| multimask_output=False, | |||||
| ) | |||||
| outputs_prompt.append(low_res_masks) | |||||
| # raise ValueError(low_res_masks) | |||||
| # points, point_labels = sample_prompt((low_res_masks > 0).float()) | |||||
| points, point_labels = sample_prompt(low_res_masks) | |||||
| points = points * 4 | |||||
| points = (points, point_labels) | |||||
| with torch.no_grad(): | |||||
| sparse_embeddings, dense_embeddings = self.prompt_encoder2( | |||||
| points=points, | |||||
| boxes=None, | |||||
| masks=None, | |||||
| ) | |||||
| low_res_masks, _ = self.mask_decoder2( | |||||
| image_embeddings=curr_embedding, | |||||
| image_pe=self.prompt_encoder2.get_dense_pe().detach(), | |||||
| sparse_prompt_embeddings=sparse_embeddings.detach(), | |||||
| dense_prompt_embeddings=dense_embeddings.detach(), | |||||
| multimask_output=False, | |||||
| ) | |||||
| outputs.append(low_res_masks) | |||||
| low_res_masks_promtp = torch.cat(outputs_prompt, dim=0) | |||||
| low_res_masks = torch.cat(outputs, dim=0) | |||||
| return low_res_masks, low_res_masks_promtp | |||||
| ##################################end####################################### | |||||
| ##################################Augmentation####################################### | |||||
| augmentation = A.Compose( | |||||
| [ | |||||
| A.Rotate(limit=30, p=0.5), | |||||
| A.RandomBrightnessContrast(brightness_limit=0.3, contrast_limit=0.3, p=1), | |||||
| A.RandomResizedCrop(1024, 1024, scale=(0.9, 1.0), p=1), | |||||
| A.HorizontalFlip(p=0.5), | |||||
| A.CLAHE(clip_limit=2.0, tile_grid_size=(8, 8), p=0.5), | |||||
| A.CoarseDropout( | |||||
| max_holes=8, | |||||
| max_height=16, | |||||
| max_width=16, | |||||
| min_height=8, | |||||
| min_width=8, | |||||
| fill_value=0, | |||||
| p=0.5, | |||||
| ), | |||||
| A.RandomScale(scale_limit=0.3, p=0.5), | |||||
| # A.GaussNoise(var_limit=(10.0, 50.0), p=0.5), | |||||
| # A.GridDistortion(p=0.5), | |||||
| ] | |||||
| ) | |||||
| ##################model load##################### | |||||
| panc_sam_instance = panc_sam() | |||||
| # for param in panc_sam_instance_point.parameters(): | |||||
| # param.requires_grad = False | |||||
| panc_sam_instance.to(device) | |||||
| panc_sam_instance.train() | |||||
| ##################load data####################### | |||||
| test_dataset = PanDataset( | |||||
| [args.test_dir], | |||||
| [args.test_labels_dir], | |||||
| [["NIH_PNG",1]], | |||||
| image_size, | |||||
| slice_per_image=slice_per_image, | |||||
| train=False, | |||||
| ) | |||||
| test_loader = DataLoader( | |||||
| test_dataset, | |||||
| batch_size=batch_size, | |||||
| collate_fn=test_dataset.collate_fn, | |||||
| shuffle=False, | |||||
| drop_last=False, | |||||
| num_workers=num_workers, | |||||
| ) | |||||
| ##################end load data####################### | |||||
| lr = 1e-4 | |||||
| max_lr = 5e-5 | |||||
| wd = 5e-4 | |||||
| optimizer_main = torch.optim.Adam( | |||||
| # parameters, | |||||
| list(panc_sam_instance.mask_decoder2.parameters()), | |||||
| lr=lr, | |||||
| weight_decay=wd, | |||||
| ) | |||||
| scheduler_main = torch.optim.lr_scheduler.OneCycleLR( | |||||
| optimizer_main, | |||||
| max_lr=max_lr, | |||||
| epochs=num_epochs, | |||||
| steps_per_epoch=sample_size // (accumaltive_batch_size // batch_size), | |||||
| ) | |||||
| ##################################################### | |||||
| from statistics import mean | |||||
| from tqdm import tqdm | |||||
| from torch.nn.functional import threshold, normalize | |||||
| loss_function = loss_fn(alpha=0.5, gamma=2.0) | |||||
| loss_function.to(device) | |||||
| from time import time | |||||
| import time as s_time | |||||
| def process_model(main_model , data_loader, train=0, save_output=0): | |||||
| epoch_losses = [] | |||||
| results=[] | |||||
| index = 0 | |||||
| results = torch.zeros((2, 0, 256, 256)) | |||||
| ############################# | |||||
| total_dice = 0.0 | |||||
| total_precision = 0.0 | |||||
| total_recall =0.0 | |||||
| total_jaccard = 0.0 | |||||
| ############################# | |||||
| num_samples = 0 | |||||
| ############################# | |||||
| total_dice_main =0.0 | |||||
| total_precision_main = 0.0 | |||||
| total_recall_main =0.0 | |||||
| total_jaccard_main = 0.0 | |||||
| counterb = 0 | |||||
| for image, label in tqdm(data_loader, total=sample_size): | |||||
| num_samples += 1 | |||||
| counterb += 1 | |||||
| index += 1 | |||||
| image = image.to(device) | |||||
| label = label.to(device).float() | |||||
| ############################model and dice######################################## | |||||
| box = torch.tensor([[200, 200, 750, 800]]).to(device) | |||||
| low_res_masks_main,low_res_masks_prompt = main_model(image,box) | |||||
| low_res_label = F.interpolate(label, low_res_masks_main.shape[-2:]) | |||||
| dice_prompt, precisio_prompt , recall_prompt , jaccard_prompt = what_the_f(low_res_masks_prompt,low_res_label) | |||||
| dice_main , precision_main , recall_main , jaccard_main = what_the_f(low_res_masks_main,low_res_label) | |||||
| binary_mask = normalize(threshold(low_res_masks_main, 0.0,0)) | |||||
| ##############prompt############### | |||||
| total_dice += dice_prompt | |||||
| total_precision += precisio_prompt | |||||
| total_recall += recall_prompt | |||||
| total_jaccard += jaccard_prompt | |||||
| average_dice = total_dice / num_samples | |||||
| average_precision = total_precision /num_samples | |||||
| average_recall = total_recall /num_samples | |||||
| average_jaccard = total_jaccard /num_samples | |||||
| ##############main################## | |||||
| total_dice_main+=dice_main | |||||
| total_precision_main +=precision_main | |||||
| total_recall_main +=recall_main | |||||
| total_jaccard_main += jaccard_main | |||||
| average_dice_main = total_dice_main / num_samples | |||||
| average_precision_main = total_precision_main /num_samples | |||||
| average_recall_main = total_recall_main /num_samples | |||||
| average_jaccard_main = total_jaccard_main /num_samples | |||||
| ################################### | |||||
| # result = torch.cat( | |||||
| # ( | |||||
| # # low_res_masks_main[0].detach().cpu().reshape(1, 1, 256, 256), | |||||
| # binary_mask[0].detach().cpu().reshape(1, 1, 256, 256), | |||||
| # ), | |||||
| # dim=0, | |||||
| # ) | |||||
| # results = torch.cat((results, result), dim=1) | |||||
| if counterb == sample_size and train: | |||||
| break | |||||
| elif counterb == sample_size and not train: | |||||
| break | |||||
| return epoch_losses, results, average_dice,average_precision ,average_recall, average_jaccard,average_dice_main,average_precision_main,average_recall_main,average_jaccard_main | |||||
| def train_model( test_loader, K_fold=False, N_fold=7, epoch_num_start=7): | |||||
| print("Train model started.") | |||||
| test_losses = [] | |||||
| test_epochs = [] | |||||
| dice = [] | |||||
| dice_main = [] | |||||
| dice_test = [] | |||||
| dice_test_main =[] | |||||
| results = [] | |||||
| index = 0 | |||||
| print("Testing:") | |||||
| test_epoch_losses, epoch_results, average_dice_test,average_precision ,average_recall, average_jaccard,average_dice_test_main,average_precision_main,average_recall_main,average_jaccard_main = process_model( | |||||
| panc_sam_instance,test_loader | |||||
| ) | |||||
| import torchvision.transforms.functional as TF | |||||
| dice_test.append(average_dice_test) | |||||
| dice_test_main.append(average_dice_test_main) | |||||
| print("######################Prompt##########################") | |||||
| print(f"Test Dice : {average_dice_test}") | |||||
| print(f"Test presision : {average_precision}") | |||||
| print(f"Test recall : {average_recall}") | |||||
| print(f"Test jaccard : {average_jaccard}") | |||||
| print("######################Main##########################") | |||||
| print(f"Test Dice main : {average_dice_test_main}") | |||||
| print(f"Test presision main : {average_precision_main}") | |||||
| print(f"Test recall main : {average_recall_main}") | |||||
| print(f"Test jaccard main : {average_jaccard_main}") | |||||
| # results.append(epoch_results) | |||||
| # del epoch_results | |||||
| del average_dice_test | |||||
| # return train_losses, results | |||||
| train_model(test_loader) | |||||
+ 51
- 0
README.md
View File
| # Pancreas Segmentation in CT Scan Images: Harnessing the Power of SAM | |||||
| <p align="center"> | |||||
| <img width="100%" src="Docs/ffpip.jpg"> | |||||
| </p> | |||||
| In this repositpry we describe the code impelmentation of the paper: "Pancreas Segmentation in CT Scan Images: Harnessing the Power of SAM" | |||||
| ## Requirments | |||||
| Frist step is install [requirements.txt](/requirements.txt) bakages in a conda eviroment. | |||||
| Clone the [SAM](https://github.com/facebookresearch/segment-anything) repository. | |||||
| Use the code below to download the suggested checkpoint of SAM: | |||||
| ``` | |||||
| !wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth" | |||||
| ``` | |||||
| ## Dadaset and data loader description | |||||
| For this segmentation report we used to populare pancreas datas: | |||||
| - [NIH pancreas CT](https://wiki.cancerimagingarchive.net/display/Public/Pancreas-CT) | |||||
| - [AbdomenCT-1K](https://github.com/JunMa11/AbdomenCT-1K) | |||||
| After downloading and allocating datasets, we used a specefice data format (.npy) and for this step [save.py](/data_handler/save.py) provided. `save_dir` and `labels_save_dir` should modify. | |||||
| As defualt `data.py` and `data_loader_group.py` are used in the desired codes. | |||||
| Address can be modify in [args.py](args.py). | |||||
| Due to anonymous code submitiom we haven't share our Model Weights. | |||||
| ## Train model | |||||
| For train model we use the files [fine_tune_good.py](fine_tune_good.py) and [fine_tune_good_unet.py](fine_tune_good_unet.py) and the command bellow is an example for start training with some costume settings. | |||||
| ``` | |||||
| python3 fine_tune_good_unet.py --sample_size 66 --accumulative_batch_size 4 --num_epochs 60 --num_workers 8 --batch_step_one 20 --batch_step_two 30 --lr 3e-4 --inference | |||||
| ``` | |||||
| ## Inference Model | |||||
| To infrence both types of decoders just run the [double_decoder_infrence.py](double_decoder_infrence.py) | |||||
| To get individually infrence SAM with or without prompt use [Inference_individually.py](Inference_individually) | |||||
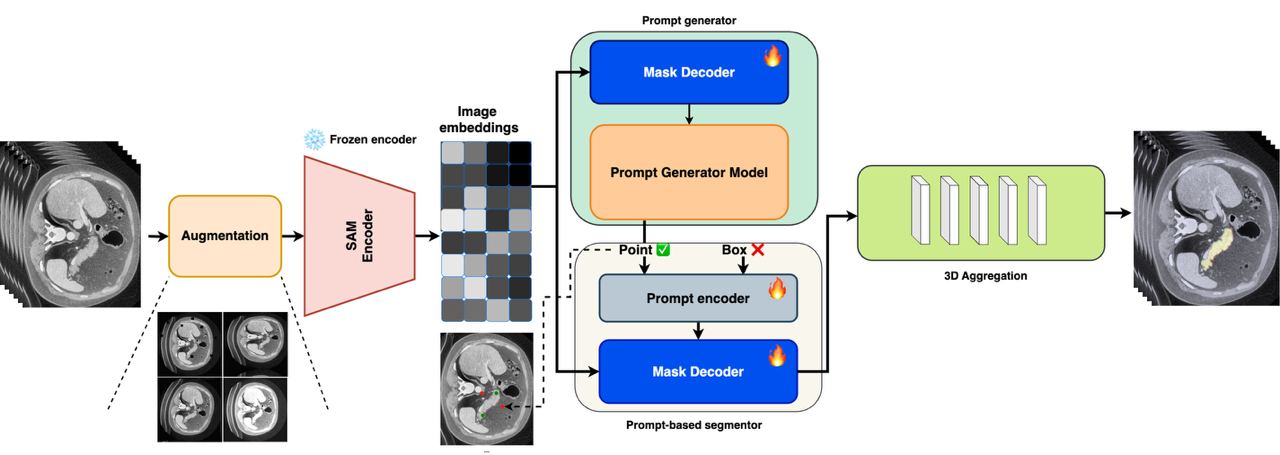
| ## 3D Aggregator | |||||
| To run the `3D Aggregator` codes are available in [kernel](/kernel) folder and just run the [run.sh](kernel/run.sh) file. | |||||
| becuase of opening so many files, the `u -limit` thresh hold should be increased using: | |||||
| ``` | |||||
| u -limit 15000 | |||||
| ``` | |||||
+ 662
- 0
SAM_with_prompt.py
View File
| debug = 0 | |||||
| from pathlib import Path | |||||
| import numpy as np | |||||
| import matplotlib.pyplot as plt | |||||
| # import cv2 | |||||
| from collections import defaultdict | |||||
| import torchvision.transforms as transforms | |||||
| import torch | |||||
| from torch import nn | |||||
| import torch.nn.functional as F | |||||
| from segment_anything.utils.transforms import ResizeLongestSide | |||||
| import albumentations as A | |||||
| from albumentations.pytorch import ToTensorV2 | |||||
| import numpy as np | |||||
| from einops import rearrange | |||||
| import random | |||||
| from tqdm import tqdm | |||||
| from time import sleep | |||||
| from data import * | |||||
| from time import time | |||||
| from PIL import Image | |||||
| from sklearn.model_selection import KFold | |||||
| from shutil import copyfile | |||||
| # import monai | |||||
| from tqdm import tqdm | |||||
| from utils import main_prompt,main_prompt_for_ground_true | |||||
| from torch.autograd import Variable | |||||
| from args import get_arguments | |||||
| # import wandb_handler | |||||
| args = get_arguments() | |||||
| def save_img(img, dir): | |||||
| img = img.clone().cpu().numpy() + 100 | |||||
| if len(img.shape) == 3: | |||||
| img = rearrange(img, "c h w -> h w c") | |||||
| img_min = np.amin(img, axis=(0, 1), keepdims=True) | |||||
| img = img - img_min | |||||
| img_max = np.amax(img, axis=(0, 1), keepdims=True) | |||||
| img = (img / img_max * 255).astype(np.uint8) | |||||
| grey_img = Image.fromarray(img[:, :, 0]) | |||||
| img = Image.fromarray(img) | |||||
| else: | |||||
| img_min = img.min() | |||||
| img = img - img_min | |||||
| img_max = img.max() | |||||
| if img_max != 0: | |||||
| img = img / img_max * 255 | |||||
| img = Image.fromarray(img).convert("L") | |||||
| img.save(dir) | |||||
| class FocalLoss(nn.Module): | |||||
| def __init__(self, gamma=2.0, alpha=0.25): | |||||
| super(FocalLoss, self).__init__() | |||||
| self.gamma = gamma | |||||
| self.alpha = alpha | |||||
| def dice_loss(self, logits, gt, eps=1): | |||||
| # Convert logits to probabilities | |||||
| # Flatten the tensors | |||||
| # probs = probs.view(-1) | |||||
| # gt = gt.view(-1) | |||||
| probs = torch.sigmoid(logits) | |||||
| # Compute Dice coefficient | |||||
| intersection = (probs * gt).sum() | |||||
| dice_coeff = (2.0 * intersection + eps) / (probs.sum() + gt.sum() + eps) | |||||
| # Compute Dice Los[s | |||||
| loss = 1 - dice_coeff | |||||
| return loss | |||||
| def focal_loss(self, pred, mask): | |||||
| """ | |||||
| pred: [B, 1, H, W] | |||||
| mask: [B, 1, H, W] | |||||
| """ | |||||
| # pred=pred.reshape(-1,1) | |||||
| # mask = mask.reshape(-1,1) | |||||
| # assert pred.shape == mask.shape, "pred and mask should have the same shape." | |||||
| p = torch.sigmoid(pred) | |||||
| num_pos = torch.sum(mask) | |||||
| num_neg = mask.numel() - num_pos | |||||
| w_pos = (1 - p) ** self.gamma | |||||
| w_neg = p**self.gamma | |||||
| loss_pos = -self.alpha * mask * w_pos * torch.log(p + 1e-12) | |||||
| loss_neg = -(1 - self.alpha) * (1 - mask) * w_neg * torch.log(1 - p + 1e-12) | |||||
| loss = (torch.sum(loss_pos) + torch.sum(loss_neg)) / (num_pos + num_neg + 1e-12) | |||||
| return loss | |||||
| def forward(self, logits, target): | |||||
| logits = logits.squeeze(1) | |||||
| target = target.squeeze(1) | |||||
| # Dice Loss | |||||
| # prob = F.softmax(logits, dim=1)[:, 1, ...] | |||||
| dice_loss = self.dice_loss(logits, target) | |||||
| # Focal Loss | |||||
| focal_loss = self.focal_loss(logits, target.squeeze(-1)) | |||||
| alpha = 20.0 | |||||
| # Combined Loss | |||||
| combined_loss = alpha * focal_loss + dice_loss | |||||
| return combined_loss | |||||
| class loss_fn(torch.nn.Module): | |||||
| def __init__(self, alpha=0.7, gamma=2.0, epsilon=1e-5): | |||||
| super(loss_fn, self).__init__() | |||||
| self.alpha = alpha | |||||
| self.gamma = gamma | |||||
| self.epsilon = epsilon | |||||
| def tversky_loss(self, y_pred, y_true, alpha=0.8, beta=0.2, smooth=1e-2): | |||||
| y_pred = torch.sigmoid(y_pred) | |||||
| # raise ValueError(y_pred) | |||||
| y_true_pos = torch.flatten(y_true) | |||||
| y_pred_pos = torch.flatten(y_pred) | |||||
| true_pos = torch.sum(y_true_pos * y_pred_pos) | |||||
| false_neg = torch.sum(y_true_pos * (1 - y_pred_pos)) | |||||
| false_pos = torch.sum((1 - y_true_pos) * y_pred_pos) | |||||
| tversky_index = (true_pos + smooth) / ( | |||||
| true_pos + alpha * false_neg + beta * false_pos + smooth | |||||
| ) | |||||
| return 1 - tversky_index | |||||
| def focal_tversky(self, y_pred, y_true, gamma=0.75): | |||||
| pt_1 = self.tversky_loss(y_pred, y_true) | |||||
| return torch.pow((1 - pt_1), gamma) | |||||
| def dice_loss(self, logits, gt, eps=1): | |||||
| # Convert logits to probabilities | |||||
| # Flatten the tensorsx | |||||
| probs = torch.sigmoid(logits) | |||||
| probs = probs.view(-1) | |||||
| gt = gt.view(-1) | |||||
| # Compute Dice coefficient | |||||
| intersection = (probs * gt).sum() | |||||
| dice_coeff = (2.0 * intersection + eps) / (probs.sum() + gt.sum() + eps) | |||||
| # Compute Dice Los[s | |||||
| loss = 1 - dice_coeff | |||||
| return loss | |||||
| def focal_loss(self, logits, gt, gamma=2): | |||||
| logits = logits.reshape(-1, 1) | |||||
| gt = gt.reshape(-1, 1) | |||||
| logits = torch.cat((1 - logits, logits), dim=1) | |||||
| probs = torch.sigmoid(logits) | |||||
| pt = probs.gather(1, gt.long()) | |||||
| modulating_factor = (1 - pt) ** gamma | |||||
| # pt_false= pt<=0.5 | |||||
| # modulating_factor[pt_false] *= 2 | |||||
| focal_loss = -modulating_factor * torch.log(pt + 1e-12) | |||||
| # Compute the mean focal loss | |||||
| loss = focal_loss.mean() | |||||
| return loss # Store as a Python number to save memory | |||||
| def forward(self, logits, target): | |||||
| logits = logits.squeeze(1) | |||||
| target = target.squeeze(1) | |||||
| # Dice Loss | |||||
| # prob = F.softmax(logits, dim=1)[:, 1, ...] | |||||
| dice_loss = self.dice_loss(logits, target) | |||||
| tversky_loss = self.tversky_loss(logits, target) | |||||
| # Focal Loss | |||||
| focal_loss = self.focal_loss(logits, target.squeeze(-1)) | |||||
| alpha = 20.0 | |||||
| # Combined Loss | |||||
| combined_loss = alpha * focal_loss + dice_loss | |||||
| return combined_loss | |||||
| def img_enhance(img2, coef=0.2): | |||||
| img_mean = np.mean(img2) | |||||
| img_max = np.max(img2) | |||||
| val = (img_max - img_mean) * coef + img_mean | |||||
| img2[img2 < img_mean * 0.7] = img_mean * 0.7 | |||||
| img2[img2 > val] = val | |||||
| return img2 | |||||
| def dice_coefficient(pred, target): | |||||
| smooth = 1 # Smoothing constant to avoid division by zero | |||||
| dice = 0 | |||||
| pred_index = pred | |||||
| target_index = target | |||||
| intersection = (pred_index * target_index).sum() | |||||
| union = pred_index.sum() + target_index.sum() | |||||
| dice += (2.0 * intersection + smooth) / (union + smooth) | |||||
| return dice.item() | |||||
| num_workers = 4 | |||||
| slice_per_image = 1 | |||||
| num_epochs = 80 | |||||
| sample_size = 2000 | |||||
| # image_size=sam_model.image_encoder.img_size | |||||
| image_size = 1024 | |||||
| exp_id = 0 | |||||
| found = 0 | |||||
| if debug: | |||||
| user_input = "debug" | |||||
| else: | |||||
| user_input = input("Related changes: ") | |||||
| while found == 0: | |||||
| try: | |||||
| os.makedirs(f"exps/{exp_id}-{user_input}") | |||||
| found = 1 | |||||
| except: | |||||
| exp_id = exp_id + 1 | |||||
| copyfile(os.path.realpath(__file__), f"exps/{exp_id}-{user_input}/code.py") | |||||
| layer_n = 4 | |||||
| L = layer_n | |||||
| a = np.full(L, layer_n) | |||||
| params = {"M": 255, "a": a, "p": 0.35} | |||||
| device = "cuda:0" | |||||
| from segment_anything import SamPredictor, sam_model_registry | |||||
| # ////////////////// | |||||
| class panc_sam(nn.Module): | |||||
| def __init__(self, *args, **kwargs) -> None: | |||||
| super().__init__(*args, **kwargs) | |||||
| sam=sam_model_registry[args.model_type](args.checkpoint) | |||||
| def forward(self, batched_input): | |||||
| # with torch.no_grad(): | |||||
| # raise ValueError(10) | |||||
| input_images = torch.stack([x["image"] for x in batched_input], dim=0) | |||||
| with torch.no_grad(): | |||||
| image_embeddings = self.sam.image_encoder(input_images).detach() | |||||
| outputs = [] | |||||
| for image_record, curr_embedding in zip(batched_input, image_embeddings): | |||||
| if "point_coords" in image_record: | |||||
| points = (image_record["point_coords"].unsqueeze(0), image_record["point_labels"].unsqueeze(0)) | |||||
| # raise ValueError(points) | |||||
| else: | |||||
| raise ValueError('what the f?') | |||||
| points = None | |||||
| # raise ValueError(image_record["point_coords"].shape) | |||||
| with torch.no_grad(): | |||||
| sparse_embeddings, dense_embeddings = self.sam.prompt_encoder( | |||||
| points=points, | |||||
| boxes=image_record.get("boxes", None), | |||||
| masks=image_record.get("mask_inputs", None), | |||||
| ) | |||||
| low_res_masks, _ = self.sam.mask_decoder( | |||||
| image_embeddings=curr_embedding.unsqueeze(0), | |||||
| image_pe=self.sam.prompt_encoder.get_dense_pe().detach(), | |||||
| sparse_prompt_embeddings=sparse_embeddings.detach(), | |||||
| dense_prompt_embeddings=dense_embeddings.detach(), | |||||
| multimask_output=False, | |||||
| ) | |||||
| outputs.append( | |||||
| { | |||||
| "low_res_logits": low_res_masks, | |||||
| } | |||||
| ) | |||||
| low_res_masks = torch.stack([x["low_res_logits"] for x in outputs], dim=0) | |||||
| return low_res_masks.squeeze(1) | |||||
| # /////////////// | |||||
| augmentation = A.Compose( | |||||
| [ | |||||
| A.Rotate(limit=90, p=0.5), | |||||
| A.RandomBrightnessContrast(brightness_limit=0.3, contrast_limit=0.3, p=1), | |||||
| A.RandomResizedCrop(1024, 1024, scale=(0.9, 1.0), p=1), | |||||
| A.HorizontalFlip(p=0.5), | |||||
| A.CLAHE(clip_limit=2.0, tile_grid_size=(8, 8), p=0.5), | |||||
| A.CoarseDropout( | |||||
| max_holes=8, | |||||
| max_height=16, | |||||
| max_width=16, | |||||
| min_height=8, | |||||
| min_width=8, | |||||
| fill_value=0, | |||||
| p=0.5, | |||||
| ), | |||||
| A.RandomScale(scale_limit=0.1, p=0.5), | |||||
| ] | |||||
| ) | |||||
| panc_sam_instance = panc_sam() | |||||
| panc_sam_instance.to(device) | |||||
| panc_sam_instance.train() | |||||
| train_dataset = PanDataset( | |||||
| [args.train_dir], | |||||
| [args.train_labels_dir], | |||||
| [["NIH_PNG",1]], | |||||
| image_size, | |||||
| slice_per_image=slice_per_image, | |||||
| train=True, | |||||
| augmentation=augmentation, | |||||
| ) | |||||
| val_dataset = PanDataset( | |||||
| [args.val_dir], | |||||
| [args.train_dir], | |||||
| [["NIH_PNG",1]], | |||||
| image_size, | |||||
| slice_per_image=slice_per_image, | |||||
| train=False, | |||||
| ) | |||||
| train_loader = DataLoader( | |||||
| train_dataset, | |||||
| batch_size=args.batch_size, | |||||
| collate_fn=train_dataset.collate_fn, | |||||
| shuffle=True, | |||||
| drop_last=False, | |||||
| num_workers=num_workers, | |||||
| ) | |||||
| val_loader = DataLoader( | |||||
| val_dataset, | |||||
| batch_size=args.batch_size, | |||||
| collate_fn=val_dataset.collate_fn, | |||||
| shuffle=False, | |||||
| drop_last=False, | |||||
| num_workers=num_workers, | |||||
| ) | |||||
| # Set up the optimizer, hyperparameter tuning will improve performance here | |||||
| lr = 1e-4 | |||||
| max_lr = 5e-5 | |||||
| wd = 5e-4 | |||||
| optimizer = torch.optim.Adam( | |||||
| # parameters, | |||||
| list(panc_sam_instance.sam.mask_decoder.parameters()), | |||||
| # list(panc_sam_instance.mask_decoder.parameters()), | |||||
| lr=lr, | |||||
| weight_decay=wd, | |||||
| ) | |||||
| scheduler = torch.optim.lr_scheduler.OneCycleLR( | |||||
| optimizer, | |||||
| max_lr=max_lr, | |||||
| epochs=num_epochs, | |||||
| steps_per_epoch=sample_size // (args.accumulative_batch_size // args.batch_size), | |||||
| ) | |||||
| from statistics import mean | |||||
| from tqdm import tqdm | |||||
| from torch.nn.functional import threshold, normalize | |||||
| loss_function = loss_fn(alpha=0.5, gamma=2.0) | |||||
| loss_function.to(device) | |||||
| from time import time | |||||
| import time as s_time | |||||
| log_file = open(f"exps/{exp_id}-{user_input}/log.txt", "a") | |||||
| def process_model(data_loader, train=0, save_output=0): | |||||
| epoch_losses = [] | |||||
| index = 0 | |||||
| results = torch.zeros((2, 0, 256, 256)) | |||||
| total_dice = 0.0 | |||||
| num_samples = 0 | |||||
| counterb = 0 | |||||
| for image, label in tqdm(data_loader, total=sample_size): | |||||
| s_time.sleep(0.6) | |||||
| counterb += 1 | |||||
| index += 1 | |||||
| image = image.to(device) | |||||
| label = label.to(device).float() | |||||
| input_size = (1024, 1024) | |||||
| box = torch.tensor([[200, 200, 750, 800]]).to(device) | |||||
| points, point_labels = main_prompt_for_ground_true(label) | |||||
| # raise ValueError(points) | |||||
| batched_input = [] | |||||
| for ibatch in range(args.batch_size): | |||||
| batched_input.append( | |||||
| { | |||||
| "image": image[ibatch], | |||||
| "point_coords": points[ibatch], | |||||
| "point_labels": point_labels[ibatch], | |||||
| "original_size": (1024, 1024) | |||||
| # 'original_size': image1.shape[:2] | |||||
| }, | |||||
| ) | |||||
| # raise ValueError(batched_input) | |||||
| low_res_masks = panc_sam_instance(batched_input) | |||||
| low_res_label = F.interpolate(label, low_res_masks.shape[-2:]) | |||||
| binary_mask = normalize(threshold(low_res_masks, 0.0,0)) | |||||
| loss = loss_function(low_res_masks, low_res_label) | |||||
| loss /= (args.accumulative_batch_size / args.batch_size) | |||||
| opened_binary_mask = torch.zeros_like(binary_mask).cpu() | |||||
| for j, mask in enumerate(binary_mask[:, 0]): | |||||
| numpy_mask = mask.detach().cpu().numpy().astype(np.uint8) | |||||
| opened_binary_mask[j][0] = torch.from_numpy(numpy_mask) | |||||
| dice = dice_coefficient( | |||||
| opened_binary_mask.numpy(), low_res_label.cpu().detach().numpy() | |||||
| ) | |||||
| # print(dice) | |||||
| total_dice += dice | |||||
| num_samples += 1 | |||||
| average_dice = total_dice / num_samples | |||||
| log_file.write(str(average_dice) + "\n") | |||||
| log_file.flush() | |||||
| if train: | |||||
| loss.backward() | |||||
| if index % (args.accumulative_batch_size / args.batch_size) == 0: | |||||
| # print(loss) | |||||
| optimizer.step() | |||||
| scheduler.step() | |||||
| optimizer.zero_grad() | |||||
| index = 0 | |||||
| else: | |||||
| result = torch.cat( | |||||
| ( | |||||
| low_res_masks[0].detach().cpu().reshape(1, 1, 256, 256), | |||||
| opened_binary_mask[0].reshape(1, 1, 256, 256), | |||||
| ), | |||||
| dim=0, | |||||
| ) | |||||
| results = torch.cat((results, result), dim=1) | |||||
| if index % (args.accumulative_batch_size / args.batch_size) == 0: | |||||
| epoch_losses.append(loss.item()) | |||||
| if counterb == sample_size and train: | |||||
| break | |||||
| elif counterb == sample_size // 5 and not train: | |||||
| break | |||||
| return epoch_losses, results, average_dice | |||||
| def train_model(train_loader, val_loader, K_fold=False, N_fold=7, epoch_num_start=7): | |||||
| print("Train model started.") | |||||
| train_losses = [] | |||||
| train_epochs = [] | |||||
| val_losses = [] | |||||
| val_epochs = [] | |||||
| dice = [] | |||||
| dice_val = [] | |||||
| results = [] | |||||
| if debug==0: | |||||
| index = 0 | |||||
| ## training with k-fold cross validation: | |||||
| last_best_dice = 0 | |||||
| for epoch in range(num_epochs): | |||||
| if epoch > epoch_num_start: | |||||
| kf = KFold(n_splits=N_fold, shuffle=True) | |||||
| for i, (train_index, val_index) in enumerate(kf.split(train_loader)): | |||||
| print( | |||||
| f"=====================EPOCH: {epoch} fold: {i}=====================" | |||||
| ) | |||||
| print("Training:") | |||||
| x_train, x_val = ( | |||||
| train_loader[train_index], | |||||
| train_loader[val_index], | |||||
| ) | |||||
| train_epoch_losses, epoch_results, average_dice = process_model( | |||||
| x_train, train=1 | |||||
| ) | |||||
| dice.append(average_dice) | |||||
| train_losses.append(train_epoch_losses) | |||||
| if (average_dice) > 0.6: | |||||
| print("validating:") | |||||
| ( | |||||
| val_epoch_losses, | |||||
| epoch_results, | |||||
| average_dice_val, | |||||
| ) = process_model(x_val) | |||||
| val_losses.append(val_epoch_losses) | |||||
| for i in tqdm(range(len(epoch_results[0]))): | |||||
| if not os.path.exists(f"ims/batch_{i}"): | |||||
| os.mkdir(f"ims/batch_{i}") | |||||
| save_img( | |||||
| epoch_results[0, i].clone(), | |||||
| f"ims/batch_{i}/prob_epoch_{epoch}.png", | |||||
| ) | |||||
| save_img( | |||||
| epoch_results[1, i].clone(), | |||||
| f"ims/batch_{i}/pred_epoch_{epoch}.png", | |||||
| ) | |||||
| train_mean_losses = [mean(x) for x in train_losses] | |||||
| val_mean_losses = [mean(x) for x in val_losses] | |||||
| np.save("train_losses.npy", train_mean_losses) | |||||
| np.save("val_losses.npy", val_mean_losses) | |||||
| print(f"Train Dice: {average_dice}") | |||||
| print(f"Mean train loss: {mean(train_epoch_losses)}") | |||||
| try: | |||||
| dice_val.append(average_dice_val) | |||||
| print(f"val Dice : {average_dice_val}") | |||||
| print(f"Mean val loss: {mean(val_epoch_losses)}") | |||||
| results.append(epoch_results) | |||||
| val_epochs.append(epoch) | |||||
| train_epochs.append(epoch) | |||||
| plt.plot( | |||||
| val_epochs, | |||||
| val_mean_losses, | |||||
| train_epochs, | |||||
| train_mean_losses, | |||||
| ) | |||||
| if average_dice_val > last_best_dice: | |||||
| torch.save( | |||||
| panc_sam_instance, | |||||
| f"exps/{exp_id}-{user_input}/sam_tuned_save.pth", | |||||
| ) | |||||
| last_best_dice = average_dice_val | |||||
| del epoch_results | |||||
| del average_dice_val | |||||
| except: | |||||
| train_epochs.append(epoch) | |||||
| plt.plot(train_epochs, train_mean_losses) | |||||
| print( | |||||
| f"=================End of EPOCH: {epoch} Fold :{i}==================\n" | |||||
| ) | |||||
| plt.yscale("log") | |||||
| plt.title("Mean epoch loss") | |||||
| plt.xlabel("Epoch Number") | |||||
| plt.ylabel("Loss") | |||||
| plt.savefig("result") | |||||
| else: | |||||
| print(f"=====================EPOCH: {epoch}=====================") | |||||
| last_best_dice = 0 | |||||
| print("Training:") | |||||
| train_epoch_losses, epoch_results, average_dice = process_model( | |||||
| train_loader, train=1 | |||||
| ) | |||||
| dice.append(average_dice) | |||||
| train_losses.append(train_epoch_losses) | |||||
| if (average_dice) > 0.6: | |||||
| print("validating:") | |||||
| val_epoch_losses, epoch_results, average_dice_val = process_model( | |||||
| val_loader | |||||
| ) | |||||
| val_losses.append(val_epoch_losses) | |||||
| # for i in tqdm(range(len(epoch_results[0]))): | |||||
| # if not os.path.exists(f"ims/batch_{i}"): | |||||
| # os.mkdir(f"ims/batch_{i}") | |||||
| # save_img( | |||||
| # epoch_results[0, i].clone(), | |||||
| # f"ims/batch_{i}/prob_epoch_{epoch}.png", | |||||
| # ) | |||||
| # save_img( | |||||
| # epoch_results[1, i].clone(), | |||||
| # f"ims/batch_{i}/pred_epoch_{epoch}.png", | |||||
| # ) | |||||
| train_mean_losses = [mean(x) for x in train_losses] | |||||
| val_mean_losses = [mean(x) for x in val_losses] | |||||
| np.save("train_losses.npy", train_mean_losses) | |||||
| np.save("val_losses.npy", val_mean_losses) | |||||
| print(f"Train Dice: {average_dice}") | |||||
| print(f"Mean train loss: {mean(train_epoch_losses)}") | |||||
| try: | |||||
| dice_val.append(average_dice_val) | |||||
| print(f"val Dice : {average_dice_val}") | |||||
| print(f"Mean val loss: {mean(val_epoch_losses)}") | |||||
| results.append(epoch_results) | |||||
| val_epochs.append(epoch) | |||||
| train_epochs.append(epoch) | |||||
| plt.plot( | |||||
| val_epochs, val_mean_losses, train_epochs, train_mean_losses | |||||
| ) | |||||
| if average_dice_val > last_best_dice: | |||||
| torch.save( | |||||
| panc_sam_instance, | |||||
| f"exps/{exp_id}-{user_input}/sam_tuned_save.pth", | |||||
| ) | |||||
| last_best_dice = average_dice_val | |||||
| del epoch_results | |||||
| del average_dice_val | |||||
| except: | |||||
| train_epochs.append(epoch) | |||||
| plt.plot(train_epochs, train_mean_losses) | |||||
| print(f"=================End of EPOCH: {epoch}==================\n") | |||||
| plt.yscale("log") | |||||
| plt.title("Mean epoch loss") | |||||
| plt.xlabel("Epoch Number") | |||||
| plt.ylabel("Loss") | |||||
| plt.savefig("result") | |||||
| return train_losses, val_losses, results | |||||
| train_losses, val_losses, results = train_model(train_loader, val_loader) | |||||
| log_file.close() | |||||
| # train and also test the model |
+ 456
- 0
SAM_without_prompt.py
View File
| from pathlib import Path | |||||
| import numpy as np | |||||
| import matplotlib.pyplot as plt | |||||
| # import cv2 | |||||
| from collections import defaultdict | |||||
| import torchvision.transforms as transforms | |||||
| import torch | |||||
| from torch import nn | |||||
| import torch.nn.functional as F | |||||
| from segment_anything.utils.transforms import ResizeLongestSide | |||||
| import albumentations as A | |||||
| from albumentations.pytorch import ToTensorV2 | |||||
| import numpy as np | |||||
| from einops import rearrange | |||||
| import random | |||||
| from tqdm import tqdm | |||||
| from time import sleep | |||||
| from data import * | |||||
| from time import time | |||||
| from PIL import Image | |||||
| from sklearn.model_selection import KFold | |||||
| from shutil import copyfile | |||||
| from args import get_arguments | |||||
| # import wandb_handler | |||||
| args = get_arguments() | |||||
| def save_img(img, dir): | |||||
| img = img.clone().cpu().numpy() + 100 | |||||
| if len(img.shape) == 3: | |||||
| img = rearrange(img, "c h w -> h w c") | |||||
| img_min = np.amin(img, axis=(0, 1), keepdims=True) | |||||
| img = img - img_min | |||||
| img_max = np.amax(img, axis=(0, 1), keepdims=True) | |||||
| img = (img / img_max * 255).astype(np.uint8) | |||||
| grey_img = Image.fromarray(img[:, :, 0]) | |||||
| img = Image.fromarray(img) | |||||
| else: | |||||
| img_min = img.min() | |||||
| img = img - img_min | |||||
| img_max = img.max() | |||||
| if img_max != 0: | |||||
| img = img / img_max * 255 | |||||
| img = Image.fromarray(img).convert("L") | |||||
| img.save(dir) | |||||
| class loss_fn(torch.nn.Module): | |||||
| def __init__(self, alpha=0.7, gamma=2.0, epsilon=1e-5): | |||||
| super(loss_fn, self).__init__() | |||||
| self.alpha = alpha | |||||
| self.gamma = gamma | |||||
| self.epsilon = epsilon | |||||
| def dice_loss(self, logits, gt, eps=1): | |||||
| # Convert logits to probabilities | |||||
| # Flatten the tensorsx | |||||
| probs = torch.sigmoid(logits) | |||||
| probs = probs.view(-1) | |||||
| gt = gt.view(-1) | |||||
| # Compute Dice coefficient | |||||
| intersection = (probs * gt).sum() | |||||
| dice_coeff = (2.0 * intersection + eps) / (probs.sum() + gt.sum() + eps) | |||||
| # Compute Dice Los[s | |||||
| loss = 1 - dice_coeff | |||||
| return loss | |||||
| def focal_loss(self, logits, gt, gamma=2): | |||||
| logits = logits.reshape(-1, 1) | |||||
| gt = gt.reshape(-1, 1) | |||||
| logits = torch.cat((1 - logits, logits), dim=1) | |||||
| probs = torch.sigmoid(logits) | |||||
| pt = probs.gather(1, gt.long()) | |||||
| modulating_factor = (1 - pt) ** gamma | |||||
| # pt_false= pt<=0.5 | |||||
| # modulating_factor[pt_false] *= 2 | |||||
| focal_loss = -modulating_factor * torch.log(pt + 1e-12) | |||||
| # Compute the mean focal loss | |||||
| loss = focal_loss.mean() | |||||
| return loss # Store as a Python number to save memory | |||||
| def forward(self, logits, target): | |||||
| logits = logits.squeeze(1) | |||||
| target = target.squeeze(1) | |||||
| # Dice Loss | |||||
| # prob = F.softmax(logits, dim=1)[:, 1, ...] | |||||
| dice_loss = self.dice_loss(logits, target) | |||||
| # Focal Loss | |||||
| focal_loss = self.focal_loss(logits, target.squeeze(-1)) | |||||
| alpha = 20.0 | |||||
| # Combined Loss | |||||
| combined_loss = alpha * focal_loss + dice_loss | |||||
| return combined_loss | |||||
| def img_enhance(img2, coef=0.2): | |||||
| img_mean = np.mean(img2) | |||||
| img_max = np.max(img2) | |||||
| val = (img_max - img_mean) * coef + img_mean | |||||
| img2[img2 < img_mean * 0.7] = img_mean * 0.7 | |||||
| img2[img2 > val] = val | |||||
| return img2 | |||||
| def dice_coefficient(logits, gt): | |||||
| eps=1 | |||||
| binary_mask = logits>0 | |||||
| intersection = (binary_mask * gt).sum(dim=(-2,-1)) | |||||
| dice_scores = (2.0 * intersection + eps) / (binary_mask.sum(dim=(-2,-1)) + gt.sum(dim=(-2,-1)) + eps) | |||||
| return dice_scores.mean() | |||||
| def what_the_f(low_res_masks,label): | |||||
| low_res_label = F.interpolate(label, low_res_masks.shape[-2:]) | |||||
| dice = dice_coefficient( | |||||
| low_res_masks, low_res_label | |||||
| ) | |||||
| return dice | |||||
| accumaltive_batch_size = 8 | |||||
| batch_size = 1 | |||||
| num_workers = 4 | |||||
| slice_per_image = 1 | |||||
| num_epochs = 80 | |||||
| sample_size = 2000 | |||||
| image_size = 1024 | |||||
| exp_id = 0 | |||||
| found=0 | |||||
| debug = 0 | |||||
| if debug: | |||||
| user_input='debug' | |||||
| else: | |||||
| user_input = input("Related changes: ") | |||||
| while found == 0: | |||||
| try: | |||||
| os.makedirs(f"exps/{exp_id}-{user_input}/") | |||||
| found = 1 | |||||
| except: | |||||
| exp_id = exp_id + 1 | |||||
| copyfile(os.path.realpath(__file__), f"exps/{exp_id}-{user_input}/code.py") | |||||
| device = "cuda:1" | |||||
| from segment_anything import SamPredictor, sam_model_registry | |||||
| # ////////////////// | |||||
| class panc_sam(nn.Module): | |||||
| def __init__(self, *args, **kwargs) -> None: | |||||
| super().__init__(*args, **kwargs) | |||||
| sam=sam_model_registry[args.model_type](args.checkpoint) | |||||
| # self.sam = torch.load('exps/sam_tuned_save.pth').sam | |||||
| self.prompt_encoder = self.sam.prompt_encoder | |||||
| for param in self.prompt_encoder.parameters(): | |||||
| param.requires_grad = False | |||||
| def forward(self, image ,box): | |||||
| with torch.no_grad(): | |||||
| image_embedding = self.sam.image_encoder(image).detach() | |||||
| outputs_prompt = [] | |||||
| for curr_embedding in image_embedding: | |||||
| with torch.no_grad(): | |||||
| sparse_embeddings, dense_embeddings = self.sam.prompt_encoder( | |||||
| points=None, | |||||
| boxes=None, | |||||
| masks=None, | |||||
| ) | |||||
| low_res_masks, _ = self.sam.mask_decoder( | |||||
| image_embeddings=curr_embedding, | |||||
| image_pe=self.sam.prompt_encoder.get_dense_pe().detach(), | |||||
| sparse_prompt_embeddings=sparse_embeddings.detach(), | |||||
| dense_prompt_embeddings=dense_embeddings.detach(), | |||||
| multimask_output=False, | |||||
| ) | |||||
| outputs_prompt.append(low_res_masks) | |||||
| low_res_masks_promtp = torch.cat(outputs_prompt, dim=0) | |||||
| # raise ValueError(low_res_masks_promtp) | |||||
| return low_res_masks_promtp | |||||
| # /////////////// | |||||
| augmentation = A.Compose( | |||||
| [ | |||||
| A.Rotate(limit=90, p=0.5), | |||||
| A.RandomBrightnessContrast(brightness_limit=0.3, contrast_limit=0.3, p=1), | |||||
| A.RandomResizedCrop(1024, 1024, scale=(0.9, 1.0), p=1), | |||||
| A.HorizontalFlip(p=0.5), | |||||
| A.CLAHE(clip_limit=2.0, tile_grid_size=(8, 8), p=0.5), | |||||
| A.CoarseDropout(max_holes=8, max_height=16, max_width=16, min_height=8, min_width=8, fill_value=0, p=0.5), | |||||
| A.RandomScale(scale_limit=0.3, p=0.5), | |||||
| A.GaussNoise(var_limit=(10.0, 50.0), p=0.5), | |||||
| A.GridDistortion(p=0.5), | |||||
| ] | |||||
| ) | |||||
| panc_sam_instance=panc_sam() | |||||
| panc_sam_instance.to(device) | |||||
| panc_sam_instance.train() | |||||
| train_dataset = PanDataset( | |||||
| [args.train_dir], | |||||
| [args.train_labels_dir], | |||||
| [["NIH_PNG",1]], | |||||
| image_size, | |||||
| slice_per_image=slice_per_image, | |||||
| train=True, | |||||
| augmentation=augmentation, | |||||
| ) | |||||
| val_dataset = PanDataset( | |||||
| [args.val_dir], | |||||
| [args.val_labels_dir], | |||||
| [["NIH_PNG",1]], | |||||
| image_size, | |||||
| slice_per_image=slice_per_image, | |||||
| train=False, | |||||
| ) | |||||
| train_loader = DataLoader( | |||||
| train_dataset, | |||||
| batch_size=batch_size, | |||||
| collate_fn=train_dataset.collate_fn, | |||||
| shuffle=True, | |||||
| drop_last=False, | |||||
| num_workers=num_workers, | |||||
| ) | |||||
| val_loader = DataLoader( | |||||
| val_dataset, | |||||
| batch_size=batch_size, | |||||
| collate_fn=val_dataset.collate_fn, | |||||
| shuffle=False, | |||||
| drop_last=False, | |||||
| num_workers=num_workers, | |||||
| ) | |||||
| # Set up the optimizer, hyperparameter tuning will improve performance here | |||||
| lr = 1e-4 | |||||
| max_lr = 5e-5 | |||||
| wd = 5e-4 | |||||
| optimizer = torch.optim.Adam( | |||||
| # parameters, | |||||
| list(panc_sam_instance.sam.mask_decoder.parameters()), | |||||
| lr=lr, weight_decay=wd | |||||
| ) | |||||
| scheduler = torch.optim.lr_scheduler.OneCycleLR( | |||||
| optimizer, | |||||
| max_lr=max_lr, | |||||
| epochs=num_epochs, | |||||
| steps_per_epoch=sample_size // (accumaltive_batch_size // batch_size), | |||||
| ) | |||||
| from statistics import mean | |||||
| from tqdm import tqdm | |||||
| from torch.nn.functional import threshold, normalize | |||||
| loss_function = loss_fn(alpha=0.5, gamma=2.0) | |||||
| loss_function.to(device) | |||||
| from time import time | |||||
| import time as s_time | |||||
| log_file = open(f"exps/{exp_id}-{user_input}/log.txt", "a") | |||||
| def process_model(data_loader, train=0, save_output=0): | |||||
| epoch_losses = [] | |||||
| index = 0 | |||||
| results = torch.zeros((2, 0, 256, 256)) | |||||
| total_dice = 0.0 | |||||
| num_samples = 0 | |||||
| counterb = 0 | |||||
| for image, label in tqdm(data_loader, total=sample_size): | |||||
| counterb += 1 | |||||
| num_samples += 1 | |||||
| index += 1 | |||||
| image = image.to(device) | |||||
| label = label.to(device).float() | |||||
| input_size = (1024, 1024) | |||||
| box = torch.tensor([[200, 200, 750, 800]]).to(device) | |||||
| low_res_masks = panc_sam_instance(image,box) | |||||
| low_res_label = F.interpolate(label, low_res_masks.shape[-2:]) | |||||
| dice = what_the_f(low_res_masks,low_res_label) | |||||
| binary_mask = normalize(threshold(low_res_masks, 0.0, 0)) | |||||
| total_dice += dice | |||||
| average_dice = total_dice / num_samples | |||||
| log_file.write(str(average_dice) + "\n") | |||||
| log_file.flush() | |||||
| loss = loss_function.forward(low_res_masks, low_res_label) | |||||
| loss /= accumaltive_batch_size / batch_size | |||||
| if train: | |||||
| loss.backward() | |||||
| if index % (accumaltive_batch_size / batch_size) == 0: | |||||
| # print(loss) | |||||
| optimizer.step() | |||||
| scheduler.step() | |||||
| optimizer.zero_grad() | |||||
| index = 0 | |||||
| else: | |||||
| pass | |||||
| if index % (accumaltive_batch_size / batch_size) == 0: | |||||
| epoch_losses.append(loss.item()) | |||||
| if counterb == sample_size and train: | |||||
| break | |||||
| elif counterb == sample_size / 10 and not train: | |||||
| break | |||||
| return epoch_losses, results, average_dice | |||||
| def train_model(train_loader, val_loader, K_fold=False, N_fold=7, epoch_num_start=7): | |||||
| print("Train model started.") | |||||
| train_losses = [] | |||||
| train_epochs = [] | |||||
| val_losses = [] | |||||
| val_epochs = [] | |||||
| dice = [] | |||||
| dice_val = [] | |||||
| results = [] | |||||
| index = 0 | |||||
| last_best_dice = 0 | |||||
| for epoch in range(num_epochs): | |||||
| print(f"=====================EPOCH: {epoch + 1}=====================") | |||||
| log_file.write( | |||||
| f"=====================EPOCH: {epoch + 1}===================\n" | |||||
| ) | |||||
| print("Training:") | |||||
| train_epoch_losses, epoch_results, average_dice = process_model( | |||||
| train_loader, train=1 | |||||
| ) | |||||
| dice.append(average_dice) | |||||
| train_losses.append(train_epoch_losses) | |||||
| if (average_dice) > 0.5: | |||||
| print("valing:") | |||||
| val_epoch_losses, epoch_results, average_dice_val = process_model( | |||||
| val_loader | |||||
| ) | |||||
| val_losses.append(val_epoch_losses) | |||||
| for i in tqdm(range(len(epoch_results[0]))): | |||||
| if not os.path.exists(f"ims/batch_{i}"): | |||||
| os.mkdir(f"ims/batch_{i}") | |||||
| save_img(epoch_results[0, i].clone(), f"ims/batch_{i}/prob_epoch_{epoch}.png") | |||||
| save_img(epoch_results[1, i].clone(), f"ims/batch_{i}/pred_epoch_{epoch}.png") | |||||
| train_mean_losses = [mean(x) for x in train_losses] | |||||
| # raise ValueError(average_dice) | |||||
| val_mean_losses = [mean(x) for x in val_losses] | |||||
| np.save("train_losses.npy", train_mean_losses) | |||||
| np.save("val_losses.npy", val_mean_losses) | |||||
| print(f"Train Dice: {average_dice}") | |||||
| print(f"Mean train loss: {mean(train_epoch_losses)}") | |||||
| try: | |||||
| dice_val.append(average_dice_val) | |||||
| print(f"val Dice : {average_dice_val}") | |||||
| print(f"Mean val loss: {mean(val_epoch_losses)}") | |||||
| results.append(epoch_results) | |||||
| val_epochs.append(epoch) | |||||
| train_epochs.append(epoch) | |||||
| plt.plot(val_epochs, val_mean_losses, train_epochs, train_mean_losses) | |||||
| print(last_best_dice) | |||||
| log_file.write(f'bestwieght:{last_best_dice}') | |||||
| if average_dice_val > last_best_dice: | |||||
| torch.save(panc_sam_instance, f"exps/{exp_id}-{user_input}/sam_tuned_save.pth") | |||||
| last_best_dice = average_dice_val | |||||
| del epoch_results | |||||
| del average_dice_val | |||||
| except: | |||||
| train_epochs.append(epoch) | |||||
| plt.plot(train_epochs, train_mean_losses) | |||||
| print(f"=================End of EPOCH: {epoch}==================\n") | |||||
| plt.yscale("log") | |||||
| plt.title("Mean epoch loss") | |||||
| plt.xlabel("Epoch Number") | |||||
| plt.ylabel("Loss") | |||||
| plt.savefig("result") | |||||
| return train_losses, val_losses, results | |||||
| train_losses, val_losses, results = train_model(train_loader, val_loader) | |||||
| log_file.close() | |||||
| # train and also val the model |
+ 36
- 0
args.py
View File
| import argparse | |||||
| def get_arguments(): | |||||
| parser = argparse.ArgumentParser(description="Your program's description here") | |||||
| parser.add_argument('--debug', action='store_true', help='Enable debug mode') | |||||
| parser.add_argument('--accumulative_batch_size', type=int, default=2, help='Accumulative batch size') | |||||
| parser.add_argument('--batch_size', type=int, default=1, help='Batch size') | |||||
| parser.add_argument('--num_workers', type=int, default=1, help='Number of workers') | |||||
| parser.add_argument('--slice_per_image', type=int, default=1, help='Slices per image') | |||||
| parser.add_argument('--num_epochs', type=int, default=40, help='Number of epochs') | |||||
| parser.add_argument('--sample_size', type=int, default=4, help='Sample size') | |||||
| parser.add_argument('--image_size', type=int, default=1024, help='Image size') | |||||
| parser.add_argument('--run_name', type=str, default='debug', help='The name of the run') | |||||
| parser.add_argument('--lr', type=float, default=1e-3, help='Learning Rate') | |||||
| parser.add_argument('--batch_step_one', type=int, default=15, help='Batch one') | |||||
| parser.add_argument('--batch_step_two', type=int, default=25, help='Batch two') | |||||
| parser.add_argument('--conv_model', type=str, default=None, help='Path to convolution model') | |||||
| parser.add_argument('--custom_bias', type=float, default=0, help='Learning Rate') | |||||
| parser.add_argument("--inference", action="store_true", help="Set for inference") | |||||
| ######################################################################################## | |||||
| parser.add_argument(" --promptprovider" , type=str , help="path weight of prompt provider") | |||||
| parser.add_argument(" --pointbasemodel" , type=str , help="path weight of prompt provider") | |||||
| parser.add_argument("--train_dir",type=str, help="Path to the training data") | |||||
| parser.add_argument("--test_dir",type=str, help="Path to the test data") | |||||
| parser.add_argument("--test_labels_dir",type=str, help="Path to the test data") | |||||
| parser.add_argument("--train_labels_dir",type=str, help="Path to the test data") | |||||
| parser.add_argument("--images_dir",type=str, help="Path to the test data") | |||||
| parser.add_argument("--checkpoint",type=str, help="Path to the test data") | |||||
| parser.add_argument("--model_type",type=str, help="Path to the test data",default="vit_h") | |||||
| return parser.parse_args() |
+ 291
- 0
data.py
View File
| import matplotlib.pyplot as plt | |||||
| import os | |||||
| import numpy as np | |||||
| import random | |||||
| from segment_anything.utils.transforms import ResizeLongestSide | |||||
| from einops import rearrange | |||||
| import torch | |||||
| from segment_anything import SamPredictor, sam_model_registry | |||||
| from torch.utils.data import DataLoader | |||||
| from time import time | |||||
| import torch.nn.functional as F | |||||
| import cv2 | |||||
| from PIL import Image | |||||
| import cv2 | |||||
| from kernel.pre_processer import PreProcessing | |||||
| def apply_median_filter(input_matrix, kernel_size=5, sigma=0): | |||||
| # Apply the Gaussian filter | |||||
| filtered_matrix = cv2.medianBlur(input_matrix.astype(np.uint8), kernel_size) | |||||
| return filtered_matrix.astype(np.float32) | |||||
| def apply_guassain_filter(input_matrix, kernel_size=(7, 7), sigma=0): | |||||
| smoothed_matrix = cv2.blur(input_matrix, kernel_size) | |||||
| return smoothed_matrix.astype(np.float32) | |||||
| def img_enhance(img2, over_coef=0.8, under_coef=0.7): | |||||
| img2 = apply_median_filter(img2) | |||||
| img_blure = apply_guassain_filter(img2) | |||||
| img2 = img2 - 0.8 * img_blure | |||||
| img_mean = np.mean(img2, axis=(1, 2)) | |||||
| img_max = np.amax(img2, axis=(1, 2)) | |||||
| val = (img_max - img_mean) * over_coef + img_mean | |||||
| img2 = (img2 < img_mean * under_coef).astype(np.float32) * img_mean * under_coef + ( | |||||
| (img2 >= img_mean * under_coef).astype(np.float32) | |||||
| ) * img2 | |||||
| img2 = (img2 <= val).astype(np.float32) * img2 + (img2 > val).astype( | |||||
| np.float32 | |||||
| ) * val | |||||
| return img2 | |||||
| def normalize_and_pad(x, img_size): | |||||
| """Normalize pixel values and pad to a square input.""" | |||||
| pixel_mean = torch.tensor([[[[123.675]], [[116.28]], [[103.53]]]]) | |||||
| pixel_std = torch.tensor([[[[58.395]], [[57.12]], [[57.375]]]]) | |||||
| # Normalize colors | |||||
| x = (x - pixel_mean) / pixel_std | |||||
| # Pad | |||||
| h, w = x.shape[-2:] | |||||
| padh = img_size - h | |||||
| padw = img_size - w | |||||
| x = F.pad(x, (0, padw, 0, padh)) | |||||
| return x | |||||
| def preprocess(img_enhanced, img_enhance_times=1, over_coef=0.4, under_coef=0.5): | |||||
| # img_enhanced = img_enhanced+0.1 | |||||
| img_enhanced -= torch.amin(img_enhanced, dim=(1, 2), keepdim=True) | |||||
| img_max = torch.amax(img_enhanced, axis=(1, 2), keepdims=True) | |||||
| img_max[img_max == 0] = 1 | |||||
| img_enhanced = img_enhanced / img_max | |||||
| # raise ValueError(img_max) | |||||
| img_enhanced = img_enhanced.unsqueeze(1) | |||||
| img_enhanced = PreProcessing.CLAHE(img_enhanced, clip_limit=9.0, grid_size=(4, 4)) | |||||
| img_enhanced = img_enhanced[0] | |||||
| # for i in range(img_enhance_times): | |||||
| # img_enhanced=img_enhance(img_enhanced.astype(np.float32), over_coef=over_coef,under_coef=under_coef) | |||||
| img_enhanced -= torch.amin(img_enhanced, dim=(1, 2), keepdim=True) | |||||
| larg_imag = ( | |||||
| img_enhanced / torch.amax(img_enhanced, axis=(1, 2), keepdims=True) * 255 | |||||
| ).type(torch.uint8) | |||||
| return larg_imag | |||||
| def prepare(larg_imag, target_image_size): | |||||
| # larg_imag = 255 - larg_imag | |||||
| larg_imag = rearrange(larg_imag, "S H W -> S 1 H W") | |||||
| larg_imag = torch.tensor( | |||||
| np.concatenate([larg_imag, larg_imag, larg_imag], axis=1) | |||||
| ).float() | |||||
| transform = ResizeLongestSide(target_image_size) | |||||
| larg_imag = transform.apply_image_torch(larg_imag) | |||||
| larg_imag = normalize_and_pad(larg_imag, target_image_size) | |||||
| return larg_imag | |||||
| def process_single_image(image_path, target_image_size): | |||||
| # Load the image | |||||
| if image_path.endswith(".png") or image_path.endswith(".jpg"): | |||||
| data = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE).squeeze() | |||||
| else: | |||||
| data = np.load(image_path) | |||||
| x = rearrange(data, "H W -> 1 H W") | |||||
| x = torch.tensor(x) | |||||
| # Apply preprocessing | |||||
| x = preprocess(x) | |||||
| x = prepare(x, target_image_size) | |||||
| return x | |||||
| class PanDataset: | |||||
| def __init__( | |||||
| self, | |||||
| images_dirs, | |||||
| labels_dirs, | |||||
| datasets, | |||||
| target_image_size, | |||||
| slice_per_image, | |||||
| train=True, | |||||
| ratio=0.9, | |||||
| augmentation=None, | |||||
| ): | |||||
| self.data_set_names = [] | |||||
| self.labels_path = [] | |||||
| self.images_path = [] | |||||
| for labels_dir, images_dir, dataset_name in zip( | |||||
| labels_dirs, images_dirs, datasets | |||||
| ): | |||||
| if train == True: | |||||
| self.data_set_names.extend( | |||||
| sorted([dataset_name[0] for _ in os.listdir(labels_dir)[:int(len(os.listdir(labels_dir)) * ratio)]]) | |||||
| ) | |||||
| self.labels_path.extend( | |||||
| sorted([os.path.join(labels_dir, item) for item in os.listdir(labels_dir)[:int(len(os.listdir(labels_dir)) * ratio)]]) | |||||
| ) | |||||
| self.images_path.extend( | |||||
| sorted([os.path.join(images_dir, item) for item in os.listdir(images_dir)[:int(len(os.listdir(images_dir)) * ratio)]]) | |||||
| ) | |||||
| else: | |||||
| self.data_set_names.extend( | |||||
| sorted([dataset_name[0] for _ in os.listdir(labels_dir)[int(len(os.listdir(labels_dir)) * ratio):]]) | |||||
| ) | |||||
| self.labels_path.extend( | |||||
| sorted([os.path.join(labels_dir, item) for item in os.listdir(labels_dir)[int(len(os.listdir(labels_dir)) * ratio):]]) | |||||
| ) | |||||
| self.images_path.extend( | |||||
| sorted([os.path.join(images_dir, item) for item in os.listdir(images_dir)[int(len(os.listdir(images_dir)) * ratio):]]) | |||||
| ) | |||||
| self.target_image_size = target_image_size | |||||
| self.datasets = datasets | |||||
| self.slice_per_image = slice_per_image | |||||
| self.augmentation = augmentation | |||||
| def __getitem__(self, idx): | |||||
| data = np.load(self.images_path[idx]) | |||||
| raw_data = data | |||||
| labels = np.load(self.labels_path[idx]) | |||||
| if self.data_set_names[idx] == "NIH_PNG": | |||||
| x = rearrange(data.T, "H W -> 1 H W") | |||||
| y = rearrange(labels.T, "H W -> 1 H W") | |||||
| y = (y == 1).astype(np.uint8) | |||||
| elif self.data_set_names[idx] == "Abdment1kPNG": | |||||
| x = rearrange(data, "H W -> 1 H W") | |||||
| y = rearrange(labels, "H W -> 1 H W") | |||||
| y = (y == 4).astype(np.uint8) | |||||
| else: | |||||
| raise ValueError("Incorect dataset name") | |||||
| x = torch.tensor(x) | |||||
| y = torch.tensor(y) | |||||
| x = preprocess(x) | |||||
| x, y = self.apply_augmentation(x.numpy(), y.numpy()) | |||||
| y = F.interpolate(y.unsqueeze(1), size=self.target_image_size) | |||||
| x = prepare(x, self.target_image_size) | |||||
| return x, y ,raw_data | |||||
| def collate_fn(self, data): | |||||
| images, labels , raw_data = zip(*data) | |||||
| images = torch.cat(images, dim=0) | |||||
| labels = torch.cat(labels, dim=0) | |||||
| # raw_data = torch.cat(raw_data, dim=0) | |||||
| return images, labels , raw_data | |||||
| def __len__(self): | |||||
| return len(self.images_path) | |||||
| def apply_augmentation(self, image, label): | |||||
| if self.augmentation: | |||||
| # If image and label are tensors, convert them to numpy arrays | |||||
| # raise ValueError(label.shape) | |||||
| augmented = self.augmentation(image=image[0], mask=label[0]) | |||||
| image = torch.tensor(augmented["image"]) | |||||
| label = torch.tensor(augmented["mask"]) | |||||
| # You might want to convert back to torch.Tensor after the transformation | |||||
| image = image.unsqueeze(0) | |||||
| label = label.unsqueeze(0) | |||||
| else: | |||||
| image = torch.Tensor(image) | |||||
| label = torch.Tensor(label) | |||||
| return image, label | |||||
| import albumentations as A | |||||
| if __name__ == "__main__": | |||||
| model_type = "vit_h" | |||||
| batch_size = 4 | |||||
| num_workers = 4 | |||||
| slice_per_image = 1 | |||||
| image_size = 1024 | |||||
| checkpoint = "checkpoints/sam_vit_h_4b8939.pth" | |||||
| panc_sam_instance = sam_model_registry[model_type](checkpoint=checkpoint) | |||||
| augmentation = A.Compose( | |||||
| [ | |||||
| A.Rotate(limit=10, p=0.5), | |||||
| A.RandomBrightnessContrast(brightness_limit=0.2, contrast_limit=0.2, p=1), | |||||
| A.RandomResizedCrop(1024, 1024, scale=(0.9, 1.0), p=1), | |||||
| ] | |||||
| ) | |||||
| train_dataset = PanDataset( | |||||
| "bath image", | |||||
| "bath label", | |||||
| image_size, | |||||
| slice_per_image=slice_per_image, | |||||
| train=True, | |||||
| augmentation=None, | |||||
| ) | |||||
| train_loader = DataLoader( | |||||
| train_dataset, | |||||
| batch_size=batch_size, | |||||
| collate_fn=train_dataset.collate_fn, | |||||
| shuffle=True, | |||||
| drop_last=False, | |||||
| num_workers=num_workers, | |||||
| ) | |||||
| # x, y = dataset[7] | |||||
| # print(x.shape, y.shape) | |||||
| now = time() | |||||
| for images, labels in train_loader: | |||||
| # pass | |||||
| image_numpy = images[0].permute(1, 2, 0).cpu().numpy() | |||||
| # Ensure that the values are in the correct range [0, 255] and cast to uint8 | |||||
| image_numpy = (image_numpy * 255).astype(np.uint8) | |||||
| # Save the image using OpenCV | |||||
| cv2.imwrite("image2.png", image_numpy[:, :, 1]) | |||||
| break | |||||
| # print((time() - now) / batch_size / slice_per_image) |
+ 166
- 0
data_handler/save.py
View File
| import matplotlib.pyplot as plt | |||||
| import os | |||||
| import numpy as np | |||||
| import random | |||||
| from segment_anything.utils.transforms import ResizeLongestSide | |||||
| from einops import rearrange | |||||
| import torch | |||||
| import os | |||||
| from segment_anything import SamPredictor, sam_model_registry | |||||
| from torch.utils.data import DataLoader | |||||
| from time import time | |||||
| import torch.nn.functional as F | |||||
| import cv2 | |||||
| # def preprocess(image_paths, label_paths): | |||||
| # preprocessed_images = [] | |||||
| # preprocessed_labels = [] | |||||
| # for image_path, label_path in zip(image_paths, label_paths): | |||||
| # # Load image and label from paths | |||||
| # image = plt.imread(image_path) | |||||
| # label = plt.imread(label_path) | |||||
| # # Perform preprocessing steps here | |||||
| # # ... | |||||
| # preprocessed_images.append(image) | |||||
| # preprocessed_labels.append(label) | |||||
| # return preprocessed_images, preprocessed_labels | |||||
| class PanDataset: | |||||
| def __init__(self, images_dir, labels_dir, slice_per_image, train=True,**kwargs): | |||||
| #for Abdonomial | |||||
| self.images_path = sorted([os.path.join(images_dir, item[:item.rindex('.')] + '_0000.npz') for item in os.listdir(labels_dir) if item.endswith('.npz') and not item.startswith('.')]) | |||||
| self.labels_path = sorted([os.path.join(labels_dir, item) for item in os.listdir(labels_dir) if item.endswith('.npz') and not item.startswith('.')]) | |||||
| #for NIH | |||||
| # self.images_path = sorted([os.path.join(images_dir, item) for item in os.listdir(labels_dir) if item.endswith('.npy')]) | |||||
| # self.labels_path = sorted([os.path.join(labels_dir, item) for item in os.listdir(labels_dir) if item.endswith('.npy')]) | |||||
| N = len(self.images_path) | |||||
| n = int(N * 0.8) | |||||
| self.train = train | |||||
| self.slice_per_image = slice_per_image | |||||
| if train: | |||||
| self.labels_path = self.labels_path[:n] | |||||
| self.images_path = self.images_path[:n] | |||||
| else: | |||||
| self.labels_path = self.labels_path[n:] | |||||
| self.images_path = self.images_path[n:] | |||||
| self.args=kwargs['args'] | |||||
| def __getitem__(self, idx): | |||||
| now = time() | |||||
| # for abdoment | |||||
| data = np.load(self.images_path[idx])['arr_0'] | |||||
| labels = np.load(self.labels_path[idx])['arr_0'] | |||||
| #for nih | |||||
| # data = np.load(self.images_path[idx]) | |||||
| # labels = np.load(self.labels_path[idx]) | |||||
| H, W, C = data.shape | |||||
| positive_slices = np.any(labels == 1, axis=(0, 1)) | |||||
| # print("Load from file time = ", time() - now) | |||||
| now = time() | |||||
| # Find the first and last positive slices | |||||
| first_positive_slice = np.argmax(positive_slices) | |||||
| last_positive_slice = labels.shape[2] - np.argmax(positive_slices[::-1]) - 1 | |||||
| dist=last_positive_slice-first_positive_slice | |||||
| if self.train: | |||||
| save_dir = self.args.images_dir # data address here | |||||
| labels_save_dir = self.args.labels_dir # label address here | |||||
| else : | |||||
| save_dir = self.args.test_images_dir # data address here | |||||
| labels_save_dir = self.args.test_labels_dir # label address here | |||||
| j=0 | |||||
| for j in range(1): | |||||
| slice = range(len(labels[0,0,:])) | |||||
| # raise ValueError(labels.shape) | |||||
| image_paths = [] | |||||
| label_paths = [] | |||||
| for i, slc_idx in enumerate(slice): | |||||
| # Saving Image Slices | |||||
| image_array = data[:, :, slc_idx] | |||||
| # Resize the array to 512x512 | |||||
| resized_image_array = cv2.resize(image_array, (512, 512)) | |||||
| min_val = resized_image_array.min() | |||||
| max_val = resized_image_array.max() | |||||
| normalized_image_array = ((resized_image_array - min_val) / (max_val - min_val) * 255).astype(np.uint8) | |||||
| image_paths.append(f"slice_{i}_{idx}.npy") | |||||
| if normalized_image_array.max()>0: | |||||
| np.save(os.path.join(save_dir, image_paths[-1]), normalized_image_array) | |||||
| # Saving Corresponding Label Slices | |||||
| label_array = labels[:, :, slc_idx] | |||||
| # Resize the array to 512x512 | |||||
| resized_label_array = cv2.resize(label_array, (512, 512)) | |||||
| min_val = resized_label_array.min() | |||||
| max_val = resized_label_array.max() | |||||
| # raise ValueError(np.unique(resized_label_array)) | |||||
| # normalized_label_array = ((resized_label_array - min_val) / (max_val - min_val) * 255).astype(np.uint8) | |||||
| label_paths.append(f"label_{i}_{idx}.npy") | |||||
| np.save(os.path.join(labels_save_dir, label_paths[-1]), resized_label_array) | |||||
| return data | |||||
| def collate_fn(self, data): | |||||
| return data | |||||
| def __len__(self): | |||||
| return len(self.images_path) | |||||
| if __name__ == '__main__': | |||||
| model_type = 'vit_b' | |||||
| batch_size = 4 | |||||
| num_workers = 4 | |||||
| slice_per_image = 1 | |||||
| dataset = PanDataset('../../Data/AbdomenCT-1K/numpy/images', '../../Data/AbdomenCT-1K/numpy/labels', | |||||
| slice_per_image=slice_per_image) | |||||
| # x, y = dataset[7] | |||||
| # # print(x.shape, y.shape) | |||||
| dataloader = DataLoader(dataset, batch_size=batch_size, collate_fn=dataset.collate_fn, shuffle=True, drop_last=False, num_workers=num_workers) | |||||
| now = time() | |||||
| for data in dataloader: | |||||
| # pass | |||||
| # print(images.shape, labels.shape) | |||||
| continue | |||||
| dataset = PanDataset(f'{args.train_dir}/numpy/images', f'{args.train_dir}/numpy/labels', | |||||
| train = False , slice_per_image=slice_per_image) | |||||
| # x, y = dataset[7] | |||||
| # # print(x.shape, y.shape) | |||||
| dataloader = DataLoader(dataset, batch_size=batch_size, collate_fn=dataset.collate_fn, shuffle=True, drop_last=False, num_workers=num_workers) | |||||
| now = time() | |||||
| for data in dataloader: | |||||
| # pass | |||||
| # print(images.shape, labels.shape) | |||||
| continue | |||||
+ 434
- 0
double_decoder_infrence.py
View File
| from pathlib import Path | |||||
| import numpy as np | |||||
| import matplotlib.pyplot as plt | |||||
| from utils import main_prompt , sample_prompt | |||||
| from collections import defaultdict | |||||
| import torchvision.transforms as transforms | |||||
| import torch | |||||
| from torch import nn | |||||
| import torch.nn.functional as F | |||||
| from segment_anything.utils.transforms import ResizeLongestSide | |||||
| import albumentations as A | |||||
| from albumentations.pytorch import ToTensorV2 | |||||
| from einops import rearrange | |||||
| import random | |||||
| from tqdm import tqdm | |||||
| from time import sleep | |||||
| from data import * | |||||
| from time import time | |||||
| from PIL import Image | |||||
| from sklearn.model_selection import KFold | |||||
| from shutil import copyfile | |||||
| from torch.nn.functional import threshold, normalize | |||||
| import torchvision.transforms.functional as TF | |||||
| from args import get_arguments | |||||
| args = get_arguments() | |||||
| def dice_coefficient(logits, gt): | |||||
| eps=1 | |||||
| binary_mask = logits>0 | |||||
| intersection = (binary_mask * gt).sum(dim=(-2,-1)) | |||||
| dice_scores = (2.0 * intersection + eps) / (binary_mask.sum(dim=(-2,-1)) + gt.sum(dim=(-2,-1)) + eps) | |||||
| return dice_scores.mean() | |||||
| def calculate_recall(pred, target): | |||||
| smooth = 1 | |||||
| batch_size = pred.shape[0] | |||||
| recall_scores = [] | |||||
| binary_mask = pred>0 | |||||
| for i in range(batch_size): | |||||
| true_positive = ((binary_mask[i] == 1) & (target[i] == 1)).sum().item() | |||||
| false_negative = ((binary_mask[i] == 0) & (target[i] == 1)).sum().item() | |||||
| recall = (true_positive + smooth) / ((true_positive + false_negative) + smooth) | |||||
| recall_scores.append(recall) | |||||
| return sum(recall_scores) / len(recall_scores) | |||||
| def calculate_precision(pred, target): | |||||
| smooth = 1 | |||||
| batch_size = pred.shape[0] | |||||
| precision_scores = [] | |||||
| binary_mask = pred>0 | |||||
| for i in range(batch_size): | |||||
| true_positive = ((binary_mask[i] == 1) & (target[i] == 1)).sum().item() | |||||
| false_positive = ((binary_mask[i] == 1) & (target[i] == 0)).sum().item() | |||||
| precision = (true_positive + smooth) / ((true_positive + false_positive) + smooth) | |||||
| precision_scores.append(precision) | |||||
| return sum(precision_scores) / len(precision_scores) | |||||
| def calculate_jaccard(pred, target): | |||||
| smooth = 1 | |||||
| batch_size = pred.shape[0] | |||||
| jaccard_scores = [] | |||||
| binary_mask = pred>0 | |||||
| for i in range(batch_size): | |||||
| true_positive = ((binary_mask[i] == 1) & (target[i] == 1)).sum().item() | |||||
| false_positive = ((binary_mask[i] == 1) & (target[i] == 0)).sum().item() | |||||
| false_negative = ((binary_mask[i] == 0) & (target[i] == 1)).sum().item() | |||||
| jaccard = (true_positive + smooth) / (true_positive + false_positive + false_negative + smooth) | |||||
| jaccard_scores.append(jaccard) | |||||
| return sum(jaccard_scores) / len(jaccard_scores) | |||||
| def calculate_specificity(pred, target): | |||||
| smooth = 1 | |||||
| batch_size = pred.shape[0] | |||||
| specificity_scores = [] | |||||
| binary_mask = pred>0 | |||||
| for i in range(batch_size): | |||||
| true_negative = ((binary_mask[i] == 0) & (target[i] == 0)).sum().item() | |||||
| false_positive = ((binary_mask[i] == 1) & (target[i] == 0)).sum().item() | |||||
| specificity = (true_negative + smooth) / (true_negative + false_positive + smooth) | |||||
| specificity_scores.append(specificity) | |||||
| return sum(specificity_scores) / len(specificity_scores) | |||||
| def what_the_f(low_res_masks,label): | |||||
| low_res_label = F.interpolate(label, low_res_masks.shape[-2:]) | |||||
| dice = dice_coefficient( | |||||
| low_res_masks, low_res_label | |||||
| ) | |||||
| recall=calculate_recall(low_res_masks, low_res_label) | |||||
| precision =calculate_precision(low_res_masks, low_res_label) | |||||
| jaccard = calculate_jaccard(low_res_masks, low_res_label) | |||||
| return dice , precision , recall , jaccard | |||||
| def save_img(img, dir): | |||||
| img = img.clone().cpu().numpy() | |||||
| if len(img.shape) == 3: | |||||
| img = rearrange(img, "c h w -> h w c") | |||||
| img_min = np.amin(img, axis=(0, 1), keepdims=True) | |||||
| img = img - img_min | |||||
| img_max = np.amax(img, axis=(0, 1), keepdims=True) | |||||
| img = (img / img_max * 255).astype(np.uint8) | |||||
| img = Image.fromarray(img) | |||||
| else: | |||||
| img_min = img.min() | |||||
| img = img - img_min | |||||
| img_max = img.max() | |||||
| if img_max != 0: | |||||
| img = img / img_max * 255 | |||||
| img = Image.fromarray(img).convert("L") | |||||
| img.save(dir) | |||||
| slice_per_image = 1 | |||||
| image_size = 1024 | |||||
| class panc_sam(nn.Module): | |||||
| def __init__(self, *args, **kwargs) -> None: | |||||
| super().__init__(*args, **kwargs) | |||||
| #Promptless | |||||
| sam = torch.load("sam_tuned_save.pth").sam | |||||
| self.prompt_encoder = sam.prompt_encoder | |||||
| self.mask_decoder = sam.mask_decoder | |||||
| for param in self.prompt_encoder.parameters(): | |||||
| param.requires_grad = False | |||||
| for param in self.mask_decoder.parameters(): | |||||
| param.requires_grad = False | |||||
| #with Prompt | |||||
| sam=sam_model_registry[model_type](checkpoint=checkpoint) | |||||
| # sam = torch.load( | |||||
| # "sam_tuned_save.pth" | |||||
| # ).sam | |||||
| self.image_encoder = sam.image_encoder | |||||
| self.prompt_encoder2 = sam.prompt_encoder | |||||
| self.mask_decoder2 = sam.mask_decoder | |||||
| for param in self.image_encoder.parameters(): | |||||
| param.requires_grad = False | |||||
| for param in self.prompt_encoder2.parameters(): | |||||
| param.requires_grad = False | |||||
| def forward(self, input_images,box=None): | |||||
| # input_images = torch.stack([x["image"] for x in batched_input], dim=0) | |||||
| with torch.no_grad(): | |||||
| image_embeddings = self.image_encoder(input_images).detach() | |||||
| outputs_prompt = [] | |||||
| outputs = [] | |||||
| for curr_embedding in image_embeddings: | |||||
| with torch.no_grad(): | |||||
| sparse_embeddings, dense_embeddings = self.prompt_encoder( | |||||
| points=None, | |||||
| boxes=None, | |||||
| masks=None, | |||||
| ) | |||||
| low_res_masks, _ = self.mask_decoder( | |||||
| image_embeddings=curr_embedding, | |||||
| image_pe=self.prompt_encoder.get_dense_pe().detach(), | |||||
| sparse_prompt_embeddings=sparse_embeddings.detach(), | |||||
| dense_prompt_embeddings=dense_embeddings.detach(), | |||||
| multimask_output=False, | |||||
| ) | |||||
| outputs_prompt.append(low_res_masks) | |||||
| # points, point_labels = sample_prompt((low_res_masks > 0).float()) | |||||
| points, point_labels = main_prompt(low_res_masks) | |||||
| points = points * 4 | |||||
| points = (points, point_labels) | |||||
| with torch.no_grad(): | |||||
| sparse_embeddings, dense_embeddings = self.prompt_encoder2( | |||||
| points=points, | |||||
| boxes=None, | |||||
| masks=None, | |||||
| ) | |||||
| low_res_masks, _ = self.mask_decoder2( | |||||
| image_embeddings=curr_embedding, | |||||
| image_pe=self.prompt_encoder2.get_dense_pe().detach(), | |||||
| sparse_prompt_embeddings=sparse_embeddings.detach(), | |||||
| dense_prompt_embeddings=dense_embeddings.detach(), | |||||
| multimask_output=False, | |||||
| ) | |||||
| outputs.append(low_res_masks) | |||||
| low_res_masks_promtp = torch.cat(outputs_prompt, dim=0) | |||||
| low_res_masks = torch.cat(outputs, dim=0) | |||||
| return low_res_masks, low_res_masks_promtp | |||||
| test_dataset = PanDataset( | |||||
| [ | |||||
| args.test_dir | |||||
| ], | |||||
| [ | |||||
| args.test_labels_dir | |||||
| ], | |||||
| [["NIH_PNG",1]], | |||||
| image_size, | |||||
| slice_per_image=slice_per_image, | |||||
| train=False, | |||||
| ) | |||||
| device = "cuda:0" | |||||
| x = torch.load('sam_tuned_save.pth', map_location='cpu') | |||||
| # raise ValueError(x) | |||||
| x.to(device) | |||||
| # num_samples = 0 | |||||
| # counterb=0 | |||||
| # index=0 | |||||
| # for image, label in tqdm(test_dataset, total=len(test_dataset)): | |||||
| # num_samples += 1 | |||||
| # counterb += 1 | |||||
| # index += 1 | |||||
| # image = image.to(device) | |||||
| # label = label.to(device).float() | |||||
| # ############################model and dice######################################## | |||||
| # box = torch.tensor([[200, 200, 750, 800]]).to(device) | |||||
| # low_res_masks_main,low_res_masks_prompt = x(image,box) | |||||
| def process_model(main_model , test_dataset, train=0, save_output=0): | |||||
| epoch_losses = [] | |||||
| results=[] | |||||
| results_prompt=[] | |||||
| index = 0 | |||||
| results = torch.zeros((2, 0, 256, 256)) | |||||
| results_prompt = torch.zeros((2, 0, 256, 256)) | |||||
| ############################# | |||||
| total_dice = 0.0 | |||||
| total_precision = 0.0 | |||||
| total_recall =0.0 | |||||
| total_jaccard = 0.0 | |||||
| ############################# | |||||
| num_samples = 0 | |||||
| ############################# | |||||
| total_dice_main =0.0 | |||||
| total_precision_main = 0.0 | |||||
| total_recall_main =0.0 | |||||
| total_jaccard_main = 0.0 | |||||
| counterb = 0 | |||||
| for image, label , raw_data in tqdm(test_dataset, total=len(test_dataset)): | |||||
| # raise ValueError(image.shape , label.shape , raw_data.shape) | |||||
| num_samples += 1 | |||||
| counterb += 1 | |||||
| index += 1 | |||||
| image = image.to(device) | |||||
| label = label.to(device).float() | |||||
| ############################model and dice######################################## | |||||
| box = torch.tensor([[200, 200, 750, 800]]).to(device) | |||||
| low_res_masks_main,low_res_masks_prompt = main_model(image,box) | |||||
| low_res_label = F.interpolate(label, low_res_masks_main.shape[-2:]) | |||||
| dice_prompt, precisio_prompt , recall_prompt , jaccard_prompt = what_the_f(low_res_masks_prompt,low_res_label) | |||||
| dice_main , precision_main , recall_main , jaccard_main = what_the_f(low_res_masks_main,low_res_label) | |||||
| # binary_mask = normalize(threshold(low_res_masks_main, 0.0,0)) | |||||
| ##############prompt############### | |||||
| total_dice += dice_prompt | |||||
| total_precision += precisio_prompt | |||||
| total_recall += recall_prompt | |||||
| total_jaccard += jaccard_prompt | |||||
| average_dice = total_dice / num_samples | |||||
| average_precision = total_precision /num_samples | |||||
| average_recall = total_recall /num_samples | |||||
| average_jaccard = total_jaccard /num_samples | |||||
| ##############main################## | |||||
| total_dice_main+=dice_main | |||||
| total_precision_main +=precision_main | |||||
| total_recall_main +=recall_main | |||||
| total_jaccard_main += jaccard_main | |||||
| average_dice_main = total_dice_main / num_samples | |||||
| average_precision_main = total_precision_main /num_samples | |||||
| average_recall_main = total_recall_main /num_samples | |||||
| average_jaccard_main = total_jaccard_main /num_samples | |||||
| binary_mask = normalize(threshold(low_res_masks_main, 0.0,0)) | |||||
| binary_mask_mask = normalize(threshold(low_res_masks_prompt, 0.0,0)) | |||||
| ################################### | |||||
| result = torch.cat( | |||||
| ( | |||||
| low_res_masks_main[0].detach().cpu().reshape(1, 1, 256, 256), | |||||
| binary_mask[0].detach().cpu().reshape(1, 1, 256, 256), | |||||
| ), | |||||
| dim=0, | |||||
| ) | |||||
| results = torch.cat((results, result), dim=1) | |||||
| result_prompt = torch.cat( | |||||
| ( | |||||
| low_res_masks_prompt[0].detach().cpu().reshape(1, 1, 256, 256), | |||||
| binary_mask_mask[0].detach().cpu().reshape(1, 1, 256, 256), | |||||
| ), | |||||
| dim=0, | |||||
| ) | |||||
| results_prompt = torch.cat((results_prompt, result_prompt), dim=1) | |||||
| # if counterb == len(test_dataset)-5: | |||||
| # break | |||||
| if counterb == 200: | |||||
| break | |||||
| # elif counterb == sample_size and not train: | |||||
| # break | |||||
| return epoch_losses, results,results_prompt, average_dice,average_precision ,average_recall, average_jaccard,average_dice_main,average_precision_main,average_recall_main,average_jaccard_main | |||||
| print("Testing:") | |||||
| test_epoch_losses, epoch_results , results_prompt, average_dice_test,average_precision ,average_recall, average_jaccard,average_dice_test_main,average_precision_main,average_recall_main,average_jaccard_main = process_model( | |||||
| x,test_dataset | |||||
| ) | |||||
| # raise ValueError(len(epoch_results[0])) | |||||
| train_losses = [] | |||||
| train_epochs = [] | |||||
| test_losses = [] | |||||
| test_epochs = [] | |||||
| dice = [] | |||||
| dice_main = [] | |||||
| dice_test = [] | |||||
| dice_test_main =[] | |||||
| results = [] | |||||
| index = 0 | |||||
| ##############################save image######################################### | |||||
| for image, label , raw_data in tqdm(test_dataset): | |||||
| if index < 200: | |||||
| if not os.path.exists(f"result_img/batch_{index}"): | |||||
| os.mkdir(f"result_img/batch_{index}") | |||||
| save_img( | |||||
| image[0], | |||||
| f"result_img/batch_{index}/img.png", | |||||
| ) | |||||
| tensor_raw = torch.tensor(raw_data) | |||||
| save_img( | |||||
| tensor_raw.T, | |||||
| f"result_img/batch_{index}/raw_img.png", | |||||
| ) | |||||
| model_result_resized = TF.resize(epoch_results, size=(1024, 1024)) | |||||
| result_canvas = torch.zeros_like(image[0]) | |||||
| result_canvas[1] = label[0][0] | |||||
| result_canvas[0] = model_result_resized[1, index] | |||||
| blended_result = 0.2 * image[0] + 0.5 * result_canvas | |||||
| ################################################################### | |||||
| model_result_resized_prompt = TF.resize(results_prompt, size=(1024, 1024)) | |||||
| result_canvas_prompt = torch.zeros_like(image[0]) | |||||
| result_canvas_prompt[1] = label[0][0] | |||||
| # raise ValueError(model_result_resized_prompt.shape ,model_result_resized.shape ) | |||||
| result_canvas_prompt[0] = model_result_resized_prompt[1, index] | |||||
| blended_result_prompt = 0.2 * image[0] + 0.5 * result_canvas_prompt | |||||
| save_img(blended_result, f"result_img/batch_{index}/comb.png") | |||||
| save_img(blended_result_prompt, f"result_img/batch_{index}/comb_prompt.png") | |||||
| save_img( | |||||
| epoch_results[1, index].clone(),f"result_img/batch_{index}/modelresult.png", | |||||
| ) | |||||
| save_img( | |||||
| epoch_results[0, index].clone(),f"result_img/batch_{index}/prob_epoch_{index}.png",) | |||||
| index += 1 | |||||
| if index == 200: | |||||
| break | |||||
| dice_test.append(average_dice_test) | |||||
| dice_test_main.append(average_dice_test_main) | |||||
| print("######################Prompt##########################") | |||||
| print(f"Test Dice : {average_dice_test}") | |||||
| print(f"Test presision : {average_precision}") | |||||
| print(f"Test recall : {average_recall}") | |||||
| print(f"Test jaccard : {average_jaccard}") | |||||
| print("######################Main##########################") | |||||
| print(f"Test Dice main : {average_dice_test_main}") | |||||
| print(f"Test presision main : {average_precision_main}") | |||||
| print(f"Test recall main : {average_recall_main}") | |||||
| print(f"Test jaccard main : {average_jaccard_main}") | |||||
+ 541
- 0
fine_tune_good.py
View File
| debug = 0 | |||||
| from pathlib import Path | |||||
| import numpy as np | |||||
| import matplotlib.pyplot as plt | |||||
| from utils import sample_prompt , main_prompt | |||||
| from collections import defaultdict | |||||
| import torchvision.transforms as transforms | |||||
| import torch | |||||
| from torch import nn | |||||
| import torch.nn.functional as F | |||||
| from segment_anything.utils.transforms import ResizeLongestSide | |||||
| import albumentations as A | |||||
| from albumentations.pytorch import ToTensorV2 | |||||
| import numpy as np | |||||
| from einops import rearrange | |||||
| import random | |||||
| from tqdm import tqdm | |||||
| from time import sleep | |||||
| from data import * | |||||
| from time import time | |||||
| from PIL import Image | |||||
| from sklearn.model_selection import KFold | |||||
| from shutil import copyfile | |||||
| from args import get_arguments | |||||
| args = get_arguments() | |||||
| def save_img(img, dir): | |||||
| img = img.clone().cpu().numpy() + 100 | |||||
| if len(img.shape) == 3: | |||||
| img = rearrange(img, "c h w -> h w c") | |||||
| img_min = np.amin(img, axis=(0, 1), keepdims=True) | |||||
| img = img - img_min | |||||
| img_max = np.amax(img, axis=(0, 1), keepdims=True) | |||||
| img = (img / img_max * 255).astype(np.uint8) | |||||
| # grey_img = Image.fromarray(img[:, :, 0]) | |||||
| img = Image.fromarray(img) | |||||
| else: | |||||
| img_min = img.min() | |||||
| img = img - img_min | |||||
| img_max = img.max() | |||||
| if img_max != 0: | |||||
| img = img / img_max * 255 | |||||
| img = Image.fromarray(img).convert("L") | |||||
| img.save(dir) | |||||
| class loss_fn(torch.nn.Module): | |||||
| def __init__(self, alpha=0.7, gamma=2.0, epsilon=1e-5): | |||||
| super(loss_fn, self).__init__() | |||||
| self.alpha = alpha | |||||
| self.gamma = gamma | |||||
| self.epsilon = epsilon | |||||
| def tversky_loss(self, y_pred, y_true, alpha=0.8, beta=0.2, smooth=1e-2): | |||||
| y_pred = torch.sigmoid(y_pred) | |||||
| y_true_pos = torch.flatten(y_true) | |||||
| y_pred_pos = torch.flatten(y_pred) | |||||
| true_pos = torch.sum(y_true_pos * y_pred_pos) | |||||
| false_neg = torch.sum(y_true_pos * (1 - y_pred_pos)) | |||||
| false_pos = torch.sum((1 - y_true_pos) * y_pred_pos) | |||||
| tversky_index = (true_pos + smooth) / ( | |||||
| true_pos + alpha * false_neg + beta * false_pos + smooth | |||||
| ) | |||||
| return 1 - tversky_index | |||||
| def focal_tversky(self, y_pred, y_true, gamma=0.75): | |||||
| pt_1 = self.tversky_loss(y_pred, y_true) | |||||
| return torch.pow((1 - pt_1), gamma) | |||||
| def dice_loss(self, logits, gt, eps=1): | |||||
| # Convert logits to probabilities | |||||
| # Flatten the tensorsx | |||||
| probs = torch.sigmoid(logits) | |||||
| probs = probs.view(-1) | |||||
| gt = gt.view(-1) | |||||
| # Compute Dice coefficient | |||||
| intersection = (probs * gt).sum() | |||||
| dice_coeff = (2.0 * intersection + eps) / (probs.sum() + gt.sum() + eps) | |||||
| # Compute Dice Los[s | |||||
| loss = 1 - dice_coeff | |||||
| return loss | |||||
| def focal_loss(self, logits, gt, gamma=2): | |||||
| logits = logits.reshape(-1, 1) | |||||
| gt = gt.reshape(-1, 1) | |||||
| logits = torch.cat((1 - logits, logits), dim=1) | |||||
| probs = torch.sigmoid(logits) | |||||
| pt = probs.gather(1, gt.long()) | |||||
| modulating_factor = (1 - pt) ** gamma | |||||
| # pt_false= pt<=0.5 | |||||
| # modulating_factor[pt_false] *= 2 | |||||
| focal_loss = -modulating_factor * torch.log(pt + 1e-12) | |||||
| # Compute the mean focal loss | |||||
| loss = focal_loss.mean() | |||||
| return loss # Store as a Python number to save memory | |||||
| def forward(self, logits, target): | |||||
| logits = logits.squeeze(1) | |||||
| target = target.squeeze(1) | |||||
| # Dice Loss | |||||
| # prob = F.softmax(logits, dim=1)[:, 1, ...] | |||||
| dice_loss = self.dice_loss(logits, target) | |||||
| tversky_loss = self.tversky_loss(logits, target) | |||||
| # Focal Loss | |||||
| focal_loss = self.focal_loss(logits, target.squeeze(-1)) | |||||
| alpha = 20.0 | |||||
| # Combined Loss | |||||
| combined_loss = alpha * focal_loss + dice_loss | |||||
| return combined_loss | |||||
| def img_enhance(img2, coef=0.2): | |||||
| img_mean = np.mean(img2) | |||||
| img_max = np.max(img2) | |||||
| val = (img_max - img_mean) * coef + img_mean | |||||
| img2[img2 < img_mean * 0.7] = img_mean * 0.7 | |||||
| img2[img2 > val] = val | |||||
| return img2 | |||||
| def dice_coefficient(logits, gt): | |||||
| eps=1 | |||||
| binary_mask = logits>0 | |||||
| intersection = (binary_mask * gt).sum(dim=(-2,-1)) | |||||
| dice_scores = (2.0 * intersection + eps) / (binary_mask.sum(dim=(-2,-1)) + gt.sum(dim=(-2,-1)) + eps) | |||||
| return dice_scores.mean() | |||||
| def what_the_f(low_res_masks,label): | |||||
| low_res_label = F.interpolate(label, low_res_masks.shape[-2:]) | |||||
| dice = dice_coefficient( | |||||
| low_res_masks, low_res_label | |||||
| ) | |||||
| return dice | |||||
| image_size = args.image_size | |||||
| exp_id = 0 | |||||
| found = 0 | |||||
| if debug: | |||||
| user_input='debug' | |||||
| else: | |||||
| user_input = input("Related changes: ") | |||||
| while found == 0: | |||||
| try: | |||||
| os.makedirs(f"exps/{exp_id}-{user_input}") | |||||
| found = 1 | |||||
| except: | |||||
| exp_id = exp_id + 1 | |||||
| copyfile(os.path.realpath(__file__), f"exps/{exp_id}-{user_input}/code.py") | |||||
| layer_n = 4 | |||||
| L = layer_n | |||||
| a = np.full(L, layer_n) | |||||
| params = {"M": 255, "a": a, "p": 0.35} | |||||
| device = "cuda:1" | |||||
| from segment_anything import SamPredictor, sam_model_registry | |||||
| class panc_sam(nn.Module): | |||||
| def __init__(self, *args, **kwargs) -> None: | |||||
| super().__init__(*args, **kwargs) | |||||
| #Promptless | |||||
| sam = torch.load(args.promptprovider) | |||||
| self.prompt_encoder = sam.prompt_encoder | |||||
| self.mask_decoder = sam.mask_decoder | |||||
| for param in self.prompt_encoder.parameters(): | |||||
| param.requires_grad = False | |||||
| for param in self.mask_decoder.parameters(): | |||||
| param.requires_grad = False | |||||
| #with Prompt | |||||
| sam=sam_model_registry[args.model_type](args.checkpoint) | |||||
| self.image_encoder = sam.image_encoder | |||||
| self.prompt_encoder2 = sam.prompt_encoder | |||||
| self.mask_decoder2 = sam.mask_decoder | |||||
| for param in self.image_encoder.parameters(): | |||||
| param.requires_grad = False | |||||
| for param in self.prompt_encoder2.parameters(): | |||||
| param.requires_grad = False | |||||
| def forward(self, input_images,box=None): | |||||
| # input_images = torch.stack([x["image"] for x in batched_input], dim=0) | |||||
| with torch.no_grad(): | |||||
| image_embeddings = self.image_encoder(input_images).detach() | |||||
| outputs_prompt = [] | |||||
| outputs = [] | |||||
| for curr_embedding in image_embeddings: | |||||
| with torch.no_grad(): | |||||
| sparse_embeddings, dense_embeddings = self.prompt_encoder( | |||||
| points=None, | |||||
| boxes=None, | |||||
| masks=None, | |||||
| ) | |||||
| low_res_masks, _ = self.mask_decoder( | |||||
| image_embeddings=curr_embedding, | |||||
| image_pe=self.prompt_encoder.get_dense_pe().detach(), | |||||
| sparse_prompt_embeddings=sparse_embeddings.detach(), | |||||
| dense_prompt_embeddings=dense_embeddings.detach(), | |||||
| multimask_output=False, | |||||
| ) | |||||
| outputs_prompt.append(low_res_masks) | |||||
| points, point_labels = main_prompt(low_res_masks) | |||||
| points_sconed, point_labels_sconed = sample_prompt(low_res_masks) | |||||
| points = torch.cat([points, points_sconed], dim=1) # Adjust dimensions as necessary | |||||
| point_labels = torch.cat([point_labels, point_labels_sconed], dim=1) | |||||
| points = points * 4 | |||||
| points = (points, point_labels) | |||||
| with torch.no_grad(): | |||||
| sparse_embeddings, dense_embeddings = self.prompt_encoder2( | |||||
| points=points, | |||||
| boxes=None, | |||||
| masks=None, | |||||
| ) | |||||
| low_res_masks, _ = self.mask_decoder2( | |||||
| image_embeddings=curr_embedding, | |||||
| image_pe=self.prompt_encoder2.get_dense_pe().detach(), | |||||
| sparse_prompt_embeddings=sparse_embeddings.detach(), | |||||
| dense_prompt_embeddings=dense_embeddings.detach(), | |||||
| multimask_output=False, | |||||
| ) | |||||
| outputs.append(low_res_masks) | |||||
| low_res_masks_promtp = torch.cat(outputs_prompt, dim=0) | |||||
| low_res_masks = torch.cat(outputs, dim=0) | |||||
| return low_res_masks, low_res_masks_promtp | |||||
| augmentation = A.Compose( | |||||
| [ | |||||
| A.Rotate(limit=30, p=0.5), | |||||
| A.RandomBrightnessContrast(brightness_limit=0.3, contrast_limit=0.3, p=1), | |||||
| A.RandomResizedCrop(1024, 1024, scale=(0.9, 1.0), p=1), | |||||
| A.HorizontalFlip(p=0.5), | |||||
| A.CLAHE(clip_limit=2.0, tile_grid_size=(8, 8), p=0.5), | |||||
| A.CoarseDropout( | |||||
| max_holes=8, | |||||
| max_height=16, | |||||
| max_width=16, | |||||
| min_height=8, | |||||
| min_width=8, | |||||
| fill_value=0, | |||||
| p=0.5, | |||||
| ), | |||||
| A.RandomScale(scale_limit=0.3, p=0.5), | |||||
| ] | |||||
| ) | |||||
| panc_sam_instance = panc_sam() | |||||
| panc_sam_instance.to(device) | |||||
| panc_sam_instance.train() | |||||
| train_dataset = PanDataset( | |||||
| [args.dir_train], | |||||
| [args.dir_labels], | |||||
| [["NIH_PNG",1]], | |||||
| args.image_size, | |||||
| slice_per_image=args.slice_per_image, | |||||
| train=True, | |||||
| augmentation=augmentation, | |||||
| ) | |||||
| val_dataset = PanDataset( | |||||
| [args.dir_train], | |||||
| [args.dir_labels], | |||||
| [["NIH_PNG",1]], | |||||
| image_size, | |||||
| slice_per_image=args.slice_per_image, | |||||
| train=False, | |||||
| ) | |||||
| train_loader = DataLoader( | |||||
| train_dataset, | |||||
| batch_size=args.batch_size, | |||||
| collate_fn=train_dataset.collate_fn, | |||||
| shuffle=True, | |||||
| drop_last=False, | |||||
| num_workers=args.num_workers, | |||||
| ) | |||||
| val_loader = DataLoader( | |||||
| val_dataset, | |||||
| batch_size=args.batch_size, | |||||
| collate_fn=val_dataset.collate_fn, | |||||
| shuffle=True, | |||||
| drop_last=False, | |||||
| num_workers=args.num_workers, | |||||
| ) | |||||
| lr = 1e-4 | |||||
| #1e-3 | |||||
| max_lr = 3e-4 | |||||
| wd = 5e-4 | |||||
| optimizer_main = torch.optim.Adam( | |||||
| # parameters, | |||||
| list(panc_sam_instance.mask_decoder2.parameters()), | |||||
| lr=lr, | |||||
| weight_decay=wd, | |||||
| ) | |||||
| scheduler_main = torch.optim.lr_scheduler.OneCycleLR( | |||||
| optimizer_main, | |||||
| max_lr=max_lr, | |||||
| epochs=args.num_epochs, | |||||
| steps_per_epoch=args.sample_size // (args.accumulative_batch_size // args.batch_size), | |||||
| ) | |||||
| ##################################################### | |||||
| from statistics import mean | |||||
| from tqdm import tqdm | |||||
| from torch.nn.functional import threshold, normalize | |||||
| loss_function = loss_fn(alpha=0.5, gamma=4.0) | |||||
| loss_function.to(device) | |||||
| from time import time | |||||
| import time as s_time | |||||
| log_file = open(f"exps/{exp_id}-{user_input}/log.txt", "a") | |||||
| def process_model(main_model , data_loader, train=0, save_output=0): | |||||
| epoch_losses = [] | |||||
| index = 0 | |||||
| results = torch.zeros((2, 0, 256, 256)) | |||||
| total_dice = 0.0 | |||||
| num_samples = 0 | |||||
| total_dice_main =0.0 | |||||
| counterb = 0 | |||||
| for image, label,raw_data in tqdm(data_loader, total=args.sample_size): | |||||
| num_samples += 1 | |||||
| counterb += 1 | |||||
| index += 1 | |||||
| image = image.to(device) | |||||
| label = label.to(device).float() | |||||
| ############################promt######################################## | |||||
| box = torch.tensor([[200, 200, 750, 800]]).to(device) | |||||
| low_res_masks_main,low_res_masks_prompt = main_model(image,box) | |||||
| low_res_label = F.interpolate(label, low_res_masks_main.shape[-2:]) | |||||
| dice_prompt = what_the_f(low_res_masks_prompt,low_res_label) | |||||
| dice_main = what_the_f(low_res_masks_main,low_res_label) | |||||
| binary_mask = normalize(threshold(low_res_masks_main, 0.0,0)) | |||||
| total_dice += dice_prompt | |||||
| total_dice_main+=dice_main | |||||
| average_dice = total_dice / num_samples | |||||
| average_dice_main = total_dice_main / num_samples | |||||
| log_file.write(str(average_dice) + "\n") | |||||
| log_file.flush() | |||||
| loss = loss_function.forward(low_res_masks_main, low_res_label) | |||||
| loss /= args.accumulative_batch_size / args.batch_size | |||||
| if train: | |||||
| loss.backward() | |||||
| if index % (args.accumulative_batch_size / args.batch_size) == 0: | |||||
| # print(loss) | |||||
| optimizer_main.step() | |||||
| scheduler_main.step() | |||||
| optimizer_main.zero_grad() | |||||
| index = 0 | |||||
| else: | |||||
| result = torch.cat( | |||||
| ( | |||||
| low_res_masks_main[0].detach().cpu().reshape(1, 1, 256, 256), | |||||
| binary_mask[0].detach().cpu().reshape(1, 1, 256, 256), | |||||
| ), | |||||
| dim=0, | |||||
| ) | |||||
| results = torch.cat((results, result), dim=1) | |||||
| if index % (args.accumulative_batch_size / args.batch_size) == 0: | |||||
| epoch_losses.append(loss.item()) | |||||
| if counterb == args.sample_size and train: | |||||
| break | |||||
| elif counterb == args.sample_size //2 and not train: | |||||
| break | |||||
| return epoch_losses, results, average_dice ,average_dice_main | |||||
| def train_model(train_loader, val_loader, K_fold=False, N_fold=7, epoch_num_start=7): | |||||
| print("Train model started.") | |||||
| train_losses = [] | |||||
| train_epochs = [] | |||||
| val_losses = [] | |||||
| val_epochs = [] | |||||
| dice = [] | |||||
| dice_main = [] | |||||
| dice_val = [] | |||||
| dice_val_main =[] | |||||
| results = [] | |||||
| #########################save image################################## | |||||
| index = 0 | |||||
| if debug==0: | |||||
| for image, label , raw_data in tqdm(val_loader): | |||||
| if index < 100: | |||||
| if not os.path.exists(f"ims/batch_{index}"): | |||||
| os.mkdir(f"ims/batch_{index}") | |||||
| save_img( | |||||
| image[0], | |||||
| f"ims/batch_{index}/img_0.png", | |||||
| ) | |||||
| save_img(0.2 * image[0][0] + label[0][0], f"ims/batch_{index}/gt_0.png") | |||||
| index += 1 | |||||
| if index == 100: | |||||
| break | |||||
| # In each epoch we will train the model and the val it | |||||
| # training without k_fold cross validation: | |||||
| last_best_dice = 0 | |||||
| if K_fold == False: | |||||
| for epoch in range(args.num_epochs): | |||||
| print(f"=====================EPOCH: {epoch + 1}=====================") | |||||
| log_file.write( | |||||
| f"=====================EPOCH: {epoch + 1}===================\n" | |||||
| ) | |||||
| print("Training:") | |||||
| train_epoch_losses, epoch_results, average_dice ,average_dice_main = process_model(panc_sam_instance,train_loader, train=1) | |||||
| dice.append(average_dice) | |||||
| dice_main.append(average_dice_main) | |||||
| train_losses.append(train_epoch_losses) | |||||
| if (average_dice) > 0.5: | |||||
| print("validating:") | |||||
| val_epoch_losses, epoch_results, average_dice_val,average_dice_val_main = process_model( | |||||
| panc_sam_instance,val_loader | |||||
| ) | |||||
| val_losses.append(val_epoch_losses) | |||||
| for i in tqdm(range(len(epoch_results[0]))): | |||||
| if not os.path.exists(f"ims/batch_{i}"): | |||||
| os.mkdir(f"ims/batch_{i}") | |||||
| save_img( | |||||
| epoch_results[0, i].clone(), | |||||
| f"ims/batch_{i}/prob_epoch_{epoch}.png", | |||||
| ) | |||||
| save_img( | |||||
| epoch_results[1, i].clone(), | |||||
| f"ims/batch_{i}/pred_epoch_{epoch}.png", | |||||
| ) | |||||
| train_mean_losses = [mean(x) for x in train_losses] | |||||
| val_mean_losses = [mean(x) for x in val_losses] | |||||
| np.save("train_losses.npy", train_mean_losses) | |||||
| np.save("val_losses.npy", val_mean_losses) | |||||
| print(f"Train Dice: {average_dice}") | |||||
| print(f"Train Dice main: {average_dice_main}") | |||||
| print(f"Mean train loss: {mean(train_epoch_losses)}") | |||||
| try: | |||||
| dice_val.append(average_dice_val) | |||||
| dice_val_main.append(average_dice_val_main) | |||||
| print(f"val Dice : {average_dice_val}") | |||||
| print(f"val Dice main : {average_dice_val_main}") | |||||
| print(f"Mean val loss: {mean(val_epoch_losses)}") | |||||
| results.append(epoch_results) | |||||
| val_epochs.append(epoch) | |||||
| train_epochs.append(epoch) | |||||
| plt.plot(val_epochs, val_mean_losses, train_epochs, train_mean_losses) | |||||
| if average_dice_val_main > last_best_dice: | |||||
| torch.save( | |||||
| panc_sam_instance, | |||||
| f"exps/{exp_id}-{user_input}/sam_tuned_save.pth", | |||||
| ) | |||||
| last_best_dice = average_dice_val | |||||
| del epoch_results | |||||
| del average_dice_val | |||||
| except: | |||||
| train_epochs.append(epoch) | |||||
| plt.plot(train_epochs, train_mean_losses) | |||||
| print(f"=================End of EPOCH: {epoch}==================\n") | |||||
| plt.yscale("log") | |||||
| plt.title("Mean epoch loss") | |||||
| plt.xlabel("Epoch Number") | |||||
| plt.ylabel("Loss") | |||||
| plt.savefig("result") | |||||
| ## training with k-fold cross validation: | |||||
| return train_losses, val_losses, results | |||||
| train_losses, val_losses, results = train_model(train_loader, val_loader) | |||||
| log_file.close() | |||||
+ 202
- 0
kernel/Models/model_handler.py
View File
| import torch | |||||
| from torch import nn | |||||
| from torch.nn import functional as F | |||||
| from utils import create_prompt_main | |||||
| device = 'cuda:0' | |||||
| from segment_anything import SamPredictor, sam_model_registry | |||||
| class panc_sam(nn.Module): | |||||
| def forward(self, batched_input, device): | |||||
| box = torch.tensor([[200, 200, 750, 800]]).to(device) | |||||
| outputs = [] | |||||
| outputs_prompt = [] | |||||
| for image_record in batched_input: | |||||
| image_embeddings = image_record["image_embedd"].to(device) | |||||
| if "point_coords" in image_record: | |||||
| point_coords = image_record["point_coords"].to(device) | |||||
| point_labels = image_record["point_labels"].to(device) | |||||
| points = (point_coords.unsqueeze(0), point_labels.unsqueeze(0)) | |||||
| else: | |||||
| raise ValueError("what the f?") | |||||
| # input_images = torch.stack([x["image"] for x in batched_input], dim=0) | |||||
| with torch.no_grad(): | |||||
| sparse_embeddings, dense_embeddings = self.prompt_encoder( | |||||
| points=None, | |||||
| boxes=box, | |||||
| masks=None, | |||||
| ) | |||||
| sparse_embeddings = sparse_embeddings | |||||
| dense_embeddings = dense_embeddings | |||||
| # raise ValueError(image_embeddings.shape) | |||||
| ##################################################### | |||||
| low_res_masks, _ = self.mask_decoder( | |||||
| image_embeddings=image_embeddings, | |||||
| image_pe=self.prompt_encoder.get_dense_pe().detach(), | |||||
| sparse_prompt_embeddings=sparse_embeddings.detach(), | |||||
| dense_prompt_embeddings=dense_embeddings.detach(), | |||||
| multimask_output=False, | |||||
| ) | |||||
| outputs.append(low_res_masks) | |||||
| # points, point_labels = create_prompt((low_res_masks > 0).float()) | |||||
| # points, point_labels = create_prompt(low_res_masks) | |||||
| points, point_labels = create_prompt_main(low_res_masks) | |||||
| points = points * 4 | |||||
| points = (points, point_labels) | |||||
| with torch.no_grad(): | |||||
| sparse_embeddings, dense_embeddings = self.prompt_encoder2( | |||||
| points=points, | |||||
| boxes=None, | |||||
| masks=None, | |||||
| ) | |||||
| low_res_masks, _ = self.mask_decoder2( | |||||
| image_embeddings=image_embeddings, | |||||
| image_pe=self.prompt_encoder2.get_dense_pe().detach(), | |||||
| sparse_prompt_embeddings=sparse_embeddings.detach(), | |||||
| dense_prompt_embeddings=dense_embeddings.detach(), | |||||
| multimask_output=False, | |||||
| ) | |||||
| outputs_prompt.append(low_res_masks) | |||||
| low_res_masks_promtp = torch.cat(outputs_prompt, dim=1) | |||||
| low_res_masks = torch.cat(outputs, dim=1) | |||||
| return low_res_masks, low_res_masks_promtp | |||||
| def double_conv_3d(in_channels, out_channels): | |||||
| return nn.Sequential( | |||||
| nn.Conv3d(in_channels, out_channels, kernel_size=(1, 3, 3), padding=(0, 1, 1)), | |||||
| nn.ReLU(inplace=True), | |||||
| nn.Conv3d(out_channels, out_channels, kernel_size=(3, 1, 1), padding=(1, 0, 0)), | |||||
| nn.ReLU(inplace=True), | |||||
| ) | |||||
| #Was not used | |||||
| class UNet3D(nn.Module): | |||||
| def __init__(self): | |||||
| super(UNet3D, self).__init__() | |||||
| self.dconv_down1 = double_conv_3d(1, 32) | |||||
| self.dconv_down2 = double_conv_3d(32, 64) | |||||
| self.dconv_down3 = double_conv_3d(64, 96) | |||||
| self.maxpool = nn.MaxPool3d((1, 2, 2)) | |||||
| self.upsample = nn.Upsample( | |||||
| scale_factor=(1, 2, 2), mode="trilinear", align_corners=True | |||||
| ) | |||||
| self.dconv_up2 = double_conv_3d(64 + 96, 64) | |||||
| self.dconv_up1 = double_conv_3d(64 + 32, 32) | |||||
| self.conv_last = nn.Conv3d(32, 1, kernel_size=1) | |||||
| def forward(self, x): | |||||
| x = x.unsqueeze(1) | |||||
| conv1 = self.dconv_down1(x) | |||||
| x = self.maxpool(conv1) | |||||
| conv2 = self.dconv_down2(x) | |||||
| x = self.maxpool(conv2) | |||||
| x = self.dconv_down3(x) | |||||
| x = self.upsample(x) | |||||
| x = torch.cat([x, conv2], dim=1) | |||||
| x = self.dconv_up2(x) | |||||
| x = self.upsample(x) | |||||
| x = torch.cat([x, conv1], dim=1) | |||||
| x = self.dconv_up1(x) | |||||
| out = self.conv_last(x) | |||||
| return out | |||||
| class Conv3DFilter(nn.Module): | |||||
| def __init__( | |||||
| self, | |||||
| in_channels=1, | |||||
| out_channels=1, | |||||
| kernel_size=[(3, 1, 1), (3, 1, 1), (3, 1, 1), (3, 1, 1)], | |||||
| padding_sizes=None, | |||||
| custom_bias=0, | |||||
| ): | |||||
| super(Conv3DFilter, self).__init__() | |||||
| self.custom_bias = custom_bias | |||||
| self.bias = 1e-8 | |||||
| # Convolutional layer with padding to maintain input spatial dimensions | |||||
| self.convs = nn.ModuleList( | |||||
| [ | |||||
| nn.Sequential( | |||||
| nn.Conv3d( | |||||
| in_channels, | |||||
| out_channels, | |||||
| kernel_size[0], | |||||
| padding=padding_sizes[0], | |||||
| ), | |||||
| nn.ReLU(), | |||||
| nn.Conv3d( | |||||
| out_channels, | |||||
| out_channels, | |||||
| kernel_size[0], | |||||
| padding=padding_sizes[0], | |||||
| ), | |||||
| nn.ReLU(), | |||||
| ) | |||||
| ] | |||||
| ) | |||||
| for kernel, padding in zip(kernel_size[1:-1], padding_sizes[1:-1]): | |||||
| self.convs.extend( | |||||
| [ | |||||
| nn.Sequential( | |||||
| nn.Conv3d( | |||||
| out_channels, out_channels, kernel, padding=padding | |||||
| ), | |||||
| nn.ReLU(), | |||||
| nn.Conv3d( | |||||
| out_channels, out_channels, kernel, padding=padding | |||||
| ), | |||||
| nn.ReLU(), | |||||
| ) | |||||
| ] | |||||
| ) | |||||
| self.output_conv = nn.Conv3d( | |||||
| out_channels, 1, kernel_size[-1], padding=padding_sizes[-1] | |||||
| ) | |||||
| # self.m = nn.LeakyReLU(0.1) | |||||
| def forward(self, input): | |||||
| x = input.unsqueeze(1) | |||||
| for module in self.convs: | |||||
| x = module(x) + x | |||||
| x = self.output_conv(x) | |||||
| x = torch.sigmoid(x).squeeze(1) | |||||
| return x |
+ 170
- 0
kernel/Models/utils.py
View File
| import torch | |||||
| import torch.nn as nn | |||||
| import numpy as np | |||||
| def create_prompt_simple(masks, forground=2, background=2): | |||||
| kernel_size = 9 | |||||
| kernel = nn.Conv2d( | |||||
| in_channels=1, | |||||
| bias=False, | |||||
| out_channels=1, | |||||
| kernel_size=kernel_size, | |||||
| stride=1, | |||||
| padding=kernel_size // 2, | |||||
| ) | |||||
| # print(kernel.weight.shape) | |||||
| kernel.weight = nn.Parameter( | |||||
| torch.zeros(1, 1, kernel_size, kernel_size).to(masks.device), | |||||
| requires_grad=False, | |||||
| ) | |||||
| kernel.weight[0, 0] = 1.0 | |||||
| eroded_masks = kernel(masks).squeeze(1)//(kernel_size**2) | |||||
| masks = masks.squeeze(1) | |||||
| use_eroded = (eroded_masks.sum(dim=(1, 2), keepdim=True) >= forground).float() | |||||
| new_masks = (eroded_masks * use_eroded) + (masks * (1 - use_eroded)) | |||||
| all_points = [] | |||||
| all_labels = [] | |||||
| for i in range(len(new_masks)): | |||||
| new_background = background | |||||
| points = [] | |||||
| labels = [] | |||||
| new_mask = new_masks[i] | |||||
| nonzeros = torch.nonzero(new_mask, as_tuple=False) | |||||
| n_nonzero = len(nonzeros) | |||||
| if n_nonzero >= forground: | |||||
| indices = np.random.choice( | |||||
| np.arange(n_nonzero), size=forground, replace=False | |||||
| ).tolist() | |||||
| # raise ValueError(nonzeros[:, [0, 1]][indices]) | |||||
| points.append(nonzeros[:, [1,0]][indices]) | |||||
| labels.append(torch.ones(forground)) | |||||
| else: | |||||
| if n_nonzero > 0: | |||||
| points.append(nonzeros) | |||||
| labels.append(torch.ones(n_nonzero)) | |||||
| new_background += forground - n_nonzero | |||||
| # print(points, new_background) | |||||
| zeros = torch.nonzero(1 - masks[i], as_tuple=False) | |||||
| n_zero = len(zeros) | |||||
| indices = np.random.choice( | |||||
| np.arange(n_zero), size=new_background, replace=False | |||||
| ).tolist() | |||||
| points.append(zeros[:, [1, 0]][indices]) | |||||
| labels.append(torch.zeros(new_background)) | |||||
| points = torch.cat(points, dim=0) | |||||
| labels = torch.cat(labels, dim=0) | |||||
| all_points.append(points) | |||||
| all_labels.append(labels) | |||||
| all_points = torch.stack(all_points, dim=0) | |||||
| all_labels = torch.stack(all_labels, dim=0) | |||||
| return all_points, all_labels | |||||
| def distance_to_edge(point, image_shape): | |||||
| y, x = point | |||||
| height, width = image_shape | |||||
| distance_top = y | |||||
| distance_bottom = height - y | |||||
| distance_left = x | |||||
| distance_right = width - x | |||||
| return min(distance_top, distance_bottom, distance_left, distance_right) | |||||
| def create_prompt(probabilities, foreground=2, background=2): | |||||
| kernel_size = 9 | |||||
| kernel = nn.Conv2d( | |||||
| in_channels=1, | |||||
| bias=False, | |||||
| out_channels=1, | |||||
| kernel_size=kernel_size, | |||||
| stride=1, | |||||
| padding=kernel_size // 2, | |||||
| ) | |||||
| kernel.weight = nn.Parameter( | |||||
| torch.zeros(1, 1, kernel_size, kernel_size).to(probabilities.device), | |||||
| requires_grad=False, | |||||
| ) | |||||
| kernel.weight[0, 0] = 1.0 | |||||
| eroded_probs = kernel(probabilities).squeeze(1) / (kernel_size ** 2) | |||||
| probabilities = probabilities.squeeze(1) | |||||
| all_points = [] | |||||
| all_labels = [] | |||||
| for i in range(len(probabilities)): | |||||
| points = [] | |||||
| labels = [] | |||||
| prob_mask = probabilities[i] | |||||
| if torch.max(prob_mask) > 0.01: | |||||
| foreground_indices = torch.topk(prob_mask.view(-1), k=foreground, dim=0).indices | |||||
| foreground_points = torch.nonzero(prob_mask > 0, as_tuple=False) | |||||
| n_foreground = len(foreground_points) | |||||
| if n_foreground >= foreground: | |||||
| # Get the index of the point with the highest probability | |||||
| top_prob_idx = torch.topk(prob_mask.view(-1), k=1).indices[0] | |||||
| # Convert the flat index to 2D coordinates | |||||
| top_prob_point = np.unravel_index(top_prob_idx.item(), prob_mask.shape) | |||||
| top_prob_point = torch.tensor(top_prob_point, device=probabilities.device) # Move to the same device | |||||
| # Add the point with the highest probability to the points list | |||||
| points.append(torch.tensor([top_prob_point[1], top_prob_point[0]], device=probabilities.device).unsqueeze(0)) | |||||
| labels.append(torch.ones(1, device=probabilities.device)) | |||||
| # Exclude the top probability point when finding the point closest to the edge | |||||
| remaining_foreground_points = foreground_points[(foreground_points != top_prob_point.unsqueeze(0)).all(dim=1)] | |||||
| if remaining_foreground_points.numel() > 0: | |||||
| distances = [distance_to_edge(point.cpu().numpy(), prob_mask.shape) for point in remaining_foreground_points] | |||||
| edge_point_idx = np.argmin(distances) | |||||
| edge_point = remaining_foreground_points[edge_point_idx] | |||||
| # Add the edge point to the points list | |||||
| points.append(edge_point[[1, 0]].unsqueeze(0)) | |||||
| labels.append(torch.ones(1, device=probabilities.device)) | |||||
| # raise ValueError(points , labels) | |||||
| else: | |||||
| if n_foreground > 0: | |||||
| points.append(foreground_points[:, [1, 0]]) | |||||
| labels.append(torch.ones(n_foreground)) | |||||
| # Select 2 background points, one from 0 to -15 and one less than -15 | |||||
| background_indices_1 = torch.nonzero((prob_mask < 0) & (prob_mask > -15), as_tuple=False) | |||||
| background_indices_2 = torch.nonzero(prob_mask < -15, as_tuple=False) | |||||
| # Randomly sample from each set of background points | |||||
| indices_1 = np.random.choice(np.arange(len(background_indices_1)), size=1, replace=False).tolist() | |||||
| indices_2 = np.random.choice(np.arange(len(background_indices_2)), size=1, replace=False).tolist() | |||||
| points.append(background_indices_1[indices_1]) | |||||
| points.append(background_indices_2[indices_2]) | |||||
| labels.append(torch.zeros(2)) | |||||
| else: | |||||
| # If no probability is greater than 0, return 4 background points | |||||
| # print(prob_mask.unique()) | |||||
| background_indices_1 = torch.nonzero(prob_mask < 0, as_tuple=False) | |||||
| indices_1 = np.random.choice(np.arange(len(background_indices_1)), size=4, replace=False).tolist() | |||||
| points.append(background_indices_1[indices_1]) | |||||
| labels.append(torch.zeros(4)) | |||||
| labels = [label.to(probabilities.device) for label in labels] | |||||
| points = torch.cat(points, dim=0) | |||||
| all_points.append(points) | |||||
| all_labels.append(torch.cat(labels, dim=0)) | |||||
| all_points = torch.stack(all_points, dim=0) | |||||
| all_labels = torch.stack(all_labels, dim=0) | |||||
| # print(all_points, all_labels) | |||||
| return all_points, all_labels | |||||
+ 30
- 0
kernel/args.py
View File
| import argparse | |||||
| def get_arguments(): | |||||
| parser = argparse.ArgumentParser(description="Your program's description here") | |||||
| parser.add_argument('--debug', action='store_true', help='Enable debug mode') | |||||
| parser.add_argument('--accumulative_batch_size', type=int, default=2, help='Accumulative batch size') | |||||
| parser.add_argument('--batch_size', type=int, default=1, help='Batch size') | |||||
| parser.add_argument('--num_workers', type=int, default=1, help='Number of workers') | |||||
| parser.add_argument('--slice_per_image', type=int, default=1, help='Slices per image') | |||||
| parser.add_argument('--num_epochs', type=int, default=40, help='Number of epochs') | |||||
| parser.add_argument('--sample_size', type=int, default=4, help='Sample size') | |||||
| parser.add_argument('--image_size', type=int, default=1024, help='Image size') | |||||
| parser.add_argument('--run_name', type=str, default='debug', help='The name of the run') | |||||
| parser.add_argument('--lr', type=float, default=1e-3, help='Learning Rate') | |||||
| parser.add_argument('--batch_step_one', type=int, default=15, help='Batch one') | |||||
| parser.add_argument('--batch_step_two', type=int, default=25, help='Batch two') | |||||
| parser.add_argument('--conv_model', type=str, default=None, help='Path to convolution model') | |||||
| parser.add_argument('--custom_bias', type=float, default=0, help='Learning Rate') | |||||
| parser.add_argument("--inference", action="store_true", help="Set for inference") | |||||
| parser.add_argument("--conv_path", type=str, help="Path for convolutional model path (normally found in exps folder)") | |||||
| parser.add_argument("--train_dir",type=str, help="Path to the training data") | |||||
| parser.add_argument("--test_dir",type=str, help="Path to the test data") | |||||
| parser.add_argument("--test_labels_dir",type=str, help="Path to the test data") | |||||
| parser.add_argument("--train_labels_dir",type=str, help="Path to the test data") | |||||
| parser.add_argument("--model_path",type=str, help="Path to the test data") | |||||
| return parser.parse_args() |
+ 282
- 0
kernel/data_load_group.py
View File
| import matplotlib.pyplot as plt | |||||
| import os | |||||
| import numpy as np | |||||
| import random | |||||
| from segment_anything.utils.transforms import ResizeLongestSide | |||||
| from einops import rearrange | |||||
| import torch | |||||
| from segment_anything import SamPredictor, sam_model_registry | |||||
| from torch.utils.data import DataLoader | |||||
| from time import time | |||||
| import torch.nn.functional as F | |||||
| import cv2 | |||||
| from PIL import Image | |||||
| import cv2 | |||||
| from utils import create_prompt_simple | |||||
| from pre_processer import PreProcessing | |||||
| from tqdm import tqdm | |||||
| from args import get_arguments | |||||
| def apply_median_filter(input_matrix, kernel_size=5, sigma=0): | |||||
| # Apply the Gaussian filter | |||||
| filtered_matrix = cv2.medianBlur(input_matrix.astype(np.uint8), kernel_size) | |||||
| return filtered_matrix.astype(np.float32) | |||||
| def apply_guassain_filter(input_matrix, kernel_size=(7, 7), sigma=0): | |||||
| smoothed_matrix = cv2.blur(input_matrix, kernel_size) | |||||
| return smoothed_matrix.astype(np.float32) | |||||
| def img_enhance(img2, over_coef=0.8, under_coef=0.7): | |||||
| img2 = apply_median_filter(img2) | |||||
| img_blure = apply_guassain_filter(img2) | |||||
| img2 = img2 - 0.8 * img_blure | |||||
| img_mean = np.mean(img2, axis=(1, 2)) | |||||
| img_max = np.amax(img2, axis=(1, 2)) | |||||
| val = (img_max - img_mean) * over_coef + img_mean | |||||
| img2 = (img2 < img_mean * under_coef).astype(np.float32) * img_mean * under_coef + ( | |||||
| (img2 >= img_mean * under_coef).astype(np.float32) | |||||
| ) * img2 | |||||
| img2 = (img2 <= val).astype(np.float32) * img2 + (img2 > val).astype( | |||||
| np.float32 | |||||
| ) * val | |||||
| return img2 | |||||
| def normalize_and_pad(x, img_size): | |||||
| """Normalize pixel values and pad to a square input.""" | |||||
| pixel_mean = torch.tensor([[[[123.675]], [[116.28]], [[103.53]]]]) | |||||
| pixel_std = torch.tensor([[[[58.395]], [[57.12]], [[57.375]]]]) | |||||
| # Normalize colors | |||||
| x = (x - pixel_mean) / pixel_std | |||||
| # Pad | |||||
| h, w = x.shape[-2:] | |||||
| padh = img_size - h | |||||
| padw = img_size - w | |||||
| x = F.pad(x, (0, padw, 0, padh)) | |||||
| return x | |||||
| def preprocess(img_enhanced, img_enhance_times=1, over_coef=0.4, under_coef=0.5): | |||||
| # img_enhanced = img_enhanced+0.1 | |||||
| img_enhanced -= torch.min(img_enhanced) | |||||
| img_max = torch.max(img_enhanced) | |||||
| if img_max > 0: | |||||
| img_enhanced = img_enhanced / img_max | |||||
| # raise ValueError(img_max) | |||||
| img_enhanced = img_enhanced.unsqueeze(1) | |||||
| img_enhanced = img_enhanced.unsqueeze(1) | |||||
| img_enhanced = PreProcessing.CLAHE( | |||||
| img_enhanced, clip_limit=9.0, grid_size=(4, 4) | |||||
| ) | |||||
| raise ValueError(img_enhanced.shape) | |||||
| img_enhanced = img_enhanced[0] | |||||
| # for i in range(img_enhance_times): | |||||
| # img_enhanced=img_enhance(img_enhanced.astype(np.float32), over_coef=over_coef,under_coef=under_coef) | |||||
| img_enhanced -= torch.amin(img_enhanced, dim=(1, 2), keepdim=True) | |||||
| larg_imag = ( | |||||
| img_enhanced / torch.amax(img_enhanced, axis=(1, 2), keepdims=True) * 255 | |||||
| ).type(torch.uint8) | |||||
| return larg_imag | |||||
| def prepare(larg_imag, target_image_size): | |||||
| # larg_imag = 255 - larg_imag | |||||
| larg_imag = rearrange(larg_imag, "S H W -> S 1 H W") | |||||
| larg_imag = torch.tensor( | |||||
| np.concatenate([larg_imag, larg_imag, larg_imag], axis=1) | |||||
| ).float() | |||||
| transform = ResizeLongestSide(target_image_size) | |||||
| larg_imag = transform.apply_image_torch(larg_imag) | |||||
| larg_imag = normalize_and_pad(larg_imag, target_image_size) | |||||
| return larg_imag | |||||
| def process_single_image(image_path, target_image_size): | |||||
| # Load the image | |||||
| if image_path.endswith(".png") or image_path.endswith(".jpg"): | |||||
| data = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE).squeeze() | |||||
| else: | |||||
| data = np.load(image_path) | |||||
| x = rearrange(data, "H W -> 1 H W") | |||||
| x = torch.tensor(x) | |||||
| # Apply preprocessing | |||||
| x = preprocess(x) | |||||
| x = prepare(x, target_image_size) | |||||
| return x | |||||
| class PanDataset: | |||||
| def __init__( | |||||
| self, | |||||
| dirs, | |||||
| datasets, | |||||
| target_image_size, | |||||
| slice_per_image, | |||||
| split_ratio=0.9, | |||||
| train=True, | |||||
| val=False, | |||||
| augmentation=None, | |||||
| ): | |||||
| self.data_set_names = [] | |||||
| self.labels_path = [] | |||||
| self.images_path = [] | |||||
| self.embedds_path = [] | |||||
| self.labels_indexes = [] | |||||
| self.individual_index = [] | |||||
| for dir, dataset_name in zip(dirs, datasets): | |||||
| labels_dir = dir + "/labels" | |||||
| npy_files = [file for file in os.listdir(labels_dir)] | |||||
| items_label = sorted( | |||||
| npy_files, | |||||
| key=lambda x: ( | |||||
| int(x.split("_")[2].split(".")[0]), | |||||
| int(x.split("_")[1]), | |||||
| ), | |||||
| ) | |||||
| images_dir = dir + "/images" | |||||
| npy_files = [file for file in os.listdir(images_dir)] | |||||
| items_image = sorted( | |||||
| npy_files, | |||||
| key=lambda x: ( | |||||
| int(x.split("_")[2].split(".")[0]), | |||||
| int(x.split("_")[1]), | |||||
| ), | |||||
| ) | |||||
| try: | |||||
| embedds_dir = dir + "/embeddings" | |||||
| npy_files = [file for file in os.listdir(embedds_dir)] | |||||
| items_embedds = sorted( | |||||
| npy_files, | |||||
| key=lambda x: ( | |||||
| int(x.split("_")[2].split(".")[0]), | |||||
| int(x.split("_")[1]), | |||||
| ), | |||||
| ) | |||||
| self.embedds_path.extend( | |||||
| [os.path.join(embedds_dir, item) for item in items_embedds] | |||||
| ) | |||||
| except: | |||||
| a = 1 | |||||
| # raise ValueError(items_label[990].split('_')[2].split('.')[0]) | |||||
| subject_indexes = set() | |||||
| for item in items_label: | |||||
| subject_indexes.add(int(item.split("_")[2].split(".")[0])) | |||||
| indexes = list(subject_indexes) | |||||
| self.labels_indexes.extend(indexes) | |||||
| self.individual_index.extend( | |||||
| [int(item.split("_")[2].split(".")[0]) for item in items_label] | |||||
| ) | |||||
| self.data_set_names.extend([dataset_name[0] for _ in items_label]) | |||||
| self.labels_path.extend( | |||||
| [os.path.join(labels_dir, item) for item in items_label] | |||||
| ) | |||||
| self.images_path.extend( | |||||
| [os.path.join(images_dir, item) for item in items_image] | |||||
| ) | |||||
| self.target_image_size = target_image_size | |||||
| self.datasets = datasets | |||||
| self.slice_per_image = slice_per_image | |||||
| self.augmentation = augmentation | |||||
| self.individual_index = torch.tensor(self.individual_index) | |||||
| if val: | |||||
| self.labels_indexes=self.labels_indexes[int(split_ratio*len(self.labels_indexes)):] | |||||
| elif train: | |||||
| self.labels_indexes=self.labels_indexes[:int(split_ratio*len(self.labels_indexes))] | |||||
| def __getitem__(self, idx): | |||||
| indexes = (self.individual_index == self.labels_indexes[idx]).nonzero() | |||||
| images_list = [] | |||||
| labels_list = [] | |||||
| batched_input = [] | |||||
| for index in indexes: | |||||
| data = np.load(self.images_path[index]) | |||||
| embedd = np.load(self.embedds_path[index]) | |||||
| labels = np.load(self.labels_path[index]) | |||||
| if self.data_set_names[index] == "NIH_PNG": | |||||
| x = data.T | |||||
| y = rearrange(labels.T, "H W -> 1 H W") | |||||
| y = (y == 1).astype(np.uint8) | |||||
| elif self.data_set_names[index] == "Abdment1k-npy": | |||||
| x = data | |||||
| y = rearrange(labels, "H W -> 1 H W") | |||||
| y = (y == 4).astype(np.uint8) | |||||
| else: | |||||
| raise ValueError("Incorect dataset name") | |||||
| x = torch.tensor(x) | |||||
| embedd = torch.tensor(embedd) | |||||
| y = torch.tensor(y) | |||||
| current_image_size = y.shape[-1] | |||||
| points, point_labels = create_prompt_simple(y[:, ::2, ::2].squeeze(1).float()) | |||||
| points *= self.target_image_size // y[:, ::2, ::2].shape[-1] | |||||
| y = F.interpolate(y.unsqueeze(1), size=self.target_image_size) | |||||
| batched_input.append( | |||||
| { | |||||
| "image_embedd": embedd, | |||||
| "image": x, | |||||
| "label": y, | |||||
| "point_coords": points[0], | |||||
| "point_labels": point_labels[0], | |||||
| "original_size": (1024, 1024), | |||||
| }, | |||||
| ) | |||||
| return batched_input | |||||
| def collate_fn(self, data): | |||||
| batched_input = zip(*data) | |||||
| return data | |||||
| def __len__(self): | |||||
| return len(self.labels_indexes) | |||||
+ 564
- 0
kernel/fine_tune_good_unet.py
View File
| from pathlib import Path | |||||
| import numpy as np | |||||
| import matplotlib.pyplot as plt | |||||
| # import cv2 | |||||
| from collections import defaultdict | |||||
| import torchvision.transforms as transforms | |||||
| import torch | |||||
| from torch import nn | |||||
| import torch.nn.functional as F | |||||
| from segment_anything.utils.transforms import ResizeLongestSide | |||||
| import albumentations as A | |||||
| from albumentations.pytorch import ToTensorV2 | |||||
| import numpy as np | |||||
| import random | |||||
| from tqdm import tqdm | |||||
| from time import sleep | |||||
| from data_load_group import * | |||||
| from time import time | |||||
| from PIL import Image | |||||
| from sklearn.model_selection import KFold | |||||
| from shutil import copyfile | |||||
| # import monai | |||||
| from utils import * | |||||
| from torch.autograd import Variable | |||||
| from Models.model_handler import panc_sam | |||||
| from Models.model_handler import UNet3D | |||||
| from Models.model_handler import Conv3DFilter | |||||
| from loss import * | |||||
| from args import get_arguments | |||||
| from segment_anything import SamPredictor, sam_model_registry | |||||
| from statistics import mean | |||||
| from copy import deepcopy | |||||
| from torch.nn.functional import threshold, normalize | |||||
| def calculate_recall(pred, target): | |||||
| smooth = 1 | |||||
| batch_size = 1 | |||||
| recall_scores = [] | |||||
| binary_mask = pred>0 | |||||
| true_positive = ((pred == 1) & (target == 1)).sum().item() | |||||
| false_negative = ((pred == 0) & (target == 1)).sum().item() | |||||
| recall = (true_positive + smooth) / ((true_positive + false_negative) + smooth) | |||||
| return recall | |||||
| def calculate_precision(pred, target): | |||||
| smooth = 1 | |||||
| batch_size = 1 | |||||
| recall_scores = [] | |||||
| binary_mask = pred>0 | |||||
| true_positive = ((pred == 1) & (target == 1)).sum().item() | |||||
| false_negative = ((pred == 1) & (target == 0)).sum().item() | |||||
| recall = (true_positive + smooth) / ((true_positive + false_negative) + smooth) | |||||
| return recall | |||||
| def calculate_jaccard(pred, target): | |||||
| smooth = 1 | |||||
| batch_size = pred.shape[0] | |||||
| jaccard_scores = [] | |||||
| binary_mask = pred>0 | |||||
| true_positive = ((pred == 1) & (target == 1)).sum().item() | |||||
| false_negative = ((pred == 0) & (target == 1)).sum().item() | |||||
| true_positive = ((pred == 1) & (target == 1)).sum().item() | |||||
| false_positive = ((pred == 1) & (target == 0)).sum().item() | |||||
| jaccard = (true_positive + smooth) / (true_positive + false_positive + false_negative + smooth) | |||||
| # jaccard_scores.append(jaccard) | |||||
| # for i in range(batch_size): | |||||
| # true_positive = ((binary_mask[i] == 1) & (target[i] == 1)).sum().item() | |||||
| # false_positive = ((binary_mask[i] == 1) & (target[i] == 0)).sum().item() | |||||
| # false_negative = ((binary_mask[i] == 0) & (target[i] == 1)).sum().item() | |||||
| return jaccard | |||||
| def save_img(img, dir): | |||||
| img = img.clone().cpu().numpy() + 100 | |||||
| if len(img.shape) == 3: | |||||
| img = rearrange(img, "c h w -> h w c") | |||||
| img_min = np.amin(img, axis=(0, 1), keepdims=True) | |||||
| img = img - img_min | |||||
| img_max = np.amax(img, axis=(0, 1), keepdims=True) | |||||
| img = (img / img_max * 255).astype(np.uint8) | |||||
| # grey_img = Image.fromarray(img[:, :, 0]) | |||||
| img = Image.fromarray(img) | |||||
| else: | |||||
| img_min = img.min() | |||||
| img = img - img_min | |||||
| img_max = img.max() | |||||
| if img_max != 0: | |||||
| img = img / img_max * 255 | |||||
| img = Image.fromarray(img).convert("L") | |||||
| img.save(dir) | |||||
| def seed_everything(seed: int): | |||||
| import random, os | |||||
| import numpy as np | |||||
| import torch | |||||
| random.seed(seed) | |||||
| os.environ['PYTHONHASHSEED'] = str(seed) | |||||
| np.random.seed(seed) | |||||
| torch.manual_seed(seed) | |||||
| torch.cuda.manual_seed(seed) | |||||
| torch.backends.cudnn.deterministic = True | |||||
| torch.backends.cudnn.benchmark = True | |||||
| seed_everything(2024) | |||||
| global optimizer | |||||
| args = get_arguments() | |||||
| exp_id = 0 | |||||
| found = 0 | |||||
| user_input = args.run_name | |||||
| while found == 0: | |||||
| try: | |||||
| os.makedirs(f"exps/{exp_id}-{user_input}") | |||||
| found = 1 | |||||
| except: | |||||
| exp_id = exp_id + 1 | |||||
| copyfile(os.path.realpath(__file__), f"exps/{exp_id}-{user_input}/code.py") | |||||
| augmentation = A.Compose( | |||||
| [ | |||||
| A.Rotate(limit=100, p=0.7), | |||||
| A.RandomScale(scale_limit=0.3, p=0.5), | |||||
| ] | |||||
| ) | |||||
| device = "cuda:0" | |||||
| panc_sam_instance = torch.load(args.model_path) | |||||
| panc_sam_instance.to(device) | |||||
| conv3d_instance = UNet3D() | |||||
| kernel_size = [(1, 5, 5), (5, 5, 5), (5, 5, 5), (5, 5, 5)] | |||||
| conv3d_instance = Conv3DFilter( | |||||
| 1, | |||||
| 5, | |||||
| kernel_size, | |||||
| np.array(kernel_size) // 2, | |||||
| custom_bias=args.custom_bias, | |||||
| ) | |||||
| conv3d_instance.to(device) | |||||
| conv3d_instance.train() | |||||
| train_dataset = PanDataset( | |||||
| dirs=[f"{args.train_dir}/train"], | |||||
| datasets=[["NIH_PNG", 1]], | |||||
| target_image_size=args.image_size, | |||||
| slice_per_image=args.slice_per_image, | |||||
| train=True, | |||||
| val=False, # Enable validation data splitting | |||||
| augmentation=augmentation, | |||||
| ) | |||||
| val_dataset = PanDataset( | |||||
| [f"{args.train_dir}/train"], | |||||
| [["NIH_PNG", 1]], | |||||
| args.image_size, | |||||
| slice_per_image=args.slice_per_image, | |||||
| val=True | |||||
| ) | |||||
| test_dataset = PanDataset( | |||||
| [f"{args.test_dir}/test"], | |||||
| [["NIH_PNG", 1]], | |||||
| args.image_size, | |||||
| slice_per_image=args.slice_per_image, | |||||
| train=False, | |||||
| ) | |||||
| train_loader = DataLoader( | |||||
| train_dataset, | |||||
| batch_size=args.batch_size, | |||||
| collate_fn=train_dataset.collate_fn, | |||||
| shuffle=True, | |||||
| drop_last=False, | |||||
| num_workers=args.num_workers, | |||||
| ) | |||||
| val_loader = DataLoader( | |||||
| val_dataset, | |||||
| batch_size=args.batch_size, | |||||
| collate_fn=val_dataset.collate_fn, | |||||
| shuffle=False, | |||||
| drop_last=False, | |||||
| num_workers=args.num_workers, | |||||
| ) | |||||
| test_loader = DataLoader( | |||||
| test_dataset, | |||||
| batch_size=args.batch_size, | |||||
| collate_fn=test_dataset.collate_fn, | |||||
| shuffle=False, | |||||
| drop_last=False, | |||||
| num_workers=args.num_workers, | |||||
| ) | |||||
| # Set up the optimizer, hyperparameter tuning will improve performance here | |||||
| lr = args.lr | |||||
| max_lr = 3e-4 | |||||
| wd = 5e-4 | |||||
| all_parameters = list(conv3d_instance.parameters()) | |||||
| optimizer = torch.optim.Adam( | |||||
| all_parameters, | |||||
| lr=lr, | |||||
| weight_decay=wd, | |||||
| ) | |||||
| scheduler = torch.optim.lr_scheduler.StepLR( | |||||
| optimizer, step_size=10, gamma=0.7, verbose=True | |||||
| ) | |||||
| loss_function = loss_fn(alpha=0.5, gamma=2.0) | |||||
| loss_function.to(device) | |||||
| from time import time | |||||
| import time as s_time | |||||
| log_file = open(f"exps/{exp_id}-{user_input}/log.txt", "a") | |||||
| def process_model(data_loader, train=0, save_output=0, epoch=None, scheduler=None): | |||||
| epoch_losses = [] | |||||
| index = 0 | |||||
| results = [] | |||||
| dice_sam_lists = [] | |||||
| dice_sam_prompt_lists = [] | |||||
| dice_lists = [] | |||||
| dice_prompt_lists = [] | |||||
| num_samples = 0 | |||||
| counterb = 0 | |||||
| for batch in tqdm(data_loader, total=args.sample_size // args.batch_size): | |||||
| for batched_input in batch: | |||||
| num_samples += 1 | |||||
| # raise ValueError(len(batched_input)) | |||||
| low_res_masks = torch.zeros((1, 1, 0, 256, 256)) | |||||
| # s_time.sleep(0.6) | |||||
| counterb += len(batch) | |||||
| index += 1 | |||||
| label = [] | |||||
| label = [i["label"] for i in batched_input] | |||||
| # Only correct if gray scale | |||||
| label = torch.cat(label, dim=1) | |||||
| # raise ValueError(la) | |||||
| label = label.float() | |||||
| true_indexes = torch.where((torch.amax(label, dim=(2, 3)) > 0).view(-1))[0] | |||||
| low_res_label = F.interpolate(label, low_res_masks.shape[-2:]).to("cuda:0") | |||||
| low_res_masks, low_res_masks_promtp = panc_sam_instance( | |||||
| batched_input, device | |||||
| ) | |||||
| low_res_shape = low_res_masks.shape[-2:] | |||||
| low_res_label_prompt=low_res_label | |||||
| if train: | |||||
| transformed = augmentation( | |||||
| image=low_res_masks_promtp[0].permute(1, 2, 0).cpu().numpy(), | |||||
| mask=low_res_label[0].permute(1, 2, 0).cpu().numpy(), | |||||
| ) | |||||
| low_res_masks_promtp = ( | |||||
| torch.tensor(transformed["image"]) | |||||
| .permute(2, 0, 1) | |||||
| .unsqueeze(0) | |||||
| .to(device) | |||||
| ) | |||||
| low_res_label_prompt = ( | |||||
| torch.tensor(transformed["mask"]) | |||||
| .permute(2, 0, 1) | |||||
| .unsqueeze(0) | |||||
| .to(device) | |||||
| ) | |||||
| transformed = augmentation( | |||||
| image=low_res_masks[0].permute(1, 2, 0).cpu().numpy(), | |||||
| mask=low_res_label[0].permute(1, 2, 0).cpu().numpy(), | |||||
| ) | |||||
| low_res_masks = ( | |||||
| torch.tensor(transformed["image"]) | |||||
| .permute(2, 0, 1) | |||||
| .unsqueeze(0) | |||||
| .to(device) | |||||
| ) | |||||
| low_res_label = ( | |||||
| torch.tensor(transformed["mask"]) | |||||
| .permute(2, 0, 1) | |||||
| .unsqueeze(0) | |||||
| .to(device) | |||||
| ) | |||||
| low_res_masks = F.interpolate(low_res_masks, low_res_shape).to(device) | |||||
| low_res_label = F.interpolate(low_res_label, low_res_shape).to(device) | |||||
| low_res_masks = F.interpolate(low_res_masks, low_res_shape).to(device) | |||||
| low_res_label = F.interpolate(low_res_label, low_res_shape).to(device) | |||||
| low_res_masks_promtp = F.interpolate( | |||||
| low_res_masks_promtp, low_res_shape | |||||
| ).to(device) | |||||
| low_res_label_prompt = F.interpolate( | |||||
| low_res_label_prompt, low_res_shape | |||||
| ).to(device) | |||||
| low_res_masks = low_res_masks.detach() | |||||
| low_res_masks_promtp = low_res_masks_promtp.detach() | |||||
| dice_sam = dice_coefficient(low_res_masks , low_res_label).detach().cpu() | |||||
| dice_sam_prompt = ( | |||||
| dice_coefficient(low_res_masks_promtp, low_res_label_prompt) | |||||
| .detach() | |||||
| .cpu() | |||||
| ) | |||||
| low_res_masks_promtp = conv3d_instance( | |||||
| low_res_masks_promtp.detach().to(device) | |||||
| ) | |||||
| loss = loss_function(low_res_masks_promtp, low_res_masks_promtp) | |||||
| loss /= args.accumulative_batch_size / args.batch_size | |||||
| binary_mask = low_res_masks > 0.5 | |||||
| binary_mask_prompt = low_res_masks_promtp > 0.5 | |||||
| dice = dice_coefficient(binary_mask, low_res_label).detach().cpu() | |||||
| dice_prompt = ( | |||||
| dice_coefficient(binary_mask_prompt, low_res_label_prompt) | |||||
| .detach() | |||||
| .cpu() | |||||
| ) | |||||
| dice_sam_lists.append(dice_sam) | |||||
| dice_sam_prompt_lists.append(dice_sam_prompt) | |||||
| dice_lists.append(dice) | |||||
| dice_prompt_lists.append(dice_prompt) | |||||
| log_file.flush() | |||||
| if train: | |||||
| loss.backward() | |||||
| if index % (args.accumulative_batch_size / args.batch_size) == 0: | |||||
| optimizer.step() | |||||
| # if epoch==40: | |||||
| # scheduler.step() | |||||
| optimizer.zero_grad() | |||||
| index = 0 | |||||
| else: | |||||
| result = torch.cat( | |||||
| ( | |||||
| low_res_masks[:, ::10].detach().cpu().reshape(1, -1, 256, 256), | |||||
| binary_mask[:, ::10].detach().cpu().reshape(1, -1, 256, 256), | |||||
| ), | |||||
| dim=0, | |||||
| ) | |||||
| results.append(result) | |||||
| if index % (args.accumulative_batch_size / args.batch_size) == 0: | |||||
| epoch_losses.append(loss.item()) | |||||
| if counterb == (args.sample_size // args.batch_size) and train: | |||||
| break | |||||
| return ( | |||||
| epoch_losses, | |||||
| results, | |||||
| dice_lists, | |||||
| dice_prompt_lists, | |||||
| dice_sam_lists, | |||||
| dice_sam_prompt_lists, | |||||
| ) | |||||
| def train_model(train_loader, val_loader,test_loader, K_fold=False, N_fold=7, epoch_num_start=7): | |||||
| global optimizer | |||||
| index=0 | |||||
| if args.inference: | |||||
| with torch.no_grad(): | |||||
| conv = torch.load(f'{args.conv_path}') | |||||
| recall_list=[] | |||||
| percision_list=[] | |||||
| jaccard_list=[] | |||||
| for input in tqdm(test_loader): | |||||
| low_res_masks_sam, low_res_masks_promtp_sam = panc_sam_instance( | |||||
| input[0], device | |||||
| ) | |||||
| low_res_masks_sam = F.interpolate(low_res_masks_sam, 512).cpu() | |||||
| low_res_masks_promtp_sam = F.interpolate(low_res_masks_promtp_sam, 512).cpu() | |||||
| low_res_masks_promtp = conv(low_res_masks_promtp_sam.to(device)).detach().cpu() | |||||
| for slice_id,(batched_input,mask_sam,mask_prompt_sam,mask_prompt) in enumerate(zip(input[0],low_res_masks_sam[0],low_res_masks_promtp_sam[0],low_res_masks_promtp[0])): | |||||
| if not os.path.exists(f"ims/batch_{index}"): | |||||
| os.mkdir(f"ims/batch_{index}") | |||||
| image = batched_input["image"] | |||||
| label = batched_input["label"][0,0,::2,::2].to(bool) | |||||
| binary_mask_sam = (mask_sam > 0) | |||||
| binary_mask_prompt_sam = (mask_prompt_sam > 0) | |||||
| binary_mask_prompt = (mask_prompt > 0.5) | |||||
| recall = calculate_recall(label, binary_mask_prompt) | |||||
| percision = calculate_precision(label, binary_mask_prompt) | |||||
| jaccard = calculate_jaccard(label, binary_mask_prompt) | |||||
| percision_list.append(percision) | |||||
| recall_list.append(recall) | |||||
| jaccard_list.append(jaccard) | |||||
| image_mask = image.clone().to(torch.long) | |||||
| image_label = image.clone().to(torch.long) | |||||
| image_mask[binary_mask_sam]=255 | |||||
| image_label[label]=255 | |||||
| save_img( | |||||
| torch.stack((image_mask,image_label,image),dim=0), | |||||
| f"ims/batch_{index}/sam{slice_id}.png", | |||||
| ) | |||||
| image_mask = image.clone().to(torch.long) | |||||
| image_mask[binary_mask_prompt_sam]=255 | |||||
| save_img( | |||||
| torch.stack((image_mask,image_label,image),dim=0), | |||||
| f"ims/batch_{index}/sam_prompt{slice_id}.png", | |||||
| ) | |||||
| image_mask = image.clone().to(torch.long) | |||||
| image_mask[binary_mask_prompt]=255 | |||||
| save_img( | |||||
| torch.stack((image_mask,image_label,image),dim=0), | |||||
| f"ims/batch_{index}/prompt_{slice_id}.png", | |||||
| ) | |||||
| print(f'Recall={np.mean(recall_list)}') | |||||
| print(f'Percision={np.mean(percision_list)}') | |||||
| print(f'Jaccard={np.mean(jaccard_list)}') | |||||
| index += 1 | |||||
| print(f'Recall={np.mean(recall_list)}') | |||||
| print(f'Percision={np.mean(percision_list)}') | |||||
| print(f'Jaccard={np.mean(jaccard_list)}') | |||||
| else: | |||||
| print("Train model started.") | |||||
| train_losses = [] | |||||
| train_epochs = [] | |||||
| val_losses = [] | |||||
| val_epochs = [] | |||||
| dice = [] | |||||
| dice_val = [] | |||||
| results = [] | |||||
| last_best_dice=0 | |||||
| for epoch in range(args.num_epochs): | |||||
| print(f"=====================EPOCH: {epoch + 1}=====================") | |||||
| log_file.write(f"=====================EPOCH: {epoch + 1}===================\n") | |||||
| print("Training:") | |||||
| ( | |||||
| train_epoch_losses, | |||||
| results, | |||||
| dice_list, | |||||
| dice_prompt_list, | |||||
| dice_sam_list, | |||||
| dice_sam_prompt_list, | |||||
| ) = process_model(train_loader, train=1, epoch=epoch, scheduler=scheduler) | |||||
| dice_mean = np.mean(dice_list) | |||||
| dice_prompt_mean = np.mean(dice_prompt_list) | |||||
| dice_sam_mean = np.mean(dice_sam_list) | |||||
| dice_sam_prompt_mean = np.mean(dice_sam_prompt_list) | |||||
| print("Validating:") | |||||
| ( | |||||
| _, | |||||
| _, | |||||
| val_dice_list, | |||||
| val_dice_prompt_list, | |||||
| val_dice_sam_list, | |||||
| val_dice_sam_prompt_list, | |||||
| ) = process_model(val_loader) | |||||
| val_dice_mean = np.mean(val_dice_list) | |||||
| val_dice_prompt_mean = np.mean(val_dice_prompt_list) | |||||
| val_dice_sam_mean = np.mean(val_dice_sam_list) | |||||
| val_dice_sam_prompt_mean = np.mean(val_dice_sam_prompt_list) | |||||
| train_mean_losses = [mean(x) for x in train_losses] | |||||
| logs = "" | |||||
| logs += f"Train Dice_sam: {dice_sam_mean}\n" | |||||
| logs += f"Train Dice: {dice_mean}\n" | |||||
| logs += f"Train Dice_sam_prompt: {dice_sam_prompt_mean}\n" | |||||
| logs += f"Train Dice_prompt: {dice_prompt_mean}\n" | |||||
| logs += f"Mean train loss: {mean(train_epoch_losses)}\n" | |||||
| logs += f"val Dice_sam: {val_dice_sam_mean}\n" | |||||
| logs += f"val Dice: {val_dice_mean}\n" | |||||
| logs += f"val Dice_sam_prompt: {val_dice_sam_prompt_mean}\n" | |||||
| logs += f"val Dice_prompt: {val_dice_prompt_mean}\n" | |||||
| # plt.plot(val_epochs, val_mean_losses, train_epochs, train_mean_losses) | |||||
| if val_dice_prompt_mean > last_best_dice: | |||||
| torch.save( | |||||
| conv3d_instance, | |||||
| f"exps/{exp_id}-{user_input}/conv_save.pth", | |||||
| ) | |||||
| print("Model saved") | |||||
| last_best_dice = val_dice_prompt_mean | |||||
| print(logs) | |||||
| log_file.write(logs) | |||||
| scheduler.step() | |||||
| ## training with k-fold cross validation: | |||||
| fff = time() | |||||
| train_model(train_loader, val_loader,test_loader) | |||||
| log_file.close() | |||||
| # train and also test the model |
+ 90
- 0
kernel/loss.py
View File
| import torch | |||||
| from torch import nn | |||||
| import numpy as np | |||||
| class loss_fn(torch.nn.Module): | |||||
| def __init__(self, alpha=0.7, gamma=2.0, epsilon=1e-5): | |||||
| super(loss_fn, self).__init__() | |||||
| self.alpha = alpha | |||||
| self.gamma = gamma | |||||
| self.epsilon = epsilon | |||||
| def focal_tversky(self, y_pred, y_true, gamma=0.75): | |||||
| pt_1 = self.tversky_loss(y_pred, y_true) | |||||
| return torch.pow((1 - pt_1), gamma) | |||||
| def dice_loss(self, probs, gt, eps=1): | |||||
| intersection = (probs * gt).sum(dim=(-2,-1)) | |||||
| dice_coeff = (2.0 * intersection + eps) / (probs.sum(dim=(-2,-1)) + gt.sum(dim=(-2,-1)) + eps) | |||||
| loss = 1 - dice_coeff.mean() | |||||
| return loss | |||||
| def focal_loss(self, probs, gt, gamma=4): | |||||
| probs = probs.reshape(-1, 1) | |||||
| gt = gt.reshape(-1, 1) | |||||
| probs = torch.cat((1 - probs, probs), dim=1) | |||||
| pt = probs.gather(1, gt.long()) | |||||
| modulating_factor = (1 - pt) ** gamma | |||||
| # modulating_factor = (3**(10*((1-pt)-0.5)))*(1 - pt) ** gamma | |||||
| modulating_factor[pt>0.55] = 0.1*modulating_factor[pt>0.55] | |||||
| focal_loss = -modulating_factor * torch.log(pt + 1e-12) | |||||
| # Compute the mean focal loss | |||||
| loss = focal_loss.mean() | |||||
| return loss # Store as a Python number to save memory | |||||
| def forward(self, probs, target): | |||||
| self.gamma=8 | |||||
| dice_loss = self.dice_loss(probs, target) | |||||
| # tversky_loss = self.tversky_loss(logits, target) | |||||
| # Focal Loss | |||||
| focal_loss = self.focal_loss(probs, target,self.gamma) | |||||
| alpha = 20.0 | |||||
| # Combined Loss | |||||
| combined_loss = alpha * focal_loss + dice_loss | |||||
| return combined_loss | |||||
| def img_enhance(img2, coef=0.2): | |||||
| img_mean = np.mean(img2) | |||||
| img_max = np.max(img2) | |||||
| val = (img_max - img_mean) * coef + img_mean | |||||
| img2[img2 < img_mean * 0.7] = img_mean * 0.7 | |||||
| img2[img2 > val] = val | |||||
| return img2 | |||||
| def dice_coefficient(logits, gt): | |||||
| eps=1 | |||||
| binary_mask = logits>0 | |||||
| # raise ValueError( binary_mask.shape,gt.shape) | |||||
| intersection = (binary_mask * gt).sum(dim=(-2,-1)) | |||||
| dice_scores = (2.0 * intersection + eps) / (binary_mask.sum(dim=(-2,-1)) + gt.sum(dim=(-2,-1)) + eps) | |||||
| # raise ValueError(intersection.shape , binary_mask.shape,gt.shape) | |||||
| return dice_scores.mean() | |||||
| def calculate_accuracy(pred, target): | |||||
| correct = (pred == target).sum().item() | |||||
| total = target.numel() | |||||
| return correct / total | |||||
| def calculate_sensitivity(pred, target): | |||||
| smooth = 1 | |||||
| # Also known as recall | |||||
| true_positive = ((pred == 1) & (target == 1)).sum().item() | |||||
| false_negative = ((pred == 0) & (target == 1)).sum().item() | |||||
| return (true_positive + smooth) / ((true_positive + false_negative) + smooth) | |||||
| def calculate_specificity(pred, target): | |||||
| smooth = 1 | |||||
| true_negative = ((pred == 0) & (target == 0)).sum().item() | |||||
| false_positive = ((pred == 1) & (target == 0)).sum().item() | |||||
| return (true_negative + smooth) / ((true_negative + false_positive ) + smooth) |
+ 501
- 0
kernel/pre_processer.py
View File
| # This code has been taken from monai | |||||
| import matplotlib.pyplot as plt | |||||
| from typing import Tuple, Optional | |||||
| import os | |||||
| import math | |||||
| import torch.nn.functional as F | |||||
| import glob | |||||
| from pprint import pprint | |||||
| import tempfile | |||||
| import shutil | |||||
| import torchvision.transforms as transforms | |||||
| import pandas as pd | |||||
| import numpy as np | |||||
| import torch | |||||
| from einops import rearrange | |||||
| import nibabel as nib | |||||
| ############################### | |||||
| from typing import Collection, Hashable, Iterable, Sequence, TypeVar, Union, Mapping, Callable, Generator | |||||
| from enum import Enum | |||||
| from abc import ABC, abstractmethod | |||||
| from typing import Any, TypeVar | |||||
| from warnings import warn | |||||
| def _map_luts(interp_tiles: torch.Tensor, luts: torch.Tensor) -> torch.Tensor: | |||||
| r"""Assign the required luts to each tile. | |||||
| Args: | |||||
| interp_tiles (torch.Tensor): set of interpolation tiles. (B, 2GH, 2GW, C, TH/2, TW/2) | |||||
| luts (torch.Tensor): luts for each one of the original tiles. (B, GH, GW, C, 256) | |||||
| Returns: | |||||
| torch.Tensor: mapped luts (B, 2GH, 2GW, 4, C, 256) | |||||
| """ | |||||
| assert interp_tiles.dim() == 6, "interp_tiles tensor must be 6D." | |||||
| assert luts.dim() == 5, "luts tensor must be 5D." | |||||
| # gh, gw -> 2x the number of tiles used to compute the histograms | |||||
| # th, tw -> /2 the sizes of the tiles used to compute the histograms | |||||
| num_imgs, gh, gw, c, th, tw = interp_tiles.shape | |||||
| # precompute idxs for non corner regions (doing it in cpu seems sligthly faster) | |||||
| j_idxs = torch.ones(gh - 2, 4, dtype=torch.long) * torch.arange(1, gh - 1).reshape(gh - 2, 1) | |||||
| i_idxs = torch.ones(gw - 2, 4, dtype=torch.long) * torch.arange(1, gw - 1).reshape(gw - 2, 1) | |||||
| j_idxs = j_idxs // 2 + j_idxs % 2 | |||||
| j_idxs[:, 0:2] -= 1 | |||||
| i_idxs = i_idxs // 2 + i_idxs % 2 | |||||
| # i_idxs[:, [0, 2]] -= 1 # this slicing is not supported by jit | |||||
| i_idxs[:, 0] -= 1 | |||||
| i_idxs[:, 2] -= 1 | |||||
| # selection of luts to interpolate each patch | |||||
| # create a tensor with dims: interp_patches height and width x 4 x num channels x bins in the histograms | |||||
| # the tensor is init to -1 to denote non init hists | |||||
| luts_x_interp_tiles: torch.Tensor = -torch.ones( | |||||
| num_imgs, gh, gw, 4, c, luts.shape[-1], device=interp_tiles.device) # B x GH x GW x 4 x C x 256 | |||||
| # corner regions | |||||
| luts_x_interp_tiles[:, 0::gh - 1, 0::gw - 1, 0] = luts[:, 0::max(gh // 2 - 1, 1), 0::max(gw // 2 - 1, 1)] | |||||
| # border region (h) | |||||
| luts_x_interp_tiles[:, 1:-1, 0::gw - 1, 0] = luts[:, j_idxs[:, 0], 0::max(gw // 2 - 1, 1)] | |||||
| luts_x_interp_tiles[:, 1:-1, 0::gw - 1, 1] = luts[:, j_idxs[:, 2], 0::max(gw // 2 - 1, 1)] | |||||
| # border region (w) | |||||
| luts_x_interp_tiles[:, 0::gh - 1, 1:-1, 0] = luts[:, 0::max(gh // 2 - 1, 1), i_idxs[:, 0]] | |||||
| luts_x_interp_tiles[:, 0::gh - 1, 1:-1, 1] = luts[:, 0::max(gh // 2 - 1, 1), i_idxs[:, 1]] | |||||
| # internal region | |||||
| luts_x_interp_tiles[:, 1:-1, 1:-1, :] = luts[ | |||||
| :, j_idxs.repeat(max(gh - 2, 1), 1, 1).permute(1, 0, 2), i_idxs.repeat(max(gw - 2, 1), 1, 1)] | |||||
| return luts_x_interp_tiles | |||||
| def marginal_pdf(values: torch.Tensor, bins: torch.Tensor, sigma: torch.Tensor, | |||||
| epsilon: float = 1e-10) -> Tuple[torch.Tensor, torch.Tensor]: | |||||
| """Function that calculates the marginal probability distribution function of the input tensor | |||||
| based on the number of histogram bins. | |||||
| Args: | |||||
| values (torch.Tensor): shape [BxNx1]. | |||||
| bins (torch.Tensor): shape [NUM_BINS]. | |||||
| sigma (torch.Tensor): shape [1], gaussian smoothing factor. | |||||
| epsilon: (float), scalar, for numerical stability. | |||||
| Returns: | |||||
| Tuple[torch.Tensor, torch.Tensor]: | |||||
| - torch.Tensor: shape [BxN]. | |||||
| - torch.Tensor: shape [BxNxNUM_BINS]. | |||||
| """ | |||||
| if not isinstance(values, torch.Tensor): | |||||
| raise TypeError("Input values type is not a torch.Tensor. Got {}" | |||||
| .format(type(values))) | |||||
| if not isinstance(bins, torch.Tensor): | |||||
| raise TypeError("Input bins type is not a torch.Tensor. Got {}" | |||||
| .format(type(bins))) | |||||
| if not isinstance(sigma, torch.Tensor): | |||||
| raise TypeError("Input sigma type is not a torch.Tensor. Got {}" | |||||
| .format(type(sigma))) | |||||
| if not values.dim() == 3: | |||||
| raise ValueError("Input values must be a of the shape BxNx1." | |||||
| " Got {}".format(values.shape)) | |||||
| if not bins.dim() == 1: | |||||
| raise ValueError("Input bins must be a of the shape NUM_BINS" | |||||
| " Got {}".format(bins.shape)) | |||||
| if not sigma.dim() == 0: | |||||
| raise ValueError("Input sigma must be a of the shape 1" | |||||
| " Got {}".format(sigma.shape)) | |||||
| residuals = values - bins.unsqueeze(0).unsqueeze(0) | |||||
| kernel_values = torch.exp(-0.5 * (residuals / sigma).pow(2)) | |||||
| pdf = torch.mean(kernel_values, dim=1) | |||||
| normalization = torch.sum(pdf, dim=1).unsqueeze(1) + epsilon | |||||
| pdf = pdf / normalization | |||||
| return (pdf, kernel_values) | |||||
| def histogram(x: torch.Tensor, bins: torch.Tensor, bandwidth: torch.Tensor, | |||||
| epsilon: float = 1e-10) -> torch.Tensor: | |||||
| """Function that estimates the histogram of the input tensor. | |||||
| The calculation uses kernel density estimation which requires a bandwidth (smoothing) parameter. | |||||
| Args: | |||||
| x (torch.Tensor): Input tensor to compute the histogram with shape :math:`(B, D)`. | |||||
| bins (torch.Tensor): The number of bins to use the histogram :math:`(N_{bins})`. | |||||
| bandwidth (torch.Tensor): Gaussian smoothing factor with shape shape [1]. | |||||
| epsilon (float): A scalar, for numerical stability. Default: 1e-10. | |||||
| Returns: | |||||
| torch.Tensor: Computed histogram of shape :math:`(B, N_{bins})`. | |||||
| Examples: | |||||
| >>> x = torch.rand(1, 10) | |||||
| >>> bins = torch.torch.linspace(0, 255, 128) | |||||
| >>> hist = histogram(x, bins, bandwidth=torch.tensor(0.9)) | |||||
| >>> hist.shape | |||||
| torch.Size([1, 128]) | |||||
| """ | |||||
| pdf, _ = marginal_pdf(x.unsqueeze(2), bins, bandwidth, epsilon) | |||||
| return pdf | |||||
| def _compute_tiles(imgs: torch.Tensor, grid_size: Tuple[int, int], even_tile_size: bool = False | |||||
| ) -> Tuple[torch.Tensor, torch.Tensor]: | |||||
| r"""Compute tiles on an image according to a grid size. | |||||
| Note that padding can be added to the image in order to crop properly the image. | |||||
| So, the grid_size (GH, GW) x tile_size (TH, TW) >= image_size (H, W) | |||||
| Args: | |||||
| imgs (torch.Tensor): batch of 2D images with shape (B, C, H, W) or (C, H, W). | |||||
| grid_size (Tuple[int, int]): number of tiles to be cropped in each direction (GH, GW) | |||||
| even_tile_size (bool, optional): Determine if the width and height of the tiles must be even. Default: False. | |||||
| Returns: | |||||
| torch.Tensor: tensor with tiles (B, GH, GW, C, TH, TW). B = 1 in case of a single image is provided. | |||||
| torch.Tensor: tensor with the padded batch of 2D imageswith shape (B, C, H', W') | |||||
| """ | |||||
| batch: torch.Tensor = _to_bchw(imgs) # B x C x H x W | |||||
| # compute stride and kernel size | |||||
| h, w = batch.shape[-2:] | |||||
| # raise ValueError(batch.shape) | |||||
| kernel_vert: int = math.ceil(h / grid_size[0]) | |||||
| kernel_horz: int = math.ceil(w / grid_size[1]) | |||||
| if even_tile_size: | |||||
| kernel_vert += 1 if kernel_vert % 2 else 0 | |||||
| kernel_horz += 1 if kernel_horz % 2 else 0 | |||||
| # add padding (with that kernel size we could need some extra cols and rows...) | |||||
| pad_vert = kernel_vert * grid_size[0] - h | |||||
| pad_horz = kernel_horz * grid_size[1] - w | |||||
| # raise ValueError(pad_horz) | |||||
| # add the padding in the last coluns and rows | |||||
| if pad_vert > 0 or pad_horz > 0: | |||||
| batch = F.pad(batch, (0, pad_horz, 0, pad_vert), mode='reflect') # B x C x H' x W' | |||||
| # compute tiles | |||||
| c: int = batch.shape[-3] | |||||
| tiles: torch.Tensor = (batch.unfold(1, c, c) # unfold(dimension, size, step) | |||||
| .unfold(2, kernel_vert, kernel_vert) | |||||
| .unfold(3, kernel_horz, kernel_horz) | |||||
| .squeeze(1)) # GH x GW x C x TH x TW | |||||
| assert tiles.shape[-5] == grid_size[0] # check the grid size | |||||
| assert tiles.shape[-4] == grid_size[1] | |||||
| return tiles, batch | |||||
| def _to_bchw(tensor: torch.Tensor, color_channel_num: Optional[int] = None) -> torch.Tensor: | |||||
| """Converts a PyTorch tensor image to BCHW format. | |||||
| Args: | |||||
| tensor (torch.Tensor): image of the form :math:`(H, W)`, :math:`(C, H, W)`, :math:`(H, W, C)` or | |||||
| :math:`(B, C, H, W)`. | |||||
| color_channel_num (Optional[int]): Color channel of the input tensor. | |||||
| If None, it will not alter the input channel. | |||||
| Returns: | |||||
| torch.Tensor: input tensor of the form :math:`(B, C, H, W)`. | |||||
| """ | |||||
| if not isinstance(tensor, torch.Tensor): | |||||
| raise TypeError(f"Input type is not a torch.Tensor. Got {type(tensor)}") | |||||
| if len(tensor.shape) > 4 or len(tensor.shape) < 2: | |||||
| raise ValueError(f"Input size must be a two, three or four dimensional tensor. Got {tensor.shape}") | |||||
| if len(tensor.shape) == 2: | |||||
| tensor = tensor.unsqueeze(0) | |||||
| if len(tensor.shape) == 3: | |||||
| tensor = tensor.unsqueeze(0) | |||||
| # TODO(jian): this function is never used. Besides is not feasible for torchscript. | |||||
| # In addition, the docs must be updated. I don't understand what is doing. | |||||
| # if color_channel_num is not None and color_channel_num != 1: | |||||
| # channel_list = [0, 1, 2, 3] | |||||
| # channel_list.insert(1, channel_list.pop(color_channel_num)) | |||||
| # tensor = tensor.permute(*channel_list) | |||||
| return tensor | |||||
| def _compute_interpolation_tiles(padded_imgs: torch.Tensor, tile_size: Tuple[int, int]) -> torch.Tensor: | |||||
| r"""Compute interpolation tiles on a properly padded set of images. | |||||
| Note that images must be padded. So, the tile_size (TH, TW) * grid_size (GH, GW) = image_size (H, W) | |||||
| Args: | |||||
| padded_imgs (torch.Tensor): batch of 2D images with shape (B, C, H, W) already padded to extract tiles | |||||
| of size (TH, TW). | |||||
| tile_size (Tuple[int, int]): shape of the current tiles (TH, TW). | |||||
| Returns: | |||||
| torch.Tensor: tensor with the interpolation tiles (B, 2GH, 2GW, C, TH/2, TW/2). | |||||
| """ | |||||
| assert padded_imgs.dim() == 4, "Images Tensor must be 4D." | |||||
| assert padded_imgs.shape[-2] % tile_size[0] == 0, "Images are not correctly padded." | |||||
| assert padded_imgs.shape[-1] % tile_size[1] == 0, "Images are not correctly padded." | |||||
| # tiles to be interpolated are built by dividing in 4 each alrady existing | |||||
| interp_kernel_vert: int = tile_size[0] // 2 | |||||
| interp_kernel_horz: int = tile_size[1] // 2 | |||||
| c: int = padded_imgs.shape[-3] | |||||
| interp_tiles: torch.Tensor = (padded_imgs.unfold(1, c, c) | |||||
| .unfold(2, interp_kernel_vert, interp_kernel_vert) | |||||
| .unfold(3, interp_kernel_horz, interp_kernel_horz) | |||||
| .squeeze(1)) # 2GH x 2GW x C x TH/2 x TW/2 | |||||
| assert interp_tiles.shape[-3] == c | |||||
| assert interp_tiles.shape[-2] == tile_size[0] / 2 | |||||
| assert interp_tiles.shape[-1] == tile_size[1] / 2 | |||||
| return interp_tiles | |||||
| def _compute_luts(tiles_x_im: torch.Tensor, num_bins: int = 256, clip: float = 40., diff: bool = False) -> torch.Tensor: | |||||
| r"""Compute luts for a batched set of tiles. | |||||
| Same approach as in OpenCV (https://github.com/opencv/opencv/blob/master/modules/imgproc/src/clahe.cpp) | |||||
| Args: | |||||
| tiles_x_im (torch.Tensor): set of tiles per image to apply the lut. (B, GH, GW, C, TH, TW) | |||||
| num_bins (int, optional): number of bins. default: 256 | |||||
| clip (float): threshold value for contrast limiting. If it is 0 then the clipping is disabled. Default: 40. | |||||
| diff (bool, optional): denote if the differentiable histagram will be used. Default: False | |||||
| Returns: | |||||
| torch.Tensor: Lut for each tile (B, GH, GW, C, 256) | |||||
| """ | |||||
| assert tiles_x_im.dim() == 6, "Tensor must be 6D." | |||||
| b, gh, gw, c, th, tw = tiles_x_im.shape | |||||
| pixels: int = th * tw | |||||
| tiles: torch.Tensor = tiles_x_im.reshape(-1, pixels) # test with view # T x (THxTW) | |||||
| histos: torch.Tensor = torch.empty((tiles.shape[0], num_bins), device=tiles.device) | |||||
| if not diff: | |||||
| for i in range(tiles.shape[0]): | |||||
| histos[i] = torch.histc(tiles[i], bins=num_bins, min=0, max=1) | |||||
| else: | |||||
| bins: torch.Tensor = torch.linspace(0, 1, num_bins, device=tiles.device) | |||||
| histos = histogram(tiles, bins, torch.tensor(0.001)).squeeze() | |||||
| histos *= pixels | |||||
| # clip limit (TODO: optimice the code) | |||||
| if clip > 0.: | |||||
| clip_limit: torch.Tensor = torch.tensor( | |||||
| max(clip * pixels // num_bins, 1), dtype=histos.dtype, device=tiles.device) | |||||
| clip_idxs: torch.Tensor = histos > clip_limit | |||||
| for i in range(histos.shape[0]): | |||||
| hist: torch.Tensor = histos[i] | |||||
| idxs = clip_idxs[i] | |||||
| if idxs.any(): | |||||
| clipped: float = float((hist[idxs] - clip_limit).sum().item()) | |||||
| hist = torch.where(idxs, clip_limit, hist) | |||||
| redist: float = clipped // num_bins | |||||
| hist += redist | |||||
| residual: float = clipped - redist * num_bins | |||||
| if residual: | |||||
| hist[0:int(residual)] += 1 | |||||
| histos[i] = hist | |||||
| lut_scale: float = (num_bins - 1) / pixels | |||||
| luts: torch.Tensor = torch.cumsum(histos, 1) * lut_scale | |||||
| luts = luts.clamp(0, num_bins - 1).floor() # to get the same values as converting to int maintaining the type | |||||
| luts = luts.view((b, gh, gw, c, num_bins)) | |||||
| return luts | |||||
| def _compute_equalized_tiles(interp_tiles: torch.Tensor, luts: torch.Tensor) -> torch.Tensor: | |||||
| r"""Equalize the tiles. | |||||
| Args: | |||||
| interp_tiles (torch.Tensor): set of interpolation tiles, values must be in the range [0, 1]. | |||||
| (B, 2GH, 2GW, C, TH/2, TW/2) | |||||
| luts (torch.Tensor): luts for each one of the original tiles. (B, GH, GW, C, 256) | |||||
| Returns: | |||||
| torch.Tensor: equalized tiles (B, 2GH, 2GW, C, TH/2, TW/2) | |||||
| """ | |||||
| assert interp_tiles.dim() == 6, "interp_tiles tensor must be 6D." | |||||
| assert luts.dim() == 5, "luts tensor must be 5D." | |||||
| mapped_luts: torch.Tensor = _map_luts(interp_tiles, luts) # Bx2GHx2GWx4xCx256 | |||||
| # gh, gw -> 2x the number of tiles used to compute the histograms | |||||
| # th, tw -> /2 the sizes of the tiles used to compute the histograms | |||||
| num_imgs, gh, gw, c, th, tw = interp_tiles.shape | |||||
| # print(interp_tiles.max()) | |||||
| # equalize tiles | |||||
| flatten_interp_tiles: torch.Tensor = (interp_tiles * 255).long().flatten(-2, -1) # B x GH x GW x 4 x C x (THxTW) | |||||
| flatten_interp_tiles = flatten_interp_tiles.unsqueeze(-3).expand(num_imgs, gh, gw, 4, c, th * tw) | |||||
| # raise ValueError(flatten_interp_tiles.max()) | |||||
| k=torch.gather(mapped_luts, 5, flatten_interp_tiles) | |||||
| preinterp_tiles_equalized = torch.gather(mapped_luts, 5, flatten_interp_tiles).reshape(num_imgs, gh, gw, 4, c, th, tw) # B x GH x GW x 4 x C x TH x TW | |||||
| # interp tiles | |||||
| tiles_equalized: torch.Tensor = torch.zeros_like(interp_tiles, dtype=torch.long) | |||||
| # compute the interpolation weights (shapes are 2 x TH x TW because they must be applied to 2 interp tiles) | |||||
| ih = torch.arange(2 * th - 1, -1, -1, device=interp_tiles.device).div( | |||||
| 2. * th - 1)[None].transpose(-2, -1).expand(2 * th, tw) | |||||
| ih = ih.unfold(0, th, th).unfold(1, tw, tw) # 2 x 1 x TH x TW | |||||
| iw = torch.arange(2 * tw - 1, -1, -1, device=interp_tiles.device).div(2. * tw - 1).expand(th, 2 * tw) | |||||
| iw = iw.unfold(0, th, th).unfold(1, tw, tw) # 1 x 2 x TH x TW | |||||
| # compute row and column interpolation weigths | |||||
| tiw = iw.expand((gw - 2) // 2, 2, th, tw).reshape(gw - 2, 1, th, tw).unsqueeze(0) # 1 x GW-2 x 1 x TH x TW | |||||
| tih = ih.repeat((gh - 2) // 2, 1, 1, 1).unsqueeze(1) # GH-2 x 1 x 1 x TH x TW | |||||
| # internal regions | |||||
| tl, tr, bl, br = preinterp_tiles_equalized[:, 1:-1, 1:-1].unbind(3) | |||||
| t = tiw * (tl - tr) + tr | |||||
| b = tiw * (bl - br) + br | |||||
| tiles_equalized[:, 1:-1, 1:-1] = tih * (t - b) + b | |||||
| # corner regions | |||||
| tiles_equalized[:, 0::gh - 1, 0::gw - 1] = preinterp_tiles_equalized[:, 0::gh - 1, 0::gw - 1, 0] | |||||
| # border region (h) | |||||
| t, b, _, _ = preinterp_tiles_equalized[:, 1:-1, 0].unbind(2) | |||||
| tiles_equalized[:, 1:-1, 0] = tih.squeeze(1) * (t - b) + b | |||||
| t, b, _, _ = preinterp_tiles_equalized[:, 1:-1, gh - 1].unbind(2) | |||||
| tiles_equalized[:, 1:-1, gh - 1] = tih.squeeze(1) * (t - b) + b | |||||
| # border region (w) | |||||
| l, r, _, _ = preinterp_tiles_equalized[:, 0, 1:-1].unbind(2) | |||||
| tiles_equalized[:, 0, 1:-1] = tiw * (l - r) + r | |||||
| l, r, _, _ = preinterp_tiles_equalized[:, gw - 1, 1:-1].unbind(2) | |||||
| tiles_equalized[:, gw - 1, 1:-1] = tiw * (l - r) + r | |||||
| # same type as the input | |||||
| return tiles_equalized.to(interp_tiles).div(255.) | |||||
| def equalize_clahe(input: torch.Tensor, clip_limit: float = 40., grid_size: Tuple[int, int] = (8, 8)) -> torch.Tensor: | |||||
| r"""Apply clahe equalization on the input tensor. | |||||
| NOTE: Lut computation uses the same approach as in OpenCV, in next versions this can change. | |||||
| Args: | |||||
| input (torch.Tensor): images tensor to equalize with values in the range [0, 1] and shapes like | |||||
| :math:`(C, H, W)` or :math:`(B, C, H, W)`. | |||||
| clip_limit (float): threshold value for contrast limiting. If 0 clipping is disabled. Default: 40. | |||||
| grid_size (Tuple[int, int]): number of tiles to be cropped in each direction (GH, GW). Default: (8, 8). | |||||
| Returns: | |||||
| torch.Tensor: Equalized image or images with shape as the input. | |||||
| Examples: | |||||
| >>> img = torch.rand(1, 10, 20) | |||||
| >>> res = equalize_clahe(img) | |||||
| >>> res.shape | |||||
| torch.Size([1, 10, 20]) | |||||
| >>> img = torch.rand(2, 3, 10, 20) | |||||
| >>> res = equalize_clahe(img) | |||||
| >>> res.shape | |||||
| torch.Size([2, 3, 10, 20]) | |||||
| """ | |||||
| if not isinstance(input, torch.Tensor): | |||||
| raise TypeError(f"Input input type is not a torch.Tensor. Got {type(input)}") | |||||
| if input.dim() not in [3, 4]: | |||||
| raise ValueError(f"Invalid input shape, we expect CxHxW or BxCxHxW. Got: {input.shape}") | |||||
| if input.dim() ==3 and len(input) not in [1,3]: | |||||
| raise ValueError(f'What type of image is this? The first dimension should be batch or channel number') | |||||
| if input.numel() == 0: | |||||
| raise ValueError("Invalid input tensor, it is empty.") | |||||
| if not isinstance(clip_limit, float): | |||||
| raise TypeError(f"Input clip_limit type is not float. Got {type(clip_limit)}") | |||||
| if not isinstance(grid_size, tuple): | |||||
| raise TypeError(f"Input grid_size type is not Tuple. Got {type(grid_size)}") | |||||
| if len(grid_size) != 2: | |||||
| raise TypeError(f"Input grid_size is not a Tuple with 2 elements. Got {len(grid_size)}") | |||||
| if isinstance(grid_size[0], float) or isinstance(grid_size[1], float): | |||||
| raise TypeError("Input grid_size type is not valid, must be a Tuple[int, int].") | |||||
| if grid_size[0] <= 0 or grid_size[1] <= 0: | |||||
| raise ValueError("Input grid_size elements must be positive. Got {grid_size}") | |||||
| imgs: torch.Tensor = _to_bchw(input) # B x C x H x W | |||||
| # hist_tiles: torch.Tensor # B x GH x GW x C x TH x TW # not supported by JIT | |||||
| # img_padded: torch.Tensor # B x C x H' x W' # not supported by JIT | |||||
| # the size of the tiles must be even in order to divide them into 4 tiles for the interpolation | |||||
| hist_tiles, img_padded = _compute_tiles(imgs, grid_size, True) | |||||
| tile_size: Tuple[int, int] = (hist_tiles.shape[-2], hist_tiles.shape[-1]) | |||||
| # print(imgs.max()) | |||||
| interp_tiles: torch.Tensor = ( | |||||
| _compute_interpolation_tiles(img_padded, tile_size)) # B x 2GH x 2GW x C x TH/2 x TW/2 | |||||
| luts: torch.Tensor = _compute_luts(hist_tiles, clip=clip_limit) # B x GH x GW x C x B | |||||
| equalized_tiles: torch.Tensor = _compute_equalized_tiles(interp_tiles, luts) # B x 2GH x 2GW x C x TH/2 x TW/2 | |||||
| # reconstruct the images form the tiles | |||||
| eq_imgs: torch.Tensor = torch.cat(equalized_tiles.unbind(2), 4) | |||||
| eq_imgs = torch.cat(eq_imgs.unbind(1), 2) | |||||
| h, w = imgs.shape[-2:] | |||||
| eq_imgs = eq_imgs[..., :h, :w] # crop imgs if they were padded | |||||
| # remove batch if the input was not in batch form | |||||
| if input.dim() != eq_imgs.dim(): | |||||
| eq_imgs = eq_imgs.squeeze(0) | |||||
| return eq_imgs | |||||
| ############## | |||||
| def histo(image): | |||||
| # Calculate the histogram | |||||
| min=np.min(image) | |||||
| max=np.max(image) | |||||
| histogram, bins = np.histogram(image.flatten(), bins=np.linspace(min,max,100)) | |||||
| # Plot the histogram | |||||
| plt.figure() | |||||
| plt.title('Histogram') | |||||
| plt.xlabel('Pixel Value') | |||||
| plt.ylabel('Frequency') | |||||
| plt.bar(bins[:-1], histogram, width=1) | |||||
| # Display the histogram | |||||
| # plt.show() | |||||
| ## class for data pre-processing | |||||
| class PreProcessing: | |||||
| def CLAHE(img, clip_limit=40.0,grid_size=(8,8)): | |||||
| img=equalize_clahe( img,clip_limit,grid_size) | |||||
| return img | |||||
| def INTERPOLATE(img, size=(64),mode='linear',align_corners=False): | |||||
| img=F.interpolate( img,size=size, mode=mode, align_corners=False) | |||||
| return img | |||||
+ 11
- 0
kernel/run.sh
View File
| #!/bin/bash | |||||
| rm -r ims | |||||
| mkdir ims | |||||
| python3 fine_tune_good_unet.py --sample_size 4 --accumulative_batch_size 4\ | |||||
| --num_epochs 60 --num_workers 8 --batch_step_one 20\ | |||||
| --batch_step_two 30 --lr 1e-3\ | |||||
| --train_dir "The path to your train data"\ | |||||
| --test_dir "The path to your test data"\ | |||||
| --model_path "The path to pre-trained sam model" |
+ 122
- 0
kernel/utils.py
View File
| import torch | |||||
| import torch.nn as nn | |||||
| import numpy as np | |||||
| import torch.nn.functional as F | |||||
| def create_prompt_simple(masks, forground=2, background=2): | |||||
| kernel_size = 9 | |||||
| kernel = nn.Conv2d( | |||||
| in_channels=1, | |||||
| bias=False, | |||||
| out_channels=1, | |||||
| kernel_size=kernel_size, | |||||
| stride=1, | |||||
| padding=kernel_size // 2, | |||||
| ) | |||||
| # print(kernel.weight.shape) | |||||
| kernel.weight = nn.Parameter( | |||||
| torch.zeros(1, 1, kernel_size, kernel_size).to(masks.device), | |||||
| requires_grad=False, | |||||
| ) | |||||
| kernel.weight[0, 0] = 1.0 | |||||
| eroded_masks = kernel(masks).squeeze(1)//(kernel_size**2) | |||||
| masks = masks.squeeze(1) | |||||
| use_eroded = (eroded_masks.sum(dim=(1, 2), keepdim=True) >= forground).float() | |||||
| new_masks = (eroded_masks * use_eroded) + (masks * (1 - use_eroded)) | |||||
| all_points = [] | |||||
| all_labels = [] | |||||
| for i in range(len(new_masks)): | |||||
| new_background = background | |||||
| points = [] | |||||
| labels = [] | |||||
| new_mask = new_masks[i] | |||||
| nonzeros = torch.nonzero(new_mask, as_tuple=False) | |||||
| n_nonzero = len(nonzeros) | |||||
| if n_nonzero >= forground: | |||||
| indices = np.random.choice( | |||||
| np.arange(n_nonzero), size=forground, replace=False | |||||
| ).tolist() | |||||
| # raise ValueError(nonzeros[:, [0, 1]][indices]) | |||||
| points.append(nonzeros[:, [1,0]][indices]) | |||||
| labels.append(torch.ones(forground)) | |||||
| else: | |||||
| if n_nonzero > 0: | |||||
| points.append(nonzeros) | |||||
| labels.append(torch.ones(n_nonzero)) | |||||
| new_background += forground - n_nonzero | |||||
| # print(points, new_background) | |||||
| zeros = torch.nonzero(1 - masks[i], as_tuple=False) | |||||
| n_zero = len(zeros) | |||||
| indices = np.random.choice( | |||||
| np.arange(n_zero), size=new_background, replace=False | |||||
| ).tolist() | |||||
| points.append(zeros[:, [1, 0]][indices]) | |||||
| labels.append(torch.zeros(new_background)) | |||||
| points = torch.cat(points, dim=0) | |||||
| labels = torch.cat(labels, dim=0) | |||||
| all_points.append(points) | |||||
| all_labels.append(labels) | |||||
| all_points = torch.stack(all_points, dim=0) | |||||
| all_labels = torch.stack(all_labels, dim=0) | |||||
| return all_points, all_labels | |||||
| # | |||||
| device = "cuda:0" | |||||
| def create_prompt_main(probabilities): | |||||
| probabilities = probabilities.sigmoid() | |||||
| # Thresholding function | |||||
| def threshold(tensor, thresh): | |||||
| return (tensor > thresh).float() | |||||
| # Morphological operations | |||||
| def morphological_op(tensor, operation, kernel_size): | |||||
| kernel = torch.ones(1, 1, kernel_size[0], kernel_size[1]).to(tensor.device) | |||||
| if kernel_size[0] % 2 == 0: | |||||
| padding = [(k - 1) // 2 for k in kernel_size] | |||||
| extra_pad = [0, 2, 0, 2] | |||||
| else: | |||||
| padding = [(k - 1) // 2 for k in kernel_size] | |||||
| extra_pad = [0, 0, 0, 0] | |||||
| if operation == 'erode': | |||||
| tensor = F.conv2d(F.pad(tensor, extra_pad), kernel, padding=padding).clamp(max=1) | |||||
| elif operation == 'dilate': | |||||
| tensor = F.max_pool2d(F.pad(tensor, extra_pad), kernel_size, stride=1, padding=padding).clamp(max=1) | |||||
| if kernel_size[0] % 2 == 0: | |||||
| tensor = tensor[:, :, :tensor.shape[2] - 1, :tensor.shape[3] - 1] | |||||
| return tensor.squeeze(1) | |||||
| # Foreground prompts | |||||
| th_O = threshold(probabilities, 0.5) | |||||
| M_f = morphological_op(morphological_op(th_O, 'erode', (10, 10)), 'dilate', (5, 5)) | |||||
| foreground_indices = torch.nonzero(M_f.squeeze(0), as_tuple=False) | |||||
| n_for = 2 if len(foreground_indices) >= 2 else len(foreground_indices) | |||||
| n_back = 4 - n_for | |||||
| # Background prompts | |||||
| M_b1 = 1 - morphological_op(threshold(probabilities, 0.5), 'dilate', (10, 10)) | |||||
| M_b2 = 1 - threshold(probabilities, 0.4) | |||||
| M_b2 = M_b2.squeeze(1) | |||||
| M_b = M_b1 * M_b2 | |||||
| M_b = M_b.squeeze(0) | |||||
| background_indices = torch.nonzero(M_b, as_tuple=False) | |||||
| if n_for > 0: | |||||
| indices = torch.concat([foreground_indices[np.random.choice(np.arange(len(foreground_indices)), size=n_for)], | |||||
| background_indices[np.random.choice(np.arange(len(background_indices)), size=n_back)] | |||||
| ]) | |||||
| values = torch.tensor([1] * n_for + [0] * n_back) | |||||
| else: | |||||
| indices = background_indices[np.random.choice(np.arange(len(background_indices)), size=4)] | |||||
| values = torch.tensor([0] * 4) | |||||
| # raise ValueError(indices, values) | |||||
| return indices.unsqueeze(0), values.unsqueeze(0) | |||||
+ 148
- 0
requirements.txt
View File
| addict==2.4.0 | |||||
| albumentations==1.3.1 | |||||
| aliyun-python-sdk-core==2.14.0 | |||||
| aliyun-python-sdk-kms==2.16.2 | |||||
| asttokens @ file:///home/conda/feedstock_root/build_artifacts/asttokens_1694046349000/work | |||||
| backcall @ file:///home/conda/feedstock_root/build_artifacts/backcall_1592338393461/work | |||||
| backports.functools-lru-cache @ file:///home/conda/feedstock_root/build_artifacts/backports.functools_lru_cache_1687772187254/work | |||||
| brotlipy==0.7.0 | |||||
| certifi @ file:///croot/certifi_1690232220950/work/certifi | |||||
| cffi==1.16.0 | |||||
| charset-normalizer @ file:///tmp/build/80754af9/charset-normalizer_1630003229654/work | |||||
| click==8.1.7 | |||||
| cmake==3.27.5 | |||||
| colorama==0.4.6 | |||||
| coloredlogs==15.0.1 | |||||
| comm @ file:///home/conda/feedstock_root/build_artifacts/comm_1691044910542/work | |||||
| contourpy @ file:///work/ci_py311/contourpy_1676827066340/work | |||||
| crcmod==1.7 | |||||
| cryptography @ file:///croot/cryptography_1694444244250/work | |||||
| cycler @ file:///tmp/build/80754af9/cycler_1637851556182/work | |||||
| debugpy @ file:///croot/debugpy_1690905042057/work | |||||
| decorator @ file:///home/conda/feedstock_root/build_artifacts/decorator_1641555617451/work | |||||
| einops==0.6.1 | |||||
| exceptiongroup @ file:///home/conda/feedstock_root/build_artifacts/exceptiongroup_1692026125334/work | |||||
| executing @ file:///home/conda/feedstock_root/build_artifacts/executing_1667317341051/work | |||||
| filelock==3.12.4 | |||||
| flatbuffers==23.5.26 | |||||
| fonttools==4.25.0 | |||||
| gmpy2 @ file:///work/ci_py311/gmpy2_1676839849213/work | |||||
| humanfriendly==10.0 | |||||
| idna @ file:///work/ci_py311/idna_1676822698822/work | |||||
| imageio==2.31.4 | |||||
| importlib-metadata @ file:///home/conda/feedstock_root/build_artifacts/importlib-metadata_1688754491823/work | |||||
| ipykernel @ file:///home/conda/feedstock_root/build_artifacts/ipykernel_1693880262622/work | |||||
| ipython @ file:///home/conda/feedstock_root/build_artifacts/ipython_1693579759651/work | |||||
| jedi @ file:///home/conda/feedstock_root/build_artifacts/jedi_1690896916983/work | |||||
| Jinja2 @ file:///work/ci_py311/jinja2_1676823587943/work | |||||
| jmespath==0.10.0 | |||||
| joblib==1.3.2 | |||||
| jupyter_client @ file:///home/conda/feedstock_root/build_artifacts/jupyter_client_1693317508789/work | |||||
| jupyter_core @ file:///home/conda/feedstock_root/build_artifacts/jupyter_core_1695827980501/work | |||||
| kiwisolver @ file:///work/ci_py311/kiwisolver_1676827230232/work | |||||
| lazy_loader==0.3 | |||||
| lit==17.0.1 | |||||
| Markdown==3.4.4 | |||||
| markdown-it-py==3.0.0 | |||||
| MarkupSafe @ file:///work/ci_py311/markupsafe_1676823507015/work | |||||
| mat4py==0.5.0 | |||||
| matplotlib @ file:///croot/matplotlib-suite_1693812469450/work | |||||
| matplotlib-inline @ file:///home/conda/feedstock_root/build_artifacts/matplotlib-inline_1660814786464/work | |||||
| mdurl==0.1.2 | |||||
| mkl-fft @ file:///croot/mkl_fft_1695058164594/work | |||||
| mkl-random @ file:///croot/mkl_random_1695059800811/work | |||||
| mkl-service==2.4.0 | |||||
| mmcv==2.0.1 | |||||
| -e git+https://github.com/open-mmlab/mmdetection.git@f78af7785ada87f1ced75a2313746e4ba3149760#egg=mmdet | |||||
| mmengine==0.8.5 | |||||
| mmpretrain==1.0.2 | |||||
| model-index==0.1.11 | |||||
| modelindex==0.0.2 | |||||
| motmetrics==1.4.0 | |||||
| mpmath @ file:///croot/mpmath_1690848262763/work | |||||
| munkres==1.1.4 | |||||
| nest-asyncio @ file:///home/conda/feedstock_root/build_artifacts/nest-asyncio_1664684991461/work | |||||
| networkx @ file:///croot/networkx_1690561992265/work | |||||
| nibabel @ file:///home/conda/feedstock_root/build_artifacts/nibabel_1680908467684/work | |||||
| numpy @ file:///croot/numpy_and_numpy_base_1691091611330/work | |||||
| nvidia-cublas-cu11==11.10.3.66 | |||||
| nvidia-cuda-cupti-cu11==11.7.101 | |||||
| nvidia-cuda-nvrtc-cu11==11.7.99 | |||||
| nvidia-cuda-runtime-cu11==11.7.99 | |||||
| nvidia-cudnn-cu11==8.5.0.96 | |||||
| nvidia-cufft-cu11==10.9.0.58 | |||||
| nvidia-curand-cu11==10.2.10.91 | |||||
| nvidia-cusolver-cu11==11.4.0.1 | |||||
| nvidia-cusparse-cu11==11.7.4.91 | |||||
| nvidia-nccl-cu11==2.14.3 | |||||
| nvidia-nvtx-cu11==11.7.91 | |||||
| onnx==1.14.1 | |||||
| onnxruntime==1.16.0 | |||||
| opencv-python-headless==4.8.1.78 | |||||
| opendatalab==0.0.10 | |||||
| openmim==0.3.9 | |||||
| openxlab==0.0.26 | |||||
| ordered-set==4.1.0 | |||||
| oss2==2.17.0 | |||||
| packaging @ file:///croot/packaging_1693575174725/work | |||||
| pandas==2.1.1 | |||||
| parso @ file:///home/conda/feedstock_root/build_artifacts/parso_1638334955874/work | |||||
| pexpect @ file:///home/conda/feedstock_root/build_artifacts/pexpect_1667297516076/work | |||||
| pickleshare @ file:///home/conda/feedstock_root/build_artifacts/pickleshare_1602536217715/work | |||||
| Pillow @ file:///croot/pillow_1695134008276/work | |||||
| platformdirs @ file:///home/conda/feedstock_root/build_artifacts/platformdirs_1690813113769/work | |||||
| ply==3.11 | |||||
| prompt-toolkit @ file:///home/conda/feedstock_root/build_artifacts/prompt-toolkit_1688565951714/work | |||||
| protobuf==4.24.3 | |||||
| psutil @ file:///work/ci_py311_2/psutil_1679337388738/work | |||||
| ptyprocess @ file:///home/conda/feedstock_root/build_artifacts/ptyprocess_1609419310487/work/dist/ptyprocess-0.7.0-py2.py3-none-any.whl | |||||
| pure-eval @ file:///home/conda/feedstock_root/build_artifacts/pure_eval_1642875951954/work | |||||
| pycocotools==2.0.7 | |||||
| pycparser @ file:///tmp/build/80754af9/pycparser_1636541352034/work | |||||
| pycryptodome==3.19.0 | |||||
| pydicom @ file:///home/conda/feedstock_root/build_artifacts/pydicom_1692139723652/work | |||||
| Pygments @ file:///home/conda/feedstock_root/build_artifacts/pygments_1691408637400/work | |||||
| pyOpenSSL @ file:///croot/pyopenssl_1690223430423/work | |||||
| pyparsing @ file:///work/ci_py311/pyparsing_1677811559502/work | |||||
| PyQt5-sip==12.11.0 | |||||
| PySocks @ file:///work/ci_py311/pysocks_1676822712504/work | |||||
| python-dateutil @ file:///tmp/build/80754af9/python-dateutil_1626374649649/work | |||||
| pytz==2023.3.post1 | |||||
| PyWavelets==1.4.1 | |||||
| PyYAML==6.0.1 | |||||
| pyzmq @ file:///croot/pyzmq_1686601365461/work | |||||
| qudida==0.0.4 | |||||
| requests==2.28.2 | |||||
| rich==13.4.2 | |||||
| scikit-image==0.21.0 | |||||
| scikit-learn==1.3.1 | |||||
| scipy==1.11.2 | |||||
| seaborn==0.13.0 | |||||
| -e git+ssh://[email protected]/facebookresearch/segment-anything.git@6fdee8f2727f4506cfbbe553e23b895e27956588#egg=segment_anything | |||||
| shapely==2.0.1 | |||||
| sip @ file:///work/ci_py311/sip_1676825117084/work | |||||
| six @ file:///tmp/build/80754af9/six_1644875935023/work | |||||
| stack-data @ file:///home/conda/feedstock_root/build_artifacts/stack_data_1669632077133/work | |||||
| sympy @ file:///work/ci_py311_2/sympy_1679339311852/work | |||||
| tabulate==0.9.0 | |||||
| termcolor==2.3.0 | |||||
| terminaltables==3.1.10 | |||||
| threadpoolctl==3.2.0 | |||||
| tifffile==2023.9.26 | |||||
| toml @ file:///tmp/build/80754af9/toml_1616166611790/work | |||||
| tomli==2.0.1 | |||||
| torch==2.0.1+cu118 | |||||
| torchaudio==2.0.2 | |||||
| torchvision==0.15.2 | |||||
| tornado @ file:///croot/tornado_1690848263220/work | |||||
| tqdm==4.65.2 | |||||
| trackeval @ git+https://github.com/JonathonLuiten/TrackEval.git@12c8791b303e0a0b50f753af204249e622d0281a | |||||
| traitlets @ file:///home/conda/feedstock_root/build_artifacts/traitlets_1695739569237/work | |||||
| triton==2.0.0 | |||||
| typing_extensions @ file:///home/conda/feedstock_root/build_artifacts/typing_extensions_1695040754690/work | |||||
| tzdata==2023.3 | |||||
| urllib3 @ file:///croot/urllib3_1686163155763/work | |||||
| wcwidth @ file:///home/conda/feedstock_root/build_artifacts/wcwidth_1673864653149/work | |||||
| xmltodict==0.13.0 | |||||
| yapf==0.40.2 | |||||
| zipp @ file:///home/conda/feedstock_root/build_artifacts/zipp_1695255097490/work |
+ 520
- 0
test_inference.py
View File
| debug = 1 | |||||
| from pathlib import Path | |||||
| import numpy as np | |||||
| import matplotlib.pyplot as plt | |||||
| # import cv2 | |||||
| from collections import defaultdict | |||||
| import torchvision.transforms as transforms | |||||
| import torch | |||||
| from torch import nn | |||||
| import torch.nn.functional as F | |||||
| from segment_anything.utils.transforms import ResizeLongestSide | |||||
| import albumentations as A | |||||
| from albumentations.pytorch import ToTensorV2 | |||||
| import numpy as np | |||||
| from einops import rearrange | |||||
| import random | |||||
| from tqdm import tqdm | |||||
| from time import sleep | |||||
| from data import * | |||||
| from time import time | |||||
| from PIL import Image | |||||
| from sklearn.model_selection import KFold | |||||
| from shutil import copyfile | |||||
| import monai | |||||
| from tqdm import tqdm | |||||
| from utils import sample_prompt | |||||
| from torch.autograd import Variable | |||||
| from args import get_arguments | |||||
| # import wandb_handler | |||||
| args = get_arguments() | |||||
| def save_img(img, dir): | |||||
| img = img.clone().cpu().numpy() + 100 | |||||
| if len(img.shape) == 3: | |||||
| img = rearrange(img, "c h w -> h w c") | |||||
| img_min = np.amin(img, axis=(0, 1), keepdims=True) | |||||
| img = img - img_min | |||||
| img_max = np.amax(img, axis=(0, 1), keepdims=True) | |||||
| img = (img / img_max * 255).astype(np.uint8) | |||||
| grey_img = Image.fromarray(img[:, :, 0]) | |||||
| img = Image.fromarray(img) | |||||
| else: | |||||
| img_min = img.min() | |||||
| img = img - img_min | |||||
| img_max = img.max() | |||||
| if img_max != 0: | |||||
| img = img / img_max * 255 | |||||
| img = Image.fromarray(img).convert("L") | |||||
| img.save(dir) | |||||
| class FocalLoss(nn.Module): | |||||
| def __init__(self, gamma=2.0, alpha=0.25): | |||||
| super(FocalLoss, self).__init__() | |||||
| self.gamma = gamma | |||||
| self.alpha = alpha | |||||
| def dice_loss(self, logits, gt, eps=1): | |||||
| # Convert logits to probabilities | |||||
| # Flatten the tensors | |||||
| # probs = probs.view(-1) | |||||
| # gt = gt.view(-1) | |||||
| probs = torch.sigmoid(logits) | |||||
| # Compute Dice coefficient | |||||
| intersection = (probs * gt).sum() | |||||
| dice_coeff = (2.0 * intersection + eps) / (probs.sum() + gt.sum() + eps) | |||||
| # Compute Dice Los[s | |||||
| loss = 1 - dice_coeff | |||||
| return loss | |||||
| def focal_loss(self, pred, mask): | |||||
| """ | |||||
| pred: [B, 1, H, W] | |||||
| mask: [B, 1, H, W] | |||||
| """ | |||||
| # pred=pred.reshape(-1,1) | |||||
| # mask = mask.reshape(-1,1) | |||||
| # assert pred.shape == mask.shape, "pred and mask should have the same shape." | |||||
| p = torch.sigmoid(pred) | |||||
| num_pos = torch.sum(mask) | |||||
| num_neg = mask.numel() - num_pos | |||||
| w_pos = (1 - p) ** self.gamma | |||||
| w_neg = p**self.gamma | |||||
| loss_pos = -self.alpha * mask * w_pos * torch.log(p + 1e-12) | |||||
| loss_neg = -(1 - self.alpha) * (1 - mask) * w_neg * torch.log(1 - p + 1e-12) | |||||
| loss = (torch.sum(loss_pos) + torch.sum(loss_neg)) / (num_pos + num_neg + 1e-12) | |||||
| return loss | |||||
| def forward(self, logits, target): | |||||
| logits = logits.squeeze(1) | |||||
| target = target.squeeze(1) | |||||
| # Dice Loss | |||||
| # prob = F.softmax(logits, dim=1)[:, 1, ...] | |||||
| dice_loss = self.dice_loss(logits, target) | |||||
| # Focal Loss | |||||
| focal_loss = self.focal_loss(logits, target.squeeze(-1)) | |||||
| alpha = 20.0 | |||||
| # Combined Loss | |||||
| combined_loss = alpha * focal_loss + dice_loss | |||||
| return combined_loss | |||||
| class loss_fn(torch.nn.Module): | |||||
| def __init__(self, alpha=0.7, gamma=2.0, epsilon=1e-5): | |||||
| super(loss_fn, self).__init__() | |||||
| self.alpha = alpha | |||||
| self.gamma = gamma | |||||
| self.epsilon = epsilon | |||||
| def dice_loss(self, logits, gt, eps=1): | |||||
| # Convert logits to probabilities | |||||
| # Flatten the tensorsx | |||||
| probs = torch.sigmoid(logits) | |||||
| probs = probs.view(-1) | |||||
| gt = gt.view(-1) | |||||
| # Compute Dice coefficient | |||||
| intersection = (probs * gt).sum() | |||||
| dice_coeff = (2.0 * intersection + eps) / (probs.sum() + gt.sum() + eps) | |||||
| # Compute Dice Los[s | |||||
| loss = 1 - dice_coeff | |||||
| return loss | |||||
| def focal_loss(self, logits, gt, gamma=4): | |||||
| logits = logits.reshape(-1, 1) | |||||
| gt = gt.reshape(-1, 1) | |||||
| logits = torch.cat((1 - logits, logits), dim=1) | |||||
| probs = torch.sigmoid(logits) | |||||
| pt = probs.gather(1, gt.long()) | |||||
| modulating_factor = (1 - pt) ** gamma | |||||
| # pt_false= pt<=0.5 | |||||
| # modulating_factor[pt_false] *= 2 | |||||
| focal_loss = -modulating_factor * torch.log(pt + 1e-12) | |||||
| # Compute the mean focal loss | |||||
| loss = focal_loss.mean() | |||||
| return loss # Store as a Python number to save memory | |||||
| def forward(self, logits, target): | |||||
| logits = logits.squeeze(1) | |||||
| target = target.squeeze(1) | |||||
| # Dice Loss | |||||
| # prob = F.softmax(logits, dim=1)[:, 1, ...] | |||||
| dice_loss = self.dice_loss(logits, target) | |||||
| # Focal Loss | |||||
| focal_loss = self.focal_loss(logits, target.squeeze(-1)) | |||||
| alpha = 20.0 | |||||
| # Combined Loss | |||||
| combined_loss = alpha * focal_loss + dice_loss | |||||
| return combined_loss | |||||
| def img_enhance(img2, coef=0.2): | |||||
| img_mean = np.mean(img2) | |||||
| img_max = np.max(img2) | |||||
| val = (img_max - img_mean) * coef + img_mean | |||||
| img2[img2 < img_mean * 0.7] = img_mean * 0.7 | |||||
| img2[img2 > val] = val | |||||
| return img2 | |||||
| def dice_coefficient(pred, target): | |||||
| smooth = 1 # Smoothing constant to avoid division by zero | |||||
| dice = 0 | |||||
| pred_index = pred | |||||
| target_index = target | |||||
| intersection = (pred_index * target_index).sum() | |||||
| union = pred_index.sum() + target_index.sum() | |||||
| dice += (2.0 * intersection + smooth) / (union + smooth) | |||||
| return dice.item() | |||||
| def calculate_accuracy(pred, target): | |||||
| correct = (pred == target).sum().item() | |||||
| total = target.numel() | |||||
| return correct / total | |||||
| def calculate_sensitivity(pred, target): | |||||
| smooth = 1 | |||||
| # Also known as recall | |||||
| true_positive = ((pred == 1) & (target == 1)).sum().item() | |||||
| false_negative = ((pred == 0) & (target == 1)).sum().item() | |||||
| return (true_positive + smooth) / ((true_positive + false_negative) + smooth) | |||||
| def calculate_specificity(pred, target): | |||||
| smooth = 1 | |||||
| true_negative = ((pred == 0) & (target == 0)).sum().item() | |||||
| false_positive = ((pred == 1) & (target == 0)).sum().item() | |||||
| return (true_negative + smooth) / ((true_negative + false_positive ) + smooth) | |||||
| # def calculate_recall(pred, target): # Same as sensitivity | |||||
| # return calculate_sensitivity(pred, target) | |||||
| accumaltive_batch_size = 512 | |||||
| batch_size = 2 | |||||
| num_workers = 4 | |||||
| slice_per_image = 1 | |||||
| num_epochs = 40 | |||||
| sample_size = 1800 | |||||
| # image_size=sam_model.image_encoder.img_size | |||||
| image_size = 1024 | |||||
| exp_id = 0 | |||||
| found = 0 | |||||
| # if debug: | |||||
| # user_input = "debug" | |||||
| # else: | |||||
| # user_input = input("Related changes: ") | |||||
| # while found == 0: | |||||
| # try: | |||||
| # os.makedirs(f"exps/{exp_id}-{user_input}") | |||||
| # found = 1 | |||||
| # except: | |||||
| # exp_id = exp_id + 1 | |||||
| # copyfile(os.path.realpath(__file__), f"exps/{exp_id}-{user_input}/code.py") | |||||
| layer_n = 4 | |||||
| L = layer_n | |||||
| a = np.full(L, layer_n) | |||||
| params = {"M": 255, "a": a, "p": 0.35} | |||||
| model_type = "vit_h" | |||||
| checkpoint = "checkpoints/sam_vit_h_4b8939.pth" | |||||
| device = "cuda:0" | |||||
| from segment_anything import SamPredictor, sam_model_registry | |||||
| # ////////////////// | |||||
| class panc_sam(nn.Module): | |||||
| def __init__(self, *args, **kwargs) -> None: | |||||
| super().__init__(*args, **kwargs) | |||||
| # self.sam = sam_model_registry[model_type](checkpoint=checkpoint) | |||||
| self.sam = torch.load( | |||||
| "sam_tuned_save.pth" | |||||
| ).sam | |||||
| def forward(self, batched_input): | |||||
| # with torch.no_grad(): | |||||
| input_images = torch.stack([x["image"] for x in batched_input], dim=0) | |||||
| with torch.no_grad(): | |||||
| image_embeddings = self.sam.image_encoder(input_images).detach() | |||||
| outputs = [] | |||||
| for image_record, curr_embedding in zip(batched_input, image_embeddings): | |||||
| if "point_coords" in image_record: | |||||
| points = (image_record["point_coords"].unsqueeze(0), image_record["point_labels"].unsqueeze(0)) | |||||
| else: | |||||
| raise ValueError('what the f?') | |||||
| points = None | |||||
| # raise ValueError(image_record["point_coords"].shape) | |||||
| with torch.no_grad(): | |||||
| sparse_embeddings, dense_embeddings = self.sam.prompt_encoder( | |||||
| points=points, | |||||
| boxes=image_record.get("boxes", None), | |||||
| masks=image_record.get("mask_inputs", None), | |||||
| ) | |||||
| #sparse_embeddings, dense_embeddings = self.sam.prompt_encoder( | |||||
| # points=None, | |||||
| # boxes=None, | |||||
| # masks=None, | |||||
| #) | |||||
| sparse_embeddings = sparse_embeddings / 5 | |||||
| dense_embeddings = dense_embeddings / 5 | |||||
| # raise ValueError(image_embeddings.shape) | |||||
| low_res_masks, _ = self.sam.mask_decoder( | |||||
| image_embeddings=curr_embedding.unsqueeze(0), | |||||
| image_pe=self.sam.prompt_encoder.get_dense_pe().detach(), | |||||
| sparse_prompt_embeddings=sparse_embeddings.detach(), | |||||
| dense_prompt_embeddings=dense_embeddings.detach(), | |||||
| multimask_output=False, | |||||
| ) | |||||
| outputs.append( | |||||
| { | |||||
| "low_res_logits": low_res_masks, | |||||
| } | |||||
| ) | |||||
| low_res_masks = torch.stack([x["low_res_logits"] for x in outputs], dim=0) | |||||
| return low_res_masks.squeeze(1) | |||||
| panc_sam_instance = panc_sam() | |||||
| panc_sam_instance.to(device) | |||||
| panc_sam_instance.eval() # Set the model to evaluation mode | |||||
| test_dataset = PanDataset( | |||||
| [args.test_dir], | |||||
| [args.test_labels_dir], | |||||
| [["NIH_PNG",1]], | |||||
| image_size, | |||||
| slice_per_image=slice_per_image, | |||||
| train=False, | |||||
| ) | |||||
| test_loader = DataLoader( | |||||
| test_dataset, | |||||
| batch_size=batch_size, | |||||
| collate_fn=test_dataset.collate_fn, | |||||
| shuffle=False, | |||||
| drop_last=False, | |||||
| num_workers=num_workers,) | |||||
| lr = 1e-4 | |||||
| max_lr = 1e-3 | |||||
| wd = 5e-4 | |||||
| optimizer = torch.optim.Adam( | |||||
| # parameters, | |||||
| list(panc_sam_instance.sam.mask_decoder.parameters()), | |||||
| lr=lr, | |||||
| weight_decay=wd, | |||||
| ) | |||||
| scheduler = torch.optim.lr_scheduler.OneCycleLR( | |||||
| optimizer, | |||||
| max_lr=max_lr, | |||||
| epochs=num_epochs, | |||||
| steps_per_epoch=sample_size // (accumaltive_batch_size // batch_size), | |||||
| ) | |||||
| loss_function = loss_fn(alpha=0.5, gamma=2.0) | |||||
| loss_function.to(device) | |||||
| from statistics import mean | |||||
| from tqdm import tqdm | |||||
| from torch.nn.functional import threshold, normalize | |||||
| def process_model(data_loader, train=False, save_output=0): | |||||
| epoch_losses = [] | |||||
| index = 0 | |||||
| results = torch.zeros((2, 0, 256, 256)) | |||||
| total_dice = 0.0 | |||||
| total_accuracy = 0.0 | |||||
| total_sensitivity = 0.0 | |||||
| total_specificity = 0.0 | |||||
| num_samples = 0 | |||||
| counterb = 0 | |||||
| for image, label in tqdm(data_loader, total=sample_size): | |||||
| counterb += 1 | |||||
| index += 1 | |||||
| image = image.to(device) | |||||
| label = label.to(device).float() | |||||
| points, point_labels = sample_prompt(label) | |||||
| batched_input = [] | |||||
| for ibatch in range(batch_size): | |||||
| batched_input.append( | |||||
| { | |||||
| "image": image[ibatch], | |||||
| "point_coords": points[ibatch], | |||||
| "point_labels": point_labels[ibatch], | |||||
| "original_size": (1024, 1024) | |||||
| }, | |||||
| ) | |||||
| low_res_masks = panc_sam_instance(batched_input) | |||||
| low_res_label = F.interpolate(label, low_res_masks.shape[-2:]) | |||||
| binary_mask = normalize(threshold(low_res_masks, 0.0,0)) | |||||
| loss = loss_function(low_res_masks, low_res_label) | |||||
| loss /= (accumaltive_batch_size / batch_size) | |||||
| opened_binary_mask = torch.zeros_like(binary_mask).cpu() | |||||
| for j, mask in enumerate(binary_mask[:, 0]): | |||||
| numpy_mask = mask.detach().cpu().numpy().astype(np.uint8) | |||||
| opened_binary_mask[j][0] = torch.from_numpy(numpy_mask) | |||||
| dice = dice_coefficient( | |||||
| opened_binary_mask.numpy(), low_res_label.cpu().detach().numpy() | |||||
| ) | |||||
| accuracy = calculate_accuracy(binary_mask, low_res_label) | |||||
| sensitivity = calculate_sensitivity(binary_mask, low_res_label) | |||||
| specificity = calculate_specificity(binary_mask, low_res_label) | |||||
| total_accuracy += accuracy | |||||
| total_sensitivity += sensitivity | |||||
| total_specificity += specificity | |||||
| total_dice += dice | |||||
| num_samples += 1 | |||||
| average_dice = total_dice / num_samples | |||||
| average_accuracy = total_accuracy / num_samples | |||||
| average_sensitivity = total_sensitivity / num_samples | |||||
| average_specificity = total_specificity / num_samples | |||||
| if train: | |||||
| loss.backward() | |||||
| if index % (accumaltive_batch_size / batch_size) == 0: | |||||
| optimizer.step() | |||||
| scheduler.step() | |||||
| optimizer.zero_grad() | |||||
| index = 0 | |||||
| else: | |||||
| result = torch.cat( | |||||
| ( | |||||
| low_res_masks[0].detach().cpu().reshape(1, 1, 256, 256), | |||||
| opened_binary_mask[0].reshape(1, 1, 256, 256), | |||||
| ), | |||||
| dim=0, | |||||
| ) | |||||
| results = torch.cat((results, result), dim=1) | |||||
| if index % (accumaltive_batch_size / batch_size) == 0: | |||||
| epoch_losses.append(loss.item()) | |||||
| if counterb == sample_size: | |||||
| break | |||||
| return epoch_losses, results, average_dice , average_accuracy , average_sensitivity ,average_specificity | |||||
| def test_model(test_loader): | |||||
| print("Testing started.") | |||||
| test_losses = [] | |||||
| dice_test = [] | |||||
| results = [] | |||||
| test_epoch_losses, epoch_results, average_dice_test, average_accuracy_test, average_sensitivity_test, average_specificity_test = process_model(test_loader) | |||||
| test_losses.append(test_epoch_losses) | |||||
| dice_test.append(average_dice_test) | |||||
| print(dice_test) | |||||
| # Handling the results as needed | |||||
| return test_losses, results | |||||
| test_losses, results = test_model(test_loader) | |||||
| import torch | |||||
| import torch.nn as nn | |||||
| def double_conv_3d(in_channels, out_channels): | |||||
| return nn.Sequential( | |||||
| nn.Conv3d(in_channels, out_channels, kernel_size=3, padding=1), | |||||
| nn.ReLU(inplace=True), | |||||
| nn.Conv3d(out_channels, out_channels, kernel_size=3, padding=1), | |||||
| nn.ReLU(inplace=True) | |||||
| ) | |||||
| class UNet3D(nn.Module): | |||||
| def __init__(self): | |||||
| super(UNet3D, self).__init__() | |||||
| self.dconv_down1 = double_conv_3d(3, 64) | |||||
| self.dconv_down2 = double_conv_3d(64, 128) | |||||
| self.dconv_down3 = double_conv_3d(128, 256) | |||||
| self.dconv_down4 = double_conv_3d(256, 512) | |||||
| self.maxpool = nn.MaxPool3d(2) | |||||
| self.upsample = nn.Upsample(scale_factor=2, mode='trilinear', align_corners=True) | |||||
| self.dconv_up3 = double_conv_3d(256 + 512, 256) | |||||
| self.dconv_up2 = double_conv_3d(128 + 256, 128) | |||||
| self.dconv_up1 = double_conv_3d(128 + 64, 64) | |||||
| self.conv_last = nn.Conv3d(64, 1, kernel_size=1) | |||||
| def forward(self, x): | |||||
| conv1 = self.dconv_down1(x) | |||||
| x = self.maxpool(conv1) | |||||
| conv2 = self.dconv_down2(x) | |||||
| x = self.maxpool(conv2) | |||||
| conv3 = self.dconv_down3(x) | |||||
| x = self.maxpool(conv3) | |||||
| x = self.dconv_down4(x) | |||||
| x = self.upsample(x) | |||||
| x = torch.cat([x, conv3], dim=1) | |||||
| x = self.dconv_up3(x) | |||||
| x = self.upsample(x) | |||||
| x = torch.cat([x, conv2], dim=1) | |||||
| x = self.dconv_up2(x) | |||||
| x = self.upsample(x) | |||||
| x = torch.cat([x, conv1], dim=1) | |||||
| x = self.dconv_up1(x) | |||||
| out = self.conv_last(x) | |||||
| return out |
+ 158
- 0
utils.py
View File
| import torch | |||||
| import torch.nn as nn | |||||
| import numpy as np | |||||
| import torch.nn.functional as F | |||||
| def distance_to_edge(point, image_shape): | |||||
| y, x = point | |||||
| height, width = image_shape | |||||
| distance_top = y | |||||
| distance_bottom = height - y | |||||
| distance_left = x | |||||
| distance_right = width - x | |||||
| return min(distance_top, distance_bottom, distance_left, distance_right) | |||||
| def sample_prompt(probabilities, forground=2, background=2): | |||||
| kernel_size = 9 | |||||
| kernel = nn.Conv2d( | |||||
| in_channels=1, | |||||
| bias=False, | |||||
| out_channels=1, | |||||
| kernel_size=kernel_size, | |||||
| stride=1, | |||||
| padding=kernel_size // 2, | |||||
| ) | |||||
| kernel.weight = nn.Parameter( | |||||
| torch.zeros(1, 1, kernel_size, kernel_size).to(probabilities.device), | |||||
| requires_grad=False, | |||||
| ) | |||||
| kernel.weight[0, 0] = 1.0 | |||||
| eroded_probs = kernel(probabilities).squeeze(1) / (kernel_size ** 2) | |||||
| probabilities = probabilities.squeeze(1) | |||||
| all_points = [] | |||||
| all_labels = [] | |||||
| for i in range(len(probabilities)): | |||||
| points = [] | |||||
| labels = [] | |||||
| prob_mask = probabilities[i] | |||||
| if torch.max(prob_mask) > 0.01: | |||||
| foreground_indices = torch.topk(prob_mask.view(-1), k=forground, dim=0).indices | |||||
| foreground_points = torch.nonzero(prob_mask > 0, as_tuple=False) | |||||
| n_foreground = len(foreground_points) | |||||
| if n_foreground >= forground: | |||||
| # Calculate distance to edge for each point | |||||
| distances = [distance_to_edge(point.cpu().numpy(), prob_mask.shape) for point in foreground_points] | |||||
| # Find the point with minimum distance to edge | |||||
| edge_point_idx = np.argmin(distances) | |||||
| edge_point = foreground_points[edge_point_idx] | |||||
| # Append the point closest to the edge and another random point | |||||
| points.append(edge_point[[1, 0]].unsqueeze(0)) | |||||
| indices_foreground = np.random.choice(np.arange(n_foreground), size=forground-1, replace=False).tolist() | |||||
| selected_foreground = foreground_points[indices_foreground] | |||||
| points.append(selected_foreground[:, [1, 0]]) | |||||
| labels.append(torch.ones(forground)) | |||||
| else: | |||||
| if n_foreground > 0: | |||||
| points.append(foreground_points[:, [1, 0]]) | |||||
| labels.append(torch.ones(n_foreground)) | |||||
| # Select 2 background points, one from 0 to -15 and one less than -15 | |||||
| background_indices_1 = torch.nonzero((prob_mask < 0) & (prob_mask > -15), as_tuple=False) | |||||
| background_indices_2 = torch.nonzero(prob_mask < -15, as_tuple=False) | |||||
| # Randomly sample from each set of background points | |||||
| indices_1 = np.random.choice(np.arange(len(background_indices_1)), size=1, replace=False).tolist() | |||||
| indices_2 = np.random.choice(np.arange(len(background_indices_2)), size=1, replace=False).tolist() | |||||
| points.append(background_indices_1[indices_1]) | |||||
| points.append(background_indices_2[indices_2]) | |||||
| labels.append(torch.zeros(2)) | |||||
| else: | |||||
| # If no probability is greater than 0, return 4 background points | |||||
| # print(prob_mask.unique()) | |||||
| background_indices_1 = torch.nonzero(prob_mask < 0, as_tuple=False) | |||||
| indices_1 = np.random.choice(np.arange(len(background_indices_1)), size=4, replace=False).tolist() | |||||
| points.append(background_indices_1[indices_1]) | |||||
| labels.append(torch.zeros(4)) | |||||
| points = torch.cat(points, dim=0) | |||||
| labels = torch.cat(labels, dim=0) | |||||
| all_points.append(points) | |||||
| all_labels.append(labels) | |||||
| all_points = torch.stack(all_points, dim=0) | |||||
| all_labels = torch.stack(all_labels, dim=0) | |||||
| # print(all_points, all_labels) | |||||
| return all_points, all_labels | |||||
| device = "cuda:0" | |||||
| def main_prompt(probabilities): | |||||
| probabilities = probabilities.sigmoid() | |||||
| # Thresholding function | |||||
| def threshold(tensor, thresh): | |||||
| return (tensor > thresh).float() | |||||
| # Morphological operations | |||||
| def morphological_op(tensor, operation, kernel_size): | |||||
| kernel = torch.ones(1, 1, kernel_size[0], kernel_size[1]).to(tensor.device) | |||||
| if kernel_size[0] % 2 == 0: | |||||
| padding = [(k - 1) // 2 for k in kernel_size] | |||||
| extra_pad = [0, 2, 0, 2] | |||||
| else: | |||||
| padding = [(k - 1) // 2 for k in kernel_size] | |||||
| extra_pad = [0, 0, 0, 0] | |||||
| if operation == 'erode': | |||||
| tensor = F.conv2d(F.pad(tensor, extra_pad), kernel, padding=padding).clamp(max=1) | |||||
| elif operation == 'dilate': | |||||
| tensor = F.max_pool2d(F.pad(tensor, extra_pad), kernel_size, stride=1, padding=padding).clamp(max=1) | |||||
| if kernel_size[0] % 2 == 0: | |||||
| tensor = tensor[:, :, :tensor.shape[2] - 1, :tensor.shape[3] - 1] | |||||
| return tensor.squeeze(1) | |||||
| # Foreground prompts | |||||
| th_O = threshold(probabilities, 0.5) | |||||
| M_f = morphological_op(morphological_op(th_O, 'erode', (10, 10)), 'dilate', (5, 5)) | |||||
| foreground_indices = torch.nonzero(M_f.squeeze(0), as_tuple=False) | |||||
| n_for = 2 if len(foreground_indices) >= 2 else len(foreground_indices) | |||||
| n_back = 4 - n_for | |||||
| # Background prompts | |||||
| M_b1 = 1 - morphological_op(threshold(probabilities, 0.5), 'dilate', (10, 10)) | |||||
| M_b2 = 1 - threshold(probabilities, 0.4) | |||||
| M_b2 = M_b2.squeeze(1) | |||||
| M_b = M_b1 * M_b2 | |||||
| M_b = M_b.squeeze(0) | |||||
| background_indices = torch.nonzero(M_b, as_tuple=False) | |||||
| if n_for > 0: | |||||
| indices = torch.concat([foreground_indices[np.random.choice(np.arange(len(foreground_indices)), size=n_for)], | |||||
| background_indices[np.random.choice(np.arange(len(background_indices)), size=n_back)] | |||||
| ]) | |||||
| values = torch.tensor([1] * n_for + [0] * n_back) | |||||
| else: | |||||
| indices = background_indices[np.random.choice(np.arange(len(background_indices)), size=4)] | |||||
| values = torch.tensor([0] * 4) | |||||
| # raise ValueError(indices, values) | |||||
| return indices.unsqueeze(0), values.unsqueeze(0) | |||||
Loading…